これからChatGPT(AI)と共存するために知っておくべきこと ChatGPTの仕組みを知る
3日目は 元船員エンジニアのyukimasaさんによる
Tocbot を使用し Next.js で構築したブログに目次を追加するでした。
導入
2022年11月にChatGPTが公開され、早くも1年が経過しました。この1年でAIの進化が飛躍的で、AIに関する話題が絶えることなく広まりました。画像、動画、音声までを生成できるようになった進展には驚きを禁じ得ませんね。
AIが世間に広く浸透する一方で、その進化の速さが今年は特に目立ちました。個人的には、AIの進化がインターネットやスマートフォンの登場時と同様に革命的であると感じています。そして、これらの技術が我々の生活に一層馴染んでいくことは間違いありません。
しかし、AIが我々の日常に浸透する一方で、どうやってAIと共存していくかを考えることは重要です。
AIが人間に取って代わるといった議論がよく見られますが、実際には人間とAIがそれぞれ得意とする領域が異なるため、対立ではなく共存が望ましいのです。
私自身、まだAIと完全に共存できていないと感じています。質問に答えてもらったり、文章を添削してもらったりするくらいしか活用していません。しかし、AIと協力して仕事を進めることが社会貢献に繋がると信じています。
またここで出すAIとは基本的には生成AIの事です。生成AIについては後述します。
今回の記事では、アドベントカレンダーを通じてAIについて深く理解し、その可能性を広く知ってもらうことを目指しています。
解説というよりかはどちらかというと自分がわからない箇所を調べた共有していきます。
そのため間違っている箇所もあると思います。その点だけご了承下さい。
※良ければコメントください!
全体の流れ
以下の流れで記事を作っています。記事を出す予定です。
- ChatGPTについての基本的な理解
- ChatGPTとのやりとりをイメージ出来るようになろう
- 生成AIが得意とする領域を知ろう
- なんとなくイメージが出来たら人間とAIの得意な領域を知ろう
- 活用事例
- AIが得意な領域を理解したら、具体的にどういった事を任せられるのかを知ろう
- ChatGPTの扱い方を知ろう
- 自分が求めている成果物を出力してもらうために、何を気にすればいいのかを知ろう
- ひらたく言えばプロンプトの話
参考文献
- 人工知能学会 AIマップ日本語版
- 無料ですが、図も多くわかりやすいです。AIの事で知りたいキーワードを掴むのにおすすめ
-
生成AI時代の「超」仕事術大全
- 活用事例を知りたくて購入しました
ChatGPTについて知る
本記事のゴール
生成AIとの共存を考える上で、ChatGPTについて基本的な理解を持つことは重要です。
この記事では、生成AI全体に言及するのではなく、ChatGPTを通して、生成AIの一般的な特性をさらっと理解しておきましょう。
ChatGPTってなに?
ChatGPTはOpenAI社が提供する対話型の生成AIサービスです。ユーザーが入力した文章に対して、自然な言葉で回答を生成します。英語や日本語など、様々な言語に対応しています。
ChatGPTの仕組みは、大規模言語モデル(LLM)に基づいています。LLMはインターネット上の膨大なデータから言語のパターンや文法を学習することで、言語の理解と適切な回答生成を可能にします。
ここでは良く聞く単語が2つ出てきました。
それは生成AIとLLMの2つです。
この2点について深掘りしていきましょう。
生成AIとは?
生成AIがわからなかったのでBingAIに聞きました。
生成AI(Generative AI)とは、人工知能の一種で、自動的に新しいデータを生成することができる技術です。
生成AIは、ディープラーニングの一種であり、大量のデータを学習することで、新しいデータを生成することができます。生成AIは、画像、音声、文章など、さまざまな種類のデータを生成することができます。
学習したデータを基に画像・音楽・文章などあらゆる種類のデータを生成するAIって事ですね。
次に従来のAIと生成AIの違いが気になったので調べました。
従来のAIと生成AIの違い
生成AIとしつこく出てきますが、そもそも今までAIと何が違うんだ?ってなったと思います。
今度はChatGPTに聞いてみました
| 従来のAI | 生成AI | |
|---|---|---|
| タスクのアプローチ | 事前に考えたルールや統計を使って仕事をする | データを使って新しいものを生成することに重点を置く |
| 学習の種類 | 例えば、先生に教わるような学び方や、自分で学ぶ | データを見て、新しいことを学ぶ |
| 柔軟性と対応範囲 | 特定のタスクに向いている | 色々な仕事やデータに対応できる |
| 人間の介入 | 人がルールを作ったり、データを詳しく見たりする | 人の手をあまり使わず、データから学んで仕事をする |
| 学習メカニズム | ルールや統計の考え方 | データを見て、そこからパターンや構造を勉強する |
| 例 | 手書き数字を認識したり、顔を見分けたりする | 言葉を自動で作ったり、新しい画像を生成する、音を作ったりする |
出力結果からわかったこと
従来のAI
- 決められたルールに基づいて自動化が可能
- そのためには自動化したい対象の学習データを用意する必要がある
- データを用意しないといけないため人の介入が必要
生成AI
- さまざまなデータから学習して、コンテンツの生成する事が可能
- フォーマットが事前に決まっていないため、人の介入は不要
どちらも情報の特定や推測が出来るのは同じ。成果物の目的が異なることがわかりました。
具体的に生成AIを使ったサービスって何があるんだ?というのはそれだけで1記事できそうなので、別にしたいと思います。
LLMとは?
