0. はじめに
お疲れ様です。STARAI社員の中岸です!
前回、OCR(光学文字認識(こうがくもじにんしき、英: Optical character recognition):活字、手書きテキストの画像を文字コードの列に変換する技術)に関する記事を書きましたが、今回はもう少し深堀りして精度向上に向けてなにかできることはないかと色々と苦戦しながら調べてみた結果についてまとめてみました。
今回は、PaddleOCRのOCRモデルについて色々と試してみました。以降では、それぞれ試してみたことをセクションにして、サンプル画像(今回の処理対象は前回と似たような日本語ベースのダミー請求書、手書きは今回はなし)についてどの程度精度が変化したかなどをまとめていきます(1トライ1セクション:なにを試したのかの概要、サンプルコード、所感くらいの構成)。ノウハウカタログみたいな感じで後々使えたらいいなぁくらいの感じを目指して書いておりますので、その点ご理解ください(あくまでも今回用いた画像について色々と試行錯誤した結果になりますのであらゆる状況で当てはまるというようなものではない点にご注意ください。データセットや入力対象が変わると検討することはまた変わってくると思います。。あと商用のOCRモデル使えばいいやんというツッコミはなしで(笑)、この手のやつしか使えない環境もあるのです…)。
0.1 今回検証に使った画像
今回は以下の画像1枚を使用。
- 印字された文字がベースの日本語ダミー請求書画像(ocr_test_sample_invoice_v1.png、フリー素材に適当に文字を入れ込んで作成。前回より少し表の内容を増やしてみた)。
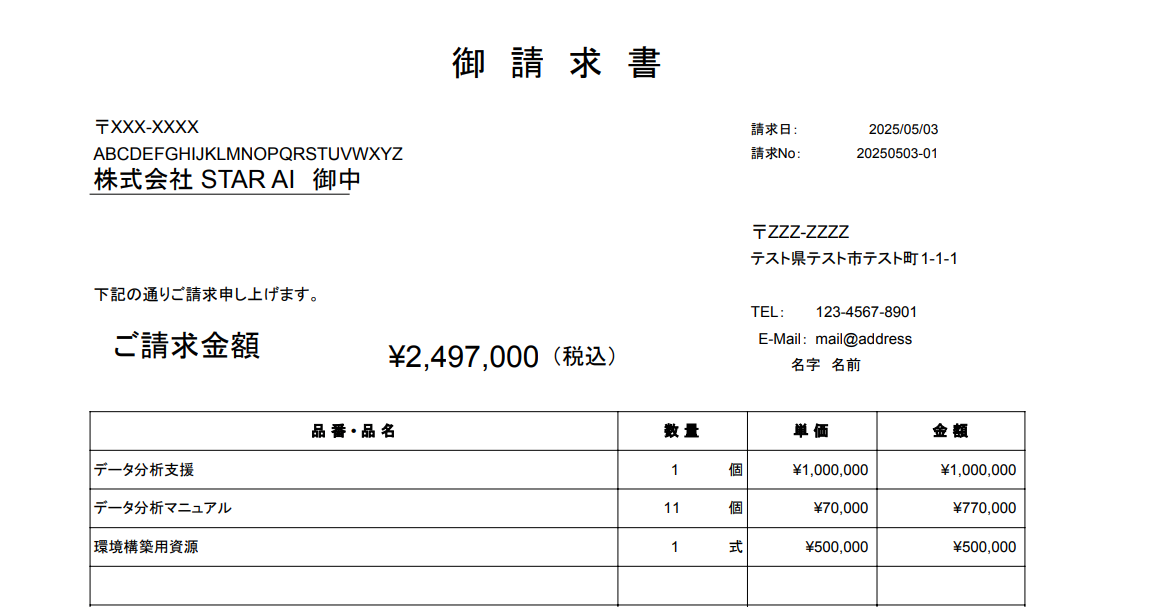 |
|---|
1. ベースライン(前回のコード)
1.1 概要
前回のコードをそのまま使ったものです(ベースラインとして以降のものと比較していきます)。
1.2 コード
# gpu(cuda11.8)
# pip install paddlepaddle-gpu==2.6.2 -i https://www.paddlepaddle.org.cn/packages/stable/cu118/
# pip install paddleocr opencv-python pillow
# cpu only
# pip install paddlepaddle paddleocr opencv-python pillow
from paddleocr import PaddleOCR, draw_ocr
import cv2
from PIL import ImageFont, ImageDraw, Image
import numpy as np
# PaddleOCRを日本語モードで初期化する(lang="japan"で日本語)
# ドキュメント -> https://paddlepaddle.github.io/PaddleOCR/latest/en/
ocr = PaddleOCR(lang='japan')
# 今回用資した画像を読み込む
img_path = 'ocr_test_sample_invoice_v1.png'
img = cv2.imread(img_path)
rgb_img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# OCRを実行
result = ocr.ocr(img_path)
# 日本語フォントのパスを指定
# Windowsは下記、他OSは適宜設定
font_path = 'C:/Windows/Fonts/msgothic.ttc'
font = ImageFont.truetype(font_path, 20) # 日本語フォントを指定
# 画像に(バウンディングボックスと)テキストを描画(見やすさのため白画像に文字を置いていく感じで実装)
#img_pil = Image.fromarray(rgb_img) # 上書きしたい場合
img_pil = Image.fromarray(np.full_like(rgb_img, 255)) # rgb_img
draw = ImageDraw.Draw(img_pil)
for line in result:
for word_info in line:
bbox = word_info[0] # バウンディングボックスの座標
text = word_info[1][0] # 抽出されたテキスト
confidence = word_info[1][1] # 信頼度
# バウンディングボックスの座標を取得(左上、右下座標)
top_left = tuple(map(int, bbox[0]))
bottom_right = tuple(map(int, bbox[2]))
# バウンディングボックス + テキストの描画(日本語OK)
#draw.rectangle([top_left, bottom_right], outline="green", width=2) #BBOXで囲みたい場合
draw.text(top_left, text, font=font, fill="red")
