BigQueryで非構造化データを扱ってみませんか?
AWS と Google Cloud で構築したデータ基盤の開発・運用に携わっているデータエンジニアです。5 年くらい携わっていて、この業務がきっかけで Google Cloud が好きになりました。
最近 Google Cloud のブログ企画であるこちらを見つけて挑戦したくなりました。GW ってこともあり、Google Cloud 関連の記事を投稿していこうと思います。

アウトプットの機会も少なくなっていたので、ここいらで気張ってインプット/アウトプットのサイクルを回していきます。
Overview
BigQuery の非構造化データを扱いに関する検証記事
- 近年、メタ空間で取得されたデータ(音声データや画像データ etc)、いわゆる非構造化データを DB 上で扱っていきたいというニーズが高まっています
- しかし、表データないため、そのものを構造化データ的に扱うことはできません
- そこで、非構造化データのメタデータを DB 上で扱えるようにすることで構造化データとの組み合わせての分析、機械学習モデルへの連携をスムーズしようといった仕組みが増えています
⇒ こちらについてデータサイエンティストに聞いてみると非常にありがたい機能という声が多く今回検証するにいたりました。
非構造化データを扱う手順やユースケースをまとめています
- BigQuery と Cloud Storage とを BigQuery Connection を介した連携で比較的簡単に実現できます
- Cloud Storage 上にある非構造化データを格納しているパスに対して BigQuery のオブジェクトテーブルとして閲覧できるように設定します
- Cloud Storage 上のオブジェクトにカスタムメタデータを設定することで BigQuery から非構造化データのメタデータに加えて、そのデータに対して行った分析結果等の自由な値も一緒に確認することができます

キーワード
非構造化データの扱い
検証した手順をまとめていきます。ニッチなネタでもあるため、中級者向けということでところどころ割愛している点はご了承ください。
1. 非構造化データの格納
今回は Cloud Storage に音声データを格納します。
(髭ダンのアルバムを買っていたのでそちらを格納しています。)
適当な画像データでも OK です。
パスは gs://hayashi-private/music です。

2. データセットの作成およびコネクションの作成
次に BigQuery の非構造化データ参照用のデータセットを作成します。
データセット名は unstructured_data として、東京リージョンに作成します。
そして、ポイントとなる BigQuery Connection を作成します。
こちらは下記の bq mk コマンドで作成可能です。コネクション名は unstructured-connector として、ローケションもデータセットに合わせます。
bq mk --connection --location=asia-northeast1 --project_id=<PROJECT_ID> --connection_type=CLOUD_RESOURCE unstructured-connector

BigQuery Connection について
下記、公式ドキュメントから抜粋してきたものです。
BigQuery では、BigQuery の外部で、Cloud Storage や Cloud Spanner などの Google Cloud サービス、または AWS や Azure などのサードパーティのソースに保存されているデータをクエリできます。これらの外部接続では、BigQuery Connection API が使用されます。
要は BigQuery のネイティブテーブル以外の外部リソースにクエリしたいときに必要なコネクタってことですかね。あとは Remote 関数という SQL で Cloud Functions を呼び出す機能を使うときにも利用されます。
注意点
BigQuery Connection は上記にある通り BigQuery Connection API が使用されるため、こちらが有効になっていないと利用できません。
コマンド実行前に有効化する点をお気をつけください。

3. コネクションのサービスアカウントへの閲覧権限付与
BigQuery Connection を作成するとサービスアカウントが自動的に作成されます。
サービスアカウント ID は bqcx-<PROJECT_NUMBER>-<RANDOM>@gcp-sa-bigquery-condel.iam.gserviceaccount.com となります(上記のスクショの赤枠部分です)。
こちらのサービスアカウントが非構造化データを格納した gs://hayashi-private を閲覧できるように権限を付与します。バケットレベルでサービスアカウントに Storage Object Viewer を付与します。

