

tacoms SREの出川です。
今日はtacomsのとある部分で採用した、Google CloudのBigQueryをWebアプリケーションから直接叩く構成を紹介します。流石に無理では?と思われると思いますが、検討するうちにBI Engineを使うことで意外と現実的なことがわかり、現在では本番環境で元気に稼働しています。
課題
tacomsではCamelという、飲食店がフードデリバリーの管理や運用を効率的に行えるプロダクトを運用しています。
この中のある機能の中の、注文の売上額を集計する機能のパフォーマンスが悪く、それの改善が課題でした。
調査してみるとAurora MySQLで素朴にgroup byとsumを行っていたり、パフォーマンスの悪さをカバーするためにアプリケーションで無理やり何十ものループをして集計を行っていたりと、かなり効率の悪い処理をしている状態でした。集計対象テーブルには数億行あるものもあり、クエリチューニングやインデックス調整などだけでは限界があることはすぐにわかりました。
様々な構成を検討するもDWHを0から設計する時間もなく、RedshiftとのゼロETL統合なども今回は諸事情で使えない状態。また絞り込める条件が店舗、デリバリーサービス、日付と時刻、注文の状態、住所など多数あり、全て同時に任意の数を指定できるという自由度を与えており、全ての場合のパフォーマンス改善を行うことが現実的ではありませんでした。データの鮮度をある程度諦めて事前に集計したデータを持っておくというのがよくある方法ですが、集計ディメンジョンが多数ある状態だと全ての組み合わせが膨大になります。このため今までのように一つの機能として提供することが難しく、画面やグラフの分割など仕様の変更までがスコープに入り始めました。
そこで社内の分析用基盤のBigQueryに直接クエリを投げてその結果を使えないかというアイディアがありました。
基本的にはBigQueryはデータウェアハウスとして大規模なデータを持たせBIツールとして使うのが基本で、tacomsでもその用途で利用していました。Webアプリケーションのリクエストがあるたびにクエリを投げて結果を返すような利用シーンは想定していないはずです。
レイテンシや料金、各種クオータの制限を考えるとそんなことはできないだろうと思いつつ調べ始めると、デメリットはあるもののBI Engineを使えばかなり現実的であり、喫緊の要件を十分満たせることがわかったため、この構成を採用することにしました。
採用した構成
構成の概要は以下のとおりです。
データの流れは以下の通りです:
- Aurora snapshot exportでS3にParquetで出力
- S3からBigQuery source Datasetへ転送
- source datasetからscheduled queryでtarget datasetへscheduled queryでデータ変換
clientからBigQuery APIを叩いて結果を取得します。
