BigQueryのJSON型データの操作とテキスト検索の高速化を検証してみた
AWS と Google Cloud で構築したデータ基盤の開発・運用に携わっているデータエンジニアです。5 年くらい携わっていて、この業務がきっかけで Google Cloud が好きになりました。
前回の記事(BigQuery で非構造化データを扱ってみませんか?)で非構造化データが格納されている Cloud Storage をオブジェクトテーブルとして連携しました。
そこで非構造化データに設定したカスタムメタデータを参照する際に配列型のデータや構造体型のデータの操作が必要ということがわかりましたが、初見だと癖があったりで操作が難しく感じたので今回はこちらをまとめたいと思います。
さらに JSON 型のデータ操作やテキストの検索が高速化できる Search Index と SEARCH 関数についても今回想定しているユースケースでは便利なので合わせてまとめていきます。
Overview
BigQuery で特殊なデータ型を扱う & テキストデータの検索高速化に関する検証
- 前回の記事のように非構造化データのカスタムメタデータに機械学習 API 等で得られた Json 形式のデータを格納するようなケースは多々あると思います
- 柔軟に検索するにはこのカスタムメタデータを扱う必要でてきて、ARRAY 型 / STRUCT 型の操作が必須となります
- Json 形式のデータを文字列で格納するというケースも想定されます、BigQuery では JSON 型というデータ型が用意されており操作が容易になっています
- BigQuery は従来テキストを高速に検索する術がありませんでしたが、Search Index と SEARCH 関数を利用することで長い文字列の中からのキーワードによる検索が高速にできます
キーワード
特殊なデータ型の扱い
ここでは ARRAY 型 / STRUCT 型 / JSON 型についてまとめます。
豊富なデータ型が用意されていて利用の幅が広がりそうです。
1. カスタムメタデータの登録
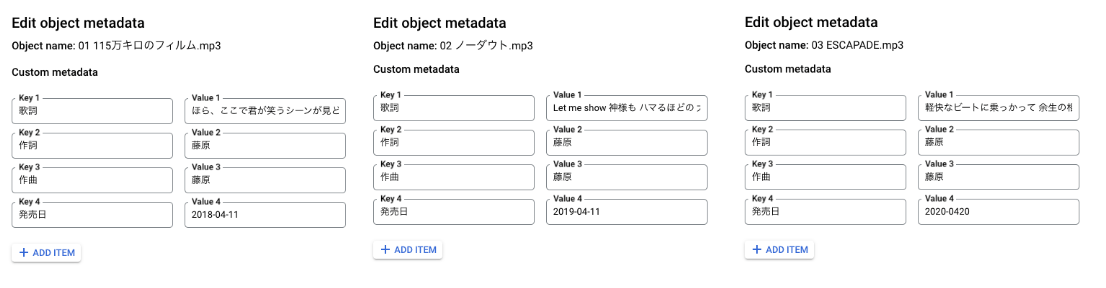
前回の記事では歌詞だけ設定しましたが、加えて「作詞」「作曲」「発売日」を適当に設定します。
コマンドでの実行は下記です。
gcloud storage objects update \
"gs://hayashi-private/music/01 115万キロのフィルム.mp3" \
--custom-metadata='作詞'='藤原'
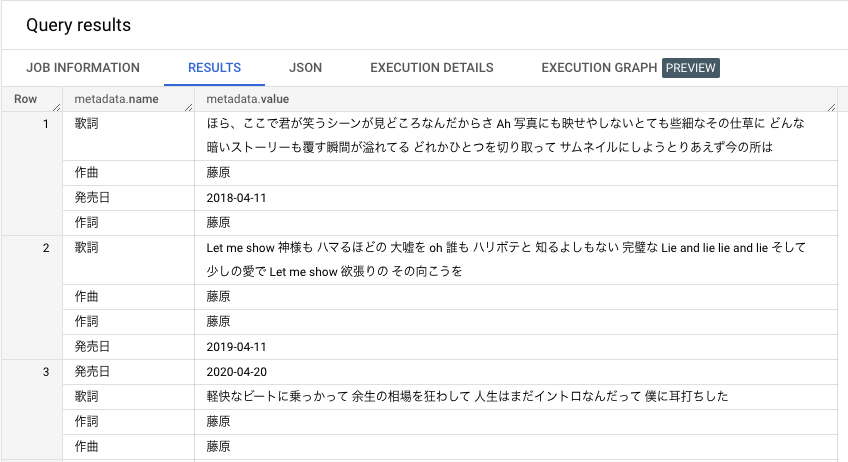
データの見え方はこちらです。1 行の中に複数の Key-Value が含まれている形です。(設定している値はダミーです)
2. 配列型データへのアクセス
データ型の確認
この metadata のデータ型を調べてみます。
SELECT
column_name
, is_nullable
, data_type
FROM `unstructured_data.INFORMATION_SCHEMA.COLUMNS`
WHERE table_name='music';
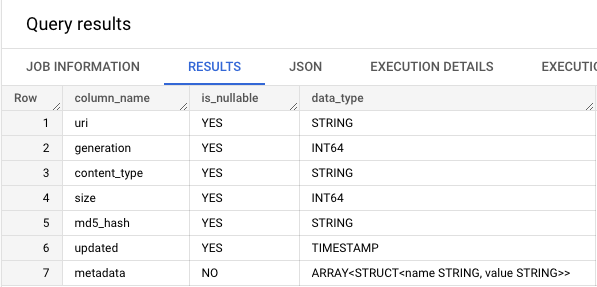
こちらから metadata は STRUCT 型が ARRAY 型に格納されていることがわかりました。
インデックスの指定
ARRAY 型の詳細なアクセスにはインデックス指定が必要で、指定の仕方としては OFFSET / ORDINAL があるようです。
SELECT
uri
, metadata[OFFSET(0)]
