先日、統計ダッシュボード機能(β)をリリースしました。記事をひとつでも公開している場合、Zennにログインすればどなたでも統計情報を表示できます。執筆頻度の確認や閲覧回数の参考にお役立てください。
本稿ではどのように実現したかについて課題とともに記録します。
TL;DR
- 投稿ページの表示イベントは Google Analytics から BigQuery へ連携しており、イベントデータ(BigQuery)と記事データ(Cloud SQL)をどうJOINさせるかが課題
- 外部接続でBigQueryからCloud SQLつなぐことにした
- 統計データ読み出し時、BigQueryを直接使うとクエリ毎に課金されてしまうため、BigQuery BI Engine を使うことにした
- スケジュールクエリを使い、BI Engineの容量に収まるように集計データを最小限にまとめる
- チャートは Chart.js で泥臭く見た目をの整えて表示する
- 残課題: スロットは共用リソースであるため、負荷状況によっては統計ページの表示に時間がかかる可能性がある
前提
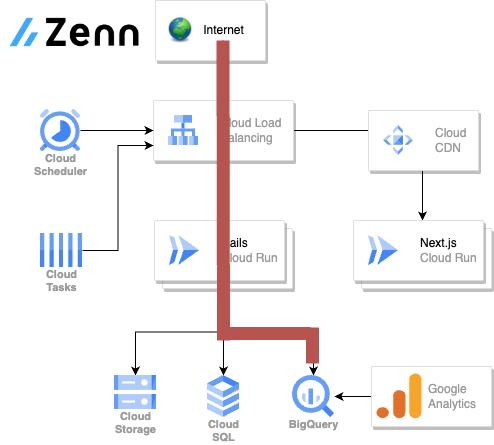
Zenn のアーキテクチャ概観は以下のようになっています。

統計ダッシュボードは自分が記事を書いていても欲しいと思いますし、Zennでもなんとか実現できないか模索していました。議論のすえ、チームとして用意しようと決めた統計は次の3つです。
- 期間ごとの表示回数が見られること
- 記事ごとの表示回数が見られること
- 執筆頻度がわかること
話をシンプルにまとめるため、本稿では 期間ごとの表示回数が見られる 統計に限定して述べます。が、他の統計も同じ仕組みで実現しており、読み出し時のクエリが違うだけです。
これを実装するためのアレコレを述べていきます
表示回数は、Google Analytics で取得しているイベントデータを利用すれば集計できそうでした。しかし、アナリティクスのpage_viewイベントで使えるのはページのURLとタイムスタンプくらいです(参考)。かといってカスタムイベントを用意し、集計に必要な情報も一緒に記録したのではデータ量が肥大化してしまいます。なので、イベントデータと、記事データをどこかでJOINする必要がありました。
前提と要件を整理します:
- Google Analytics に
page_viewイベントが記録され、BigQueryへすでに転送している。主に年末のRecapで利用していた - ユーザーごとのダッシュボードに表示するので、ログインユーザーを認可する必要がある
- イベントデータと記事データ(誰の持ち物か)をJOINする必要がある
検討した実現方法
アナリティクスに記録されたイベントからそれが誰の記事なのかたどる必要があるため、メインDBである PostgreSQL on CloudSQL を何らかの形で使うことは確定です。Cloud SQLと連携する方法を考えていくのですが…Howの話になるとさらに選択肢が増殖するのがやっかいでした。まず、表示するところは考えずに、どうやって欲しいデータを集計して取得できるようにするかを考えます:
- Cloud SQL に集計用データも持ち、Cloud SQL で完結させる
- Cube Cloud から BigQuery、CloudSQL を使う
- BigQuery から Cloud SQL のデータをどうにかしてJOINして使う(★これを採用)
Cloud SQL に集計用データを持つ方法
最後まで採用するか悩んだ方法です。ユーザーごとの集計が必要になるので、それだったら集計データを Cloud SQL へ入れてしまえばいいじゃない…と考えました。Cloud SQL は自動でストレージ容量も増やしてくれますし、イベントデータさえ持ち込めば集計も Cloud SQL で完結します。しかし、Cloud SQL にどのようなデータを持たせたいか、という観点でこの案はナシにしました。Cloud SQLはRDBであり、リレーションシップが有効に使えるコンテンツが主役です。page_viewをはじめとしたイベントデータは、容量もレコード数も規模が違います。他のイベントデータも採取することになった場合、Cloud SQL がどこまで耐えられるかわかりません。要件とシステムのスケール性を考えたとき、Cloud SQLにイベントデータを蓄積させるのは回避したいと思いました。
Cube Cloud を使う方法