# 結果画像を保存(Pillow -> cv2)
rgb_img = np.array(img_pil)
result_img = cv2.cvtColor(rgb_img, cv2.COLOR_RGB2BGR) #RGB2BGR
cv2.imwrite(img_path.split(".")[0] + "_paddle_default_result.png", result_img)
1.3 実行結果(元画像は以降は省略)
 |
|---|
まぁまぁ間違えている。金額まわり(「¥」含む)、郵便番号まわり(「〒」含む)、テーブル内の要素の間違いが特に目立っており、このまま実運用へという流れにはさすがにならない結果となった。
1.4 所感(+調べて分かったこととか)
前回の結果を踏まえるとまぁこんなもんという感じでした。以降は、これをベースに、前処理、モデル、OCRの引数調整なんかを色々と試して精度がどうなったかをまとめていきます。
ちなみに「¥」や「〒」記号全然認識できないなぁと思ってたんですが、色々と調べてる中で、日本語モデルを指定したときに読み込まれる(辞書ファイル)を覗いてみると、実はこれらの記号はそもそもモデルで識別できるようになってなかったという事実が判明(ターゲットとして登録されていなかった…、そりゃ無理だ)。これをやろうとするとちゃんと登録して再度学習とか考えないといけないので、以降の試行錯誤でもここはいったん無視します…(それも考えて辞書に登録して再学習・チューニングとかも検討したけどまぁ手元の環境では現実的ではありませんでした…(1敗))。
# ちなみに辞書は、コードで直接指定する場合は以下の用に指定できる
# (paddleocrのgitをクローンしてきて、リポジトリ直下でコードを書いた場合)
ocr = PaddleOCR(lang='japan',
rec_char_dict_path = 'ppocr/utils/dict/japan_dict.txt')
1.5 補足(インストールされるデフォルトモデル)
ベースラインのコードだと下記のモデルが、所定の場所に自動でダウンロードされます(それぞれ本家のページで紹介されているみたいです)。日本語の認識モデルはv4ってのが使われているようです。またダウンロードされるものは、それぞれ、clsは文字の向きを判別するモデル(今回はあまりここは対象ではない)、detは検出モデル、recは文字認識モデルを指している。以降では、ここを変えてトライしてみたりもしているので、このようなモデルがこのような形式で使われているよというのを前もって示しておきます。
# Linuxだと '~/.paddleocr' 以下に保存(だったと思う)
# Windowsだと以下に保存されるようです。コード内で直接指定も可能。
C:\USERS\USERNAME\.PADDLEOCR
└─whl
├─cls
│ └─ch_ppocr_mobile_v2.0_cls_infer
├─det
│ └─ml
│ └─Multilingual_PP-OCRv3_det_infer
└─rec
└─japan
└─japan_PP-OCRv4_rec_infer
2. 前処理の検討(リサイズ、コントラスト補正)
2.1 概要
ここでは、一般的によく適用されるOCRの前処理をトライしてみて、最初のコードの結果がどのように変わるのかを調べてみました(超解像、ノイズ除去、シャープ化、向き補正、罫線除去など他にも色々とあるが、いったん前もって試してみた結果タイトルのものだけでやってみました)。
2.2 コード
# gpu(cuda11.8)
# pip install paddlepaddle-gpu==2.6.2 -i https://www.paddlepaddle.org.cn/packages/stable/cu118/
# pip install paddleocr opencv-python pillow
# cpu only
# pip install paddlepaddle paddleocr opencv-python pillow
from paddleocr import PaddleOCR, draw_ocr
import cv2
from PIL import ImageFont, ImageDraw, Image, ImageEnhance
import numpy as np
# 画像を読み込む(今回用意した画像を読み込む)
img_path = 'ocr_test_sample_invoice_v1.png' # サイズ 1174x607
im = Image.open(img_path).convert('L') # グレースケールで読み込む
# 前処理部分!!(リサイズ、コントラスト)
multiplier = 2 # 画像サイズを何倍にするか指定
im = im.resize((im.width * multiplier, im.height * multiplier)) # 画像サイズをmultiplier倍にする
enhancer= ImageEnhance.Contrast(im) # ImageEnhance定義
