OCRに関する技術調査(簡易版)
0. はじめに
お疲れ様です。STARAI社員の中岸です!
最近仕事柄OCR(光学文字認識(こうがくもじにんしき、英: Optical character recognition):活字、手書きテキストの画像を文字コードの列に変換する技術)に触れることが多かったので、色々と調査したものまとめてみました。
本記事は、今回触ってみた様々なモデルについてまとめていくわけですが、
それぞれの技術単体を深く調査してまとめたようなものではなく、
シンプルにまとめて(1モデル1セクション:概要、サンプルコード(処理対象は日本語、デフォルトでの使い方のみ、オプションや精度向上のための前処理などには踏み込まない)、所感くらいの構成)、カタログみたいな感じで後々使えたらいいなくらいの感じを目指して書いておりますので、その点ご理解ください(また、今回のサンプルであまりうまくいかなかったといってそれが性能のすべてを示している点ではないことにご注意ください。入力画像を差し替えたら結果が逆になったとかはトライしていても普通にありました)。
0.1 今回検証に使った画像
今回は検証用に2枚の画像を使用(どちらも日本語を処理の対象としています)。モデルによっては、これらの画像以外に公開データセットのデモ用テスト画像も使用しています(こちらは使う際に掲載)。
- 印字された文字がベースのダミー請求書画像(ocr_test_sample_invoice.png、フリー素材に適当に文字を入れ込んで作成)。

- 自分でペイントで適当に書いた手書き文字ベースの画像(ocr_test_sample_handwritten.png)。

1. Tesseract(pytesseract)
1.1 モデル概要
名称: Tesseract OCR
1970年代から開発が始まった歴史あるオープンソースのOCRエンジン
ライセンス: Apache License 2.0(オープンソース)
モデル: LSTMベース(v4.0~)、特徴量ベース(~v3.0、現在も使用可能)
1.2 導入方法とサンプルコード
まず、公式URLから環境にあったTesseractをダウロードし、インストールしておく必要がある。インストール完了後、インストールディレクトリにパスを通す。Windowsであれば、「C:\Program Files\Tesseract-OCR」(おそらくデフォルトだとここ)を環境変数に追加しておく。また、このままではpythonから使うには不便なので、pytesseractを入れておくとよい。
# コマンドラインから実行する場合(パスを通していること前提)
# tesseract 入力画像 出力ファイル オプション(-l:言語指定オプション、jpnで日本語が読み取り可)
# 実行後、実行ディレクトリ直下にoutput_textfile.txtが生成されている
tesseract ocr_test_sample_invoice.png output_textfile -l jpn
# モジュールインストール用コマンド(必要に応じて)
# pip install pytesseract pillow opencv-python
import pytesseract
from PIL import Image, ImageDraw, ImageFont
import cv2
import numpy as np
# Tesseractのパスを設定してない場合下記を実行
# pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
# 画像を読み込む(今回用意した画像を読み込む、使わないほうをコメントアウト)
img_path = "ocr_test_sample_invoice.png"
#img_path = "ocr_test_sample_handwritten.png"
img = cv2.imread(img_path)
rgb_img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
h, w, _ = rgb_img.shape # 描画位置計算用
# TesseractでOCRを実行してバウンディングボックスを取得
# オプションはこちらを参照のこと(https://github.com/tesseract-ocr/tesseract/blob/main/doc/tesseract.1.asc)
boxes = pytesseract.image_to_boxes(Image.fromarray(rgb_img), lang='jpn')