, metadata[ORDINAL(1)]
FROM `unstructured_data.music`
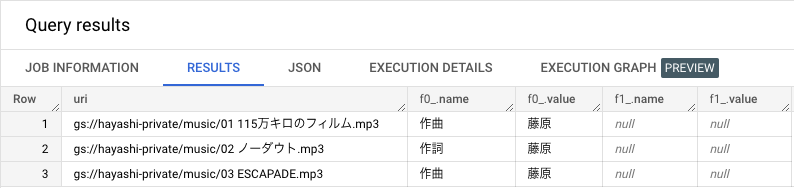
1 回目と 2 回目の実行が下記になります。配列といつつの順序の固定はなさそうですね。
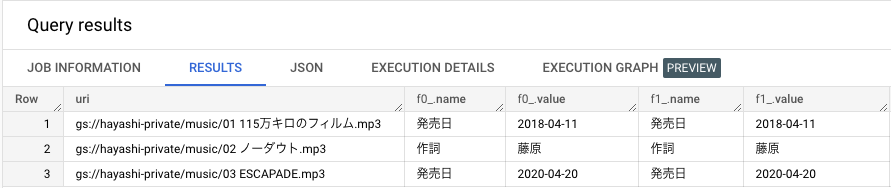

ちなみにインデックス外を指定するとエラーになりますが SAFE_OFFSET を利用すると NULL で返ってきます。エラー回避に利用できそうです。
SELECT
uri
, metadata[OFFSET(0)]
, metadata[SAFE_OFFSET(1)]
FROM `unstructured_data.music`
OFFSET と ORDINAL の違い
OFFSET には配列のインデックスが 0 が始まり、1 番目の要素を返えします。一方、ORDINAL は配列のインデックスは 1 から始まり、1 番目の要素を返します。
metadata[ORDINAL(0)] を指定すると our of index でエラーとなります。
3. 構造体型データへのアクセス
構造体型データについて
構造体型は STRUCT 型 として表現され、自由度の高いデータ格納が可能なようです。
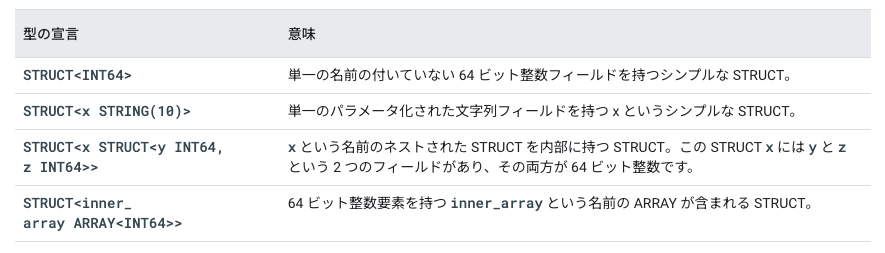
型の宣言形式は様々で公式ドキュメントでは下記のものが例としてあげられています。
フィールドへのアクセス
構造体型への参照は直感的わかりやすいですね。今回の例では、metadata は ARRAY<STRUCT<name STRING, value STRING>> なので下記のような形になります。
SELECT
uri
, metadata[OFFSET(0)].name
, metadata[OFFSET(0)].value
, metadata[OFFSET(1)].name
, metadata[OFFSET(1)].value
FROM `unstructured_data.music`
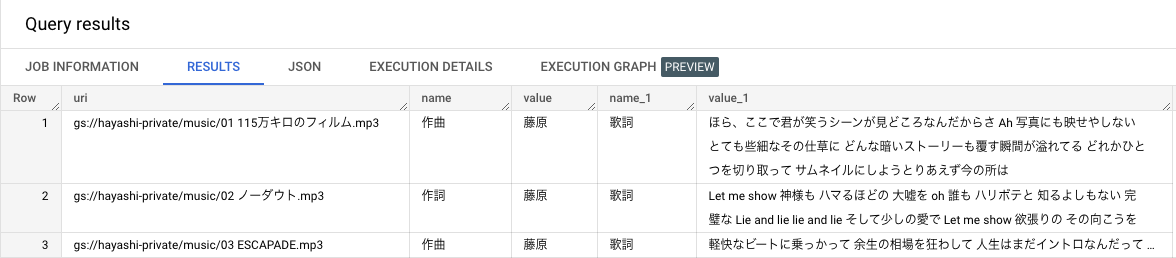
これでオブジェクトテーブルにカスタムメタデータを設定した際のアクセスは完璧です。ただ、もっと実践的な観点だと非構造化データの解析結果は Json 形式のことが多いと思われるため、Json 形式が value に格納されているケースを想定してみたいと思います。
4. JSON 型データへのアクセス
JSON 形式のデータを登録
今まで設定していたカスタムメタデータを **JSON 形式の文字列****に直します。
{"歌詞" : "ほら、ここで君が笑うシーンが見どころなんだからさ Ah 写真にも映せやしないとても些細なその仕草に どんな暗いストーリーも覆す瞬間が溢れてる どれかひとつを切り取って サムネイルにしようとりあえず今の所は","作詞":"藤原","作曲":"藤原","発売日":"2018-04-19"}
こちらを result という key に value として設定します。わかりやすいように今までのカスタムメタデータは削除します。

注意点
Json 形式の文字列が正確でないと下記のエラーが発生します。どの文字列がひっかかっているかを確認して修正が必要です。
Invalid input: syntax error while parsing value - invalid literal; last read: '''; error in PARSE_JSON expression
文字列を JSON 型に変換
