DDDを実践するためのリポジトリ層の設計(Go言語による例)

The Go gopher was designed by Renée French. Illustrations by tottie.
はじめに
この記事は、ドメイン駆動設計(DDD)の中核概念である「リポジトリ」についての理解を深めることを目的としています。リポジトリの基本的な役割と重要性を確認し、Go言語での実装の例を紹介します。
前提
- リレーショナルデータベースからデータを取得(更新)するアプリケーションを想定しています
- サンプルコードは Go 言語で書かれています
リポジトリとは
まずは、リポジトリの定義を確認してみましょう。
リポジトリパターンとは:
リポジトリは、データベースから取得したデータを構造体にマッピングし、ドメインオブジェクトにアクセスするためのインターフェースを提供します。
これは、一般的なリポジトリの理解と相違ないですね。次に DDDの文脈で、より詳しい定義をみてみましょう。
より詳しいリポジトリの定義
DDD リファレンス を確認してみましょう。DDD リファレンスは Eric Evans 氏の DDD 本の内容をもとに、各 DDD の用語がまとめられた資料です。17ページに以下のように書かれています。
リポジトリの定義 (DDD リファレンス):
ユビキタス言語で表された集約に対するアクセスを可能にするものです。
なにかを取得するために多くの関連が発生するとモデルが混乱します。成熟したモデルでは、クエリはドメインの概念を表します。しかし、クエリは問題を引き起こしやすい。データベースの技術的複雑さはすぐにクライアントのコードを埋もれさせ、それによって開発者はドメインレイヤーをバカシンプルなものにしてしまい、その結果、モデルは無意味なものになります。クエリ・フレームワークはほとんどの技術的複雑性をカプセル化し、宣言的かつ自動的な方法でデータベースからデータを取得することを可能にします。しかし、これは単に一つの問題を解決しているだけです。
なんの制約もなく書かれたクエリは、カプセル化をやぶってオブジェクトの特定のフィールドの値を取り出したり、または、集約のルートのカプセル化を破り、特定のフィールドのオブジェクトを取り出すかもしれません。これはドメインモデルのルールを守ることを不可能にします。
ドメインロジックはクエリやアプリケーション層のコードに漏れ出し、エンティティと値オブジェクトは単なるデータコンテナに成り下がります。したがって:
リポジトリは、グローバルなアクセスが必要なそれぞれの集約について、その集約のルートの型のオブジェクトのすべてのインメモリコレクションを扱うようなイリュージョンを提供します。よく知られたグローバルなインターフェースを定義します。オブジェクトを追加したり、削除したりする方法を提供し、データストアでの実際の挿入や削除をカプセル化します。そして、ドメインエキスパートにとって意味のある基準でオブジェクトを取得 (select) する方法を提供します。リポジトリが返すのは、完全にインスタンス化されたオブジェクトや、オブジェクトのコレクションです。これらのオブジェクトは実際のストレージやクエリ技術をカプセル化し、lazy な方法で完全にインスタンス化された集約であるかのようなイリュージョンを提供します。リポジトリは集約のルートに対してのみ直接アクセスが提供されます。アプリケーションのロジックはモデルに集中し、オブジェクトストレージやアクセスに関する詳細はリポジトリに委任します。
リポジトリの役割
DDDリファレンスの定義において、リポジトリの役割は集約へのアクセスを提供することです。リポジトリはかならず集約と対で存在します。
集約とは
聞き慣れない 「集約」 という言葉が登場しました(英語では Aggregate と呼ばれます)。集約とは何でしょうか?DDD リファレンスのリポジトリの一つ上の16ページに集約の解説が書かれています。
集約の定義 (DDD リファレンス):
集約とは、エンティティとバリューオブジェクトのクラスター(塊、集合体)であり、集約同士の境界を定義するものです。集約の外部のオブジェクトは、集約の root に対してのみ参照を持つことを許可されます。集約は、その属性(properties)と不変要素(invariants)を定義する単位であり、これを維持する責任を持ちます。
集約の境界は、トランザクションと分散の境界と一致していなければなりません。
集約の内側では、同期的に一貫性が確保される必要があります。集約の外部では、非同期に更新を扱います。
一つの集約は、一つのサーバー内に留めます。異なる集約は、他のサーバに分散されることが可能です。
エンティティとは
エンティティも DDD リファレンスに定義されています。エンティティは、ID で一意に識別できるドメインオブジェクトです。ドメインモデルには、エンティティと値オブジェクト (Value Object) があります。値オブジェクトは ID を持たないモデルです。
集約 = "モデル" ではない
昔から、アプリケーション開発では、"モデル"という言葉が使われています。これは使う人や話の文脈によって意味が変わる言葉です。一昔前、Web アプリケーション開発で "モデル" といえば、MVC (Model-View-Controller) パターンにおけるモデルを意味していました。