# 日本語フォントのパスを指定
# Windowsは下記、他OSは適宜設定
font_path = 'C:/Windows/Fonts/msgothic.ttc'
font = ImageFont.truetype(font_path, 20)
# 画像に(バウンディングボックスと)テキストを描画(見やすさのため白画像に文字を置いていく感じで実装)
#img_pil = Image.fromarray(rgb_img) # 上書きしたい場合
img_pil = Image.fromarray(np.full_like(rgb_img, 255)) # rgb_img
draw = ImageDraw.Draw(img_pil)
for box in boxes.splitlines():
box = box.split(' ')
text = box[0]
x, y, x2, y2 = int(box[1]), int(box[2]), int(box[3]), int(box[4])
y = h - y # tesseract用調整、y座標は画像の高さから計算
y2 = h - y2
# check
#print(text, x, y, x2, y2)
# (バウンディングボックスと)テキストの描画
#draw.rectangle([(x, y2), (x2, y)], outline="green", width=1)
draw.text((x,y2), text, font=font, fill="red")
# PILイメージをOpenCV形式に変換
rgb_img = np.array(img_pil)
#保存
result_img = cv2.cvtColor(rgb_img, cv2.COLOR_RGB2BGR) #RGB2BGR
cv2.imwrite(img_path.split(".")[0] + "_tesseract_result.png", result_img)
実行結果(元画像は以降は省略)

印字の場合はそれなりに出来ていそうではあるが、(日本語込みというのもあってか(?))精度は十分とは言えず、このまま使える感じではなさそう(本家にも書いてあったが精度向上のための前処理やオプションによる検証などは必須そう)。未検知もそれなりにあり、他にも枠線を「~」とご認識していたり、元の画像の文字位置と検出位置(バウンディングボックス)の位置に結構ぶれがあるのが気になった。
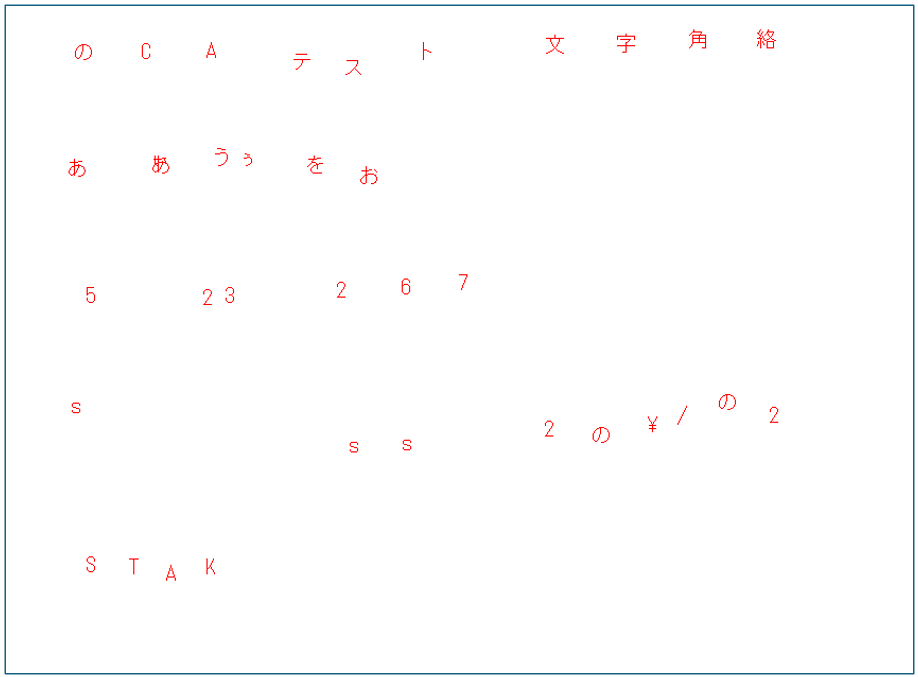
いろんなところでも言われているが手書きについてはあまり精度が出ていないことがわかる。こちらの用途では素直に別モデルを検討するのがよさそう。
1.3 所感
お手軽に使えてかつ(導入方法、ライセンス、このくらいのサイズの画像なら処理もそんなに重くはない)、pythonに閉じたモジュールではないというメリット(?)はあるが、英語ならともかく日本語とお付き合いするなら、一筋縄ではいかなさそうな感じでした(上でも書いたが、前処理やオプションの検証はやったほうがいいと思います、それをやったとて精度がどのくらい出るかは不明瞭)。
2. EasyOCR
2.1 モデル概要
名称: EasyOCR
ライセンス: Apache License 2.0(オープンソース)
モデル: ディープラーニングベース(CNNとRNN)
EasyOCRは、人工知能技術(特にディープラーニング(CNNやRNN))を用いて、様々な言語で高精度な文字認識を実現(各言語に対応する認識モデルと共通の特徴抽出モデルの組み合わせで実現とのこと)しているPythonのモジュール。Tesseractと比較して、より多様なフォントやレイアウトにも対応できたり、手書き文字の認識性能も向上しているとのこと。pythonの枠組みで簡単にインストール・利用可能で、APIも整備されている。
2.2 サンプルコード
# torchをまずインストール。GPUありの場合は適宜、自分の環境にあったバージョンを入れる
# !pip3 install torch torchvision torchaudio
# !pip install easyocr pillow opencv-python
import easyocr
import cv2
