Python でコンジョイント分析#4 - 購買確率 Streamlit編
本記事はコンジョイント分析連載の第4回です。
第1回 PythonでパパッとL9直交表作成してコンジョイント分析#1 – 準備編
第2回 PythonでL9直交表を使ったコンジョイント分析#2 – 効用値計算編
第3回 Excelでできる!コンジョイント分析#3 – 購買確率シミュレーション編
第4回 Python でコンジョイント分析#4 - 購買確率 Streamlit編 ← 今回
📌はじめに
前回では、
Excelでユーザー別の効用値 × 製品構成から購買確率を算出・可視化しましたが、
- 属性を変更するたびに表を手作業で更新する
- 補間や計算式の調整も面倒
という課題がありました。
そこで今回は、PythonでインタラクティブなUIを作成してみました。
PythonでインタラクティブなUI を作成してみました。
❓ なぜPythonでUI化したのか❓
- Excelでは表の更新や線形補間が手作業で手間
- 属性を変更して比較するには、インタラクティブなUIの方が圧倒的に楽
📌 Streamlitを用いたUIでできること
属性(バッテリー・画面サイズ・価格など)をプルダウンで選択
- 各ブランドの購買確率を自動計算&棒グラフで可視化
- 属性を変えるたびにリアルタイムで再計算
-
誰にどの商品が刺さるかがひと目でわかる!
ユーザー別効用値を使ってブランドごとの購買確率をリアルタイムで計算します
📌サンプルデータ
① 効用値_ID別.csv:ユーザー × 属性効用値

PythonでL9直交表を使ったコンジョイント分析 – 効用値計算編
② default.csv :ブランド別スマホのスペック
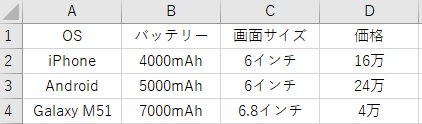
③ interpolation_rules.csv:中間値を補完するルール表(線形補間)

属性の選択肢を柔軟にし、定義されていないスペックにも対応できるように線形補間のルール表を作成します。
UI上で
「10万円の場合は?」
「7インチだったらどうなる?」
といった中間的な数値を選んだときに、効用値を線形補間するためのルールを定義したCSVです(自作)。
この表を使うことで、定義されていないスペック値でもスムーズに効用値を導出できます。
補足
- from_label / to_label:補間する軸(例:バッテリー)を指定
- from_val / to_val:補間の区間(数値、例:4000〜6000)
- interp_val:知りたい中間値(例:5000)
- new_label:補間後の名前(例:5000mAh)
④ level.csv:属性と水準の定義マスタ

