画像×タッチデータのエリア分析をサクッと実装
📌はじめに
前回の記事では、画像上でエリアを指定し、
その座標をまとめた 「エリア定義ファイル(xy_points.csv)」を作成しました。
今回はそのエリア定義を活用し、ユーザーが入力した「好き/嫌い」の
タッチ座標データを組み合わせて、
画像内のどのエリアが好まれているのかを集計・可視化していきます。
🥅今回のゴール:エリア別集計

area_summary_rule.xlsx

area_summary_ruleを使った散布図
📌分析の流れ
- 画像の読み込みと GUI でのラベリング
- ラベル情報の CSV 保存
- ラベル領域の色分け・描画
- 評価データの集計(like / dislike / none)(✅ 今回)
- Excel ファイルへの出力(✅ 今回)
- 散布図による可視化(参考)(✅ 今回)
📌調査内容(仮定)
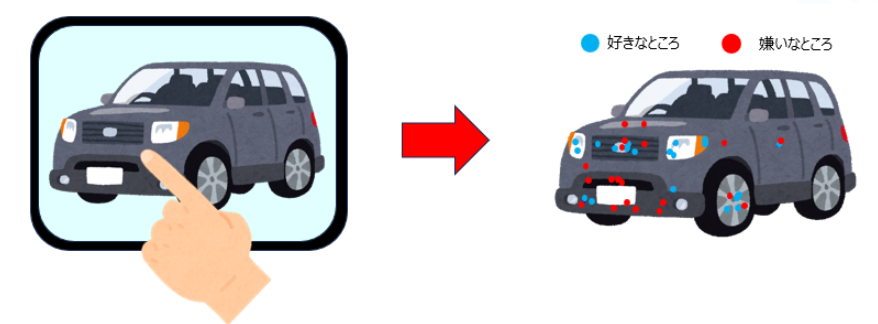
- 調査対象者には iPad 上で車の写真を見てもらい、
「好きなところ(最大2ヶ所)」と「嫌いなところ(最大2ヶ所)」をタッチしてもらいます。
※タッチ位置は、画像上の座標 (x, y) として記録されます。
📌調査データ(仮定)

| 列名 | 内容 |
|---|---|
| ID、属性情報 | 調査対象者の基本情報 |
| like1_x, like1_y | 好きな場所1の座標 |
| like2_x, like2_y | 好きな場所2の座標(あれば) |
| dislike1_x, dislike1_y | 嫌いな場所1の座標 |
| dislike2_x, dislike2_y | 嫌いな場所2の座標(あれば) |
📌集計ルールの考え方
同一回答者の同一エリア内で複数ポイントがあっても、以下のルールで集計します。
- 好き + 嫌い = 0(相殺)
- 好き × 2個 = 1ポイントとしてカウント
- 嫌い × 2個 = 1ポイントとしてカウント
📌ディレクトリ構成
project-root/
├─ analyzer.py # 集計・可視化ロジック(メイン処理)
├─ draw_helper.py # 【おまけ】ルール適用後の座標を画像上に描画するコード
├─ xy_points.csv # エリア定義ファイル(多角形座標)
└─ sample.csv # 調査データ(好き・嫌いの座標データ)
📌環境
python3.x
📌コード解説(analyzer.py)
#============================================
# 0. ライブラリとファイル読み込み
#============================================
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.path import Path
from collections import defaultdict
import japanize_matplotlib
from openpyxl import Workbook
import re
# ファイル読み込み
points_df = pd.read_csv("xy_points.csv")
data_df = pd.read_csv("サンプル.csv")
#============================================
# 1.エリア定義ファイルから多角形パスを作成
#============================================
area_polygons = {}
for name, group in points_df.groupby("name"):
polygon = group[["x", "y"]].values
area_polygons[name] = Path(polygon)
#============================================
# 2.回答者ごと・エリアごとの like/dislike カウント用辞書
#============================================
per_respondent_area = defaultdict(lambda: defaultdict(lambda: {"like":0, "dislike":0}))
total_respondents = len(data_df)
results = {area: {"like": 0, "dislike": 0} for area in area_polygons}
#============================================
# 3. 回答者ごとのエリア内好き嫌いポイントの集計準備
#============================================
for idx, row in data_df.iterrows():
# 好きポイント判定
for i in range(1, 3):
x, y = row.get(f"like{i}_x"), row.get(f"like{i}_y")
#print("like "+ str(x) + " , " + str(y))
if pd.notnull(x) and pd.notnull(y):
for area, poly in area_polygons.items():
if poly.contains_point((x, y)):