import numpy as np
from PIL import ImageFont, ImageDraw, Image
# EasyOCR初期化(日本語(ja)と英語(en)を指定するとよい)
# options -> https://www.jaided.ai/easyocr/documentation/
reader = easyocr.Reader(['ja', 'en'])
# 画像を読み込む(今回用意した画像を読み込む、使わないほうをコメントアウト)
img_path = "ocr_test_sample_invoice.png"
#img_path = "ocr_test_sample_handwritten.png"
img = cv2.imread(img_path)
rgb_img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# OCRの実行
results = reader.readtext(rgb_img)
# 日本語フォントのパスを指定
# Windowsは下記、他OSは適宜設定
font_path = 'C:/Windows/Fonts/msgothic.ttc'
font = ImageFont.truetype(font_path, 20) # 日本語フォントを指定
# 画像に(バウンディングボックスと)テキストを描画(見やすさのため白画像に文字を置いていく感じで実装)
#img_pil = Image.fromarray(rgb_img) # 上書きしたい場合
img_pil = Image.fromarray(np.full_like(rgb_img, 255)) # rgb_img
draw = ImageDraw.Draw(img_pil)
for (bbox, text, prob) in results:
# バウンディングボックスの座標を取得
(top_left, top_right, bottom_right, bottom_left) = bbox
top_left = tuple([int(x) for x in top_left])
bottom_right = tuple([int(x) for x in bottom_right])
# check
#print(text, bbox)
# バウンディングボックス + テキストの描画(日本語OK)
#draw.rectangle([top_left, bottom_right], outline="green", width=2)
draw.text(top_left, text, font=font, fill=(255, 0, 0)) # テキストを描画
# 結果画像を保存(Pillow -> cv2)
rgb_img = np.array(img_pil)
result_img = cv2.cvtColor(rgb_img, cv2.COLOR_RGB2BGR) #RGB2BGR
cv2.imwrite(img_path.split(".")[0] + "_easyocr_result.png", result_img)
実行結果(適用結果のみ)

「¥」、「〒」、日付のところが間違っているくらいで、あとは概ね大丈夫そう。
文字の検出位置も妥当な感じ。印字のOCRの場合であれば、ここから必要な情報をパースして抜くという処理が必要になってもある程度実現可能なレベルと感じた。

こちらは検出自体はできていそうだが、誤認識が目立った(OCRテスト、あいうえお、STARAIといったところは取れていた)。手書き文字はまぁこんなものかという印象(字が汚いという突っ込みはNG)。
2.3 所感
個人的には、結構悪くないと感じている。印字のOCRであれば十分実用に足りる性能であると感じた(手書きも文字のクオリティによると思うが、設定次第では使うこともできると思う)。
また、モデル初期設定の中で複数言語が設定できる点はよいと感じた(日本語と英語両方を扱えるので、今回扱うような文書ではある程度精度が見込める)。とはいえ、やっぱり複数言語が混じった場合はどうしても精度が悪くなる恐れもあるようで、OCR内で扱う言語によっては初期設定を適切にしておかなければならない(なんでもかんでも「英語、日本語」と設定するより、文書内に「英語」しかないのであればモデルを「英語」のみ読み込むようにする、など)。