Cube Cloud はヘッドレスBIツールです。BigQuery と接続し、独自のDSLで集計が可能なサービス/アプリケーションです。
キャッシュの仕組みもあり、ユーザーごとに集計した今回の要件にマッチしそうだなと思いました。しかしおそらく Cube Cloud がやりたいことはBIの統合環境を提供することです。多種多様なデータソースと、そこから集計したデータをいろいろなツールで表示するための基盤として提供することが真価になりそうです。たとえば複数の工場や部門を抱える製造業で、マーケ部隊がBIとして使ったり、工場単位で異常検知に使う、といったシーンではマッチしそうです。逆に今回のように、データソースはBigQueryとCloud SQL、表示する箇所はユーザー向けのダッシュボード(Webアプリ)のみで今後増える予定はとくにない状況では、ややオーバースペック気味だと感じました。
専用のサーバーを立てる必要もあり、DSLもメンテしなければならないため、候補から外しました。ただ、チャンスがあればどこかで使ってみたいですね。
BigQueryで完結させる方法
現在採用している方法です。 Google Analytics のデータが蓄積されており、なおかつ BigQuery でパワフルなクエリも使えるため、ここで完結できないか模索しました。先述のとおり、Google Analytics のイベントデータは年末のRecapで集計・Railsからの呼び出し実績があったため、実装がイメージしやすかったこともあります。以降はBigQueryで頑張る場合の課題とその解決策について述べていきます。
BigQueryでユーザー毎統計データを集計するときの課題
バッチ的に一度実行すれば終わりなタイプの年末Recapと違い、今回は統計データがユーザー任意のタイミングで呼び出されることになります。これはこれで別の課題が浮上します。
課題1. 認可
当たり前ですが、ユーザーAが呼びだす統計情報は、ユーザーBからアクセスできないようにしなければなりません。これは「リクエスト自体はRailsで捌き、Railsの仕組みで認可を通し、RailsからSDKでBigQueryの集計データを取得する」ことによって解決しました。構成図でいうと赤線のルートを通ることになります。
課題2. 記事データとのJOIN
page_viewをはじめとしたイベントデータは BigQuery に蓄積されていて集計可能ですが、そのイベントが発生したページが誰の記事なのか特定できる必要があります。記録されたURLから記事や執筆者を特定するため、Cloud SQL との連携が必要です。
Datastreamを使う
まず考えたのがCloud SQLの複製(もちろん必要最小限の情報のみに削ぎ落として)をBigQueryへもつことです。ちょうどこのあたりを検討しているときに、Datastreamで PostgreSQL から BigQuery へ送信できるようになりました。
しかし、結果的に採用していません。以下の点がクリアできませんでした。
- ふだん、Cloud SQL は Cloud SQL Proxy を通して利用しているため、このためだけに Public IP と認可済みネットワークを意識するのは運用コストとメリットが見合わない
- レプリケートの実体はCDCだが、PostgreSQLで有効にすると非ユニークインデックスに対するUPDATE/DELETEができなくなる
- 運用業務で「特定条件を満たす記事を一括で更新する」ということができなくなるので厳しい
外部接続を使う
次に外部接続を検討しました。こちらを採用しています。BigQueryでは外部のデータソースと連携してテーブルへ取り込んだり、直接クエリを実行できます(参考)。Cloud SQL は、連携クエリで直接BigQueryからクエリを実行できる点に注目してください。Cloud SQL のデータを BigQuery の世界へ持ち込むことができるならば、あとは BigQuery 側でどうとでも料理できます。今回の例でいくと、以下のようにして Cloud SQL から記事IDとURLを取得できるため、イベントデータのURLとJOINすれば page_view イベントが発生した記事IDとユーザーIDを特定できるという理屈です。
SELECT *
FROM EXTERNAL_QUERY(
'us.zenn_db_connection',
'''
SELECT id, user_id, url
FROM articles
