「Amazon S3 Vectors」を試す
公式ブログ
Diaによる要約
ウチがめっちゃわかりやすく説明するね!
Amazon S3 Vectorsっていうのは、AIとかで使う「ベクトル」っていうデータを、超お得に・簡単に・大量に保存&検索できる新しいクラウドサービスなんだよ。しかも、今までよりコストが最大90%も安くなるって、マジでウケるでしょ!
そもそも「ベクトル」って何?
AIとかで画像とか文章とかを「数字のかたまり(ベクトル)」に変換して、似てるもの同士を探したりするんだよね。例えば、「宇宙の冒険映画」って言ったら、スターウォーズとかがパッと出てくる感じ!
S3 Vectorsのすごいとこ
- 新しい 「ベクトルバケット」 っていう入れ物を作って、その中に「ベクトルインデックス」っていう箱をいっぱい作れるの。1バケットに1万個までインデックス作れるし、1インデックスに何千万個もベクトル入れられるから、スケールやばい。
- メタデータ(例えばジャンルとか日付とか)も一緒に保存できるから、あとで「このジャンルだけ検索!」みたいなことも余裕。
- 自動で最適化してくれるから、データ増えてもコスパ最強のまま!
使い方も超シンプル
- S3のコンソールで「ベクトルバケット」作る(名前つけて暗号化の設定するだけ)。
- その中に「ベクトルインデックス」作る(ベクトルの次元数とか決める)。
- あとはPythonとかCLIで、ベクトルデータをどんどん入れていくだけ!
どんなときに使うの?
- 画像・動画・音声・文章とか、いろんなデータをAIで分析したいとき
- 似てるデータを一瞬で探したいとき(セマンティック検索とか)
- レコメンドとか、AIチャットの「記憶」みたいなやつ作りたいとき
他のAWSサービスとも連携バッチリ
- Amazon Bedrock や SageMaker と組み合わせて、RAG(AIが知識を引っ張ってくるやつ)アプリも簡単に作れる!
- OpenSearch と連携して、よく使うデータは超高速検索、あんまり使わないデータはS3 Vectorsでコスパ重視、みたいな使い分けもできる!
どこで使えるの?
今はアメリカとかフランクフルト、シドニーのAWSリージョンでプレビュー中だよ!
マジで、AI使ったアプリ作りたい人とか、データ大量に持ってる人にはテンション上がる新サービスだし、ウチも使ってみたくなるやつだわ!質問あったら何でも聞いてね!
かなり要約されていたけど、公式によるとプレビューで使えるのは以下。