身も蓋もない話をすると、ある程度制限された環境(ローカルでの実行、マシンスペックなど)でOCRをする必要がある場合は候補になってくるモデルの1つになるうるモデルだと思う。
あと、少し高度というか手が込んだところになると、EasyOCRの結果(バウンディングボックス、抽出テキスト)とLayoutLM(これは今回の調査対象外)などの「文書画像理解用マルチモーダルTransformerモデル」と組み合わせたりすると面白いことができたりするかもしれない(EasyOCR/後述のPaddleOCRで抽出して、ラベル付けして、学習して…、みたいな感じで(試せてみたらいいなぁ))。
3. PaddleOCR
3.1 モデル概要
名称: PaddleOCR
ライセンス: Apache License 2.0(オープンソース)
モデル: ディープラーニングベース(DBNet、CRNNなど(つまるところCNNとRNN)、他にも色々とベースにしているとのこと)
PaddleOCRは、BaiduのPaddlePaddleフレームワーク(ディープラーニングプラットフォーム)に基づいて構築された多言語対応可能なオープンソースのOCRツール(pythonの枠組みで簡単にインストール・利用可能。またpython以外もサポートされているそうな)。ここまでだと、EasyOCRと同じような感じだが、モデルやタスクの選択が幅広い(軽量なモデルから高精度なモデル~レイアウト解析やテーブル認識タスクに対応したモデルも公式で公開されている(OCRソリューション充実しているとも言えるか))という特徴がある。
3.2 サンプルコード
#!pip install paddlepaddle paddleocr opencv-python pillow
from paddleocr import PaddleOCR, draw_ocr
import cv2
from PIL import ImageFont, ImageDraw, Image
import numpy as np
# PaddleOCRを日本語モードで初期化する(lang="japan"で日本語)
# options -> https://paddlepaddle.github.io/PaddleOCR/en/ppstructure/quick_start.html#24-parameter-description
ocr = PaddleOCR(lang='japan')
# 画像を読み込む(今回用意した画像を読み込む、使わないほうをコメントアウト)
img_path = "ocr_test_sample_invoice.png"
#img_path = "ocr_test_sample_handwritten.png"
img = cv2.imread(img_path)
rgb_img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# OCRを実行
result = ocr.ocr(img_path)
# 日本語フォントのパスを指定
# Windowsは下記、他OSは適宜設定
font_path = 'C:/Windows/Fonts/msgothic.ttc'
font = ImageFont.truetype(font_path, 20) # 日本語フォントを指定
# 画像に(バウンディングボックスと)テキストを描画(見やすさのため白画像に文字を置いていく感じで実装)
#img_pil = Image.fromarray(rgb_img) # 上書きしたい場合
img_pil = Image.fromarray(np.full_like(rgb_img, 255)) # rgb_img
draw = ImageDraw.Draw(img_pil)
for line in result:
for word_info in line:
bbox = word_info[0] # バウンディングボックスの座標
text = word_info[1][0] # 抽出されたテキスト
confidence = word_info[1][1] # 信頼度
# バウンディングボックスの座標を取得(左上、右下座標)
top_left = tuple(map(int, bbox[0]))
bottom_right = tuple(map(int, bbox[2]))
# バウンディングボックス + テキストの描画(日本語OK)
#draw.rectangle([top_left, bottom_right], outline="green", width=2)