per_respondent_area[idx][area]["like"] += 1
break
# 嫌いポイント判定
for i in range(1, 3):
x, y = row.get(f"Dislike{i}_x"), row.get(f"Dislike{i}_y")
#print("Dislike "+ str(x) + " , " + str(y))
if pd.notnull(x) and pd.notnull(y):
for area, poly in area_polygons.items():
if poly.contains_point((x, y)):
per_respondent_area[idx][area]["dislike"] += 1
break
#============================================
# 4. 集計ルール適用:好きと嫌いが両方あれば相殺してカウントしない
#============================================
for respondent, area_data in per_respondent_area.items():
for area, counts in area_data.items():
like_count = counts["like"]
dislike_count = counts["dislike"]
if like_count > 0 and dislike_count > 0:
# 相殺でカウント無し
continue
elif like_count > 0:
results[area]["like"] += like_count
elif dislike_count > 0:
results[area]["dislike"] += dislike_count
0. ライブラリとファイル読み込み
-
xy_points.csv:エリアの座標データ(前回作成した定義ファイル) -
サンプル.csv:各回答者の「好き」「嫌い」座標データ
1. エリア定義ファイルから多角形パスを作成
-
Path:座標リストを多角形として扱い、点が内側かどうか判定できるようにする
補足
エリアは単なる座標の集合なので、そのままでは「点が内側かどうか」を判断できません。
ここで Path に変換することで、後続の座標判定処理を一行で書けるようになります。
💡ポイント
計算可能な形に変換しておくと、集計ロジックがシンプルになります。
2. 回答者ごと・エリアごとの like/dislike カウント用辞書
-
defaultdict:回答者 × エリアごとのカウントを自動初期化 - like / dislike 数を 0 からスタートで保持
補足
普通の辞書だとキーの存在確認や初期化が必要ですが、defaultdict なら自動で 0 からスタート。
ネスト構造でも処理ロジックがスッキリ書けます。
💡ポイント
初期化コードを減らせるので、ネスト辞書でも読みやすく保守しやすいです。
3. 回答者ごとのエリア内好き嫌いポイントの集計
-
iterrows():回答者ごとの座標を順に処理 -
contains_point():座標がエリア内にあるかどうか判定
補足
ここでは各回答者の「like座標」「dislike座標」座標を順にチェックし、
もし座標がどのエリアにも含まれなければスルー、含まれていればそのエリアにカウントが加算されます。
この仕組みにより、
- 回答者が複数のエリアに触れた場合も正しく集計できる
- 座標が欠損していてもスキップできる
といった柔軟な処理が可能になります。
💡ポイント
欠損や無関係な座標を含む前提で設計すると安全です。
4. 集計ルール適用:好きと嫌いが両方あれば相殺
ルール:
- like のみ → 有効
- dislike のみ → 有効
- like & dislike 両方あり → 相殺して無効
補足
このルールを設けることで、同じエリアに対して評価がぶつかった場合
(好きでもあり嫌いでもある)は、
「判断保留」として集計に入れないようにしています。
こうすることで、集計結果が「はっきりした傾向だけ」を反映する形になり、
グラフやレポートを見る際にノイズを減らせます。
| ケース(同一エリア) | 集計に含まれる? | 理由 |
|---|---|---|
| like = 1, dislike = 0 | ✅ 含まれる | 好きだけなら有効 |
| like = 0, dislike = 1 | ✅ 含まれる | 嫌いだけなら有効 |
| like = 2, dislike = 0 | ✅ 含まれる | like = 1 |
| like = 0, dislike = 2 | ✅ 含まれる | dislike = 1 |
| like = 1, dislike = 1 | ❌ 含まれない | 相殺(ルールで無効化) |
| like = 0, dislike = 0 | ❌ 含まれない | 回答がないので無視 |
#============================================
# 5.DataFrame化と比率計算
#============================================
df = pd.DataFrame.from_dict(results, orient="index")
df["total"] = total_respondents
df["none"] = total_respondents - df["like"] - df["dislike"]
df["like_ratio"] = df["like"] / total_respondents
