【Amazon Bedrock】Amazon S3 Vectors[プレビュー] が発表!ナレッジベースで使ってみた
はじめに
「Amazon S3 Vectors」がプレビューでリリースされました。
今までは、OpenSearchやAuroraをベクトルDBとして使用できていましたが、S3がベクトルDBとして使えるようになったことでベクトルのアップロード、保存、クエリのトータルコストを最大90%削減できる革新的なサービスになりそうです。
1. Amazon S3 Vectorsとは何か
1.1 基本概念とアーキテクチャ
Amazon S3 Vectorsは、大規模なベクトルデータセットを保存し、1秒未満のクエリパフォーマンスを提供する、ネイティブサポートを備えた初のクラウドオブジェクトストレージです。
ベクトルは、埋め込みモデルによって作成された非構造化データの数値表現です。例えば、画像、動画、音声、テキストなどの多様なデータ形式を、機械学習モデルが理解できる多次元の数値配列に変換します。これらのベクトルを効率的に保存・検索することで、意味的類似性に基づいた検索や推薦システムが実現できます。
1.2 新しいアーキテクチャ設計
S3 Vectorsは、従来のS3とは異なる専用のアーキテクチャを採用しています:
ベクトルバケット(Vector Bucket)
- AWSアカウントあたり最大10,000個のベクトルバケットを作成可能
- SSE-S3またはSSE-KMS暗号化に対応
- 従来のS3バケットとは独立した管理体系
ベクトルインデックス(Vector Index)
- 1つのベクトルバケットに最大10,000個のベクトルインデックスを作成可能
- 1つのベクトルインデックスに最大5,000万個のベクトルを保存可能
- コサイン距離またはユークリッド距離メトリックをサポート
メタデータ機能
- 各ベクトルにキーと値のペアとしてメタデータを添付可能
- 日付、カテゴリー、ユーザー設定などの条件でフィルタリング検索が可能
参照:
2. 従来のベクトルストレージとの比較