UIのプルダウン選択肢や、効用値の並び順の整備に使用しています。
補完値も含まれているため、可視化・補間の両方で役立ちます。
このマスタを使うことで、UIのプルダウン順やグラフの並びも整理できます。
コード解説
# ------------------------
# 0. 必要ライブラリ
# ------------------------
import streamlit as st
import pandas as pd
import numpy as np
import plotly.express as px
import io
# グローバル設定(ブランド + 列名)
brands = ["iPhone", "Android", "Galaxy M51"]
# UI用列名
col_OS = "OS"
col_battery = "バッテリー"
col_screen = "画面サイズ"
col_price = "価格"
# カテゴリ名
cat_brand = 'brand'
cat_battery = "battery"
cat_screen = "screen"
cat_price = "price"
# ------------------------
# Streamlit UI設定
# ------------------------
st.set_page_config(page_title="購買確率シミュレーション", layout="centered")
st.title("📊 購買確率シミュレーション")
# ------------------------
# 1.線形補間関数
# ------------------------
def linear_interp(df, low_col, high_col, low_val, high_val, new_val, new_col):
if high_val == low_val:
df[new_col] = df[low_col]
else:
df[new_col] = df[low_col] + (df[high_col] - df[low_col]) * ((new_val - low_val) / (high_val - low_val))
return df
# ------------------------
# 2.CSV読み込み(安全版)
# ------------------------
def safe_read_csv(uploaded_file, **kwargs):
try:
content = uploaded_file.getvalue()
if len(content) == 0:
st.warning(f"{uploaded_file.name} は空のファイルです")
return None
return pd.read_csv(io.BytesIO(content), encoding='utf-8-sig', **kwargs)
except Exception as e:
st.error(f"{uploaded_file.name} の読み込み中にエラーが発生しました: {e}")
return None
0. 必要ライブラリ
本アプリでは以下のライブラリを使用しています:
- streamlit (st):UI作成とインタラクティブ操作
- plotly.express (px):棒グラフなどの可視化
- io:アップロードされたCSVをバイトデータとして扱う
1. 線形補間関数
-
linear_interp:「2つの値の間の効用値を自動で計算する関数」 -
例えばバッテリー容量 4000 と 6000 の間で 5000 を選んだ場合
→ 4000 と 6000 の効用値から、5000 の効用値を自動で計算します -
もし同じ値なら、そのままの効用値を使います
-
計算結果は新しい列として表に追加されます
💡 ポイント
- ユーザーが中間値を選んでも、自動で効用値を計算してくれる
- 表示やグラフにすぐ使える
補足
この関数は、価格・画面サイズ・バッテリー容量 などの数値の間を自動で計算するために使います。
たとえば…
- 「6.0インチ = +0.2」「6.8インチ = +0.6」のとき
- 「7インチ」を選ぶと → 自動で +0.7 などに補間されます
📄 interpolation_rules.csv にルールを書いておけば、自動で補間値が読み込まれます。
📈 補間範囲外(外挿)の値でも、自動で予測されます。
2. CSV読み込み(安全版)
- Streamlit ではユーザーが自由にファイルをアップロードできるので、例外処理で安全に読み込むことが大切
- 読み込んだ DataFrame はそのまま計算やグラフに使える
-
io.BytesIO(content) :バイト列をファイルのように扱い、
pandas.read_csv()に渡す
❓ラッパーとは❓
既存の処理を包んで(wrap)、使いやすく・安全にした補助的な関数やクラスのことです。
この関数も pd.read_csv() をラップしており、ファイルの中身チェックやエラー処理を追加した例です。
# ------------------------
# 3.ファイルアップローダー
# ------------------------
level_file = st.file_uploader("level.csvをアップロードしてください", type="csv")
rule_file = st.file_uploader("interpolation_rules.csvをアップロードしてください", type="csv")
default_file = st.file_uploader("default.csvをアップロードしてください", type="csv")
uploaded_file = st.file_uploader("効用値_ID別.csv をアップロードしてください", type="csv")
df_levels = None
if uploaded_file is not None and default_file is not None:
df = safe_read_csv(uploaded_file)
df_default = safe_read_csv(default_file)
if df is None or df_default is None:
st.stop()
st.success("✅ 効用値とデフォルト構成の読み込み成功!")
# 補間処理
if rule_file is not None:
rules = safe_read_csv(rule_file)
if rules is not None:
for _, row in rules.iterrows():
df = linear_interp(
df,
low_col=row["from_label"],
high_col=row["to_label"],
low_val=float(row["from_val"]),
high_val=float(row["to_val"]),
new_val=float(row["interp_val"]),
new_col=row["new_label"]
)
st.success("✅ 補間処理完了!")
# level.csv 読み込み
if level_file is not None:
df_levels = safe_read_csv(level_file, header=None)
if df_levels is not None:
st.success("✅ level.csv 読み込み成功!")
desired_order = df_levels[0].tolist()
else:
desired_order = []
else:
st.warning("level.csvをアップロードしてください")
desired_order = []
# 列順入れ替え(存在する列のみ)
existing_cols = [c for c in desired_order if c in df.columns]
remaining_cols = [c for c in df.columns if c not in existing_cols]
df = df[existing_cols + remaining_cols]
st.subheader("✅ 補間済み効用値データ")
st.dataframe(df)
st.subheader("✅ デフォルト製品構成")
st.markdown("---")
st.dataframe(df_default)
3. ファイルアップローダー
アップロードするファイル
- level.csv:属性と水準の定義マスタ(プルダウン順や並び順を整理)
- interpolation_rules.csv:線形補間ルール
- default.csv:ブランド別スマホのデフォルト構成
- 効用値_ID別.csv:ユーザーごとの効用値データ
出力例