''');
連携クエリのとっかかりは以下の記事が参考になります。
これで、BigQueryのイベントデータと、Cloud SQLの記事データをJOINする準備ができました。
課題3. クエリ課金
連携クエリで記事データとJOINできることがわかったので、ユーザーごとの必要なデータは集計・取得できます。機能的には問題ありません。あとはコストです。一般的なBIの文脈とは違い、不特定多数のログインユーザーが任意のタイミングでBigQueryのクエリを叩くことになります。BigQueryはクエリ課金であるため、愚直に使うとクエリ料金が青天井です。
雑に計算してみると、10MB(最低単位)× 10万人 × 1回 = 1000TB TBあたり$6なので 10万人が1回統計ページを開くと$6000 かかる計算になります。金額もそうなのですが、スケールさせたい構成のなかでコスト面でのボトルネックができてしまう点が気になりますね。
BigQuery BI Engine を使う
課金について悩んでいたところ、さらに調査を進めると、BigQuery BI Engineなるものを見つけました。
BigQuery BI Engine は、頻繁に使用するデータをインテリジェントにキャッシュに保存することで、BigQuery の多くの SQL クエリを加速する高速なメモリ内分析サービスです。
データをメモリに置いておくことでクエリを高速化するサービスのようです。さらに料金について調べると:
BI Engine に保存されたデータから結果を取得するクエリを実行する場合、データの読み取りについては課金されません。
データの読み取りについては課金されません!!!つまり、
- BI Engine ではキャッシュ容量をあらかじめ購入し、キャッシュに入れたいBigQueryテーブルを指定する
- ユーザーの統計で利用するデータがすべてキャッシュ内に収まれば、統計ページを表示するときのオンデマンド料金がかからずに済む
ということがわかりました。可能性の塊ですね。ちなみに、サービスの実体はキャッシュ容量と優先するテーブル設定だけで、アプリケーションからみたときの使い方は BigQuery のそれとまったく変わりません。
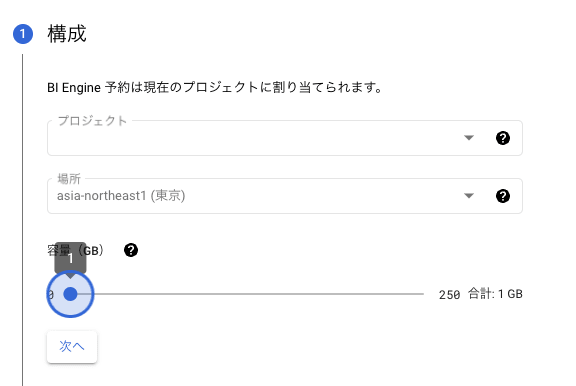
キャッシュ容量をどのくらい買うか設定

リージョンのどのテーブルを優先的にキャッシュへ入れるか設定
BI Engine はその名の通り、おそらく頻繁に分析するBIデータをキャッシュしておくための仕組みで、思想から少し外れた使い方かもしれません。しかしオンデマンド料金を抑えたい目的は同じなので、採用してみることにしました。BI Engineを有効に使うには前述のとおりなんとかしてキャッシュ容量の中に集計データを収める必要がああるため、そのために工夫したポイントが、スケジュールクエリを使い、BI Engine に特化したテーブルを毎日更新するという点です。
スケジュールクエリで必要最小限のデータを用意する
Google Analytics のイベントデータにはタイムスタンプが記録されていますが、集計に必要な最小単位は日ごとのデータです。統計ページで必要となる情報は意外とスリム化できます。あらかじめ集計に必要なデータを一段階まとめておければ、BI Engineのキャッシュ内に収めやすくなります。これを実装するために、スケジュールクエリを採用しました。
スケジュールクエリでは生データを一段階集計用にまとめます。
- 不要なデータを削ぎ落とす
- 日ごとのデータに集計する
スケジュールクエリのイメージは以下です。
INSERT INTO
`${project_id}.zenn_stats.content_pv_stats` ( event_date_jst,
id,
user_id,
content_type,
content_slug,
pv)
SELECT
event_date_jst,
id,
user_id,
content_type,
content_slug,
pv
FROM
tmp_article_pv_count_yesterday;
event_date_jst つまり日ごとの pv に集計され、そのデータに user_id と content_slug(URL)が付与されていることがわかります。これを毎日積み上げていきます。このデータがあれば、あとは統計データの呼び出し時にユーザーごと、日ごとの集計が可能になります。
本当に課金されないの?