2.1 コスト面での圧倒的優位性
従来のソリューションの課題
Amazon Kendraの場合:
- リソース作成時点から「1時間あたり1.125〜1.4ドル」(月額810〜1,008ドル)の維持費が発生
OpenSearch Serverlessの場合:
- 「サーバーレス」と謳われているが、最低でも「1時間あたり0.24ドル」(月額172.8ドル)が必要
S3 Vectorsの料金モデル
バージニア北部リージョンでの料金体系:
| 項目 | 料金 | 単位 |
|---|---|---|
| ストレージ保管 | $0.06 | 1GB・1ヶ月 |
| PUTリクエスト | $0.20 | 1GB |
| GET、LIST等 | $0.055 | 1,000リクエスト |
| クエリリクエスト | $0.0025 | 1,000リクエスト |
| データ処理(最初の10万個) | $0.0040 | 1TB |
| データ処理(10万個超) | $0.0020 | 1TB |
具体的なコスト例
小規模(1,000万ベクトル):月額$11.38、大規模(4億ベクトル):月額$1,217.29
この料金体系により、従来のベクターストレージと比べて最大90%のコスト削減が可能となります。
2.2 スケーラビリティと信頼性
S3レベルの耐久性
- 99.999999999%(イレブンナイン)の耐久性
- データ容量に関する制限なし
- 数十億のベクトルに対応可能
自動最適化機能
- ベクトルの書き込み、更新、削除に伴い、S3 Vectorsが自動的にベクトルデータを最適化
- データセットの規模や変化に応じた価格対性能の最適化
2.3 機能面での制約
一方で、従来のベクトルストレージと比較して以下の制約があります:
機能制限
- 「ハイブリッド検索」「高度なフィルタリング」「ファセット検索」といった機能は持っていない
- 基本的なベクトル保存、クエリ、メタデータフィルタリングのみ
性能面の考慮