-
df = safe_read_csv(uploaded_file):アップロードされたCSVを安全に読み込み -
st.success("✅ 読み込み成功!"):読み込み成功メッセージを表示
出力例

-
df = linear_interp(...):補間ルールがあれば効用値を自動補間
補足
指定した2列(from_label と to_label)の値をもとに、
中間値(interp_val)に対応する効用値を線形補間し、
新しい列(new_label)としてデータフレーム df に追加します。
-
df = df[existing_cols + remaining_cols]:level.csv があれば列順をプルダウン順に揃える
補足
- 「水準順に並び替えたい列」→「それ以外の列」の順で再構成
- 例:👉 並び替え後は
desired_order = ["3000mAh", "4000mAh", "5000mAh"] df.columns = ["id", "OS", "4000mAh", "5000mAh", "7000mAh"]["4000mAh", "5000mAh", "id", "OS", "7000mAh"]
-
st.dataframe(df):補間済み効用値データを表示
出力例

-
st.dataframe(df_default):デフォルト製品構成を表示
出力例

💡ポイント
この部分があるおかげで、ユーザーは自分のデータをアップロードするだけで、自動で補間や整列が完了し、すぐに分析や可視化が可能になります。
⚠️ level.csv だけ【level.csvをアップロードしてください】表示する理由
else:
st.warning("level.csvをアップロードしてください")
desired_order = []
level.csv は属性や水準の表示順やプルダウン順を決めるマスタです。
- 無くても効用値や補間処理は動くけど、列の順序がバラバラになる
- UIで見やすくグラフも整理された状態で表示したい場合は必須
他のファイル(効用値や default.csv)は計算や補間に必須ですが、
level.csv は任意でアップロード可能。無ければ警告だけ出して続行します。
# ------------------------
# 4.レベル選択 & 確率計算
# ------------------------
if df_levels is not None and df_default is not None:
df_levels.columns = ['level']
def detect_category(val):
val = str(val).lower()
if 'mah' in val:
return cat_battery
elif 'インチ' in val:
return cat_screen
elif '万' in val:
return cat_price
elif any(keyword.lower() in val for keyword in brands):
return cat_brand
else:
return 'unknown'
df_levels['category'] = df_levels['level'].astype(str).apply(detect_category)
grouped_levels = df_levels.groupby('category')['level'].apply(list).to_dict()
# 空リスト対策
brand_options = grouped_levels.get(cat_brand, [])
battery_options = grouped_levels.get(cat_battery, [])
screen_options = grouped_levels.get(cat_screen, [])
price_options = grouped_levels.get(cat_price, [])
if not (brand_options and battery_options and screen_options and price_options):
st.warning("level.csvのデータが不足しています")
st.stop()
target_brand = st.selectbox("変更するブランドを選んでください", brand_options)
battery_choice = st.selectbox(col_battery, battery_options)
screen_choice = st.selectbox(col_screen, screen_options)
price_choice = st.selectbox(col_price, price_options)
# デフォルト構成辞書(ネスト辞書)
default_dict = {
row[col_OS]: {
col_battery: row[col_battery],
col_screen: row[col_screen],
col_price: row[col_price]
} for _, row in df_default.iterrows()
}
# 列存在チェック付きで構成取得
def get_config(brand_name):
if brand_name not in default_dict:
st.warning(f"{brand_name} が df_default に存在しません")
return None