不安になりますが、クエリ実行結果で確認できます。このPVデータを表示するにあたり…
次のようなクエリが実行されます。さっき集計した日ごとの蓄積データに対するクエリですね。
SELECT
event_date_jst,
SUM(pv) AS sum_pv
FROM
`content_pv_stats`
WHERE
user_id = 1
AND event_date_jst BETWEEN '2023-06-26' AND '2023-07-26'
GROUP BY
user_id,
event_date_jst
Google Cloudのコンソールから実行結果をみてみましょう。

BI Engine モード: FULL、課金されるバイト数: 0 B となっていることがわかります。BI Engine の容量に収まり、クエリ料金は課金されていないことがわかります。
残課題: スロットの枯渇によりクエリ速度が落ちる可能性
料金の課題は BI Engine で解決できましたが、スロット が枯渇する可能性をはらんでします。スロットが枯渇すると統計ページを表示するのに待ち時間が発生してしまうと理解していて、こちらはモニタリングを続け、どのくらいで枯渇しそうか、また、待ち時間とはどれくらいなのか、調査します。
スロットについてはこちらの記事がわかりやすかったです。
グラフの描画は?
集計データの読み出しでかなり苦労しましたが、描画はもっと大変でした(主に技術力不足で)。本筋から外れるため詳細は述べませんが、Chart.jsを使って描画しています。
- 日ごとのデータである
- X軸はこういうふうに表示する
- ラベルは重ならないように間を飛ばす
のようなオプションが設定できるため、これらを駆使してなんとか見やすい形に整えました。整えてくれました。…チームメンバーに感謝します。
まとめ
統計ページの実装方法で、BI Engine を使った例について紹介しました。こうしてみると、なにか進めるごとに課題にぶつかりつつ、なんとかひとつずつつぶしていったことがみてとれますね。
BigQuery を使う上で考慮すること
BigQuery はデータウェアハウスとして申し分ないサービスであり、今後も利用が加速すると思います。しかしクエリごとに課金されるため、頻度が増えてきたらクエリを見直したり、BI Engine の利用を検討してもいいかもしれません。
BI Engine を使う上で考慮すること
容量をあらかじめ買うため、実現したい要件の必要十分なデータを用意することが肝要だと思いました。その方法のひとつにスケジュールクエリがあります。
まだまだ完璧ではありませんが、引き続き課金状況や負荷状況をモニタリングし、利便性の向上に努めていきたいと思います。

Discussion
BigQueryへアプリケーションから直接繋ぐのは避けていたんですが、意外とできてしまうものなのですね!
jobの同時実行数などは問題ないのか気になりました。
コメントありがとうございます。そうですね、実行数が増えると待ちが発生する認識があったため、同一条件による結果の取得はZenn側のDBに保存してキャッシュが効くようにしています。いまのところ大丈夫そうです。
これってプロジェクト単位とかで上限あるということですかね?ドキュメントとかご存知でしょうか。わたしはドンピシャなドキュメントが見つけられず 🤔
やはりキャッシュは有効そうですね! ありがとうございます。
軽くみてみたところ、APIを直接叩く場合は以下の値に注意が必要かなと想像しました!
ありがたいですありがたいです、ありがとうございます。
あーーこちらノーチェックでした。感謝します。APIのレート制限がありましたか…この「ユーザー」というのがCloud Runのサービスアカウントのことだとすると、そうですね、一気にたくさん呼ばれるとひっかかる可能性がありますね。キャッシュしておいてよかった…
こちらも関係ありそうです!Zennの場合は、ある程度の待ち時間を覚悟いただくことを前提に「バッチクエリ」を利用しているはずです。なので、
適用されるのはこっちかもしれません 🤔
アプリから直接つなぐ場合、このあたりのリミットは意識しておく必要がありますね。インプットしていただいたことでこの先慌てなくて済みそうです。感謝です。
いま、メトリクスを見てみたのですが(合ってるかどうか微妙)同時実行数らしき指標はだいたい1〜3で推移していました。キャッシュがいい感じに効いていそうです。
だいぶ実行数少なく済んでますね!
こちらの記事にはアプリからBigQuery APIを直接叩く勇気をもらい、非常に参考になりました。いい情報をありがとうございます!
めっちゃわかります!アプリから直接使いたい方を後押しできればという気持ちでこの記事を書いたので嬉しいです!
なんか踏んだらぜひ教えて下さい 😂