im_con = enhancer.enhance(2.0) # コントラストを上げる
np_img = np.asarray(im_con) # OCRに投げるようにnp化
# PaddleOCRを日本語モードで初期化する(lang="japan"で日本語)
# ドキュメント -> https://paddlepaddle.github.io/PaddleOCR/latest/en/
# 元のケースだと横幅が960に圧縮されてしまうが、こうするとある程度サイズを保て文字がつぶれてしまうというケースを防げる
# 入力のサイズをそのまま入れても良かったが、メモリ消費量や精度のトレードオフを考慮して以下で設定
ocr = PaddleOCR(lang='japan',
det_limit_side_len=1280 # 入力画像の最大辺サイズ(大きいと解像度が上がって精度が上がるがメモリを多く消費してしまう))
) # det_limit_side_len=960,デフォルトだと960が設定、これより大きいとこのサイズになっていまう
# OCRを実行(npの画像を指定)
result = ocr.ocr(img = np_img)
# 日本語フォントのパスを指定
# Windowsは下記、他OSは適宜設定
font_path = 'C:/Windows/Fonts/msgothic.ttc'
font = ImageFont.truetype(font_path, 40) # 日本語フォントを指定
# 画像に(バウンディングボックスと)テキストを描画(見やすさのため白画像に文字を置いていく感じで実装)
rgb_img = im_con.convert("RGB")
#img_pil = Image.fromarray(rgb_img) # 上書きしたい場合
img_pil = Image.fromarray(np.full_like(rgb_img, 255)) # rgb_img
draw = ImageDraw.Draw(img_pil)
for line in result:
for word_info in line:
bbox = word_info[0] # バウンディングボックスの座標
text = word_info[1][0] # 抽出されたテキスト
confidence = word_info[1][1] # 信頼度
# バウンディングボックスの座標を取得(左上、右下座標)
top_left = tuple(map(int, bbox[0]))
bottom_right = tuple(map(int, bbox[2]))
# バウンディングボックス + テキストの描画(日本語OK)
#draw.rectangle([top_left, bottom_right], outline="green", width=2)
draw.text(top_left, text, font=font, fill="red")
# 結果画像を保存(Pillow -> cv2)
rgb_img = np.array(img_pil)
result_img = cv2.cvtColor(rgb_img, cv2.COLOR_RGB2BGR) #RGB2BGR
cv2.imwrite(img_path.split(".")[0] + "_paddle_trial1_result.png", result_img)
print("saved: ", img_path.split(".")[0] + "_paddle_trial1_result.png")
2.3 実行結果
 |
|---|
表内の「データ分析・・・」という部分がちゃんと取れており、数字も「¥」の部分を除けばちゃんと取れている(「〒」記号含めてここは仕方ない部分もあるが、数値部分だけでもなんとか取りたい場合、この誤認識は少しやっかいではある)ことが確認でき、最初の状態よりは良くなったように見える。一方で、テーブルのヘッダー部分と数量カラムの部分がまだまだ未検出のままである。
2.4 改変した場所
最初のコードから変えた部分は主に下記、Pillowベースでリサイズとコントラスト補正を行っている部分と、OCRの引数として入力画像の最大辺サイズを指定している部分となる。想定される効果としては下記のような感じ。
- 画像サイズが圧縮され、文字がつぶれてしまい未検出や誤認識となってしまう可能性を低減(ヘッダー部分は最初からつぶれてるのでここは難しそうではある)。
- 文字が境界がはっきりして際立って検出・認識がしやすくなる。
# 前処理部分!!(リサイズ、コントラスト)
multiplier = 2 # 画像サイズを何倍にするか指定
im = im.resize((im.width * multiplier, im.height * multiplier)) # 画像サイズをmultiplier倍にする
enhancer= ImageEnhance.Contrast(im) # ImageEnhance定義
im_con = enhancer.enhance(1.5) # コントラストを上げる(1.0, 1.5~2.5?)