cols = [
brand_name,
default_dict[brand_name][col_battery],
default_dict[brand_name][col_screen],
default_dict[brand_name][col_price]
]
missing_cols = [col for col in cols if col not in df.columns]
if missing_cols:
st.warning(f"{brand_name} の構成に以下の列が見つかりません: {missing_cols}")
return None
return [df[col].fillna(0) for col in cols] # NaNを0で埋める
conf_dict = {b: get_config(b) for b in brands}
# 選択構成上書き
if target_brand in brands and conf_dict[target_brand]:
conf_dict[target_brand] = [
df[target_brand].fillna(0),
df[battery_choice].fillna(0),
df[screen_choice].fillna(0),
df[price_choice].fillna(0)
]
# sum列
sum_cols = []
for b in brands:
col_sum = f"sum_{b}"
sum_cols.append(col_sum)
df[col_sum] = sum(conf_dict[b]) if conf_dict[b] else 0
# ソフトマックス安定化
max_sum = df[sum_cols].max(axis=1)
exp_vals = [np.exp(df[f"sum_{b}"] - max_sum) for b in brands]
denom = sum(exp_vals)
for b, ev in zip(brands, exp_vals):
df[f"p_{b}"] = ev / denom
# 平均確率
mean_probs_selected = df[[f"p_{b}" for b in brands]].mean()
mean_probs_selected.index = brands
# デフォルト構成の確率計算
brands_list, sum_eff = [], []
for _, row in df_default.iterrows():
os_col = row[col_OS]
cols = [os_col, row[col_battery], row[col_screen], row[col_price]]
cols = [c for c in cols if c in df.columns]
total_eff = sum(df[c].mean() for c in cols)
brands_list.append(row[col_OS])
sum_eff.append(total_eff)
df_sum = pd.DataFrame({col_OS: brands_list, "default_sum": sum_eff})
exp_vals = np.exp(df_sum["default_sum"] - df_sum["default_sum"].max())
df_sum["p_default"] = exp_vals / exp_vals.sum()
df_compare = pd.DataFrame({
col_OS: df_sum[col_OS],
"デフォルト構成": df_sum["p_default"],
"選択構成": mean_probs_selected.values
})
# Plotly 可視化
fig = px.bar(
df_compare,
x=col_OS, y=["デフォルト構成", "選択構成"],
barmode="group", height=500,
color_discrete_sequence=["blue", "red"]
)
fig.update_traces(texttemplate="%{y:.0%}", textposition="outside")
fig.update_layout(
yaxis_tickformat=".0%",
yaxis_range=[0, 1.1],
font=dict(size=18),
title="購買確率の比較(デフォルト構成 vs 選択構成)"
)
st.plotly_chart(fig, use_container_width=True)
else:
st.warning("ファイルをアップロードしてください")
4. レベル選択 & 確率計算
ユーザーがUI上でブランドや属性を選び、その構成に基づいて購買確率を計算・可視化します。
-
df_levels.columns = ['level']: 属性をカテゴリ分け(バッテリー・画面サイズ・価格・ブランド) -
detect_category: カテゴリごとに選択肢を整理- ブランド、バッテリー容量、画面サイズ、価格の順に取得
- 値に含まれるキーワードをもとにカテゴリを判定
| 値 | 判定カテゴリ |
|---|---|
| "5000mAh" | battery |
| "6.5インチ" | screen |
| "10万円" | price |
| "iPhone15" | brand |
-
st.selectbox: プルダウンでユーザーが選択
出力例