Active Record という設計パターンを聞いたことがあるかもしれません。Active Record は Ruby on Rails や ORM ライブラリで採用されているデザインパターンです。Active Record パターンでは、"モデル" はテーブルの 1 レコードのデータを保持します。
Ruby on Rails では、Active Record を実装したクラスを "モデル" と呼びます (models/ というパスに配置します)。Rails の影響もあり、アプリケーション開発現場で "モデル" といえば、たいていは、テーブルの1行のデータを保持するオブジェクトを意味するようになっていました。
DDD における集約は、Ruby on Rails の意味する "モデル" とは異なる
前述のとおり、DDDにおける集約は、ルートとなるエンティティのデータだけでなく、他のエンティティのデータも保持することがあります。そのため、集約はテーブルと 1対1 ではなく、1対n の関係です (n >= 1)。DDD における集約は単にテーブルの 1 レコードを操作するためのものではありません。
集約はドメインモデルです。一つのエンティティから構成されるとしても集約の一種と捉えてください。リポジトリは集約にアクセスする窓口を提供します。
集約を構成するエンティティ
集約は 1 つ以上のエンティティから構成されることがわかりました。では、集約を構成するエンティティはどのように決めるべきなのでしょうか?
DDD リファレンスには、以下のように書かれています。
集約は、その属性(properties)と不変条件(invariants)を定義する単位であり、これを維持する責任を持ちます。
つまり、集約とは、ドメインモデルの属性を定義し、かつ、そのドメインモデルに求められる不変条件(Invariant)を維持する責任を持つ単位、ということです。
不変条件(インバリアント)とは、要するに常に維持されていないとマズいデータの関係のことです。つまりデータ整合性です。データ整合性(インバリアント)を維持するためには、同一トランザクションでデータを更新しなければなりません。これが集約の単位になります。まとめると以下のとおりです。
集約を構成するエンティティとは:
データベースのデータ整合性(インバリアント)を保つうえで、一体として扱われるべきエンティティと値オブジェクトの塊(クラスター)です。そのうちの一つのエンティティが集約のルートとなります。他の集約は、ルートのエンティティに対する参照のみを保持でき、集約の内部にカプセル化されたエンティティに対する参照は保持できません。
集約の境界
集約の境界を正しく決める銀の弾丸はありません。集約の境界を適切に決めるには、データベース設計の検討、拡張性の考慮、ドメイン知識が必要になります。複雑なドメイン(例えば在庫管理システムなど)では集約の境界を適切に決めるのがより難しくなります。
一般的なルール:
集約の境界はできるだけ小さくしましょう。データベースのトランザクションを小さくするため、また、集約の責務を明確にするためです。
集約の境界を小さくするには
集約の境界を小さくするにはどうしたら良いでしょうか。集約の境界を小さくするには、テーブル設計の段階から考える必要があります。
集約の境界は、将来的にサービスやプロダクトがスケールした場合、非同期処理の境界になります。そのためトランザクションが分割されてもデータ不整合が起きないように境界を決めなくてはなりません。場合によっては、意外な形でテーブルを分ける必要があるかもしれません。
集約が大きくなると、同期トランザクションで更新するテーブルが多くなり、パフォーマンスや保守性の低下に繋がります。一見、ひとつのトランザクションで更新するべきエンティティ群に思えても、よく考えたら分割できることもあります。思い込みにとらわれずに考えることが大切です。
補足:
集約の境界でトランザクションを分割する場合、一部のトランザクションが失敗したらどうなるかを考える必要があります。可能であれば、ユーザーインターフェースの一回の操作が、集約の境界をまたがない設計にするのが理想です。集約の境界はユーザーインターフェースとも関連が深いため、早い段階でプロダクトマネージャやデザイナーと認識を合わせておく必要があります。
ショッピングカートの例
EC サイトのショッピングカートのリポジトリのインターフェースを考えてみましょう。ショッピングカートのテーブルと、カートアイテムのテーブルがあるとします。アプリケーション層のユースケース X は、ショッピングカートとカートアイテムのデータを利用します(例:ショッピングカートに商品を追加する)。
ER図
DDD ではないリポジトリ
違いを確認するために、DDDを採用しない場合のインターフェース設計を見てみましょう。リポジトリとテーブルが1対1で存在しています。ShoppingCart リポジトリと CartItem リポジトリがあります。
クラス図
それぞれのリポジトリのインターフェース:
package models
type ShoppingCart interface {
GetByUserID(uuid.UUID) (*ShoppingCart, error)
Insert(*ShoppingCart) error
Update(*ShoppingCart) error
}
type CartItem interface {
GetByShoppingCartID(uuid.UUID) ([]*CartItem, error)
Insert(*CartItem) error