- 「1秒未満のクエリパフォーマンス」とあるため、100ミリ秒以下オーダーの処理速度を要求する用途には不向き
- リアルタイム検索が必要な場合は、OpenSearchとの組み合わせが推奨
3. 実際に使用してみた
今回は、「バージニア北部 us-east-1」で使用しました。
データソースのS3バケット作成
ベクトルDBに埋め込む用のS3バケットを作成しましょう。
また、そこに適当なPDF等をアップロードします。
今回は、自社の会社案内のPDFを置きました。

Bedrock ナレッジベース作成
ナレッジベースを作成していきます。

【ステップ 1:データソースを選択】はS3を選択します。

【ステップ 2:S3 の URI】は先ほどのS3バケットを選択します。

【ステップ 3:埋め込みモデル】はTitan Text Embeddings V2を選択します。
【ステップ 3:ベクトルデータベース 】はAmazon S3 Vectors - プレビューを選択します。

(既存のベクトルストアを使用」を選択して、予め作成したS3 Vectorsのベクトルインデックスを指定することも可能です)
また、ここではS3 Vectorsの「ベクトルバケットの暗号化方式」を選択することが可能です。
デフォルトではチェックボックスにチェックが入っておらず「SSE-S3」が選択されていますが、チェックを入れると「SSE-KMS」を選択することができます。
暗号化方式はベクトルバケット作成後に変更できませんので、SSE-KMSにしたい場合は必ずここで設定してください。
ナレッジベースの作成を押して作成しましょう。
Bedrock ナレッジベースのテスト
作成したら以下の項目でS3のデータソースをAmazon S3 Vectorsに同期しましょう。
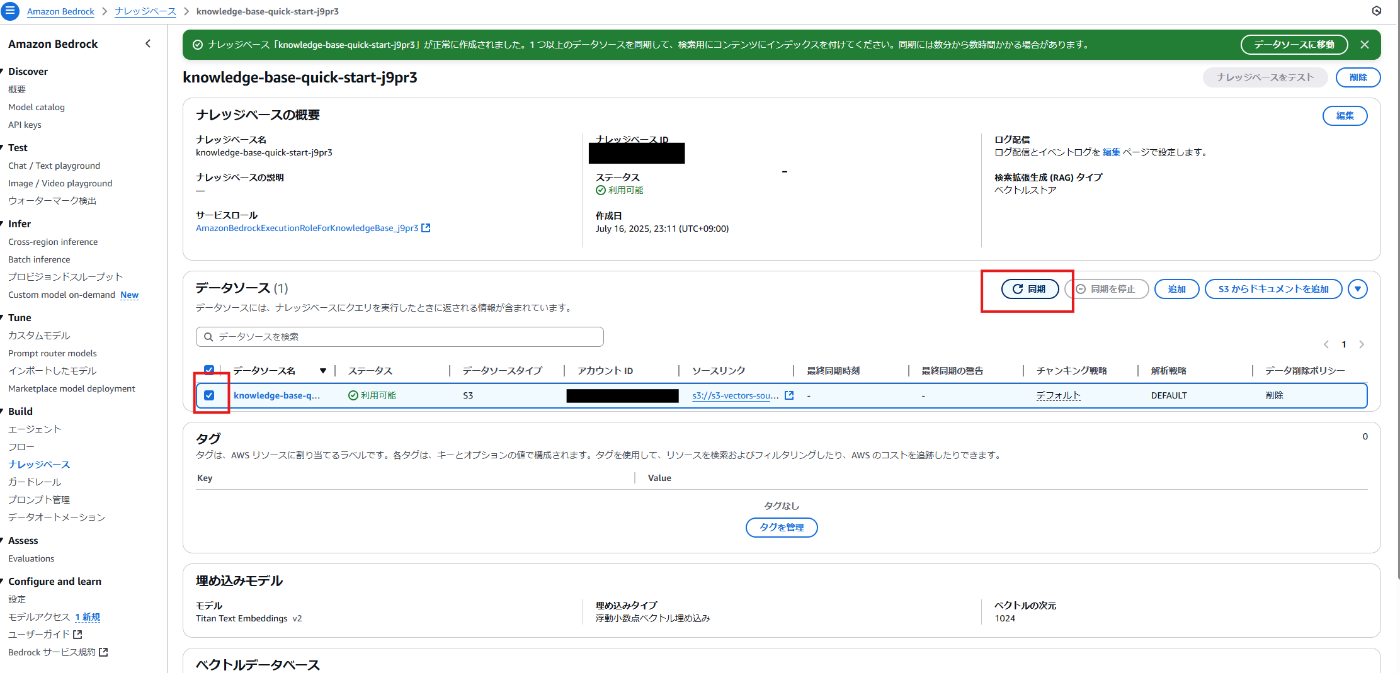
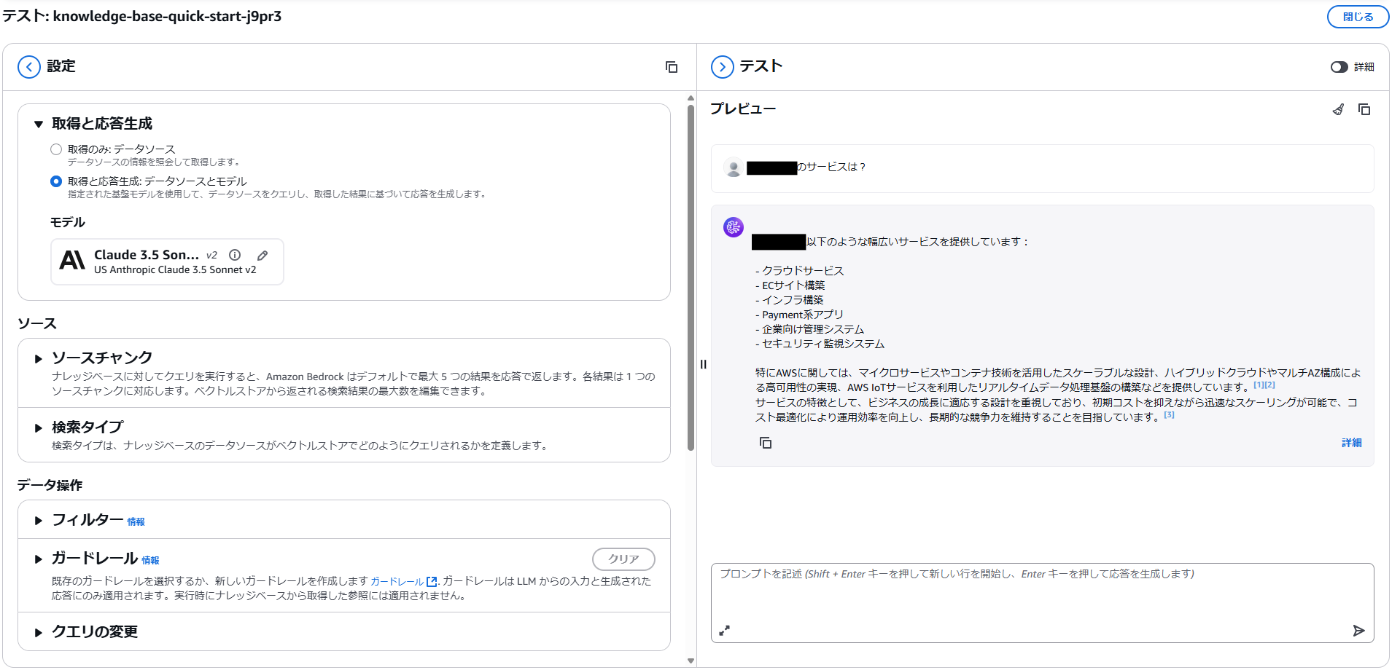
同期が完了したら右上のナレッジベースをテストを押し、テスト画面に移りましょう。
うまくRAGが使えていますね!