df["dislike_ratio"] = df["dislike"] / total_respondents
df["none_ratio"] = df["none"] / total_respondents
df = df.fillna(0)
with pd.ExcelWriter("rule_analysis_area.xlsx", engine="openpyxl") as writer:
df[["like", "dislike", "none", "total", "like_ratio", "dislike_ratio", "none_ratio"]].to_excel(writer, sheet_name="Summary", index=True)
#============================================
# 6.好き・嫌いの比率の散布図を作成
#============================================
plt.figure(figsize=(10,7))
# 0〜1の比率を100倍してパーセントに
x = df["like_ratio"] * 100
y = df["dislike_ratio"] * 100
plt.scatter(x, y, s=100, color="mediumblue")
for area, row in df.iterrows():
plt.text(row["like_ratio"] * 100 + 0.5, row["dislike_ratio"] * 100 + 0.5, area, fontsize=9)
plt.xlabel("Like (%)")
plt.ylabel("Dislike (%)")
plt.title("Like vs Dislike 散布図 (相殺ルール適用済み)")
plt.grid(True)
plt.tight_layout()
plt.show()
5.DataFrame化と比率計算
-
from_dict():辞書resultsを DataFrame に変換し、エリアごとの集計を表形式に整理 -
none列:like/dislike に含まれなかった回答数を計算して追加 -
ratio列:総数(回答者数)で割って比率を算出、可視化や比較に使いやすい形に整形 -
fillna(0):欠損値を 0 で補完して処理の安全性を確保
6.好き・嫌いの比率の散布図を作成
-
scatter():like比率をX軸、dislike比率をY軸にして散布図を作成 - 比率を 0〜1 から 0〜100 に変換してパーセント表示
-
text():各点の近くにエリア名をラベル表示して識別可能に
出力例
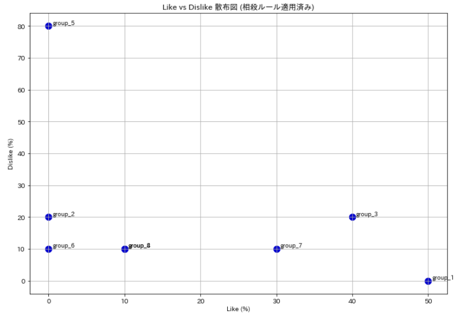
📊 ラベルの重なり問題と対応策
group_4 と group_8 の座標が同じため、ラベルが重なっています。
Pythonでラベルの重なりを回避するライブラリadjustTextもありますが、処理が重く、完全に回避するのは難しいです。
このような場合は、Excel でグラフ化する方が簡単です。
📊 ラベルを部位の名称に変えて考察(例)
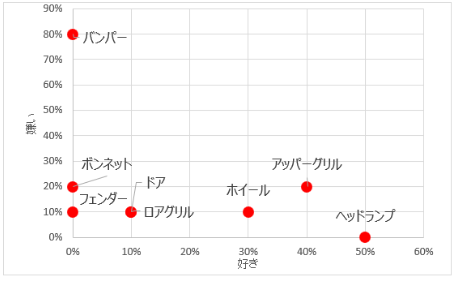
Excelで加工
-
バンパー:dislike(嫌い)が多く、デザインや機能面の改善余地あり
-
ライトやホイール:like(好き)が多く、支持されている
-
ロアグリル :dislike(嫌い)が多く、ユーザーの不快要因を調査して改善が望まれる
💡ポイント
比率やラベルを部位名に変換することで、実務的な改善策のヒントになります。
📌答え合わせコード
エリア内なのにカウントされない場合は、ルール適用前後の集計やプロット可視化を確認しましょう。
#============================================
# 7.ルール適用前の集計を回答者×エリアのDataFrameにまとめる
#============================================
records = []
for respondent_id, areas in per_respondent_area.items():
record = {"Respondent ID": respondent_id}
for area, counts in areas.items():
record[f"{area}_Like"] = counts["like"]
record[f"{area}_Dislike"] = counts["dislike"]
records.append(record)
respondent_df = pd.DataFrame(records)
respondent_df = respondent_df.fillna(0).astype({"Respondent ID": int})
# カラム並び順を調整
column_order = ["Respondent ID"]
def extract_group_number(col):
match = re.search(r"group_(\d+)_", col)
return int(match.group(1)) if match else float('inf')
like_dislike_cols = [col for col in respondent_df.columns if col != "Respondent ID"]
