駆け出しデータサイエンティストによるスキルセットの整理:キャリア設計の考え方
はじめに
こんにちは、SE出身の駆け出しデータサイエンティストの「マチ」です。以前、「【キャリア設計】得意分野の見つけ方:駆け出しデータサイエンティスト向け」という記事で、自分に合ったキャリアの方向性について考察しました。
今回はもう少し具体的に、「どんなスキルをどのように整理すればよいか」というテーマで考えてみました。整理にあたって、以下の2つを参考にしました。
- 一般社団法人データサイエンティスト協会が定義している
「データサイエンティストに求められるスキルセット」 - 初心者データサイエンティストに向けて独断と偏見だけで選んだ
読んでおいてもらいたい情報まとめ
下図の通り、スキルは3つの領域に分けられます。それぞれについて、自分の経験や視点を交えながら紹介していきます。
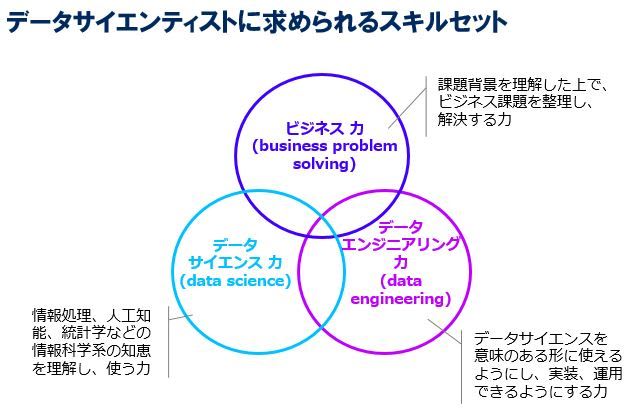
データサイエンティスト協会のページより引用
1.ビジネス力
データ分析を価値につなげるには、技術だけでは不十分です。ビジネスの構造や課題を理解するスキルが欠かせません。

1-1.業務理解力と課題整理力
分析の背景や目的を正しく理解しないまま進めてしまうと、的外れな結果につながる可能性があります。以下のような取り組みを通じて、業務や課題の全体像を把握することが重要です。
- 顧客の立場や業界構造、業務フローの全体像を把握する
- 自社・他社の過去事例を調査し、成功・失敗の傾向を把握する
- 現場ヒアリングを通して、データの収集方法や業務上の制約条件を確認する
- プロジェクトの背景や目的を明確にし、「なぜこの課題に取り組むのか」を言語化する
1-2.仮説・評価指標を設計する力
良い分析は、良い仮説から始まります。何を検証すべきかを言語化する力は、結果の解釈や次のアクション設計にも直結します。また、成果を評価するためのKPIや評価指標を適切に設計することも重要です。目的に合った指標を選ぶことで、分析の価値を定量的に伝えられるようになります。
参考書籍
1-3.ステークホルダ対応と対話力
-
ステークホルダーとの調整
分析を現場に届けるには、「相手に合わせて伝える力」も欠かせません。関係者と要件を整理し、スコープやタスクの前提を明確にしながら進めていくと、合意形成もしやすくなります。 -
ストーリーテリング・資料化
分析結果を資料にまとめる際には、ストーリー性のある構成と視覚的な工夫が求められます。非エンジニアにも伝わる言葉で、説得力のあるプレゼンができると良いでしょう。
参考書籍
2.データサイエンス力
データに潜む構造やパターンを見つけ、価値ある示唆に変換するためのスキルです。

2-1.探索的データ分析(EDA)
EDAでは、分析の前にデータの傾向や特性を把握します。具体的には、以下のような作業を行います。
- 欠損値や外れ値の確認
- 分布の把握とグルーピング
- 相関関係の確認や仮説検定(t検定・カイ二乗検定 など)
参考書籍
2-2.モデリングと予測
目的変数と説明変数の関係を数式やアルゴリズムで表現し、予測や分類を行います。
-
特徴量設計
カテゴリのエンコーディングやラグ変数の作成などを行います。 -
モデル構築
回帰・分類・クラスタリングなどのモデルを構築します。 -
評価とチューニング
目的に応じて精度、F1スコア、AUC、シャープ比などを使い分けます。
参考書籍・記事
2-3.因果推論と実験設計
単なる相関ではなく、因果関係を明らかにする力も求められます。なお、A/Bテストなどを繰り返していく際には、実験条件や結果を継続的に記録・比較できるようにしておくことも重要です。こうした「実験管理」は、再現性の確保や継続的改善に不可欠なプロセスです。
- A/Bテストなどを設計する際には、適切なサンプルサイズの見積もりや、
効果を検出するための統計的な検出力[1]の確保が求められます。 - DID(差分の差)やPSM(傾向スコアマッチング)などの因果推論手法を用いて、
交絡因子[2]の影響を抑え、共変量[3]のバランスを調整します。
参考書籍
3.データエンジニアリング力
データを「使える形」に整えるためのスキルです。インフラ的な部分も含め、現場では欠かせない領域です。

3-1.データ取得とクレンジング
SQL、API、DWHなどからデータを取得し、分析しやすい形に整える必要があります。Pandasなどを用いて、以下のような処理を行います。
- 欠損値の補完・正規化
- データの結合・分離
- 型の変換・文字列処理
参考書籍・記事
3-2.分析基盤・ワークフローの構築
分析やモデリングを安定的に実行するためには、環境構築や処理の自動化も必要です。例として以下が挙げられます。
- AirflowによるETLパイプラインの構築
- JupyterやDocker、仮想環境を使った実行環境の構築や管理
3-3.モデルの運用と本番展開
構築したモデルを現場で使うには、保存・再学習・API化などの運用設計が必要になります。
- Pickleやjoblibによるモデルの保存
- MLflowでのバージョン管理や再学習の仕組み作り
- モデルのAPI化と監視・自動更新
参考書籍
おわりに
今回紹介した分類は、キャリア設計だけでなく、現場でのスキルギャップ把握や育成計画にも役立つと思います。最初から全部できる必要はありません。自分の得意・不得意を整理して、どこから伸ばすかを明確にすることが第一歩です。これからも「データで課題を解く」ことを目指して、着実にスキルを積み上げていきたいと思います。
-
検出力とは、「効果があるのに見逃さない力」のことです。たとえば、A/Bテストで本当に差がある場合に、それをきちんと見つけ出すために必要な実験の信頼度を表します。検出力が低いと、せっかくの改善があっても「効果なし」と誤って判断してしまうリスクがあります。 ↩︎
-
交絡因子とは、分析で調べたい「要因」と「結果」の間に入り込み、両方に影響を与える“別の要因”のことです。たとえば、「アイスの売上」と「熱中症の患者数」が増えるのは、実は「気温の上昇」という交絡因子の影響かもしれません。 ↩︎
-
共変量とは、結果に影響を与える可能性がある、調整すべき「他の変数」のことです。たとえば、「年齢」や「性別」など、分析の精度を上げるために一緒に考慮する情報です。 ↩︎
Discussion