np_img = np.asarray(im_con) # OCRに投げるようにnp化
# PaddleOCRを日本語モードで初期化する(lang="japan"で日本語)
# ドキュメント -> https://paddlepaddle.github.io/PaddleOCR/latest/en/
# 元のケースだと横幅が960に圧縮されてしまうが、こうするとある程度サイズを保て文字がつぶれてしまうというケースを防げる
# 入力のサイズをそのまま入れても良かったが、メモリ消費量や精度のトレードオフを考慮して以下で設定
ocr = PaddleOCR(lang='japan',
det_limit_side_len=1280 # 入力画像の最大辺サイズ(大きいと解像度が上がって精度が上がるがメモリを多く消費してしまう))
) # det_limit_side_len=960,デフォルトだと960が設定、これより大きいとこのサイズになっていまう
2.5 所感
手間のわりに効果はそれなりにあったように思う。どちらかというと認識精度のほうで影響が大きかったように感じる。一方で、検出の部分はまだまだ課題は残るというような感じだった。数量カラム部分の1文字だけの検出部分はなかなか手ごわそう。
3. 検出モデルを変更して検証
3.1 概要
ここまでの検証から、検出部分における課題も多いように感じるので、これまでデフォルト設定で自動ダウンロードされるモデルを少し変えてトライしてみることを検討する。端的に言えば、自動でダウンロードされて使われるモデルよりも良いモデルを手動でダウンロードしてきて、それを使用するということになる。スクリプトの基本的な流れとして、スクリプトが実行された際に、OCRの引数にローカルのモデルパスが指定されていない or 指定はされているが存在していない、などの場合に自動でモデルがダウンロードされて使われてしまう(モデルのURLは、OCRの引数(言語)などをベースにスクリプト内で生成される)。このことから、使いたいモデルをスクリプトで使えるようにするためには、予めモデルを取得しておき、そのパスを引数に設定しておく必要がある。

今回は、本家のページのモデルカタログから検出精度がよさそうなモデルを見つけてきてそれをダウンロード、スクリプト内で手動で設定してこれを用いるようにすることで、なんとか検出精度を上げられないかということで試してみる。ページ内を見てみると、上記のようにモデルサイズが他のものとは桁違いのものがあったので、これをダウンロードして使うことにしてみた。今回はプロジェクトルート内に下記の用に格納して使うこととした。
# ダウンロードしてきたファイルを展開して下記の形式で保存
# 各階層に実体だけを置くような形で保存している
C:\USERS\USERNAME\PROJECT_ROOT\paddleocr
├─ch_PP-OCRv4_det_server_infer (今回使ういいモデル(容量大))
│ ├─inference.pdiparams
│ ├─inference.pdiparams.info
│ └─inference.pdmodel
├─cls
│ ├─inference.pdiparams
│ ├─inference.pdiparams.info
│ └─inference.pdmodel
├─det (これはデフォルトでダウンロードしてきたdetモデル、違いが分かるように格納)
│ ├─inference.pdiparams
│ ├─inference.pdiparams.info
│ └─inference.pdmodel
└─rec
├─inference.pdiparams
├─inference.pdiparams.info
└─inference.pdmodel
3.2 コード
前処理部分はセクション2のものを引き継いだ(コントラスト補正のパラメータが少し違うけど)。
# gpu(cuda11.8)
# pip install paddlepaddle-gpu==2.6.2 -i https://www.paddlepaddle.org.cn/packages/stable/cu118/
# pip install paddleocr opencv-python pillow
# cpu only
# pip install paddlepaddle paddleocr opencv-python pillow
from paddleocr import PaddleOCR, draw_ocr
import cv2
from PIL import ImageFont, ImageDraw, Image, ImageEnhance
import numpy as np
# 画像を読み込む(今回用意した画像を読み込む)
img_path = 'ocr_test_sample_invoice_v1.png' # サイズ 1174x607
im = Image.open(img_path).convert('L') # グレースケールで読み込む
multiplier = 2 # 画像サイズを何倍にするか指定
im = im.resize((im.width * multiplier, im.height * multiplier)) # 画像サイズをmultiplier倍にする
enhancer= ImageEnhance.Contrast(im) # ImageEnhance定義
im_con = enhancer.enhance(2.0) # コントラストを上げる(1.0, 1.5~2.5くらい?)、セクションとは少し違う
np_img = np.asarray(im_con) # OCRに投げるようにnp化
# PaddleOCRを日本語モードで初期化する(lang="japan"で日本語)
# ドキュメント -> https://paddlepaddle.github.io/PaddleOCR/latest/en/
# 新しいモデルを取得してきてそれで検出を行う
ocr = PaddleOCR(det_model_dir="paddleocr/ch_PP-OCRv4_det_server_infer", # 検出モデルのパス。テキスト領域(bbox)を検出するモデル
