🐧
PythonでL9直交表を使ったコンジョイント分析 #2 – 効用値計算編(ファーストチョイス追加)
📌はじめに
これまでに推定した効用値(part-worth)は「数字の表」にとどまらず、実際に予測シェア(占有率)を計算するために使えます。
その一番シンプルな方法が ファーストチョイス(First Choice) です。
各回答者が「効用値が最も高いプロファイルを1つ選ぶ」と仮定して集計すると、
選択肢の人気度がすぐにわかります。
PythonでL9直交表を使ったコンジョイント分析#2 – 効用値計算編
のコードにファーストチョイスを追加してみます。
📌前回のおさらい
コード
#============================================
# 0. 必要ライブラリ
#============================================
import os
import pandas as pd
import statsmodels.api as sm
import matplotlib.pyplot as plt
import japanize_matplotlib # 日本語ラベル対応
import warnings
import sys
#============================================
# 1. ディレクトリ・ファイル・変数設定
#============================================
INPUT_FOLDER = '2_data'
OUTPUT_FOLDER = '3_output'
parent_path = os.path.dirname(os.getcwd())
input_ort_path = os.path.join(parent_path, INPUT_FOLDER, 'orthogonal_table.csv')
input_path = os.path.join(parent_path, INPUT_FOLDER, '調査データ.csv')
output_path = os.path.join(parent_path, OUTPUT_FOLDER)
os.makedirs(output_path, exist_ok=True)
# 出力ファイル名
#save_name_all = os.path.join(output_path, "効用値_全体.csv")
save_name_os = os.path.join(output_path, "効用値_OS別.csv")
save_name_id = os.path.join(output_path, "効用値_ID別.csv")
# グローバル変数(列名など)
glb_ID ='ID'
glb_QA ='QA'
glb_OS ='OS'
glb_QA_NO = f"{glb_QA}_番号"
glb_OS_ha ='所有'
#============================================
# 2. 直交表読み込み & 縦持ち化
#============================================
try:
df_design = pd.read_csv(input_ort_path, index_col=0, encoding="utf-8")
except UnicodeDecodeError:
df_design = pd.read_csv(input_ort_path, index_col=0, encoding="cp932")
# 属性名の一覧を取得
attributes = df_design.index.tolist()
# 列→行に変換(long形式)
df_long = df_design.T.reset_index().rename(columns={'index': glb_QA_NO})
df_long[glb_QA_NO] = df_long[glb_QA_NO].astype(int)
#============================================
# 3. 調査データ読み込み & 縦持ち化
#============================================
try:
df_survey = pd.read_csv(input_path, encoding="utf-8")
except UnicodeDecodeError:
df_survey = pd.read_csv(input_path, encoding="cp932")
# QA列(QA_0~QA_8)をリスト化
qa_cols = [f'{glb_QA}_{i}' for i in range(len(df_design.columns))]
# wide形式 → long形式へ変換
df_melt = df_survey.melt(
id_vars=[glb_ID, glb_OS_ha],
value_vars=qa_cols,
var_name=glb_QA,
value_name='評価値'
)
df_melt[glb_QA_NO] = df_melt[glb_QA].str.replace(f'{glb_QA}_', '', regex=False).astype(int)
#============================================
# データ結合
#============================================
df_merged = pd.merge(df_melt, df_long, on=glb_QA_NO, how='left')
#============================================
# 5. 全体効用値の推定
#============================================
all_levels = []
for attr in attributes: # attributes = ['OS','バッテリー','画面サイズ','価格']
levels = df_design.loc[attr].dropna().unique().tolist()
all_levels.extend(levels)
all_levels = list(dict.fromkeys(all_levels)) # 重複削除
#============================================
# 6.関数
#============================================
# 効用値を OS 別に計算する関数
def estimate_util_by_OS(df_merged, attributes, glb_OS, all_levels):
"""
df_merged: 評価値付きデータ
attributes: ['OS','バッテリー','画面サイズ','価格'] 等
glb_OS: 'OS'