Update(*CartItem) error
}
モデルの定義:
それぞれのテーブルの 1 レコードを表すための構造体をモデルとして定義しています。ShoppingCartとCartItemのモデルが分離されているためドメインロジックをモデルにカプセル化できません。
package models
type ShoppingCart struct {
ID uuid.UUID
UserID uuid.UUID
Status ShoppingCartStatus
}
type CartItem struct {
ID uuid.UUID
ProductID string
Quantity int
}
問題点
この方法には次の問題点があります。
- モデルはテーブルのレコードを保持する単なるコンテナになる。
- ドメインロジックはユースケース X に実装される。
- 集約のインバリアントはアプリケーション層で担保される。
- 新規・更新のデータベース操作の使い分けをユースケース X で考慮する必要がある。
DDD の定義に沿ったリポジトリの例
今度は DDD の考え方でショッピングカートのリポジトリを設計してみましょう。
集約のルートを ShoppingCart エンティティとします。CartItem エンティティは ShoppingCart 集約にカプセル化されます。
まず ShoppingCart 集約に対応するリポジトリを定義します。前述の例とは異なり、CartItem リポジトリは存在しません。テーブル単位ではなく、集約単位にリポジトリを定義するからです。ShoppingCart 集約の AddItem メソッドはユースーケース X で利用するメソッドの例です。
クラス図
リポジトリのインターフェース:
リポジトリは、集約の読み込み、更新の処理をカプセル化するため、 基本的に Insert と Update を分ける必要はありません。リポジトリが Save メソッドの内部でその後の責任を持ちます。
package models
type ShoppingCartRepository interface {
GetByUserID(userID uuid.UUID) (ShoppingCart, error)
Save(ShoppingCart) error
}
集約モデルの定義:
集約のルートはShoppingCartエンティティになります。集約はドメインロジックをカプセル化します。リポジトリと同じく models パッケージに定義します。以下が集約のインターフェース定義です。
package models
type ShoppingCart interface {
ID() uuid.UUID
AddItem(Product Product, Quantity int) error
}
改善されたポイント:
- リポジトリはデータベースの複雑性(挿入・更新の判断)を完全にカプセル化することができました。
- テーブル単位でリポジトリを作成する必要がなくなりました。そのため冗長なSQLのコーディングがなくなります。
- モデルをインターフェース化できたため、ドメインロジックをカプセル化できるようになりました。
- アプリケーション層からドメインロジックとデータベースの複雑性を排除できるようになりました。
DDDを採用することにより、ドメインロジック、データベースアクセス、アプリケーション層の責務が明確に分割されました。この改善により、アプリケーションの複雑性が低下し、認知負荷が下がるため、将来にわたって開発スピードが向上します。
リポジトリと集約の実装
集約とリポジトリを実装するパッケージは分けるべきか:
リポジトリとモデルの実装は同じパッケージに配置される必要があります。
リポジトリと集約モデルの実装を同一のパッケージ内に定義する理由:
リポジトリの役割はデータベースアクセスから集約の作成、保存に関する複雑性をカプセル化することでした。リポジトリは、集約をインスタンス化するために属性の初期化を行う必要があります。インターフェースに公開されない属性を参照・更新するため、同じパッケージ内に定義する必要があります。
たとえば、リポジトリのSaveメソッドの実装で考えてみましょう。以下の実装では、データベースに新規登録するか更新するかの判断をカプセル化しています。
package models
// ShoppingCartRepository を実装する構造体
var _ ShoppingCartRepository = (*shoppingCartRepository)(nil)
type shoppingCartRepository struct {}
// ShoppingCart を実装する構造体
var _ ShoppingCart = (*shoppingCart)(nil)
type shoppingCart struct {
ID uuid.UUID
// ...その他の属性
}
func (r *shoppingCartRepository) Save(model ShoppingCart) error {
instance := model.(*shoppingCart)
if instance.ID == uuid.Nil {
// ID が nil の場合は新規登録
return r.insert(instance)
}
return r.update(instance)
}