like_cols = sorted([col for col in like_dislike_cols if "Like" in col], key=extract_group_number)
dislike_cols = sorted([col for col in like_dislike_cols if "Dislike" in col], key=extract_group_number)
column_order += [val for pair in zip(like_cols, dislike_cols) for val in pair]
# カラムを並び替えて、IDを昇順にソート
respondent_df = respondent_df[column_order].sort_values("Respondent ID").reset_index(drop=True)
respondent_df.to_csv("rule_area_count.csv", index=False)
#============================================
# 8.ルール適用後の集計
#============================================
records = []
for respondent_id, area_data in per_respondent_area.items():
record = {"Respondent ID": respondent_id}
for area, counts in area_data.items():
like_count = counts["like"]
dislike_count = counts["dislike"]
if like_count > 0 and dislike_count > 0:
# 相殺 → どちらも記録しない
continue
if like_count > 0:
record[f"{area}_Like"] = like_count
if dislike_count > 0:
record[f"{area}_Dislike"] = dislike_count
records.append(record)
# DataFrameに変換
respondent_rule_applied_df = pd.DataFrame(records).fillna(0).astype({"Respondent ID": int})
# カラム名から存在する group番号を抽出して昇順ソート
group_nums = set()
for col in respondent_rule_applied_df.columns:
m = re.match(r"group_(\d+)_", col)
if m:
group_nums.add(int(m.group(1)))
group_nums = sorted(group_nums)
# カラム並び順を作成(group番号順に Like → Dislike の順)
column_order = ["Respondent ID"]
for n in group_nums:
like_col = f"group_{n}_Like"
dislike_col = f"group_{n}_Dislike"
if like_col in respondent_rule_applied_df.columns:
column_order.append(like_col)
if dislike_col in respondent_rule_applied_df.columns:
column_order.append(dislike_col)
# 並べ替え&出力
respondent_rule_applied_df = respondent_rule_applied_df[column_order].sort_values("Respondent ID").reset_index(drop=True)
respondent_rule_applied_df.to_csv("rule_area_count_after.csv", index=False)
#============================================
# 9.ルール適用前後の差分計算とCSV出力
#============================================
before_df = respondent_df.set_index("Respondent ID")
after_df = respondent_rule_applied_df.set_index("Respondent ID")
# 差分計算(after - before)
diff_df = after_df - before_df
diff_df = diff_df.reset_index()
# 🔽 カラム順を整える:group番号順に Like → Dislike の順
group_nums = set()
for col in diff_df.columns:
m = re.match(r"group_(\d+)_", col)
if m:
group_nums.add(int(m.group(1)))
group_nums = sorted(group_nums)
column_order = ["Respondent ID"]
for n in group_nums:
like_col = f"group_{n}_Like"
dislike_col = f"group_{n}_Dislike"