all_levels: 直交表から取得した全水準リスト(横持ちdf_designから作成済み)
戻り値: OS別の穴ナシ効用値 DataFrame
"""
manufacturer_utilities = []
for manu, group in df_merged.groupby(glb_OS):
coef = estimate_util(group, attributes) # ダミー列形式
coef_full = pd.Series(index=all_levels, dtype=float) # 全水準で穴ナシ準備
for col in coef.index:
val = col.split('_',1)[-1] if '_' in col else col
coef_full[val] = coef[col]
coef_full[glb_OS] = manu # OS列追加
manufacturer_utilities.append(coef_full)
df_manufacturer_util = pd.DataFrame(manufacturer_utilities)
# 列順整理
priority_cols = [glb_OS]
ordered_cols = [c for c in all_levels if c in df_manufacturer_util.columns]
other_cols = [c for c in df_manufacturer_util.columns if c not in priority_cols + ordered_cols]
final_cols = priority_cols + ordered_cols + other_cols
df_manufacturer_util = df_manufacturer_util[final_cols]
df_manufacturer_util = df_manufacturer_util.fillna(0) # 欠けている水準は0
return df_manufacturer_util
# ダミー列作成関数
def get_dummies(df, attributes):
"""属性水準をダミー変換"""
return pd.get_dummies(df[attributes])
# 効用値推定関数
def estimate_util(df_group, attributes, id_col=None):
X = get_dummies(df_group, attributes)
y = df_group['評価値']
res = sm.OLS(y, X).fit()
coef = pd.Series(res.params)
if id_col:
coef[id_col] = df_group[id_col].iloc[0]
return coef
#============================================
# 7. OS(ブランド)別効用値の計算
#============================================
df_manufacturer_util = estimate_util_by_OS(df_merged, attributes, glb_OS, all_levels)
df_manufacturer_util.to_csv(save_name_os, index=False, encoding='utf-8-sig')
#============================================
# 8. ID別効用値(穴ナシ)
#============================================
utility_list = []
for id_, g in df_merged.groupby(glb_ID):
coef = estimate_util(g, attributes, glb_ID) # ID情報も保持
# 全水準で穴ナシ用のSeries
coef_full = pd.Series(index=[glb_ID] + all_levels, dtype=float)
coef_full[glb_ID] = coef[glb_ID] # IDをセット
# coefの値を正しい水準にセット
for col in coef.index:
if col == glb_ID:
continue
# ダミー列名の水準部分
val = col.split('_', 1)[-1] if '_' in col else col
if val in all_levels:
coef_full[val] = coef[col]
utility_list.append(coef_full)
# DataFrame化
df_utility = pd.DataFrame(utility_list)
# 所有列をマージ(IDで結合)
df_utility = df_utility.merge(
df_merged[[glb_ID, '所有']].drop_duplicates(),
on=glb_ID,
how='left'
)
# 列順整理:ID → 所有 → 全水準
cols = [glb_ID, '所有'] + [c for c in df_utility.columns if c not in [glb_ID, '所有']]
df_utility = df_utility[cols]
# CSV出力
df_utility.to_csv(save_name_id, index=False, encoding='utf-8-sig')
#============================================
# 9. OS別効用値のグラフ
#============================================
with warnings.catch_warnings():
warnings.simplefilter("ignore")
plt.rcParams['axes.unicode_minus'] = False
df_plot = df_manufacturer_util.set_index(glb_OS).T
df_plot.plot(kind='bar', figsize=(15, 6))
plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left', borderaxespad=0.)
plt.title('OS(ブランド)別効用値の比較')
plt.ylabel('効用値')
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
#============================================
# 10. ID別効用値ヒートマップ
#============================================
