Raspberry Pi 5 で高性能な日本語 LLM RakutenAI-7B-chat を動かす





Raspberry Pi 5 で高性能な日本語 LLM RakutenAI-7B-chat を動かす
概要
- Raspberry Pi 5 / 8GBで日本語LLM RakutenAI-7B-chatの量子化モデルを動かす手順
- RakutenAI-7B-chat は「7B級のモデルの中ではnejumi.aiの評価ベンチマークのスコアで上位のパフォーマンスを達成」
- 合計2万円程度でローカルLLMサーバをセットアップ
- 量子化により、高性能な日本語LLM 7BモデルがGPUなしメモリ8GBマシンで動作
- 6bit量子化モデルでは毎秒1.72トークン生成可能(量子化による品質低下は0.1%以下)
Rakuten AI 7B とは
Rakutenのプレスリリースより
「Rakuten AI 7B」は、フランスのAIスタートアップであるMistral AI社のオープンモデル「Mistral-7B-v0.1」(注4)を基に、継続的に大規模なデータを学習させて開発された70億パラメータの日本語基盤モデルです。
3. オープンな日本語LLMにおいてトップの評価を獲得
本基盤モデルと本インストラクションチューニング済モデルは、言語モデル評価ツール「LM Evaluation Harness」(注8)の基準において、日本語と英語のLLMの高いパフォーマンスが評価され、高性能であることが実証されました。
プレスリリース公開時点(2024-03-21)で、7Bクラスの「オープンな日本語LLMにおいてトップの評価」とのこと。
Note: 同じ Mistral-7B-v0.1 ベースの Swallow-MS との比較が気になるところ。Swallow-MS のインストラクションチューニング版がリリースされたら Raspberry Pi 5でのセットアップを記事にまとめる予定。
WandBのNejumi LLMリーダーボード Neoによる RakutenAI-7B-chat の評価
特にRakuten/RakutenAI-7B-chatはMT-benchでのスコアがよく、7B級のモデルの中ではnejumi.aiの評価ベンチマークのスコアで上位のパフォーマンスを達成しています
MT-benchで見ると、数学的推論(math)やcodingのスコアは大きく変わらないものの、日本語での対話能力(roleplay)や比較的長い文章生成が求められる問題(writingやstem)でスコアの大きな改善があったのは面白いポイントだと思います。
2024-03-22の時点で、WandBによる日本語LLMのベンチマークサイトNejumi LLMリーダーボード Neoにおいて、「7B級のモデルの中ではnejumi.aiの評価ベンチマークのスコアで上位のパフォーマンスを達成」とのこと。
Raspberry Pi 5のセットアップ
以下記事を参考にRaspberry Pi 5をセットアップし、 llama.cppのインストール まで実行したものとして進める。
また、ハードウェア構成はこのセクションを参照。合計2万円程度でセットアップ可能。
なお、macOS等の環境でも同様にllama.cppをセットアップすれば実行可能。メモリ16GBのMacBook Pro 13-inch 2020 (Intel Core i5)で動作確認済み。
RakutenAI-7B-chat のセットアップ
参考資料
以下の資料を参考にセットアップを進める。
- RakutenのHuggingFaceリポジトリ
- 量子化モデル(非公式)
- 自分で量子化したい場合は以下を参考に
Note: この記事で実行するのはRakutenが公式にリリースしたモデルではなく非公式の量子化されたモデルであるため、性能や不具合は量子化による可能性があることに注意。
モデルファイルのダウンロード
RakutenAI-7B-chat の6bit量子化モデルをダウンロード(5.6GB)。
aria2c -x 5 "https://huggingface.co/mmnga/RakutenAI-7B-chat-gguf/resolve/main/RakutenAI-7B-chat-q6_K.gguf" -d "models" -o "RakutenAI-7B-chat-q6_K.gguf"
コマンドライン実行
コマンドラインでプロンプトを与えて実行してみる。チャットテンプレートはこちらを参照。
./main -ngl 0 -t 4 -c 8192 --temp 0.0 -e \
-m "models/RakutenAI-7B-chat-q6_K.gguf" \
-p "A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions.\nUSER: 日本の首都について教えて下さい。\nASSISTANT:"
実行結果。若干のスカイツリー推し。なお、温度パラメータ(--temp)を0.7程度に上げて生成の多様性を高めると、ハルシネーションが起き易くなる。
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions.