if like_col in diff_df.columns:
column_order.append(like_col)
if dislike_col in diff_df.columns:
column_order.append(dislike_col)
# 並び替え&出力
diff_df = diff_df[column_order]
diff_df.to_csv("area_count_diff.csv", index=False)
7.ルール適用前の集計を回答者×エリアのDataFrameにまとめる
集計ルールを適用する前のデータで、回答者ごとにどのエリアを見たかを集計したものです。
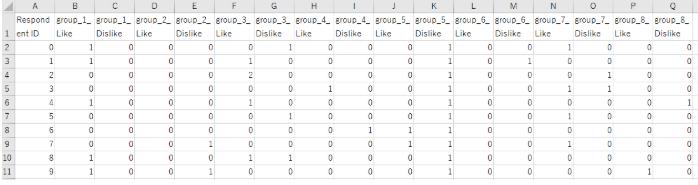
rule_area_count.csv
8.ルール適用前後の差分計算とCSV出力
集計ルールを適用したデータで、回答者ごとにどのエリアを見たかを集計したものです。

rule_area_count_after.csv
9.ルール適用前後の差分の確認
ルール適用前後を可視化して確認することで、集計ミスや意図しないカウント漏れを防止できます。
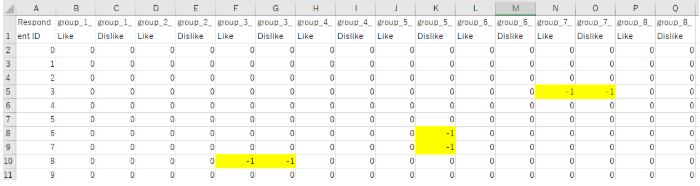
area_count_diff.csv
📊 エリア定義していない場所のプロットは分析対象外です
エリア定義は、実際のプロット位置を確認した上で行うことをおすすめします。

📌ルール適用後の座標データ作成コード
ルール適用後の座標データを作成し、
回答者IDごとに「like」「dislike」の有効な座標だけを含むrule_xy_points.csvを出力します。
rows = []
for idx, row in data_df.iterrows():
respondent_id = row.get("Respondent ID", idx)
# 各座標の保持
output_row = {
"Respondent ID": respondent_id,
"like1_x": np.nan, "like1_y": np.nan,
"like2_x": np.nan, "like2_y": np.nan,
"Dislike1_x": np.nan, "Dislike1_y": np.nan,
"Dislike2_x": np.nan, "Dislike2_y": np.nan,
}
# エリア別記録(like/dislike)→ 各座標がどのエリアに属するかを記録
like_areas = {}
dislike_areas = {}
# likeの座標
for i in range(1, 3):
x, y = row.get(f"like{i}_x"), row.get(f"like{i}_y")
if pd.notnull(x) and pd.notnull(y):
for area_name, poly in area_polygons.items():
if poly.contains_point((x, y)):
like_areas[i] = area_name
break
# dislikeの座標
for i in range(1, 3):
x, y = row.get(f"Dislike{i}_x"), row.get(f"Dislike{i}_y")
if pd.notnull(x) and pd.notnull(y):
for area_name, poly in area_polygons.items():
if poly.contains_point((x, y)):
dislike_areas[i] = area_name
break
# 相殺チェック
canceled_areas = set(like_areas.values()) & set(dislike_areas.values())
# 生き残った like 座標だけ出力に
for i in range(1, 3):
if i in like_areas and like_areas[i] not in canceled_areas:
output_row[f"like{i}_x"] = row.get(f"like{i}_x")
output_row[f"like{i}_y"] = row.get(f"like{i}_y")
# 生き残った dislike 座標だけ出力に
for i in range(1, 3):
if i in dislike_areas and dislike_areas[i] not in canceled_areas:
output_row[f"Dislike{i}_x"] = row.get(f"Dislike{i}_x")
output_row[f"Dislike{i}_y"] = row.get(f"Dislike{i}_y")
# 出力に追加
rows.append(output_row)
# DataFrame化 & CSV出力(ファイル名は適宜変更)
result_df = pd.DataFrame(rows)
result_df = result_df.sort_values("Respondent ID") # IDで昇順ソート
result_df.to_csv("rule_xy_points.csv", index=False)
print("✅ 処理終了")
相殺ルール適用後の可視化
このデータを使うと、相殺ルール適用後の評価点だけの「After画像」が作成できます。

rule_xy_points.csv
Before/Afterの比較