この状態では STRING 型での抽出になってしまい扱いづらいです。JSON 型に変換することでデータへのアクセスが容易になるので変換して取り出します。利用する関数は PARSE_JSON 関数です。
SELECT
uri
, metadata[OFFSET(0)].name
, metadata[OFFSET(0)].value
, PARSE_JSON(metadata[OFFSET(0)].value)
FROM `unstructured_data.music`

見た目は変わりませんが、JSON 型になったことで Key を指定して Value の取り出しが可能になります。
フィールドへのアクセス
方法は 2 通りあります。1 つが辞書型のようにアクセスする JSON サブスクリプト式です。
SELECT
uri
, metadata[OFFSET(0)].name
, PARSE_JSON(metadata[OFFSET(0)].value)["歌詞"]
FROM `unstructured_data.music`
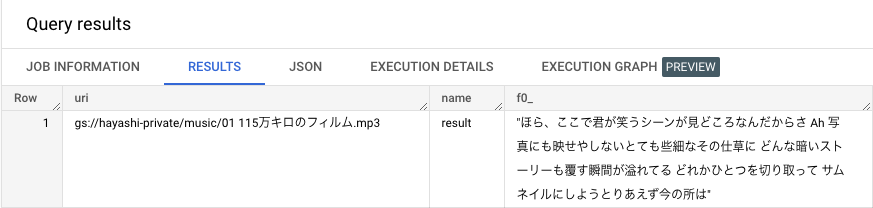
もう 1 つは構造体型データと同様のフィールドアクセスです。 PARSE_JSON(metadata[OFFSET(0)].value).歌詞 とやりたいところですが、さすが日本語はエラーになるので、この形式でアクセスしたい場合には Key をアルファベットにしておくことをオススメします。
PARSE_JSON(metadata[OFFSET(0)].value).kashi とかならうまくワークします。
ちょっとした所感
JSON 型については 1 年前ほどにサポートが発表されてから、初めてちゃんと触ってみましたがかなり使い勝手よいと感じました。今回想定しているような分析結果を JSON 形式で返すことは当たり前にあると思うので、その結果に直感的にアクセスできる点が良いと思いました。
テキストデータの検索高度化
最後にテキストデータへの検索の高速化を試していきます。
JSON 型同様に存在は知っているもののちゃんと触ったことがないので楽しみです。
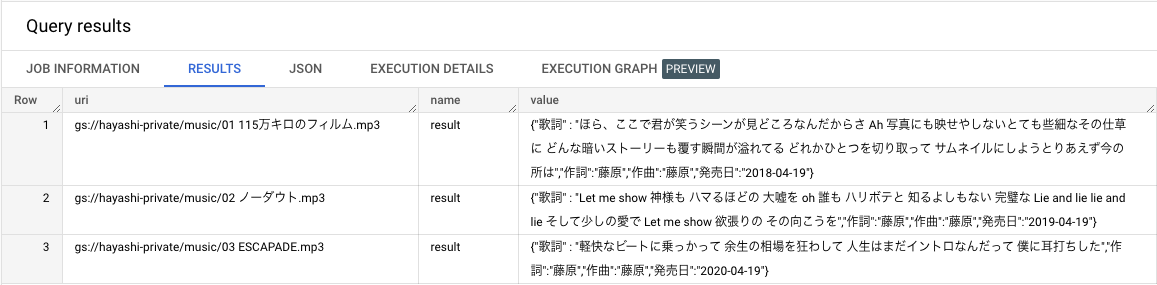
1. カスタムメタデータに Json 形式での登録
SELECT
uri
, metadata[OFFSET(0)].name
, PARSE_JSON(metadata[OFFSET(0)].value)
FROM `unstructured_data.music`
2. Serch Index の作成
こちらの検索インデックスは SEARCH 関数を使用して検索が高速されるようなデータ構造になります。
CREATE SEARCH INDEX を利用して作成可能ですが、データ型は下記のものに限られます。
- STRING
- ARRAY<STRING>
- STRUCT(STRING または ARRAY の少なくとも 1 つのフィールドを含む)
- JSON
まずはこのままオブジェクトテーブルに対してインデックスを作成したいと思います。今回は歌詞に特定の単語が入っている場合の検索スピードを上げたいという想定なので、JSON 形式で格納したカラムにインデックスを作成します。
CREATE SEARCH INDEX my_index ON
`unstructured_data.music`(PARSE_JSON(metadata[OFFSET(0)].value);
とすると下記の表示が。
Cannot create search index on table of type EXTERNAL
