【キャリア設計】得意分野の見つけ方:駆け出しデータサイエンティスト向け
はじめに
こんにちは、SE出身のデータサイエンティストの「マチ」です。せっかくデータサイエンティストに職種変更したからには、肩書きだけでなく、中身の伴った本物のデータサイエンティストになりたいと考えています。
データサイエンスの世界は広く、求められる知識や技術も多岐にわたります。すべてを完璧に網羅するのは現実的ではありません。だからこそ、自分の得意分野を定めることが、キャリアの土台として重要になると考えます。今回は、得意分野を見つけるための3つの視点をご紹介します。
- どんなお客様を得意とするか
- どんなデータを得意とするか
- どんな分析方法を得意とするか
なお、本記事は書籍「データ×AI人材キャリア大全 職種・業務別に見る必要なスキルとキャリア設計」を参照しつつ、自身の経験と独自の考察に基づいて再構成したものです。ご指摘などありましたらコメントいただけますと幸いです。適宜更新する予定です。
どんなお客様を得意とするか
業界で考える
データサイエンスは、さまざまな業界で活用されています。どの業界に興味があるのかを考えることで、自分に合ったキャリアの方向性が見えてきます。以下はデータサイエンスが活用されている主な業界とその特徴です。
- 医療・ヘルスケア
画像診断やAI問診など、活用が進んでいます。市場のポテンシャルは大きい一方、個人情報保護や法制度が未整備な部分があり、ビジネス化の壁になることもあります。 - 製造
異常検知、需要予測、工程最適化など多様な用途があります。特に自動運転やロボティクス、ファクトリーオートメーションなどは急成長中です。ただし、デジタル化にかかるコストが高く、導入するハードルが課題となることもあります。 - 小売
需要予測や商圏分析、在庫最適化など、比較的成果が出やすく、他店舗への展開がしやすいため、データ活用が進んでいます。投資対効果が見えやすいことも特徴です。
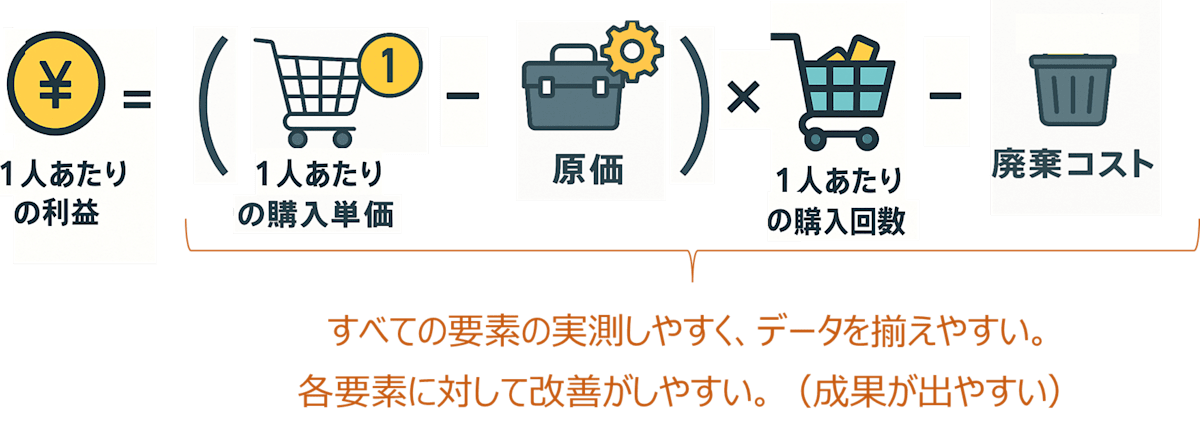
プロジェクトタイプ・関わるフェーズで考える
データサイエンスを活用する目的は、大きく2つに分けられます。
- 機械学習で作業を自動化する
- データから経営や業務に活かせる知見を得る
これらの目的に応じて、実施するプロジェクトのタイプが異なりますが、各タイプのプロジェクトは段階的に関連し合う構造を持っています。
-
データ分析プロジェクト
まずは、自社にとって重要な数値や指標が何であるかを把握するために、仮説検証や効果検証を行う「データ分析プロジェクト」を実施します。目的は、売上向上やコスト削減など、業務改善に直結する知見の獲得です。ビジネスを効率化するための代表的なアプローチとして、「改善点の分析→仮説立案と原因分析→効果検証」の分析プロセスが挙げられます。
成果物:分析レポートなど。