4. コネクションを用いたオブジェクトテーブルの作成
最後に bq mk もしくは SQL で Cloud Storage からオブジェクト情報を読み取れるテーブルを作成します。
bq mk --table \
--external_table_definition=gs://hayashi-private/music/*@asia-northeast1.unstructured-connector \
--object_metadata=SIMPLE \
unstructured_data.music
CREATE EXTERNAL TABLE `unstructured_data.music`
WITH CONNECTION `asia-northeast1.unstructured-connector`
OPTIONS(
object_metadata = 'SIMPLE',
uris = ['gs://hayashi-private/music/*']);
公式ドキュメントからテーブルスキーマを抜粋しました。
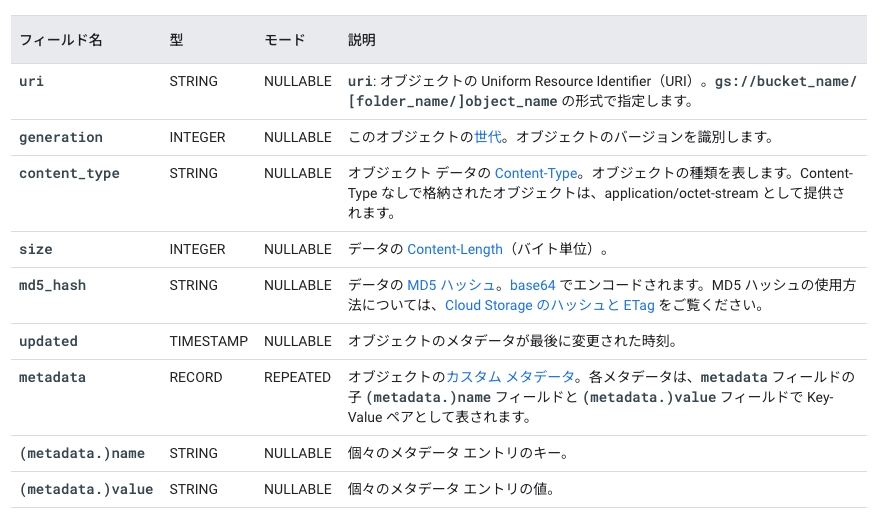
5. オブジェクトテーブルへのアクセス
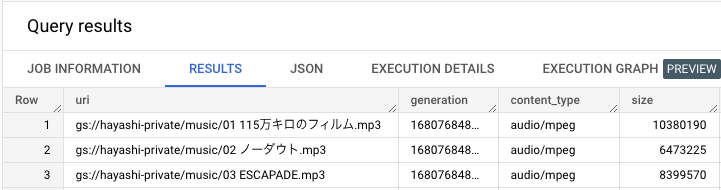
いつも通りのテーブルアクセスのクエリでメタデータを閲覧することが可能です。
select * from `unstructured_data.music`;

ユースケース
上記の情報を構造化データと組み合わせて分析等(例えば、BigQueryML へのインプット)もできますが、より実践的な観点でいうと Cloud Storage のオブジェクトに付与できるカスタムメタデータとの併用も 1 つだと思います。
カスタムメタデータの設定
この Cloud Storage 上のオブジェクトのカスタムメタデータは Key-Value 形式で自由な値を設定することが可能です。(参考)
今回格納した非構造化データに対して試しにメタデータを設定してみます。音声データの分析結果等を設定することが予想されるので、文字起こし的なニュアンスで「歌詞」という Key に「歌詞の一部」を Value として設定してみます。

カスタムメタデータの見え方
下記の SQL で取得します。このように設定することでシンプルなメタデータだけの情報に加えて分析結果等を付与でき、より高度な非構造化データの操作が可能になるのではと思います。
select uri, metadata from `unstructured_data.music`;

注意点
ただ、このカスタムメタデータは現時点では Cloud Storage への操作でしかできません。(当たり前と言えば当たり前ですが)
しかし、分析基盤ではユーザーが利用できるのは SQL での操作だけとなると、非構造化データに対するカスタムメタデータの設定は別の方法を検討する必要があるのかなーと思いました。(BigQuery の SQL で極力完結させたいというニーズは多かったりするのかなと)
おわりに
BigQuery の非構造化データの扱いについてまとめてみました。
冒頭に記載した通り、非構造化データを BigQuery で扱おうとするとカスタムメタデータとの組み合わせはかなり使い勝手がいいのではと思いました。
ただ、カスタムメタデータを扱うには配列へのアクセスに加えて、JSON の操作が必須となります。意外とすんなりいかない部分が多かったので、次の記事ではその点に触れていこうと思います。
少しニッチな内容でしたが、興味を持ってもらえたら嬉しいです。
追記
JSON 型やテキスト検索の高速化についてはこちらの記事で書きました。
よければご参考ください。
Discussion