どうやら外部テーブルには作成できないようです。公式ドキュメントによるとテーブルのみ対応しているようです。インデックスを作成する対象を JSON 型に変換してテーブルを作成します。
CREATE TABLE `unstructured_data.music_for_index` AS
SELECT uri, PARSE_JSON(metadata[OFFSET(0)].value) AS json_value
FROM `unstructured_data.music`;
その後に json_value に対して検索インデックスを作成します。
CREATE SEARCH INDEX my_index ON
`unstructured_data.music_for_index`(json_value);
これで作成完了です。念のため、検索インデックスが設定されているかどうかを確認したいと思います。
SELECT table_name, index_name, coverage_percentage
FROM `unstructured_data.INFORMATION_SCHEMA.SEARCH_INDEXES`
WHERE table_name = 'music_for_index';
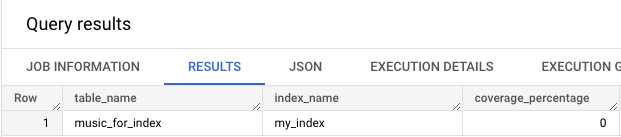
my_index が表示されたため、検索インデックスの作成はできていそうです。しかし、coverage_percentage が 0 なのが気になります。調べてみると下記の制約があることがわかりました。
名前、作成に使用される DDL ステートメント、カバレッジ率、テキスト アナライザが含まれます。インデックス登録されたベーステーブルが 10 GB 未満の場合、そのインデックスは入力されません。この場合、coverage_percentage は 0 になります。
今回はサンプル用に極めて小さいテーブルで検索インデックスを作成したので 0 と表示されました。この点は検索インデックスを利用する上での注意ですね。
3. SEARCH 関数の利用
シンプルな使い方としては、下記のクエリで取得できます。SEARCH 関数では指定したカラムとキーワードの一致を判定してくれます。サンプルデータの歌詞に「完璧」という文字列が入っているので、「完璧」をキーワードに検索してみます。
{"作曲":"藤原","作詞":"藤原","歌詞":"Let me show 神様も ハマるほどの 大嘘を oh 誰も ハリボテと 知るよしもない 完璧な Lie and lie lie and lie そして少しの愛で Let me show 欲張りの その向こうを","発売日":"2019-04-19"}
SELECT uri FROM `unstructured_data.music_for_index`
WHERE SEARCH(json_value['歌詞'], '完璧');
このクエリでは結果を得られませんでした。SEARCH 関数の挙動は公式ドキュメントで下記のように記載されています。
SEARCH 関数は、BigQuery テーブルや他の検索データに、一連の検索キーワードが含まれているかどうかを確認します。テキスト アナライザで記述されたトークン化に基づいて、search_query のすべてのトークンが search_data にある場合、TRUE を返します。それ以外の場合は FALSE を返します。search_query が NULL であるか、検索キーワードが含まれていない場合は、エラーがスローされます
このテキストアナライザが検索にひっかかる要素を作成していそうです。