Amazon S3 Vectors および Amazon Bedrock、Amazon OpenSearch Service、Amazon SageMaker との統合機能は、米国東部(バージニア北部)、米国東部(オハイオ)、米国西部(オレゴン)、ヨーロッパ(フランクフルト)、アジア太平洋(シドニー)の各リージョンでプレビュー版として利用可能です。
公式記事に従って、us-east-1(バージニア北部)で試してみる。マネジメントコンソールからS3メニューアクセスすると「ベクトルバケット」が見える。
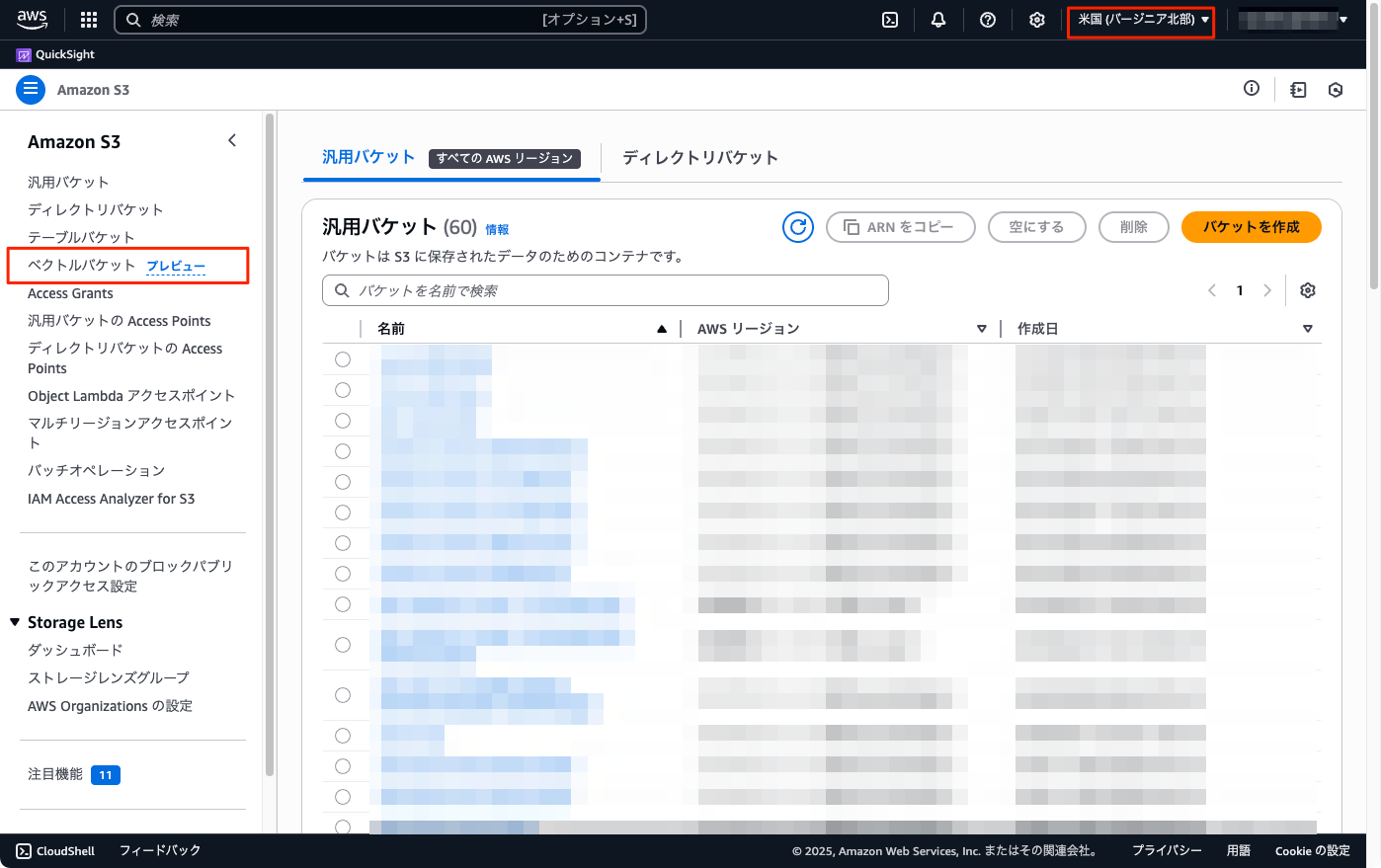
「ベクトルバケットを作成」

バケット名を入力して作成。暗号化はデフォルトのままとした。

作成されたバケット名をクリック。
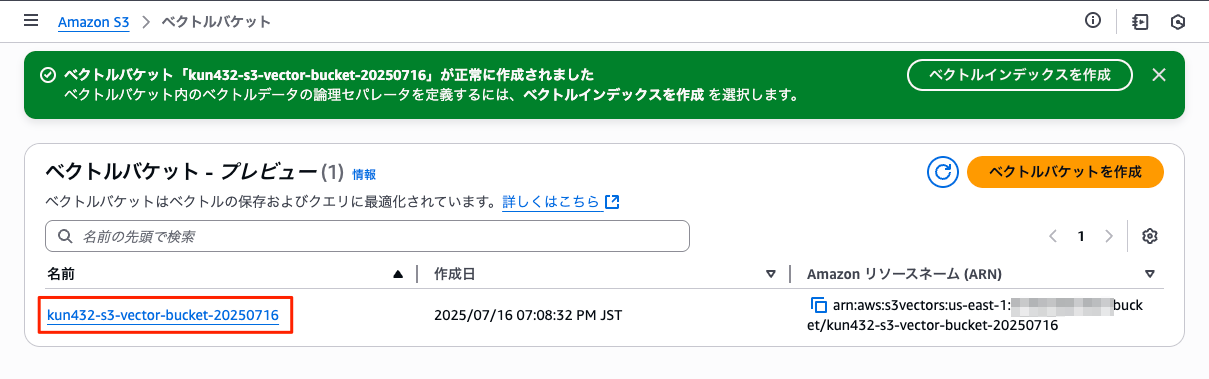
なるほど、バケット内にベクトルインデックスを作成すると。「ベクトルインデックスを作成」をクリック。
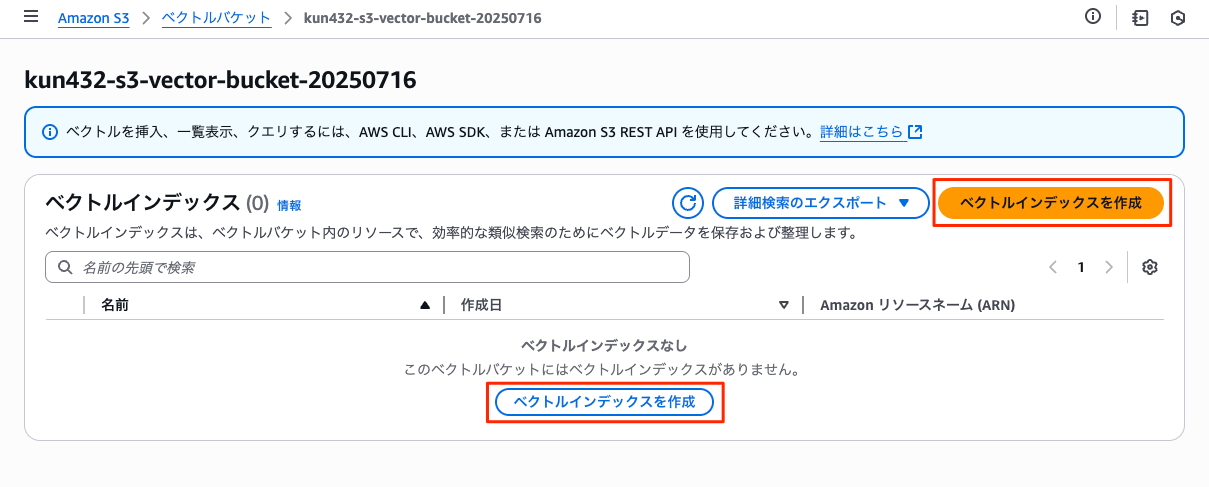
ベクトルインデックス名、次元数、距離メトリックをそれぞれ設定して作成。次元数については、OpenAI EmbeddingなどBedrock外のモデルでも使えるかどうかを確認したいので 1536 にした。あとメタデータでフィルタ設定もできそうだけど今回はスキップ。
インデックスが作成された

ではここからローカルのMacで。Pythonでベクトルデータの登録・検索を試してみる。
uvでプロジェクト作成
uv init -p 3.12 s3-vector-work && cd $_
パッケージ追加
uv add boto3 openai
(snip)
+ boto3==1.39.6
(snip)
+ openai==1.96.1
(snip)
ではまずベクトルデータを登録。
import boto3
import json
from openai import OpenAI
texts = [
"木の温もりあふれるブックカフェで、自家焙煎の深煎りコーヒーと季節のタルトを味わいながら、窓辺から路面電車をのんびり眺められるんだ。",
"庭にハーブが茂るガーデンカフェでは、ハンドドリップの浅煎りとフレッシュハーブティーが選べて、小鳥のさえずりが BGM 代わりになるよ。",
"港直送の鯖を炙りしめ鯖にしてくれる専門店、皮目の香ばしさと酢のきりりとした酸味が口いっぱいに広がるんだ。",
"カウンター割烹の金目鯛の煮付けは、甘辛ダレが骨の隅々まで染みていて、白ご飯が思わずおかわり必至だよね。",
"昔ながらの屋台ラーメンは鶏ガラの澄んだ醤油スープと細ちぢれ麺が相性抜群で、深夜の胃袋にしみるんだ。",
"真っ白な豚骨スープに焦がしニンニク油をひと垂らしした濃厚ラーメン、替え玉が無料でつい無限ループしてしまうよ。",