- Before:すべての評価(like/dislike)が表示されている
- After :同じエリアでlikeとdislikeが重複した評価は相殺されて除外
💡 ポイント
・ この可視化で、評価の偏りや矛盾を直感的に確認できます。
・ 例えば特定エリアで相殺が多い場合、評価者の迷いや意見の対立が示唆されます。
おまけ:作画コード
rule_xy_points.csvで、画像上にプロットを行い、
rule_likes_dislikes.pngとしてファイル保存します。
# 📒ルール適用後のデータでプロット図を作成
import cv2
import pandas as pd
# ファイル名
img_path = "car.png"
csv_path = "rule_xy_points.csv"
output_path = "rule_likes_dislikes.png"
# 画像読み込み
img = cv2.imread(img_path)
if img is None:
print(f"画像ファイル {img_path} が読み込めません。")
exit()
# CSV読み込み
df = pd.read_csv(csv_path)
# 点を描く関数
def draw_points(img, points, color, radius=5, thickness=2):
for (x, y) in points:
cv2.circle(img, (int(x), int(y)), radius, color, thickness)
# likeとdislikeの座標を抽出
like_points = []
dislike_points = []
for idx, row in df.iterrows():
# like座標はlike1_x, like1_y, like2_x, like2_y, ... 最大9まで対応
for i in range(1, 10):
x_col = f"like{i}_x"
y_col = f"like{i}_y"
if x_col in df.columns and y_col in df.columns:
x, y = row[x_col], row[y_col]
if pd.notnull(x) and pd.notnull(y):
like_points.append((x, y))
# dislike座標はdislike1_x, dislike1_y, ... 同様に最大9まで
for i in range(1, 10):
x_col = f"dislike{i}_x"
y_col = f"dislike{i}_y"
if x_col in df.columns and y_col in df.columns:
x, y = row[x_col], row[y_col]
if pd.notnull(x) and pd.notnull(y):
dislike_points.append((x, y))
# 描画(BGRカラー)
draw_points(img, like_points, (255, 0, 0)) # 青色(like)
draw_points(img, dislike_points, (0, 0, 255)) # 赤色(dislike)
# 画面に表示(ESCや任意キーで終了)
cv2.imshow("Likes (Blue) & dislikes (Red)", img)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 画像ファイルとして保存
cv2.imwrite(output_path, img)
print(f"描画結果を {output_path} に保存しました。")
プロットの形やサイズはお好みで
📌注意点・よくあるトラブルと対処
-
エリア定義(
xy_points.csv)の座標順序
エリアは多角形(Polygon)として判定するため、座標の並び順が正しくないとPathが誤判定を起こします。
点の順序が前後したり途中で戻ったりすると、意図しない領域になってしまうので注意してください。
→ 定義後は必ず描画して「狙ったエリアになっているか」を確認しましょう。 -
集計対象外のタッチ座標
- 画像の外にタッチされた座標
- どのエリアにも属さない座標
これらはすべてnoneとしてカウントされます。
→ 「タッチされなかった」ケースと区別して解釈してください。
-
エリア境界の確認
- エリアの境界を曖昧に定義すると、判定が想定とずれる場合があります。
特に鋭角な形や隣接するエリアが多い場合に注意が必要です。
→ GUI で定義後にプロット画像を確認し、「見た目」と「座標定義」が一致しているかチェック
- エリアの境界を曖昧に定義すると、判定が想定とずれる場合があります。
💡 ポイント
・「想定外のエリアにカウントされる」ほとんどの原因は 座標順序の乱れ or 定義ミス です。
・ デバッグ時は、まずエリアを色付きで描画し、座標が正しく結ばれているかを目視確認すると効率的です。
📌まとめ
今回は、画像内のエリアごとにタッチデータを集計・可視化する方法をご紹介しました。
💡 ポイント
この手法を使うことで、画像上の部位ごとの人気度や改善ポイントを直感的に把握できます。
参考リンク・素材について
GitHubリポジトリ
本記事で紹介したコードやサンプルデータはこちらのリポジトリで公開しています。
https://github.com/iwakazusuwa/area-touch-mit-license
画像素材
掲載している画像素材は「いらすとや」さんのものを加工して使っています。
Discussion