この単語も良くみますね。
BingAIに聞いてみました。
LLM(Large Language Model)は、自然言語処理(NLP)の一部である人工知能(AI)の一種です。以下にその主な特徴を箇条書きで示します:
大規模なデータセット:LLMは、ウェブページ、書籍、記事など、インターネット上の大量のテキストデータから学習します。
・文脈理解:LLMは、入力されたテキストの文脈を理解し、それに基づいて適切な応答を生成します。
・多様なタスク:LLMは、質問応答、文章生成、文章の要約、翻訳など、さまざまなタスクをこなすことができます。
・ゼロショット学習:LLMは、訓練データセットに存在しない新しいタスクでも、そのタスクを解決するための一般的な知識を利用して対応することができます。
・限定的な知識:LLMの知識は訓練データに基づいており、訓練後に得られた情報については知らない場合があります。
これらの特徴により、LLMは非常に強力なツールとなりますが、その使用には注意が必要です。特に、偏見のあるデータから学習した場合、その偏見を反映する可能性があります。また、ユーザーのプライバシーを保護するため、個人情報を共有しないようにすることが重要です。
ここからわかった事は
- LLMは人口知能の一種である
- 多種多様なデータから学習している
- ただし情報の精査をしているわけではない
- そのため出力結果が必ず正しい訳では無い。最終的な判断は人間がする必要がある
- 答えがわからなくても、学習したデータや知識を利用して予測して処理する出来る
- ゼロショット学習
なんとなくイメージが湧きましたかね?
ゼロショット学習の処理があるため、質問に対してChatGPTはほぼ何かしらの答え(正否問わず)を出そうとしているのかなと思います。
ChatGPTとどんなやりとりをしているのか
最後に本記事のゴールであるChatGPTとのやりとりを見ていきましょう。
最後にChatGPTを使用している時に内部的に何が起きているのかを調べました。
イメージとしてはこんな感じかなと思います。
※厳密には違うかもしれないですが、ふんわり理解で!
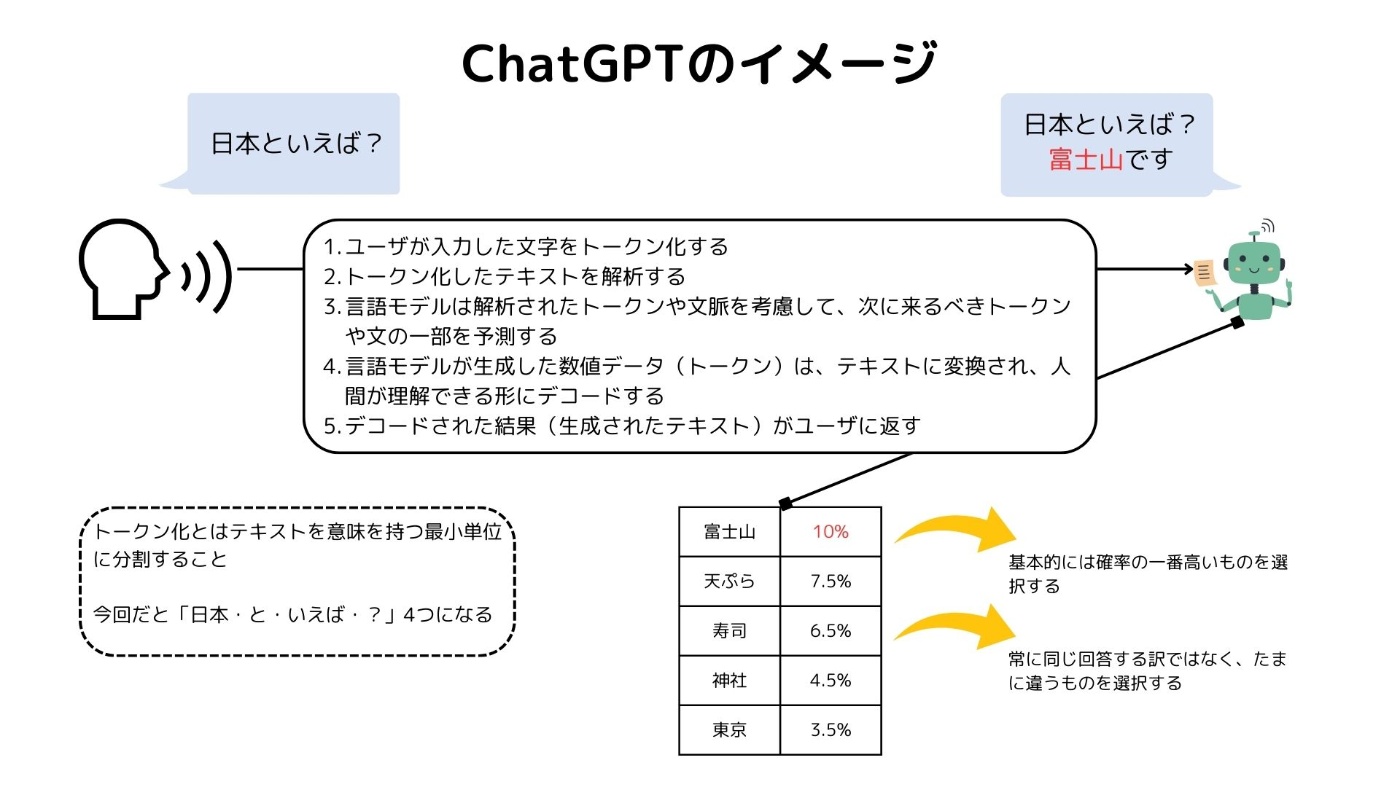
言語処理の仕組みを詳しく知りたい方はこちらの動画を参考にしてください。
最後に
ここまで読んで頂いた方なら、ChatGPTとのやりとりで何が起きているかを理解出来たかなと思います。
生成AIの活用方法がわからない方はまず得意とする領域・苦手とする領域を知る必要があります。
といった感じで次回は「生成AIが得意とする領域を知ろう」というテーマです!
Discussion