"スリランカ式の混ぜて食べるプレートカレーでは、15種類のスパイスが複雑に重なって食べ進めるほど香りが花開くんだ。",
"野菜がごろごろ入った欧風ビーフカレーは、赤ワインとバターのコクが効いたシャバっとルウで後を引くよ。",
"薪窯ナポリピッツァのマルゲリータは、モッツァレラがびよーんと伸びて焼き立てを頬張る瞬間がたまらない。",
"4種のチーズをのせたクアトロフォルマッジに蜂蜜を垂らすスタイルが人気で、塩気と甘さのコントラストがクセになるんだ。",
"しゅわっととろけるバスクチーズケーキ専門店、表面の香ばしい焦げと濃厚クリーミーな中身のギャップが病みつきになるよ。",
"パリパリの薄皮たい焼きは羽根つきで端っこまで香ばしく、黒あんか白あんか毎回真剣に迷っちゃうんだよね。",
]
openai_client = OpenAI()
def get_embedding(text: str)->list[float]:
return openai_client.embeddings.create(
input=[text],
model="text-embedding-3-small"
).data[0].embedding
embeddings = [get_embedding(text) for text in texts]
BUCKET_NAME = "kun432-s3-vector-bucket-20250716"
INDEX_NAME = "my-s3-vector-index"
REGION = "us-east-1"
s3vectors = boto3.client('s3vectors', region_name=REGION)
result = s3vectors.put_vectors(
vectorBucketName=BUCKET_NAME,
indexName=INDEX_NAME,
vectors=[
{
"key": str(idx),
"data": {
"float32": embedding
},
"metadata": {
"id": str(idx),
"source_text": text
}
}
for idx, (text, embedding) in enumerate(zip(texts, embeddings), start=1)
]
)
print(json.dumps(result, indent=2, ensure_ascii=False))
実行。
OPENAI_API_KEY=XXXXXXXXXX
uv run create_index.py
200で返ってきたらOKかな?