rec_model_dir="paddleocr/rec", # 認識モデルのパス
cls_model_dir="paddleocr/cls", # 文字の向きを判別するモデルのパス(今はどちらでもいい)
lang="japan", # 使用する言語設定
use_gpu=True, # GPUを使うかどうか
det_limit_side_len=1280, # 入力画像の最大辺サイズ(大きいと解像度が上がって精度が上がるがメモリを多く消費してしまう)
)
# OCRを実行(npの画像を指定)
result = ocr.ocr(img = np_img)
# 日本語フォントのパスを指定
# Windowsは下記、他OSは適宜設定
font_path = 'C:/Windows/Fonts/msgothic.ttc'
font = ImageFont.truetype(font_path, 40) # 日本語フォントを指定
# 画像に(バウンディングボックスと)テキストを描画(見やすさのため白画像に文字を置いていく感じで実装)
rgb_img = im_con.convert("RGB")
#img_pil = Image.fromarray(rgb_img) # 上書きしたい場合
img_pil = Image.fromarray(np.full_like(rgb_img, 255)) # rgb_img
draw = ImageDraw.Draw(img_pil)
for line in result:
for word_info in line:
bbox = word_info[0] # バウンディングボックスの座標
text = word_info[1][0] # 抽出されたテキスト
confidence = word_info[1][1] # 信頼度
# バウンディングボックスの座標を取得(左上、右下座標)
top_left = tuple(map(int, bbox[0]))
bottom_right = tuple(map(int, bbox[2]))
# バウンディングボックス + テキストの描画(日本語OK)
#draw.rectangle([top_left, bottom_right], outline="green", width=2)
draw.text(top_left, text, font=font, fill="red")
# 結果画像を保存(Pillow -> cv2)
rgb_img = np.array(img_pil)
result_img = cv2.cvtColor(rgb_img, cv2.COLOR_RGB2BGR) #RGB2BGR
cv2.imwrite(img_path.split(".")[0] + "_paddle_trial2_result.png", result_img)
print("saved: ", img_path.split(".")[0] + "_paddle_trial2_result.png")
3.3 実行結果
 |
|---|
未検出の部分がかなり改善したことが分かる(未検出部分はテーブル内の「数量」のカラムの2ヶ所と大幅に改善)。誤認識については、テーブルのヘッダー部分含め、これまでの部分とあまり変わってはいなかった。
3.4 改変した場所
モデルの呼び出し部分を下記のように変更。下記のように、モデルパスを直接指定してやることで任意のモデルを使うことができる。現状デフォルトだと、(おそらく)今回ダウンロードした(重い)モデルは使えるようになってないので下記のように明記する必要があると思われる。各引数の説明は下記のコメント部分に記載。
# PaddleOCRを日本語モードで初期化する(lang="japan"で日本語)
# ドキュメント -> https://paddlepaddle.github.io/PaddleOCR/latest/en/
# 新しいモデルを取得してきてそれで検出を行う
ocr = PaddleOCR(det_model_dir="paddleocr/ch_PP-OCRv4_det_server_infer", # 検出モデルのパス。テキスト領域(bbox)を検出するモデル
rec_model_dir="paddleocr/rec", # 認識モデルのパス
cls_model_dir="paddleocr/cls", # 文字の向きを判別するモデルのパス(今はどちらでもいい)
lang="japan", # 使用する言語設定
use_gpu=True, # GPUを使うかどうか
det_limit_side_len=1280, # 入力画像の最大辺サイズ(大きいと解像度が上がって精度が上がるがメモリを多く消費してしまう)
)
3.3 所感
モデルを変えることで、未検出部分が大幅に改善。メモリ使用量などのトレードオフはあるかもだが基本的に使わない理由がないなと思う(nvidia-smiで見てみてもそこまでメモリ食っているようには見えなかったし)。とは言ってもまだ不十分なところもあるので、以下では、OCRの引数とかを調整しながら、少し粘って検討してみたい(正直、テーブルヘッダー部分の誤認識についてはあとでルールベースや事例ベースで修正することができると思うので、あとは残っている未検出部分さえ修正すれば、かなり実用的なラインに上がってくるのではないかと思う)。
4. OCRの引数による調整
4.1 概要
ここまででかなりいい感じになってきたので、もう一段階精度を上げるために、OCRの引数を調べてみてここを調整することでなんとか精度(とくに検出部分)を上げられないかを調査してみる。ここでは、OCRの引数から特に、検出にかかわる部分をピックアップして、それらを変更することで精度がどのように変わるのかを見ていく。
4.2 コード
前処理部分はセクション3のものを引き継いだ。変更部分については、下記で詳細を記載する。