ちなみに作成したAmazon S3 Vectorsは以下から確認できます。
4. AWS サービスとの統合
4.1 Amazon Bedrock Knowledge Basesとの連携
RAGアプリケーションの低コスト化
S3 VectorsはAmazon Bedrock Knowledge Basesとネイティブに統合されており、コスト効率的なRAGアプリケーションの構築が可能です。
設定手順
-
Knowledge Base作成時の設定
- 埋め込みモデル:浮動小数点ベクトル埋め込みを選択
- ベクトルストア:Amazon S3 Vectorsを選択
- 暗号化:SSE-S3またはSSE-KMS
-
データソースの同期
- 従来のOpenSearchを使用したナレッジベースと同様の手順でデータソース同期を実行
-
精度評価
- Amazon BedrockのEvaluations機能を使用した精度評価では、有用性0.72という、OpenSearchと近い数値を記録
4.2 Amazon SageMaker Unified Studioとの統合
Amazon SageMaker Unified Studio内でS3 Vectorsを使用したナレッジベースの作成・管理が可能です。これにより、データとAIの統合開発環境において、チーム間でのスケーラブルで共有可能なAI開発環境を構築できます。
4.3 Amazon OpenSearch Serviceとの連携
階層化戦略
頻繁にクエリされないベクトルをS3 Vectorsに保存し、需要が増加したり、リアルタイム検索機能をサポートしたりする場合に、OpenSearchに迅速に移行できます。
エクスポート機能
- S3 VectorsからOpenSearch Serverlessへのワンクリックエクスポート
- 段階的な性能向上とコスト最適化の実現
OpenSearch内でのS3 Vectorsエンジン使用
- OpenSearchマネージドクラスタで、従来のElasticSearch互換エンジンの代わりにS3 Vectorsを検索エンジン&データストレージとして使用可能
5. ユースケース
大規模データ処理
- ペタバイト規模のビデオアーカイブで類似シーンを検索
- 何百万もの医療画像を含む診断コレクションでまれなパターンを検出
セマンティック検索
- 企業内文書の意味的検索
- 製品カタログの類似商品検索
- 研究論文の関連文献検索
AIエージェントとRAGアプリケーション
- 大規模なベクトルデータセットを使用してAIエージェントの記憶と文脈を向上
- カスタマーサポートボットの知識ベース
- 個人化された推薦システム
6. 利用開始方法とベストプラクティス
6.1 利用可能リージョン
プレビュー時点では、バージニア北部(us-east-1)、オハイオ(us-east-2)、オレゴン(us-west-2)、シドニー(ap-southeast-2)、フランクフルト(eu-central-1)でのみ利用可能です。
6.2 推奨される導入シナリオ
S3 Vectorsが最適な場面
- PoCや検証など、小規模なRAGシステムをコストを抑えて利用したい場合
- 大容量のデータを使ってRAGやベクトル検索のシステムを構築する際に、性能面よりもコストを重視したい場合
OpenSearchとの使い分け
- 高QPS(クエリ毎秒)、低レイテンシのベクトル検索が必要なリアルタイムアプリケーションにはOpenSearchを使用
- 大規模で長期的なベクトルデータで、インメモリベクトルデータベースの高スループット性能が不要な場合にS3 Vectorsを使用
6.3 他のベクトルDBと比べて劣る点
S3 VectorsはベクトルDBとして基本的な「ベクトルの保存 (追加)」「ベクトルデータのクエリ」「メタデータによるフィルタリング」といった機能のみを備えています。
OpenSearchのような「ハイブリッド検索」「高度なフィルタリング」「ファセット検索」といった機能は持っていません。
7. 今後の展望と課題
7.1 技術的な発展方向
機能拡張の可能性
- バイナリベクトル埋め込みのサポート
- ハイブリッド検索機能の追加
- より高度なフィルタリング機能
性能向上
- クエリ応答時間の短縮
- 大規模データセットでの最適化
- 並列処理の強化
7.2 エコシステムへの影響
AI開発の民主化
- 高額なOpenSearchやAuroraは個人利用には手が出しづらかったが、ついにナレッジベースの民主化が到来
- スタートアップや中小企業でのAIアプリケーション開発促進
競合他社への影響
- クラウドベンダー間でのベクトルストレージ競争の激化
- 料金体系の見直しとサービス向上
7.3 課題と制約
現在の制約
- プレビュー段階での機能制限
- 限定的なリージョン対応 (2025-07-15)
- バージニア北部 (us-east-1)
- オハイオ (us-east-2)
- オレゴン (us-west-2)
- シドニー (ap-southeast-2)
- フランクフルト (eu-central-1)
- IaCの未対応
8. まとめ
Bedrockのナレッジベースを使用する上でネックになっていたことの一つに「コスト」があると思います。
今回のAmazon S3 Vectorsそのコストが大幅に改善されているので、コスト重視やPoCには良いソリューションになるのではないかと思います。
機能面では、ハイブリッド検索などもまだ使えないようなので、コストは低いが実用面ではまだ不安な箇所がありそうですが、今後の進展が楽しみです。
参考
https://qiita.com/Syoitu/items/4ef4f2f0b1fe71ace919 https://dev.classmethod.jp/articles/amazon-s3-vectors-preview-release/ https://zenn.dev/kun432/scraps/c09f7044efae2a https://aws.amazon.com/jp/blogs/aws/introducing-amazon-s3-vectors-first-cloud-storage-with-native-vector-support-at-scale/
Discussion