{
"ResponseMetadata": {
"RequestId": "046866f0-a6f1-4952-ac29-500a85bb51f7",
"HostId": "",
"HTTPStatusCode": 200,
"HTTPHeaders": {
"date": "Wed, 16 Jul 2025 10:56:42 GMT",
"content-type": "application/json",
"content-length": "2",
"connection": "keep-alive",
"x-amz-request-id": "046866f0-a6f1-4952-ac29-500a85bb51f7",
"access-control-allow-origin": "*",
"vary": "origin, access-control-request-method, access-control-request-headers",
"access-control-expose-headers": "*"
},
"RetryAttempts": 0
}
}
次に検索
import boto3
import json
from openai import OpenAI
openai_client = OpenAI()
def get_embedding(text: str)->list[float]:
return openai_client.embeddings.create(
input=[text],
model="text-embedding-3-small"
).data[0].embedding
input_text = "中華そばが食べたい"
embedding = get_embedding(input_text)
BUCKET_NAME = "kun432-s3-vector-bucket-20250716"
INDEX_NAME = "my-s3-vector-index"
REGION = "us-east-1"
s3vectors = boto3.client('s3vectors', region_name=REGION)
query = s3vectors.query_vectors( vectorBucketName=BUCKET_NAME,
indexName=INDEX_NAME,
queryVector={"float32": embedding},
topK=5,
returnDistance=True,
returnMetadata=True
)
results = query["vectors"]
print(json.dumps(results, indent=2, ensure_ascii=False))
実行
uv run search.py
{
"key": "5",
"metadata": {
"source_text": "昔ながらの屋台ラーメンは鶏ガラの澄んだ醤油スープと細ちぢれ麺が相性抜群で、深夜の胃袋にしみるんだ。",
"id": "5"
},
"distance": 0.626266360282898
},
{
"key": "6",
"metadata": {
"id": "6",
"source_text": "真っ白な豚骨スープに焦がしニンニク油をひと垂らしした濃厚ラーメン、替え玉が無料でつい無限ループしてしまうよ。"
},
"distance": 0.639498233795166
},
{
"key": "8",
"metadata": {
"source_text": "野菜がごろごろ入った欧風ビーフカレーは、赤ワインとバターのコクが効いたシャバっとルウで後を引くよ。",
"id": "8"
},
"distance": 0.6542491912841797
},
{
"key": "4",
"metadata": {
"id": "4",
"source_text": "カウンター割烹の金目鯛の煮付けは、甘辛ダレが骨の隅々まで染みていて、白ご飯が思わずおかわり必至だよね。"
},
"distance": 0.6681203842163086
},
{
"key": "3",
"metadata": {
"id": "3",
"source_text": "港直送の鯖を炙りしめ鯖にしてくれる専門店、皮目の香ばしさと酢のきりりとした酸味が口いっぱいに広がるんだ。"
},
"distance": 0.6772681474685669
}
]
別のクエリでも
(snip)
input_text = "お茶したい"
(snip)
[
{
"key": "2",
"metadata": {
"id": "2",
"source_text": "庭にハーブが茂るガーデンカフェでは、ハンドドリップの浅煎りとフレッシュハーブティーが選べて、小鳥のさえずりが BGM 代わりになるよ。"
},
"distance": 0.6224315166473389
},
{
"key": "1",
"metadata": {
"id": "1",
"source_text": "木の温もりあふれるブックカフェで、自家焙煎の深煎りコーヒーと季節のタルトを味わいながら、窓辺から路面電車をのんびり眺められるんだ。"
},
"distance": 0.6707726716995239
},
{
"key": "4",
"metadata": {
"id": "4",
"source_text": "カウンター割烹の金目鯛の煮付けは、甘辛ダレが骨の隅々まで染みていて、白ご飯が思わずおかわり必至だよね。"
},
"distance": 0.7615475654602051