# gpu(cuda11.8)
# pip install paddlepaddle-gpu==2.6.2 -i https://www.paddlepaddle.org.cn/packages/stable/cu118/
# pip install paddleocr opencv-python pillow
# cpu only
# pip install paddlepaddle paddleocr opencv-python pillow
from paddleocr import PaddleOCR, draw_ocr
import cv2
from PIL import ImageFont, ImageDraw, Image, ImageEnhance
import numpy as np
# 画像を読み込む(今回用意した画像を読み込む)
img_path = 'ocr_test_sample_invoice_v1.png' # サイズ 1174x607
im = Image.open(img_path).convert('L') # グレースケールで読み込む
multiplier = 2 # 画像サイズを何倍にするか指定
im = im.resize((im.width * multiplier, im.height * multiplier)) # 画像サイズをmultiplier倍にする
enhancer= ImageEnhance.Contrast(im) # ImageEnhance定義
im_con = enhancer.enhance(2.0) # コントラストを上げる(1.0, 1.5~2.5くらい?)、セクションとは少し違う
np_img = np.asarray(im_con) # OCRに投げるようにnp化
# PaddleOCRを日本語モードで初期化する(lang="japan"で日本語)
# ドキュメント -> https://paddlepaddle.github.io/PaddleOCR/latest/en/
# 新しいモデルを取得してきてそれで検出を行う
# モデル引数を調整して未検出を減らす。
ocr = PaddleOCR(det_model_dir="paddleocr/ch_PP-OCRv4_det_server_infer", # 検出モデルのパス。テキスト領域(bbox)を検出するモデル
rec_model_dir="paddleocr/rec", # 認識モデルのパス
cls_model_dir="paddleocr/cls", # 文字の向きを判別するモデルのパス(今はどちらでもいい)
lang="japan", # 使用する言語設定
use_gpu=True, # GPUを使うかどうか
det_limit_side_len=1280, # 入力画像の最大辺サイズ(大きいと解像度が上がって精度が上がるがメモリを多く消費してしまう)
det_db_thresh=0.1, # テキスト領域かどうかを判定する閾値(デフォルト:0.3)
det_db_box_thresh=0.1, # 候補boxとして有効とみなすための閾値(デフォルト:0.6)
det_db_unclip_ratio=3.0, # 検出領域の膨張率。(デフォルト:1.5)
)
# OCRを実行(npの画像を指定)
result = ocr.ocr(img = np_img)
# 日本語フォントのパスを指定
# Windowsは下記、他OSは適宜設定
font_path = 'C:/Windows/Fonts/msgothic.ttc'
font = ImageFont.truetype(font_path, 40) # 日本語フォントを指定
# 画像に(バウンディングボックスと)テキストを描画(見やすさのため白画像に文字を置いていく感じで実装)
rgb_img = im_con.convert("RGB")
#img_pil = Image.fromarray(rgb_img) # 上書きしたい場合
img_pil = Image.fromarray(np.full_like(rgb_img, 255)) # rgb_img
draw = ImageDraw.Draw(img_pil)
for line in result:
for word_info in line:
bbox = word_info[0] # バウンディングボックスの座標
text = word_info[1][0] # 抽出されたテキスト
confidence = word_info[1][1] # 信頼度
# バウンディングボックスの座標を取得(左上、右下座標)
top_left = tuple(map(int, bbox[0]))
bottom_right = tuple(map(int, bbox[2]))
# バウンディングボックス + テキストの描画(日本語OK)
#draw.rectangle([top_left, bottom_right], outline="green", width=2)
draw.text(top_left, text, font=font, fill="red")
# 結果画像を保存(Pillow -> cv2)
rgb_img = np.array(img_pil)
result_img = cv2.cvtColor(rgb_img, cv2.COLOR_RGB2BGR) #RGB2BGR
cv2.imwrite(img_path.split(".")[0] + "_paddle_trial3_result.png", result_img)
print("saved: ", img_path.split(".")[0] + "_paddle_trial3_result.png")
4.3 実行結果
 |
|---|