次に、リポジトリのGetByUserIDメソッドの実装を考えてみましょう。リポジトリはデータが存在しない場合は、空のショッピングカートを返すことができます。集約が存在しているかどうかに関わらず適切な集約のインスタンスが返されるので、リポジトリのインターフェースがシンプルになります。
package models
func (r *shoppingCartRepository) GetByUserID(userID uuid.UUID) (ShoppingCart, error) {
data, err := r.findByUserID(userID)
if errors.Is(err, sql.ErrNotFound) {
// データが存在しない場合は空のショッピングカート集約を返す
return newEmptyShoppingCart(), nil
}
if err != nil {
return nil, err
}
// すでに保存されたショッピングカートのデータを用いて集約を作成する
return newShoppngCart(data), nil
}
シンプルなインターフェースが望ましい理由
Deep Module とは、スタンフォード大学の教授が書いた A Philosophy of Software Design という本で説明されているソフトウェア設計に関する概念です。Deep Module は、表面上はシンプルで狭いインターフェースを持ちながら、内部的には豊富な機能性と複雑さを有するモジュールを指します。逆に、表面上は複雑なインターフェースを持ちながら、内部の機能が少ないモジュールは、Shallow Module と呼ばれます。Deep Module は認知負荷が低い・再利用性が高い・理解しやすい、という面で優れています。例えば go 言語の net/http パッケージはシンプルなインターフェースですが、HTTP サーバーを実装するための多くの機能や複雑性をカプセル化しており、簡単に使うことができます。OS のファイル IO も Deep Module の例です。ファイルの読み込みや書き込みは簡単ですが、多くの複雑性が隠蔽されています。Deep Module の概念は近年、多くの開発者から支持されている考え方です。
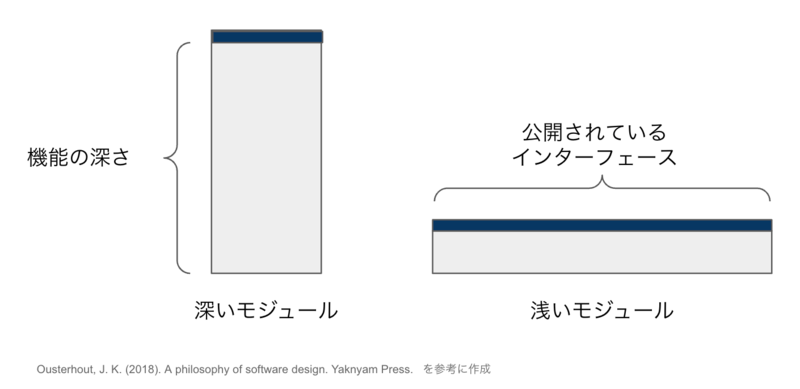
出典: ソフトウェア設計についてtwada技術顧問と話してみた 〜 A Philosophy of Software Design をベースに 〜
モデルの属性について
モデルをインターフェースとして定義すると、モデルの外部からは直接、実体である構造体の値を取得・更新できません。しかし、モデルの属性一つ一つに対してメソッドを定義するのは冗長な感じがします。
解決方法: 属性値用のバリューオブジェクトを定義する
ドメインモデルの公開属性を保持するための構造体を定義します。この構造体を介してモデルの属性の取得・更新を行います。
例:
以下は、ShoppingCart モデル(インターフェース)とプロパティ用の構造体の例です。モデルの外部から取得・更新できる属性を構造体にまとめているため、個別にインターフェースのメソッドを定義する必要はありません。
モデルのインターフェースの定義は以下の通りになります。Props()メソッドを通じてバリューオブジェクトにアクセスできます。
package models
type (
ShoppingCart interface {
ID() uuid.UUID
UserID() uuid.UUID
Items() []CartItem
Props() *ShoppingCartProps
}
)
属性値を保持するバリューオブジェクトの定義は以下の通りになります。
package models
type (
ShoppingCartProps struct {
Status ShoppingCartStatus
// その他のフィールド
}
)
ShoppingCart モデルの実装例は以下の通りになります。
package models
var _ ShoppingCart = (*shoppingCart)(nil)
type shoppingCart struct {
id uuid.UUID
props *ShoppingCartProps
userID string
version int64
items []CartItem
}
func (s *shoppingCart) ID() uuid.UUID {
return s.id
}
func (s *shoppingCart) Items() []CartItem {
return s.items
}
func (s *shoppingCart) UserID() uuid.UUID {
return s.userID
}
func (s *shoppingCart) Attrs() *ShoppingCartProps {
return s.props
}
この方法では、基本的にすべてのモデルにおいて XxxProps という構造体と Props() メソッドを定義します(構造体の名前は他の名前でも問題ありません。例えば、XxxAttrs や、XxxData 等)。
また、モデルに隠蔽したい属性(変更できない値など)は、バリューオブジェクトの構造体に含めないことで、インターフェースの背後に隠蔽できます。例えば、上記の例では ShoppingCart の userID は外部から変更できません。
ポイント:
- 簡単に属性を追加できる(構造体を変えるだけ)