USER: 日本の首都について教えて下さい。
ASSISTANT: 日本の首都は、東京です。
東京は、日本の政治、経済、文化の中心地です。
東京は、1300万人の人口を抱える世界でも有数の大都市です。
東京には、皇居、東京スカイツリー、東京タワー、東京国立博物館、東京スカイツリータウンなどの観光スポットがあります。 [end of text]
llama_print_timings: load time = 2433.81 ms
llama_print_timings: sample time = 5.28 ms / 76 runs ( 0.07 ms per token, 14402.12 tokens per second)
llama_print_timings: prompt eval time = 13234.61 ms / 47 tokens ( 281.59 ms per token, 3.55 tokens per second)
llama_print_timings: eval time = 43595.59 ms / 75 runs ( 581.27 ms per token, 1.72 tokens per second)
llama_print_timings: total time = 56929.52 ms / 122 tokens
量子化のビットを変更して生成トークン/秒(上記ログのeval time)を計測。
| モデル | 量子化 | 生成トークン/秒 |
|---|---|---|
| RakutenAI-7B-chat-q2_K.gguf | 2bit | 3.36 |
| RakutenAI-7B-chat-q3_K_S.gguf | 3bit | 3.18 |
| RakutenAI-7B-chat-q4_K_S.gguf | 4bit | 2.44 |
| RakutenAI-7B-chat-q5_K_S.gguf | 5bit | 2.03 |
| RakutenAI-7B-chat-q6_K.gguf | 6bit | 1.72 |
体感的には4トークン/秒を下回ると処理の遅さを感じるが、1.72トークン/秒は我慢すればギリギリ使えるレベル。性能と速度のトレードオフによって4〜6bit量子化モデル辺りを検討する必要がある。なお、6bit量子化モデルであれば、fp16モデルと比べて0.1%以下の品質低下であることが報告されている。詳細は参考: 量子化するとどの程度品質が低下するか?の節を参照。
対話モードで実行
対話モード(-i)で実行。
./main -ngl 0 -t 4 -c 8192 --temp 0.0 -e -i --color \
-m "models/RakutenAI-7B-chat-q6_K.gguf" \
-p "A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions.\nUSER: こんにちは!\nASSISTANT: " \
--in-prefix "USER: " \
--in-suffix "ASSISTANT:"
Ctrl-c で停止。
HTTPサーバとして実行
8080 ポートを公開するので、先にファイアウォールの設定を変更してリブートしておく。
sudo ufw allow 8080 # http for llama.cpp
sudo ufw status verbose
sudo reboot
サーバを起動。チャットテンプレートは該当するものがないが、Mistral が llama2 なのでそれを指定。
./server -t 4 -c 8192 -m "models/RakutenAI-7B-chat-q6_K.gguf" --chat-template "llama2" --port 8080 --host 0.0.0.0
ブラウザで http://pi5.local:8080 にアクセス。
RakutenAI-7B-chatの設定はこのページを参考に、以下のようにする。
- Prompt
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions.