-
default_dict = {...}:各行を OS(ブランド)名をキーとして、バッテリー・画面サイズ・価格の情報をネストした辞書にします。
❓ネストとは❓
「辞書の中に辞書があることをネスト構造 と呼びます。
✅ 普通の辞書(ネストなし)
{"iPhone": "3000mAh"}
単に "iPhone" というキーに "3000mAh" という値が入っているだけです。
✅ ネストされた辞書(入れ子)
| ブランド名 | battery | screen | price |
|---|---|---|---|
| iPhone | 3000mAh | 5インチ | 10万 |
| Android | 4000mAh | 6.5インチ | 8万 |
{"iPhone": {"battery": "3000mAh","screen": "5インチ","price": "10万"}}
これが「ネストされた辞書構造(dictionary of dictionaries)」です。
-
iPhone_conf / android_conf / galaxy_conf = [...]:プルダウンで選択された値を使ってブランドの構成を更新- ユーザーが選んだ属性(バッテリー容量・画面サイズ・価格)に合わせて、対象ブランドの効用値リストを動的に変更します。
-
df["sum_iPhone"] = sum(iPhone_conf):ブランドごとに効用値を合計- NaN は 0 に置換して計算します。
-
np.exp(df["sum_iPhone"] - max_sum):ソフトマックス関数で確率化- 合計効用値を購買確率に変換
- 最大値を引いて安定化(オーバーフロー防止)
-
df[["p_iPhone","p_Android","p_Galaxy"]].mean():平均確率を計算- デフォルト構成と選択構成を比較するために集計します。
-
px.bar(df_compare, ...):グラフで可視化- Plotly の棒グラフで「デフォルト構成 vs 選択構成」を描画
- パーセンテージ表記で直感的に比較できます
出力例

-
st.warning("...")/fillna(0):エラー処理と安全策- 必要な列やファイルが揃っていない場合は警告を表示して処理を停止
- NaN を 0 に置換し、UI入力ミスでも計算が壊れないようにします
📌UIを使ってみる
ターミナルを開き
PS C:\Users\user> cd C:\Users\user\保存されてるフォルダ
PS C:\Users\user\aa.pyが保存されてるフォルダ> streamlit run csvapp.py
1. ファイルアップロード画面
起動すると、ファイルをアップロードする画面が表示されます。
指定された level.csv / interpolation_rules.csv / default.csv / 効用値_ID別.csv をアップロードしてください。

2. 補間済みの効用値データ表示
アップロード後、補完済みの効用値データ表示。
👉ダウンロード可能

3. デフォルトの製品情報表示
ブランドごとのデフォルト構成が確認できます。

4. プルダウンで比較したい属性を選択
UI上のプルダウンから「ブランド・バッテリー容量・画面サイズ・価格」を選びます。

5. 結果の可視化
選んだ構成に応じて購買確率が再計算され、棒グラフで表示されます。
「デフォルト構成 vs 選択構成」を直感的に比較できます。

🎯グラフの色がやや鮮やかすぎる場合は、color_discrete_sequenceで調整可能です。
例: ["#1f77b4", "#ff7f0e"] ように柔らかいトーンにすると見やすくなります。
📌Excelで作ったグラフを比較
🎯 前回、Excelで計算・可視化した結果と比較してみました。
Streamlitのグラフでは、
効用値を ロジットモデル(ソフトマックス変換) に通して購買確率を算出しています。
その際の 平均の取り方や指数変換のタイミング が Excel と異なるため、数値に若干の差が生じます。
とはいえ、傾向としては概ね一致しており、
👉 Python実装でもロジックが正しく再現されていることが確認できました。

💡 補足
- Python版では
np.interp()を用いて効用値を線形補間し、その後ロジットモデルで確率化しています。 - Excel版では「補間値に関数を適用 → 平均化」の順で処理しているため、処理順序や丸め誤差の違い により数値に微小なズレが出ることがあります。
📌まとめ
Excelでやると手間がかかる 線形補間や効用値の計算 も、
このアプリなら ブランドやスペックを選ぶだけで購買確率まで自動計算 できます。
さらに、Python × Streamlit を使えば、
👉 データ処理 と UIによる可視化 を一体化したツールが簡単に作れるのも魅力です。
ぜひ試してみてください!
参考リンクについて
GitHubリポジトリ
本記事で紹介したコードやサンプルデータはこちらで公開しています。
Discussion