import seaborn as sns
import matplotlib.pyplot as plt
# IDをインデックス、全水準を列にしたデータフレームを作成
df_heat = df_utility.set_index('ID')[all_levels] # 'all_levels'は全属性水準リスト
plt.figure(figsize=(15, 10))
sns.heatmap(df_heat, cmap='coolwarm', center=0, annot=False)
plt.title('ID別効用値ヒートマップ')
plt.xlabel('属性水準')
plt.ylabel('被験者ID')
plt.tight_layout()
plt.show()
📌 追加するコード
上のコードの次に追加します
#============================================
# 11. ファーストチョイスによるシェア予測
#============================================
# df_utility: ID別の効用値
utilities_list = []
# IDごとの効用値を1行取り出して処理
for id_, g in df_utility.groupby(glb_ID):
g_row = g.iloc[0]
# QAごとにカードをループ
for qa_no, card_cols in df_design.iteritems(): # df_design = orthogonal_table.csv 読み込み
card_id = qa_no # 0〜8
card_levels = card_cols.values.tolist() # このカードの各属性水準
# 水準ごとの効用を合計
utility_sum = sum([g_row[level] for level in card_levels])
utilities_list.append({
glb_ID: id_,
"card_id": card_id,
"utility": utility_sum
})
utilities = pd.DataFrame(utilities_list)
# ファーストチョイス
def first_choice(utilities):
chosen = utilities.loc[utilities.groupby(glb_ID)["utility"].idxmax()]
share = chosen.groupby("card_id").size().reset_index(name="count")
share["share"] = share["count"] / share["count"].sum()
return share
fc_share = first_choice(utilities)
print(fc_share)
# 可視化(オプション)
fc_share.plot(x="card_id", y="share", kind="bar", legend=False)
plt.ylabel("予測シェア")
plt.title("ファーストチョイスによる予測シェア")
plt.show()
11. ファーストチョイスによるシェア予測
11-1. df_utility: ID別の効用値
-
df_utility: 回答者(ID)ごとの効用値がまとめられています - 列は属性水準名、行は回答者ごとになっています
11-2. IDごとの効用値を1行取り出して処理
-
groupby(glb_ID): 回答者ごとにグループ化 -
g_row = g.iloc[0]: その回答者の効用値1行だけを取得
11-3. QAごとにカードをループ
-
df_design.iteritems(): 列(選択肢ID)ごとに属性水準を取得 -
card_id = qa_no: 選択肢の番号を決定 -
card_levels = card_cols.values.tolist(): その選択肢の各属性水準をリスト化
❓選択肢とは❓
属性の組み合わせの1つ1つ を指します
分析に使う 商品パターン(属性の組み合わせ) をまとめたものです。

orthogonal_table.csv
- 1つ目の組み合わせ(iPhone + 3000mAh + 5インチ + 6万)が 1つの選択肢
- 2つ目の組み合わせが 別の選択肢
- 直交表の列1つ1つが選択肢に対応しています
つまり、「1つの製品イメージ」や「選択肢1つ分の条件の組み合わせ」です
11-4. 水準ごとの効用を合計
- 各選択肢の属性水準に対応する効用値を
g_row[level]で取り出し、合計 - この合計が、回答者にとってのその選択肢の「総効用値」になる
11-5. ファーストチョイス
-
utilities.groupby(glb_ID)["utility"].idxmax(): 各回答者の総効用が最大の選択肢を取得 - 選ばれた選択肢ごとに
countとshare(割合)を計算
出力例
card_id count share
0 0 34 0.377778
1 1 13 0.144444
2 3 9 0.100000
3 4 12 0.133333
4 5 21 0.233333
5 8 1 0.011111
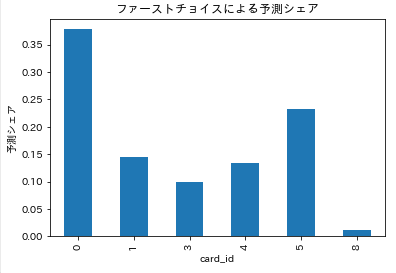
考察
- 最も選ばれた選択肢は
card_id 0(約38%) - 次に
card_id 5(約23%)、card_id 1(約14%)など - 選ばれなかった選択肢(2,6,7)は count = 0
誰も最大効用として選ばなかった
❓card_id 2,6,7が無いのはなぜ❓
だれも選ばなかったので、表示されませんでした
調査データの評価値 0(ニュートラル)とは別の意味です。
- 調査データ上の「0」はニュートラル評価(どちらでもない)
- ファーストチョイスの集計では選択されなかった選択肢は count = 0
- ファーストチョイスは「最も効用値が高い選択肢を1つだけ選ぶ」方法
- 各回答者は1枚しか選ばないので、評価が 0 でも、他の選択肢に効用値が高ければそちらが選ばれる
- その結果、card_id 2,6,7 のように誰も最大効用として選ばなかった選択肢は count=0 になる
⚠️ ここでの 0 は回答評価ではなく、「誰も選ばなかった選択肢」です。
📌ファーストチョイス集計のまとめ
- 効用値(part-worth)を計算
- ファーストチョイスで各回答者の最大効用の選択肢を選択
- 選択肢ごとの count を集計し、シェアを計算
- 選ばれなかった選択肢は count=0 / share=0
📌まとめ
ファーストチョイスを使うと、どの選択肢が人気か一目でわかるので
効用値や属性ごとの深堀と合わせると効果的です。
誰も選ばなかった選択肢(count=0)も、嗜好のばらつきが見えて面白いですね。
参考リンクについて
GitHubリポジトリ
本記事で紹介したコードやサンプルデータはこちらで公開しています。
Discussion