- User name
USER
- Bot name
ASSISTANT
- Prompt template
{{prompt}}
{{history}}
{{char}}:
- Chat history template
{{name}}: {{message}}
- Temperature
0.0

要約タスク
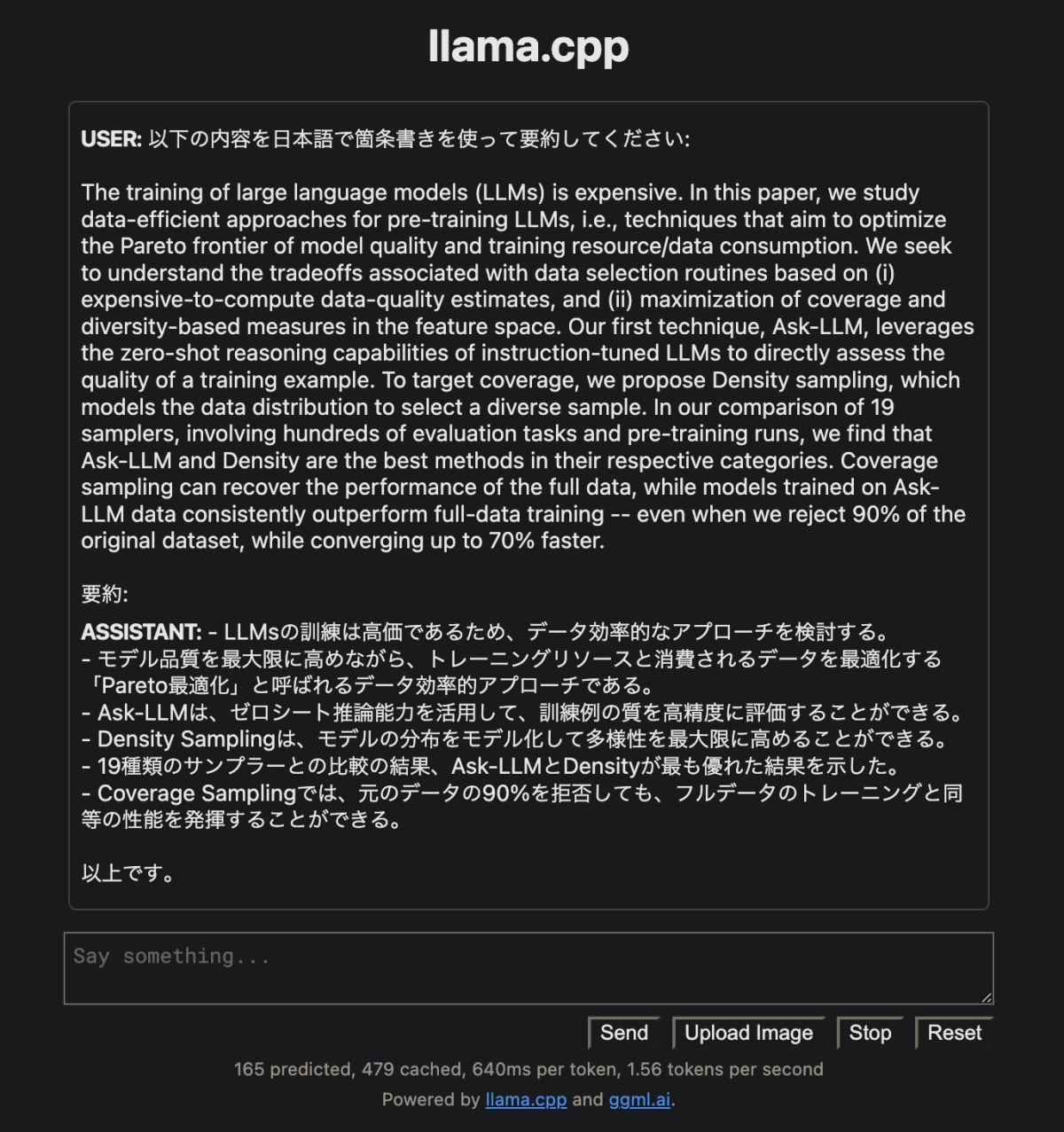
Say something... のテキストエリアに以下のような要約タスクを入力して Send ボタンを押すと要約が表示される。
以下の内容を日本語で箇条書きを使って要約してください:
The training of large language models (LLMs) is expensive. In this paper, we study data-efficient approaches for pre-training LLMs, i.e., techniques that aim to optimize the Pareto frontier of model quality and training resource/data consumption. We seek to understand the tradeoffs associated with data selection routines based on (i) expensive-to-compute data-quality estimates, and (ii) maximization of coverage and diversity-based measures in the feature space. Our first technique, Ask-LLM, leverages the zero-shot reasoning capabilities of instruction-tuned LLMs to directly assess the quality of a training example. To target coverage, we propose Density sampling, which models the data distribution to select a diverse sample. In our comparison of 19 samplers, involving hundreds of evaluation tasks and pre-training runs, we find that Ask-LLM and Density are the best methods in their respective categories. Coverage sampling can recover the performance of the full data, while models trained on Ask-LLM data consistently outperform full-data training -- even when we reject 90% of the original dataset, while converging up to 70% faster.