draw.text(top_left, text, font=font, fill="red")
# 結果画像を保存(Pillow -> cv2)
rgb_img = np.array(img_pil)
result_img = cv2.cvtColor(rgb_img, cv2.COLOR_RGB2BGR) #RGB2BGR
cv2.imwrite(img_path.split(".")[0] + "_paddle_result.png", result_img)
実行結果(適用結果のみ)

「¥」まわり、「〒」、日付のところが間違っているくらいで、あとは概ね大丈夫そう。
文字の検出位置も妥当な感じ。印字のOCRの場合であれば、EasyOCR同様ここから必要な情報をパースして抜くという処理が必要になってもある程度実現可能なレベルと感じた。とはいえ、この文書単体で見た場合、少しEasyOCRよりもご認識が多かったかな。EasyOCと異なり、モデルの初期設定の際、1つしか言語オプションを設定できないので、そのあたりがEasyOCRの結果との差分と考えられるかもしれない(複数言語の文書の精度向上にはこのあたりも考慮に)。モデルもいろいろとあるみたいなので、探してみてもいいかもしれない。

こちらはあまりいい結果は得られなかった。全ての検出対象で未検出自体、誤認識があった(Tesseractよりはマシというレベル)。モデルの初期設定、モデル選定、入力画像の問題などもあるかもしれないが、手書き文字はぱっと見EasyOCRのほうが良さそう。
3.3 所感
印字された文字のOCRに関しては、EasyOCRと同じような感じかなという印象(ほかでもいろいろと試してみたが入力画像によってあっちが良かったりこっちが良かったりみたいな結果もあり、全体としてどっこいどっこい感が否めない、より幅広いモデルやタスクで評価するならまた話は変わってくるかもだが)。こちらについても、ローカルかつ実行環境がある程度制限されているような状況では、これかEasyOCRが選択肢になってくると思われる。あと、手書きは思ったよりも精度が出なかったなという印象(これは検証不足感もあるのでまた追加で色々と試してみたい)。
個人的に1番のデメリットはドキュメントの仕様かなぁ(中国語と英語がサポート)、1番最初に前面に中国語が出てくる&ものによっては英語ドキュメント内に中国語でというケースがあるから情報が受け取りにくいというのがしんどいなと感じるところではあった…。API仕様的にはEasyOCR同様使いやすいんだけどなぁ…。
4. TrOCR
4.1 モデル概要
名称: TrOCR(Transformer-based Optical Character Recognition
with Pre-trained Models)
ライセンス: MIT License(オープンソース)
モデル: Transformerベース (画像Transformer(encoder)とテキストTransformer(decoder))
TrOCR(huggingface, github)は、Microsoftが開発したTransformerベースのOCRモデル。
TrOCRは、画像Transformer(エンコーダー, ViT)とテキストTransformer(デコーダー)を組み合わせた構造で、画像から直接テキストを生成することが可能(画像をエンコードし、その特徴をデコーダーに投げてテキストを生成という流れ)。TrOCRは、印刷された文字だけでなく特に手書き文字の認識にも強みがあるとのこと。また、transformersライブラリで提供されているため、Pythonでお手軽に使える(huggingfaceにおいてドキュメントやコードが充実している)。
4.2 サンプルコード
# !pip3 install torch torchvision torchaudio
# !pip install transformers pillow
from transformers import TrOCRProcessor, VisionEncoderDecoderModel
from PIL import Image
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
processor = TrOCRProcessor.from_pretrained("microsoft/trocr-base-handwritten")