- モデルの外部に公開する属性を限定できる
- 単なる構造体なので扱いやすい
インターフェースを用いない方法
モデルをインターフェースではなく構造体として定義する方法も紹介します。たとえば、エンティティフレームワークのentを利用する場合、以下のようにモデルを定義できます。構造体の外部からすべての属性にアクセスできるためフィールドごとにGetterやSetterを作る必要がありません。欠点は本来隠蔽すべき属性も公開されてしまうことです。意図と異なる形で構造体が使われないようにコードレビューで気をつける必要があります。
package models
import(
"ddd-example/ent"
)
// ShoppingCartはショッピングカートを表す
type ShoppingCart struct {
// ent で生成された構造体を直接埋め込む
*ent.ShoppingCart
// 以下に必要なフィールドや内部のモデルを定義する
items []CartItem
}
// NewShoppingCartは新しいショッピングカートを返す
func NewShoppingCart(e *ent.ShoppingCart) *ShoppingCart {
return &ShoppingCart{
ShoppingCart: e,
items: NewItems(e.Edges.CartItems)
}
}
// Items はショッピングカート内の商品一覧を返す
func (s *ShoppingCart) Items() []CartItem {
return s.items
}
まとめ
DDDの考え方に沿ってリポジトリと集約を実装することで、ドメインロジックをカプセル化し、認知負荷を低下させ、アプリケーションの保守性を高めることができます。
参考文献
- Martin Fowler, "Repository Pattern", https://martinfowler.com/eaaCatalog/repository.html
- Eric Evans, "Domain-Driven Design: Tackling Complexity in the Heart of Software", Addison-Wesley, 2003, https://fabiofumarola.github.io/nosql/readingMaterial/Evans03.pdf
- Domain Language, "DDD Reference", https://www.domainlanguage.com/ddd/reference/
- Vlad Khononov, "Learning Domain-Driven Design: Aligning Software Architecture and Business Strategy", https://www.oreilly.com/library/view/learning-domain-driven-design/9781098100124/
- John Ousterhout, "A Philosophy of Software Design", Yaknyam Press, 2018, https://www.amazon.co.jp/-/en/John-Ousterhout/dp/1732102201
- NTT Tech Blog, 「ソフトウェア設計についてtwada技術顧問と話してみた 〜 A Philosophy of Software Design をベースに 〜」, https://engineers.ntt.com/entry/2022/05/23/083118
- ent Framework, https://github.com/ent/ent
Discussion
素晴らしい記事をありがとうございます。
集約の設計に頭を悩ませていたので、とても参考になりました!!
一点質問させて下さい。
Repositoryに実装したGetByUserIDを利用して、UserIDに紐づいたショッピングカートの一覧情報をJSON形式で返すような実装を実現したいとします。クリーンアーキテクチャのようなアーキテクチャを採用していると、
みたいな流れになるかと思います。ドメインモデルをインターフェースで定義した際、上記ステップ3のようなインターフェースから構造体へのマッピング・変換はどのようにして実装するのが良いでしょうか?
ドメインモデルのインターフェースに
といった所謂Getterメソッドを定義する方法を思いつきましたが、Getterメソッドを定義してしまうと、モデルの知識が外部に流出してしまい、インターフェースとして定義したうま味が無くなってしまう気がしています。
私では他に良いアイデアが思い浮かばなかったので、質問させて頂きました🙇♂️
jundayoさん
ご質問いただき、ありがとうございます。
ご質問の点は確かに悩みどころですね。
とくに正解はないかと思いますが、記事に追記させていただきました。
少しでもご参考になりましたら幸いです。
濱田さん
お忙しい所、ご回答して頂きありがとうございます。
なるほど。プロパティ用の構造体を別途定義して、それを介してモデルの属性の取得等を行えば、確かに各属性ごとにメソッドを定義する必要はなくなりますし、公開したくない属性に関しても隠蔽できていますね!
私1人では思いつかなかったので大変勉強になります。是非参考にさせて頂きます🙇♂️