-
データ可視化・BI構築プロジェクト
次に、得られた数値や指標を継続的にモニタリングできる環境を整えるために、BIツールを用いてダッシュボードを構築します。これは、データに基づく意思決定を日々の業務に組み込むための基盤づくりです。
成果物:BIツールによる可視化ダッシュボードなど。
-
機械学習システム構築プロジェクト
さらに、意思決定プロセスを自動化・最適化する段階に進むと、機械学習を用いたシステム構築が必要になります。例えば、予測モデルをシステムに組み込み、API経由で定常的に出力を利用する仕組みなどがこれに該当します。
成果物:予測用API、モデル内蔵システム、バッチ処理システムなど。
このように、「分析 → 可視化 → 自動化」という一連の流れを意識することで、データ活用プロジェクトの全体像がより明確になります。自分がどのフェーズに関わるのが得意かを考えるのも、キャリア戦略の一助となります。
どんなデータを得意とするか
扱うデータによって、必要な知識や技術は大きく異なります。自分がどのタイプのデータと相性が良いかを考えるのも、得意分野を絞るヒントになります。
| データ | 分析概要 | 主な分析手法 |
|---|---|---|
| 構造化データ | 数値やカテゴリなど、表形式のデータを統計的・機械学習的手法で分析します。売上予測、顧客分類、異常検知などを行います。 | 決定木、回帰、PCA、K-means |
| 自然言語 (テキスト) |
人間の言語をコンピュータで理解・生成します。テキストの分類、要約、感情分析などを行います。 | BERT、Word2Vec 、Mecab、spaCy |
| 音声 | 音声データの解析と生成を行います。音声認識(音声→テキスト)や音声合成(テキスト→音声)などを行います。 | Wav2Vec、Deep Speech |
| 画像 | デジタル画像を解析・加工します。画像の特徴抽出(分類)や物体認識、フィルタリングなどを行います。 | CNN、Vision Transformer |
| 時系列データ | 時間に沿ったデータを解析します。トレンドや季節性を見つけ、未来の予測を行います。 | ARIMA、LSTM、Prophet |
| グラフデータ |
ノードとエッジからなるグラフデータを解析します。 |
GCN、GraphSAGE (ニューラルネット系) |
どんな分析手法を得意とするか
分析手法は、プロジェクトの内容やデータの種類によって使い分ける必要があります。以下に、3つの分類軸で分析手法を整理しました。自分が得意としたい(または伸ばしたい)手法を明確にしておくと、スキルアップの方向性が定まります。
学習形態による分類
| カテゴリ | 概要 | 代表例 |
|---|---|---|
| 教師あり学習 | 正解ラベル付きで予測モデルを学習 | 線形回帰、決定木、 SVM、深層学習 |