一部文字の誤認識(テーブルヘッダー、「〒」記号回り)を除けば、だいたい取りたい情報を抽出することができるようにはなっているように思う。このサンプルに限ってという前提はあるが、「¥」まわりの誤認識がなくなったのは嬉しい(この例では、数値を適切に扱うことができるようになったが、もちろん「¥」をの部分を検出してしまってそれを間違った文字に割り当ててしまうケースもあるので注意は必要)。
4.4 改変した場所
モデルの呼び出し部分を下記のように変更。引数の後ろ3つが今回新たに追加した部分で、特に検出部分のパフォーマンスに関連しているものとなる(間違ってたらゴメン)。
- det_db_thresh(0.3->0.1):テキスト領域かどうかを判定する閾値。detモデルを適用した際にテキスト領域かどうかを示すスコアマップ(確率値のheatmap)ができる。これについて、文字領域かどうかのバイナリマップ(マスク)を作成する際にこの閾値が用いられる。このマップはbboxを作成に使われる。
- det_db_box_thresh(0.6->0.1):上で作成したマスク領域からbbox候補が作成される。各bbox候補にはスコアが割り当てられるが(bbox内の各バイナリマップが持つスコアから計算?)、このスコアが低いものは信頼度が低いbboxとして棄却される。この判断にこの閾値が使われる。
- det_db_unclip_ratio(1.5->3.0):検出領域の膨張率。OCRが見つけたテキスト領域(スコアの高いエリア)に対して抽出される輪郭をどれくらい拡張させて、最終的な矩形(bounding box)を作るかを指定するパラメータ。この処理をしないと、文字が適切に囲まれなかったり、切れたりすることがあり、正しく認識できない可能性が出てくる。
まずは、検出ができないといけないということで、結構閾値を下げてみたのだが、想像以上にうまく機能してくれたように思う(ほかのケースでは要調整ではあると思うが)。
# PaddleOCRを日本語モードで初期化する(lang="japan"で日本語)
# ドキュメント -> https://paddlepaddle.github.io/PaddleOCR/latest/en/
# 新しいモデルを取得してきてそれで検出を行う
# モデル引数を調整して未検出を減らす。
ocr = PaddleOCR(det_model_dir="paddleocr/ch_PP-OCRv4_det_server_infer", # 検出モデルのパス。テキスト領域(bbox)を検出するモデル
rec_model_dir="paddleocr/rec", # 認識モデルのパス
cls_model_dir="paddleocr/cls", # 文字の向きを判別するモデルのパス(今はどちらでもいい)
lang="japan", # 使用する言語設定
use_gpu=True, # GPUを使うかどうか
det_limit_side_len=1280, # 入力画像の最大辺サイズ(大きいと解像度が上がって精度が上がるがメモリを多く消費してしまう)
det_db_thresh=0.1, # テキスト領域かどうかを判定する閾値(デフォルト:0.3)
det_db_box_thresh=0.1, # 候補boxとして有効とみなすための閾値(デフォルト:0.6)
det_db_unclip_ratio=3.0, # 検出領域の膨張率。(デフォルト:1.5)
)
4.3 所感
ここまでできたら、あとは誤字の部分をルールベースでFIXしてやればいい感じの結果になるんじゃないかというところまでは来たように思う。パラメータの設定は色々とガバガバだが…。
運用面で考えると、「¥」や「〒」まわりを書類内で使わないようにすることで誤認識が起こる可能性を低減させるとか、数値については整合性をチェックするよう機能を入れるとか、日本語周り(テーブルのヘッダー部分(これは間違え方を登録しておきルールベースでFIX)、会社名や郵便番号は一部の情報から補正や参照できるような名寄せ辞書を作っておけばある程度誤認識は吸収できるとは思う)の誤りを修正する機能を整備するとかするとある程度使い物になりそうかつある程度省力化につながりそうなものはできそうに思う。色々と問題設定は適切に行っていく必要はありだが…。まぁそこそこ改善したのでヨシ!
5. 最後に
全体通しての感想
前回よりは深く調査できたので、ある程度実践的にはなったんじゃないかというのが率直な感想(もちろん抜けもあるが)。とはいっても、やっぱりある程度ライトなローカルモデルでやるならある程度苦しむ覚悟は必要だということも改めて分かった。間違いを前提にコードをしっかりと整備していくべきだと思う。前も書いたけど、データをどこまで外に出していいかという点で制限がないなら商用モデル使えばいいとは思うが、そうはならんってなった状態でも足掻けるようにはしておきたい。
次回以降に向けて
前回から忙しかったから、読めてなかった記事とか論文(他テーマで、音声系触ってみたのでこのあたりもやってみたいなぁ)とか読んでまたまとめたい…。
おわり
と見せかけて
今回無謀にも、PaddleOCRで 認識モデル(rec) の追加学習というか、ファインチューニング的なことをやったのでその進め方について、ここで供養しておく(とはいってもちゃんと問題設定やデータを準備できればこれはこれで有用だと思うので、まあ知っておけて良かったと思う)。PaddleOCRは手元で学習したり、学習したモデルを推論用に使えるようにしたりするフレームワークが結構充実してて、所定のフォーマットでデータと設定ファイルさえ準備しておけば割と簡単にこの辺ができるようになっているので結構良かった。簡単にではあるが、ざっとまとめる(注意:認識モデルのものしか記載してません)。
学習用設定ファイルの準備
PaddleOCRをgit cloneしてきたときにプロジェクト直下に入ってるconfigフォルダの設定ファイルがそのまま流用できる(-> configs/rec/multi_language/rec_japan_lite_train.yml、ほぼ弄る必要すらない。必要に応じて学習用データの置き場所、事前学習の重みの場所、学習用のパラメータ設定くらいかな?)