さらにテキストアナライザについては下記のように記述されています。
SEARCH 関数は、2 つのテキスト アナライザ(NO_OP_ANALYZER と LOG_ANALYZER)をサポートしています。正確に一致させたい前処理済みのデータがある場合は、NO_OP_ANALYZER を使用します。テキストにはトークン化や正規化が適用されません。LOG_ANALYZER は、次の方法でテキストデータを変更します。
テキストは小文字になります。127 を超える ASCII 値はそのまま保持されます。
テキストは、次の区切り文字でトークンと呼ばれる個別の語句に分割されます。
[ ] < > ( ) { } | ! ; , ' " * & ? + / : = @ . - $ % \ _ \n \r \s \t %21 %26 %2526 %3B %7C %20 %2B %3D %2520 %5D %5B %3A %0A %2C %28 %29
例えば、Hello|WORLD は、hello と world になります。
今回のケースでは「完璧」との完全一致でヒットするようなパースがされなかったというでした。なので、クエリを「完璧な」で検索するように修正してみます。
SELECT uri FROM `unstructured_data.music_for_index`
WHERE SEARCH(json_value['歌詞'], '完璧な');
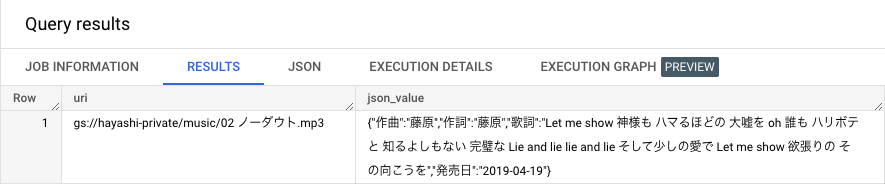
想定している結果が得られました。検索する際にはキーワードがなんでもかんでもひっかかるというわけではなさそうですが、適切なキーワードを設定すれば比較的簡単に検索を高速化できそうです。
SEARCH 関数のオプション
json_scope というオプションが設定でき JSON 型のデータに対して柔軟な検索方法を設定できます。
例えば、json_scope=>'JSON_VALUES'と設定すると JSON 型データの全ての value が検索対象になります。次のクエリでは Json 形式の Key であり「歌詞」という点を省き、 JSON_VALUES を json_scope に設定して検索できるかを検証します。
SELECT uri FROM `unstructured_data.music_for_index`
WHERE SEARCH(json_value, '完璧な', json_scope=>'JSON_VALUES');
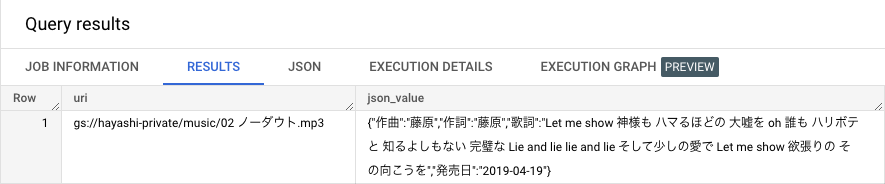
取得することができました。
複数の解析結果を value に設定している場合に、検索の際に Key を指定することなく検索対象を設定できるのは使いやすそうです。
まとめ
今回は ARRAY 型 / STRUCT 型 / JSON 型について触れきました。
それぞれ癖はあるもののデータへのアクセスは比較的容易になっており、オブジェクトテーブルのカスタムメタデータへのアクセスも可能となりました。
また、テキスト検索の高速化として Search Index と SEARCH 関数についても触れました。
今回はどれくらい高速化されるかという点までは検証できませんでした、使い始めれる程度には情報を整理できました。また、いくつか注意点もあるのでこの記事が役にたてば幸いです。
単語レベルは存在は知っているもののまだまだ触れられていない機能がたくさんあり BigQuery は面白いですね。次はこのシリーズの最後として BigQuery で非構造化データの分析について書きたいと思います。
Discussion