| 教師なし学習 | データ構造の発見・パターン認識 | クラスタリング(K-means)、次元削減(PCA、Autoencoder) |
| 強化学習 |
試行錯誤から報酬最大化を学ぶ |
Q学習、DQN、Policy Gradient |
モデル構造・アルゴリズムによる分類
| カテゴリ | 概要 | 代表例 |
|---|---|---|
| 線形モデル系 | 入力と出力を線形関係で表現 | 線形回帰、ロジスティック回帰、Ridge |
| 決定木系 | ルールベースでの分岐学習 | 決定木、ランダムフォレスト、XGBoost |
| SVM系 | マージン最大化の境界学習 | SVM、SVR |
| ベイズ系 | 確率モデルに基づいた推論 | Naive Bayes |
| ニューラルネット系 | 多層・非線形表現の学習 | MLP、CNN、RNN、Transformer |
| その他の 非パラメトリック系 |
シンプルな距離ベースなど |
k-NN、LDA |
分析の目的による分類
| カテゴリ | 概要 | 代表例 |
|---|---|---|
| 予測が目的 | 将来や未知の値・状態を推測する。 入力データから関数や構造を学習し、 ラベルや数値を予測する。 |
教師あり学習、教師なし学習、 時系列予測、統計的推定 |
| 意思決定が目的 | 選択肢の中から最も良い行動を導く。 制約条件や目的関数を基に、 最善の意思決定・計画を導出する。 |
数理最適化、線形計画法、A/Bテスト、 強化学習、シミュレーション |
参考:押さえておきたい基礎知識
分析のプロセス(CRISP-DM)
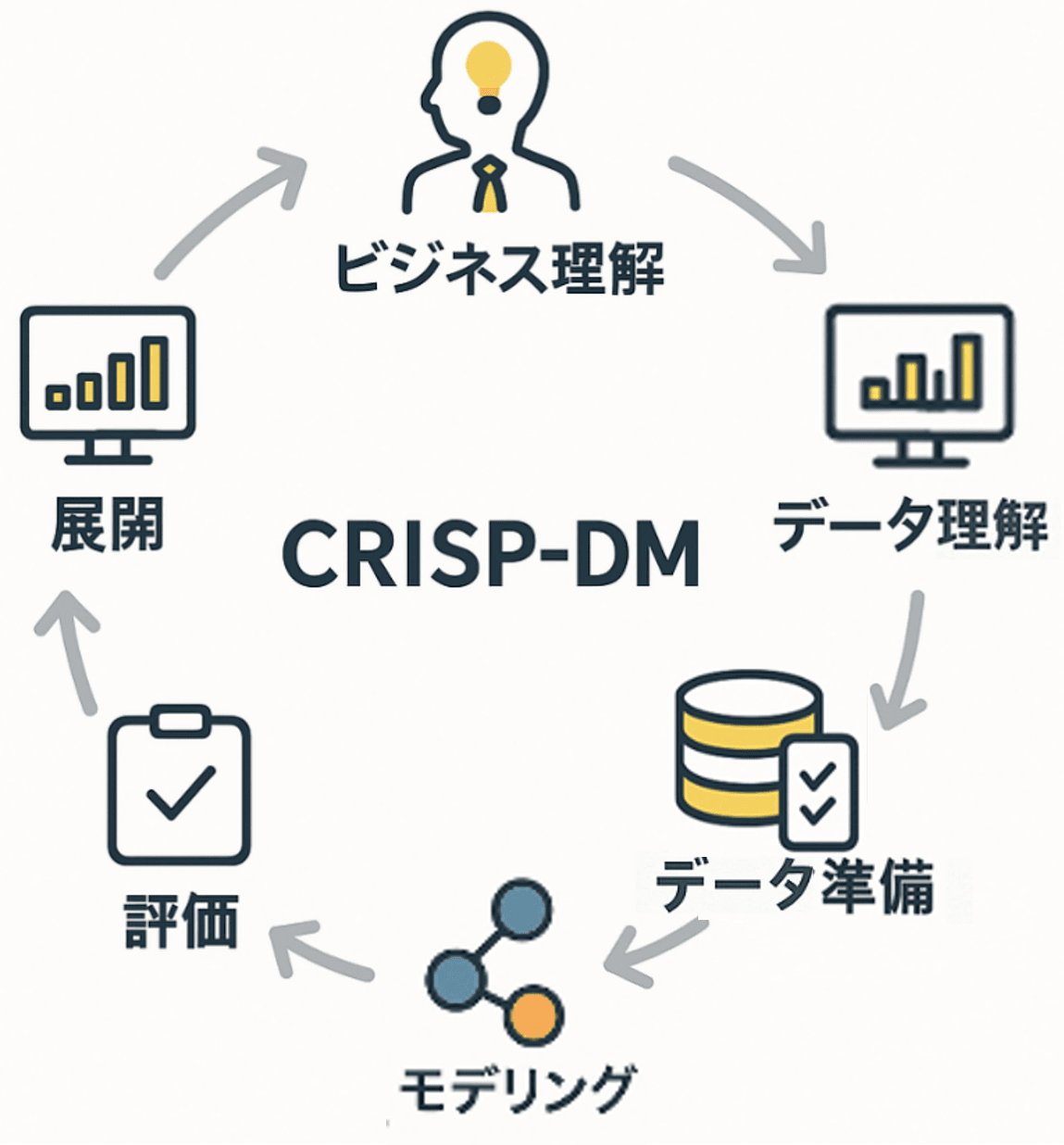
-
ビジネス理解
解決すべき課題や目的を明確化し、プロジェクトのゴールを定めます。 -
データ理解
利用可能なデータの収集・調査(探索的分析(EDA))を行い、
特徴や品質、課題を把握します。 -
データ準備
分析に必要なデータを整形・加工し、モデリング用のデータセットを構築します。 -
モデリング
適切な分析手法(機械学習など)を適用し、モデルを構築します。 -
評価
構築したモデルの性能や有用性を評価し、ビジネス目的との整合性を確認します。 -
展開・導入
モデルの結果をレポート・システムなどで活用し、現場に実装・展開します。
実務で扱う主要なデータ
-
ログデータ
Webやアプリの利用履歴・クリック数・滞在時間など、ユーザー行動分析のベースとなる場合が多いです。収集方法や粒度の設計が重要です。 -
システムデータ(DBデータなど)
IoT機器などから取得されるリアルタイムデータは、時系列分析の基礎や異常検知への応用などに使用されます。 -
アンケート
ユーザーの主観や意識を捉えるために使用されます。設問設計やバイアスの排除、母数の確保が重要です。 -