model = VisionEncoderDecoderModel.from_pretrained("microsoft/trocr-base-handwritten")
model.to(device)
print(device)
# 画像を読み込む(今回用意した画像を読み込む、使わないほうをコメントアウト)
# trOCRについては日本語NG&複数行にわたる文書が難しそうだったので、
# 英数字しか入っていない1行文書の画像を新たに用意
img_path = "ocr_test_sample_invoice_for_trOCR.png"
#img_path = "ocr_test_sample_handwritten_for_trOCR.png"
img = Image.open(img_path).convert("RGB")
# 画像準備(->GPU)
pixel_values = processor(img, return_tensors="pt").pixel_values
pixel_values = pixel_values.to(device)
# 推論(推論時は勾配計算不要のため no_grad をセット)
with torch.no_grad():
generated_ids = model.generate(pixel_values)
# 生成されたテキストを抽出(decode)し、結果を表示する
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
print("Extracted: ", generated_text)
実行結果(他とは入力画像が違うので注意)
ぱっと触ってみた感じ、TrOCRについては日本語対応が難しそう(学習してくれているモデルがあるかもだがhuggingfaceでぱっとは見つからなかった…)&複数行にわたる文書の認識が難しそうだったので、これまでとは別の画像を作ってトライしてい見た。

結果(印字への適用結果): #OCR test STAR AIR 2024109120
最初になぞの「#」があるのと日付の「/」以外のところは取れているので、文字の抽出はある程度の精度がありそう。

結果(手書き文字への適用結果): OCR test STAR AI 2024,09120
日付の「/」以外のところは取れているので、印字の場合と同様、文字の抽出はある程度の精度がありそう。
4.3 所感
1行の英語文書のみではあったが、試した感じ悪くなさそうな印象。とはいえ、英語以外の他言語のサポート(日本語…)がまだまだ不十分な点やリソースの観点(transformerアーキテクチャなのでこれまでのものよりはやっぱり重い、CPUでも動くとはいえ)から、今のところ候補にはならないかなという印象。HuggingFaceのtransformersライブラリから簡単に使える点やサンプルコードが充実している点などを考えるとこれからどんどん良くなっていきそうな感じもするので今後に期待。
5 Donut
5.1 モデル概要
名称: Donut(Document Understanding Transformer)
ライセンス: MIT License(オープンソース)
モデル: Transformerベース
Donut(huggingface, github)は、文書の構造と内容を同時に理解するために設計された最先端のOCRモデル。これまでのOCRモデルは画像から単純にテキストを抽出するだけであったが、Donutはそれだけでなく文書理解が必要なさまざまなタスク(請求書、レシートの解析など)に適用することも可能(OCRだけでなくその結果を受けてタスクがこなせる汎用的なモデル)。
5.2 サンプルコード
OCR
# !pip3 install torch torchvision torchaudio
# !pip install transformers pillow datasets
# ほぼ HuggingFaceのコードです!
import re
from transformers import DonutProcessor, VisionEncoderDecoderModel
from datasets import load_dataset
import torch
# model set
processor = DonutProcessor.from_pretrained("naver-clova-ix/donut-base")