BI Engineとは
今回の構成のポイントです。
簡単に言うとBigQueryの手前にあるインメモリ型キャッシュレイヤーです。BI Engineの予約量をGB単位で決めておくだけで、BigQuery APIを利用する際に透過的に使われ、クライアントは意識する必要がありません。
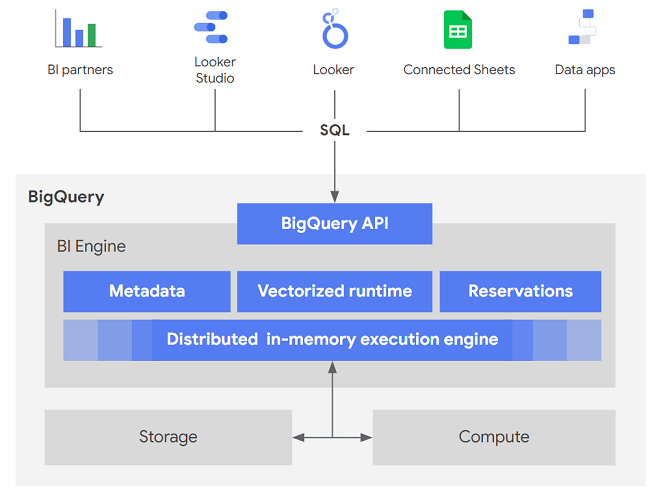
(https://cloud.google.com/bigquery/docs/bi-engine-query?hl=ja より抜粋)
予約容量に対してのみ課金され、BI Engineのみ解決されるクエリは課金が発生しません。BI Engineのみで解決できないクエリは通常のBigQueryに対するクエリと同様に課金されます。特別な設定がほぼ必要なく、予約容量と「preferred table」を設定するだけで利用可能になります。
BI Engineの料金はasia-northeast1で $0.0499 per GiB per hour です。10GBを30日間予約すると約$360です。
優先テーブルのデータを全てBI Engineに収まるように設定し、常にAPIリクエストごとの課金を0円にすることがベストとされています。テーブルの論理データサイズに合わせて予約容量を確保すると良いでしょう。
BigQueryで使える機能のうち一部はサポートされていないので、よくドキュメントをご確認ください。
実際に叩いてみた様子
以下はconsoleからクエリを叩いてみた例です
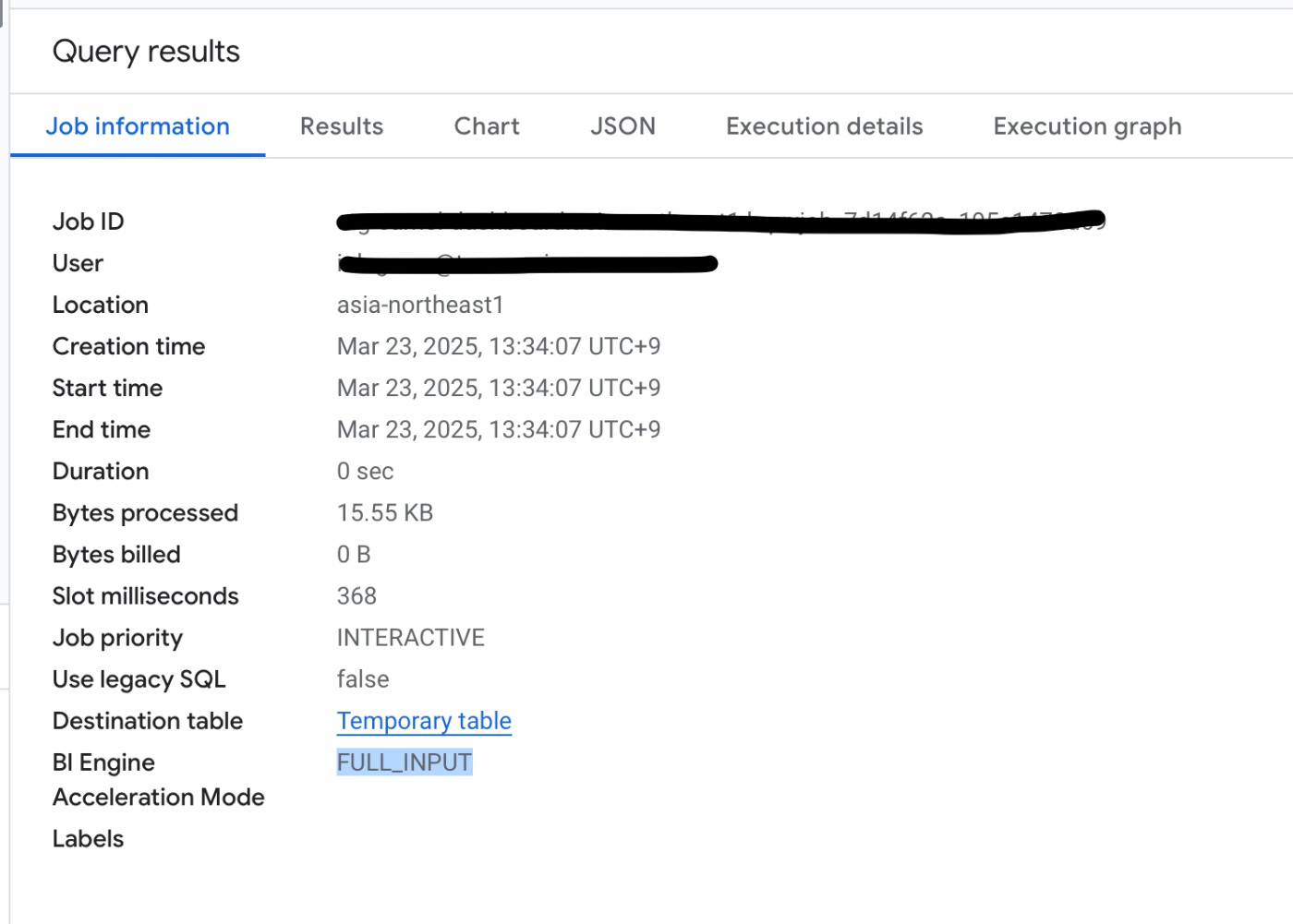
- Bytes billedが0になっている => 課金額ゼロ
- BI EngineがFULL_INPUT => 全てのデータがBI Engineから取得されている
クエリごとの課金量は抑えられていることがわかると思います。またBigQuery APIのレイテンシも、このように全てBI Engineで解決できるものは99pctで1s以下に抑えられていました。
もちろんBI Engineに全ての優先テーブルの全てのデータが収まらない場合は通常のjobのようにデータをみに行く分処理時間がかかります。今回のユースケースではこれを含めてレイテンシは許容範囲内でした。
一番の狙いだったレイテンシの改善も確認できました。本番環境での稼働開始後、今までSQLの実行で1分程度かかっていたAPIのレイテンシが1,2秒程度で収まることが確認できました。今回のケースでは数秒程度であれば機能の性質上問題ないと判断できました。また10s以上かかることは一度もないなど、レイテンシのばらつきもなく非常に安定しています。詳細なデータは今後見せられるようになったこのブログにまた投稿しようと思います。
デメリット