要約:
- 要約タスクの感想
- 概ね要約出来ている印象
-
日本語でをつけないと英語で要約してしまう場合がある - 気になる部分
-
ゼロシート推論→ゼロショット推論 -
パレート最適はアプローチというより目標 - 要約の最終行が間違っている
- カバレッジサンプリングはフルデータの性能と同等
- Ask-LLMは一貫してフルデータの性能を上回る(90%削減, 70%高速はAsk-LLMについての話でカバレッジサンプリングについての話ではない)
-
参考: 量子化するとどの程度品質が低下するか?
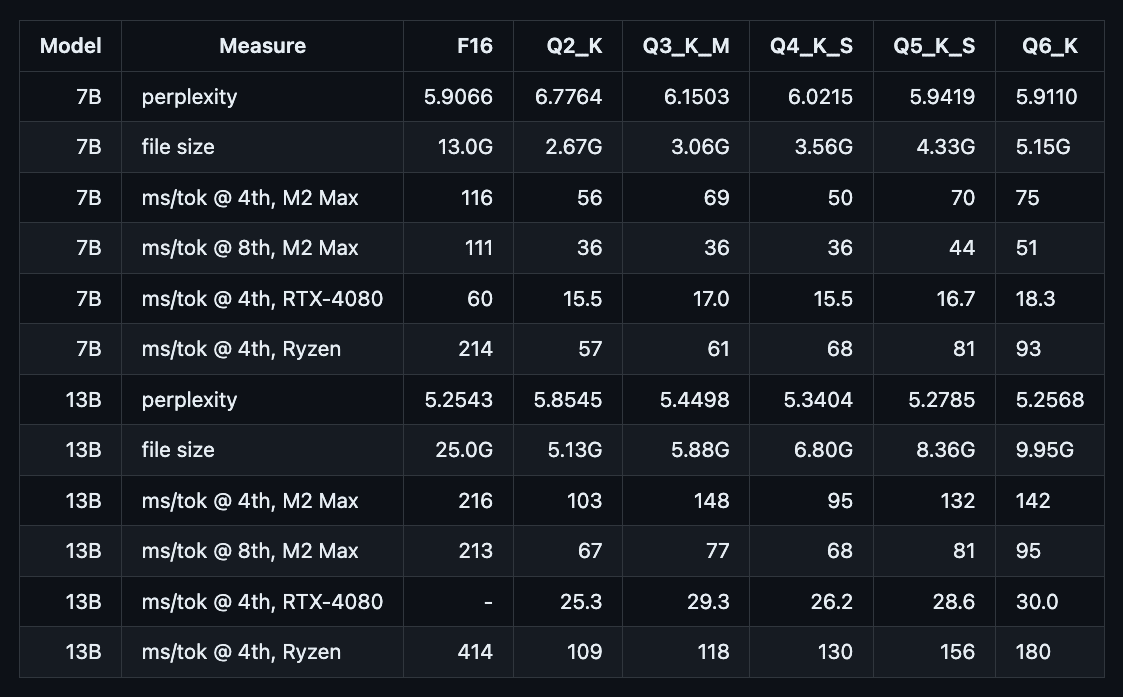
以下ページ(若干昔のページなので現在はもっと改善している可能性あり)によると、

Perhaps worth noting is that the 6-bit quantized perplexity is within 0.1% or better from the original fp16 model.
LLaMAの6bit量子化されたモデルのperplexityの性能低下は、オリジナルのfp16モデルから0.1%以下とのこと。
例えば、以下の表において、LLaMAの6bit量子化モデル(Q6_K)とfp16モデル(F16)のperplexityの性能比は、5.9110 / 5.9066 = 1.00074 となり、量子化による性能低下は 0.074% (0.1%以下)。
まとめ
- Raspberry Pi 5 / 8GBで日本語LLM RakutenAI-7B-chatの量子化モデルを動かす手順
- RakutenAI-7B-chat は「7B級のモデルの中ではnejumi.aiの評価ベンチマークのスコアで上位のパフォーマンスを達成」
- 合計2万円程度でローカルLLMサーバをセットアップ
- 量子化により高性能な日本語LLM 7Bモデルが、GPUなしメモリ8GBマシンで動作
- 6bit量子化モデルでは毎秒1.72トークン生成可能(量子化による品質低下は0.1%以下)
以上
Discussion