model = VisionEncoderDecoderModel.from_pretrained("naver-clova-ix/donut-base")
device = "cuda" if torch.cuda.is_available() else "cpu"
model.to(device)
# load document image
# 用意した画像
img_path = "ocr_test_sample_invoice.png"
#img_path = "ocr_test_sample_handwritten_for_trOCR.png"
image = Image.open(img_path).convert("RGB")
# デモ用
#dataset = load_dataset("hf-internal-testing/example-documents", split="test")
#image = dataset[2]["image"]
# prepare decoder inputs
task_prompt = "<s_synthdog>" #OCRであればこっち(日本語もある程度対応可能とのこと)#task_prompt = "<s_cord-v2>"
decoder_input_ids = processor.tokenizer(task_prompt, add_special_tokens=False, return_tensors="pt").input_ids
pixel_values = processor(image, return_tensors="pt").pixel_values
# generate text
outputs = model.generate(
pixel_values.to(device),
decoder_input_ids=decoder_input_ids.to(device),
max_length=model.decoder.config.max_position_embeddings,
pad_token_id=processor.tokenizer.pad_token_id,
eos_token_id=processor.tokenizer.eos_token_id,
use_cache=True,
bad_words_ids=[[processor.tokenizer.unk_token_id]],
return_dict_in_generate=True,
)
# output
sequence = processor.batch_decode(outputs.sequences)[0]
sequence = sequence.replace(processor.tokenizer.eos_token, "").replace(processor.tokenizer.pad_token, "")
sequence = re.sub(r"<.*?>", "", sequence, count=1).strip() # remove first task start token
print(processor.token2json(sequence))
実行結果
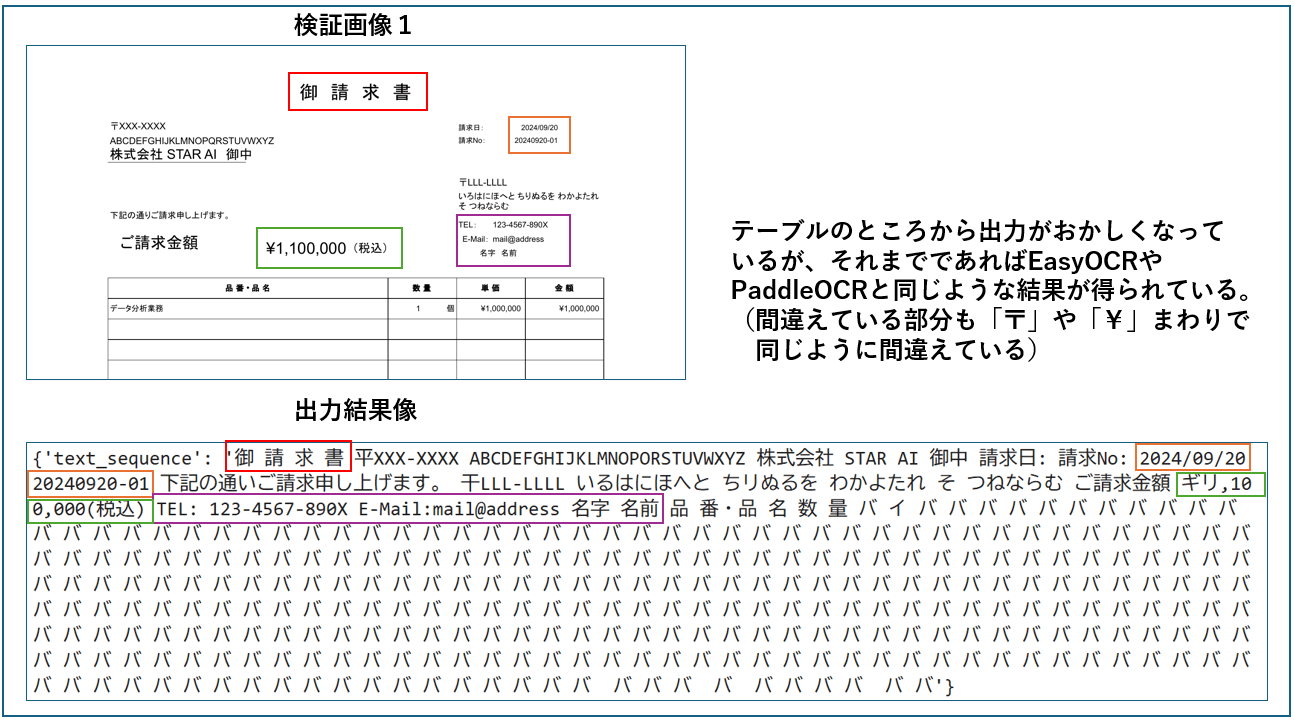
テーブルのところまでは、いい感じでOCRができてそう(そこからおかしな結果が出てしまっているのは少し残念。)。間違えているところもEasyOCRやPaddleOCRと近しいので、日本語込みでもある程度の精度で抽出してくれていることがわかる(テーブルの部分に関しては中途半端に切れていることが悪さをしていそうではあるので入力の問題かもしれない。要検証)。

1行じゃない画像を入力したら全く結果がでなかったので、1行の手書き画像に差し替えて検証。このインプットではそこまでの結果は得られなかった(「OCR」と日付の部分が破綻している…。後述のデモ画像とかは問題なく抽出できているので、入力画像のクオリティの問題ということも十分ありうる➡字が下手すぎてモデルも混乱している??(笑)➡あり得ない話ではないよなぁ)。

デモ用の画像でもトライ。こちらはレシートの項目や金額をうまくOCRできていることがわかる(やっぱり入力のクオリティの問題な気がしてきた…)。この結果であれば後述の発展的な文書理解等のタスクにも使えそうだと感じる。