Global:
use_gpu: True
epoch_num: 500
log_smooth_window: 20
print_batch_step: 10
# 出力先(エクスポート時に使う)
save_model_dir: ./output/rec_japan_lite
save_epoch_step: 3
# evaluation is run every 5000 iterations after the 4000th iteration
eval_batch_step: [0, 2000]
# if pretrained_model is saved in static mode, load_static_weights must set to True
cal_metric_during_train: True
# モデルの重みを流用するなら以下にそのパスを入れる
pretrained_model:
checkpoints:
save_inference_dir:
use_visualdl: False
infer_img:
# for data or label process
character_dict_path: ppocr/utils/dict/japan_dict.txt
max_text_length: 25
infer_mode: False
use_space_char: False
Optimizer:
name: Adam
beta1: 0.9
beta2: 0.999
lr:
name: Cosine
learning_rate: 0.001
regularizer:
name: 'L2'
factor: 0.00001
Architecture:
model_type: rec
algorithm: CRNN
Transform:
Backbone:
name: MobileNetV3
scale: 0.5
model_name: small
small_stride: [1, 2, 2, 2]
Neck:
name: SequenceEncoder
encoder_type: rnn
hidden_size: 48
Head:
name: CTCHead
fc_decay: 0.00001
Loss:
name: CTCLoss
PostProcess:
name: CTCLabelDecode
Metric:
name: RecMetric
main_indicator: acc
Train:
dataset:
name: SimpleDataSet
# 以下のディレクトリに学習用データとその設定ファイルを置く!
data_dir: ./train_data/
label_file_list: ["./train_data/train_list.txt"]
transforms:
- DecodeImage: # load image
img_mode: BGR
channel_first: False
- RecAug:
- CTCLabelEncode: # Class handling label
- RecResizeImg:
image_shape: [3, 32, 320]
- KeepKeys:
keep_keys: ['image', 'label', 'length'] # dataloader will return list in this order
loader:
shuffle: True
batch_size_per_card: 256
drop_last: True
num_workers: 8
Eval:
dataset:
name: SimpleDataSet
# 以下のディレクトリに検証用データとその設定ファイルを置く!
data_dir: ./train_data/
label_file_list: ["./train_data/eval_list.txt"]
transforms:
- DecodeImage: # load image
img_mode: BGR
channel_first: False
- CTCLabelEncode: # Class handling label
- RecResizeImg:
image_shape: [3, 32, 320]
- KeepKeys:
keep_keys: ['image', 'label', 'length'] # dataloader will return list in this order
loader:
shuffle: False
drop_last: False
batch_size_per_card: 256
num_workers: 8
学習用データセットの準備
上に倣うとすると、プロジェクトルート直下に「train_data」というディレクトリを作ってそこに画像ファイルを置いておくいい。また設定ファイルも同じようにいれておく。基本この通りに入れていくだけでよい。
フォルダ構成(./train_data)
PROJECT_ROOT
└─train_data
├─train_list.txt
├─image1.jpg
├─image2.jpg
:
設定ファイル(./train_data/train_list.txt)
検証用も同じように作る。各行、画像ファイル名とその画像に含まれているテキスト(正解データ)を記載していく。区切り文字はタブ。
image1.jpg 認識対象テキスト1
image2.jpg 認識対象テキスト2
:
学習、学習結果のエクスポート、モデルの使用方法
下記コマンドで学習~推論モデルのエクスポートができる(tools内にスクリプトが用意されている)。
# 学習
python tools/train.py -c configs/rec/multi_language/rec_japan_lite_train.yml
# 推論モデルのエクスポート
python tools/export_model.py \
-c configs/rec/multi_language/rec_japan_lite_train.yml \
-o Global.pretrained_model=./output/rec_japan_lite/best_accuracy \
Global.save_inference_dir=./inference/rec_japan_lite
推論モデルは、「./inference/rec_japan_lite」直下にできる。pythonスクリプト内で使いたい場合は下記のように書けば使うことができる。
ocr = PaddleOCR(
lang="japan",
rec_model_dir="inference/rec_japan_lite", # 自分で学習したrecモデルに差し替え
det_model_dir="paddleocr/det", # 他はそのまま
cls_model_dir="paddleocr/cls", # 〃
)
ここまでで色々と準備して学習した結果、自分は見事にモデル崩壊を起こしました…。まあデータ少なかったからこの枠組みでやると汎化性能落ちるのは当前ではある。でもある程度問題設定が整理されててその枠組みで学習データがある程度網羅的にとれてるならこの設定で十分行けるようにも感じるので、まあこのあたりはまた今後に期待。

Discussion