オープンデータ
政府や自治体、企業が提供する公開データは、信頼性と更新頻度の確認が大切です。 -
個人情報・GDPR
個人を特定できる情報は厳重に扱いましょう。GDPR(EU)や日本の個人情報保護法などの遵守が必須です。マスキング・匿名化処理も押さえましょう。
データ活用の基盤技術
-
データレイク
構造化・非構造化を問わず大量データをそのまま保存します。柔軟性は高いですが、整理が大変です。分析前に加工することを前提としています。 -
DWH(データウェアハウス)
構造化データに特化した、高速かつ整ったデータ分析基盤です。中長期の集計やKPI分析に強いです。 -
データマート
特定部門や目的向けに切り出したデータ集です。小回りが利き、現場向けのダッシュボードに最適です。 -
データパイプライン
データの取得〜変換〜蓄積の一連の流れを実施するツールです。自動化の設計が重要(ETL / ELTの理解が必要)です。 -
クラウドサービス
具体例として、AWS/GCP/Azureなどが挙げられます。コスト・スケーラビリティ・セキュリティなどの観点から選定します。 -
データ収集・蓄積ツール
用途に応じて、リアルタイムでの処理かバッチ処理か選択します。 -
API
外部サービスからデータを取得する手段です。利用規約・リクエスト制限(通信制限)・認証方式に注意が必要です。 -
スクレイピング
Webサイトからデータを自動取得する技術です。法的制約やサイト構造の変化への対応が必要です。 -
Python / R / SQL
データ取得・加工・分析に必須の言語です。SQLはDWH操作の基礎、Pythonは機械学習にも対応しています。
分析・AI活用を支えるツール
-
BIツール
比較的容易に可視化環境を整えることができ、意思決定を支援します。KPI設計と使いやすさが鍵となります。具体例として、Tableau・Power BIなどが挙げられます。 -
AutoMLツール
モデル構築を自動化します。知識の浅い人でも使えますが、ブラックボックス化に注意しましょう。具体例として、Google AutoML, H2O.aiなどなどが挙げられます。 -
分析特化型サービス
業務フローに特化した分析支援ができます。ノーコード・ローコード開発との相性が良いです。具体例として、Alteryx・DataRobotなどが挙げられます。
その他用語
-
グロースハック
データ分析に基づいて、仮説立案・検証・改善を繰り返すことを指します。
限られた時間や予算内で、事業やサービスの成長を最大化することを目的とします。
さいごに
本記事では、「お客様」「扱うデータ」「分析手法」の3つの軸で、自分の得意分野に関する考え方を整理しました。キャリアの初期段階から自分の関心と相性を見極めながら、小さく試して得意を育てていくことが大切だと思います。
Discussion