},
{
"key": "6",
"metadata": {
"source_text": "真っ白な豚骨スープに焦がしニンニク油をひと垂らしした濃厚ラーメン、替え玉が無料でつい無限ループしてしまうよ。",
"id": "6"
},
"distance": 0.7665367126464844
},
{
"key": "11",
"metadata": {
"source_text": "しゅわっととろけるバスクチーズケーキ専門店、表面の香ばしい焦げと濃厚クリーミーな中身のギャップが病みつきになるよ。",
"id": "11"
},
"distance": 0.7694482803344727
}
]
その他
- Bedrockのナレッジベースとして使える
- OpenSearch Serviceにエクスポートできる
今回はEmbeddingに外部モデルが使えることを確認したけども、Bedrock / SageMaker / OpenSearch Serviceあたりと連携して使うなら、BedrockのEmbeddingモデルを使うほうが当然メリットはありそう。(ナレッジベースはBedrockのモデルである必要があるはずだし)
あと、AWS CLIでも操作はできるようだけど、S3 Vector専用のCLIが出来ているっぽい。
バケット・インデックスの作成等はAWS CLIでやって、インデックスにデータ登録したり検索したり、は s3vectors-embed-cli という感じで棲み分ける感じかな?と思ったけど、AWS CLIをみてみるとある程度のことはできそう。s3vectors-embed-cli の方はファイルをそのままインデックスに登録したり、みたいなよりインデックスを扱いやすいもの、という感じみたい。
あと、ベクトルバケットはS3といえどオブジェクトストレージ的な使い方ができるわけではなさそうで、aws s3 lsでバケットは表示されず。代わりにaws s3vectorsというサブコマンドができていた。
PAGER=cat aws s3vectors help
S3VECTORS() S3VECTORS()
NAME
s3vectors -
DESCRIPTION
Amazon S3 vector buckets are a bucket type to store and search vectors
with sub-second search times. They are designed to provide dedicated
API operations for you to interact with vectors to do similarity
search. Within a vector bucket, you use a vector index to organize and
logically group your vector data. When you make a write or read
request, you direct it to a single vector index. You store your vector
data as vectors. A vector contains a key (a name that you assign), a
multi-dimensional vector, and, optionally, metadata that describes a
vector. The key uniquely identifies the vector in a vector index.
AVAILABLE COMMANDS
o create-index
o create-vector-bucket
o delete-index
o delete-vector-bucket
o delete-vector-bucket-policy
o delete-vectors
o get-index
o get-vector-bucket
o get-vector-bucket-policy
o get-vectors
o help
o list-indexes
o list-vector-buckets
o list-vectors
o put-vector-bucket-policy
o put-vectors
o query-vectors
S3VECTORS()
まとめ
お手軽に使えてよいのではないかな?コスト的にもS3ベースなら多分安いだろうと思うし(調べてないので知らんけど)。ただ、S3という名前がつきつつも、一般的なS3でできることのイメージとは違うと感じる。
同感。
やるならDynamoDBじゃないの?感があるが、AWSの既存でベクトル検索が使えるソリューションは正直高いなぁと思うので、お手軽にお安く使える選択肢が増えたのは歓迎。
ベクトルバケットやベクトルインデックスを作成するインタフェースがマネージメントコンソールに見当たらないのだが・・・今のところCLIだけかな
# インデックス削除
aws s3vectors delete-index \
--vector-bucket-name kun432-s3-vector-bucket-20250716 \
--index-name my-s3-vector-index \
--region us-east-1
# バケット削除
aws s3vectors delete-vector-bucket \
--vector-bucket-name kun432-s3-vector-bucket-20250716 \
--region us-east-1