BigQuery APIはGoogle Cloud外のWebアプリケーションのワークロードからリクエストごとに利用されるような想定をされているサービスではないため、本番環境での利用を可能にするためには多くの条件があり、デメリットを受け入れる必要があります。
優先テーブルのデータ量がBI Engineの予約量に収まる場合は上記のメリットが最大限に活かせますが、収まらない場合はデメリットが大きくなります。
この場合、利用頻度の低いデータに対するクエリではBI Engineに乗らずscanned bytesが0にならない場合が出てきます。こうなるとscanned bytesに比例する課金(Webアプリケーションへののリクエスト数に関係する課金)が増えますし、レイテンシも数秒になる場合が増えてきます。
またBI Engineを利用してもBigQuery API自体の制限は変わらないため意識常にする必要があります。特に以下が気になると思います。
- BigQuery API: メソッドごとのユーザーごとの 1 秒あたりの API リクエストの最大数 100 件のリクエスト
- クエリジョブ:キューに追加できるインタラクティブ クエリの最大数 クエリ 1,000 件
またHTTP APIであるため数ms、数十ms単位でのレイテンシも期待できません。総じてスケーラビリティは低い構成であることを念頭におく必要があります。
tacomsでは採用するにあたって、以下の条件を確認した上で、採用できるという判断をしました
- 該当するWebアプリケーションのAPIへのリクエストが多くない
- 同時実行数100/sで十分賄える
- BigQuery APIのレイテンシが数秒かかってもユーザー体験に大きな影響を与えない
- Scanned bytes、課金額、BigQuery APIのquotaに関係するメトリクス等のモニタリングをリリース初期から行う
また、今後利用量が増えてきた場合に以下の対策を進めることにしました。
- アプリケーションで結果をキャッシュし叩く回数を減らす
- 事前集計が可能な部分は事前集計を進める
- テーブルがBI Engineに収まるサイズにする
- アプリケーションに近いRDB等に置いてそこへアクセスする(reverse ETL, BigQuery APIを使わない)
まとめ
BI EngineはBigQuery APIを透過的に効率化して、コスト削減やレイテンシの改善をしてくれて非常に便利です。いわゆるBIツールとしてBigQueryを扱う場合に限らず、今回のようにWebアプリケーションからリクエストごとに直接BigQuery APIを叩くことも現実的になります。
BigQueryを使われている方は大きなメリットが得られることが多いと思いますので、ぜひ一度試してみてください。
Special Thanks
実は既にZennさんが同様の構成を記事にしており、この記事からWebアプリケーションからBigQuery APIを叩く勇気をもらいました。コメントへの回答を頂けたりなど、非常に助かりました。ありがとうございました!

Discussion