文書分類
# !pip3 install torch torchvision torchaudio
# !pip install transformers pillow datasets
# ほぼ HuggingFaceのコードです!
import re
from transformers import DonutProcessor, VisionEncoderDecoderModel
from datasets import load_dataset
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
# model set
processor = DonutProcessor.from_pretrained("naver-clova-ix/donut-base-finetuned-rvlcdip")
model = VisionEncoderDecoderModel.from_pretrained("naver-clova-ix/donut-base-finetuned-rvlcdip")
model.to(device)
# load document image
img_path = "ocr_test_sample_invoice.png"
image = Image.open(img_path).convert("RGB")
# load document image (demo image)
#dataset = load_dataset("hf-internal-testing/example-documents", split="test")
#image = dataset[1]["image"]
# prepare decoder inputs
task_prompt = "<s_rvlcdip>"
decoder_input_ids = processor.tokenizer(task_prompt, add_special_tokens=False, return_tensors="pt").input_ids
pixel_values = processor(image, return_tensors="pt").pixel_values
# generate text
outputs = model.generate(
pixel_values.to(device),
decoder_input_ids=decoder_input_ids.to(device),
max_length=model.decoder.config.max_position_embeddings,
pad_token_id=processor.tokenizer.pad_token_id,
eos_token_id=processor.tokenizer.eos_token_id,
use_cache=True,
bad_words_ids=[[processor.tokenizer.unk_token_id]],
return_dict_in_generate=True,
)
# output
sequence = processor.batch_decode(outputs.sequences)[0]
sequence = sequence.replace(processor.tokenizer.eos_token, "").replace(processor.tokenizer.pad_token, "")
sequence = re.sub(r"<.*?>", "", sequence, count=1).strip() # remove first task start token
print(processor.token2json(sequence))
実行結果

こちらは入力文書画像をクラス分類するタスクプロンプトに「"<s_rvlcdip>"」と設定してあげるとこのタスクがこなせるようになる。上手くいくのかどうか疑問だったが請求書のほうの検証用画像ではいい感じにクラス分類ができていた!(なお、デモ画像のほうは省略、スクリプトのほうには残している)
QA
# !pip3 install torch torchvision torchaudio
# !pip install transformers pillow datasets
import re
from transformers import DonutProcessor, VisionEncoderDecoderModel
from datasets import load_dataset
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
# model set
processor = DonutProcessor.from_pretrained("naver-clova-ix/donut-base-finetuned-docvqa")
model = VisionEncoderDecoderModel.from_pretrained("naver-clova-ix/donut-base-finetuned-docvqa")
model.to(device)
# load document image
img_path = "ocr_test_sample_invoice.png"
image = Image.open(img_path).convert("RGB")
question = "How much will I be charged?"
# load document image from the DocVQA dataset
#dataset = load_dataset("hf-internal-testing/example-documents", split="test")
#image = dataset[2]["image"]
#question = "How much change did you get?"
# prepare decoder inputs (demo) + プロンプト設定
task_prompt = "<s_docvqa><s_question>{user_input}</s_question><s_answer>"
prompt = task_prompt.replace("{user_input}", question)
decoder_input_ids = processor.tokenizer(prompt, add_special_tokens=False, return_tensors="pt").input_ids
pixel_values = processor(image, return_tensors="pt").pixel_values
# generate text
outputs = model.generate(
pixel_values.to(device),
decoder_input_ids=decoder_input_ids.to(device),
max_length=model.decoder.config.max_position_embeddings,
pad_token_id=processor.tokenizer.pad_token_id,
eos_token_id=processor.tokenizer.eos_token_id,
use_cache=True,
bad_words_ids=[[processor.tokenizer.unk_token_id]],
return_dict_in_generate=True,
)
# output
sequence = processor.batch_decode(outputs.sequences)[0]
sequence = sequence.replace(processor.tokenizer.eos_token, "").replace(processor.tokenizer.pad_token, "")
sequence = re.sub(r"<.*?>", "", sequence, count=1).strip() # remove first task start token
print(processor.token2json(sequence))
実行結果
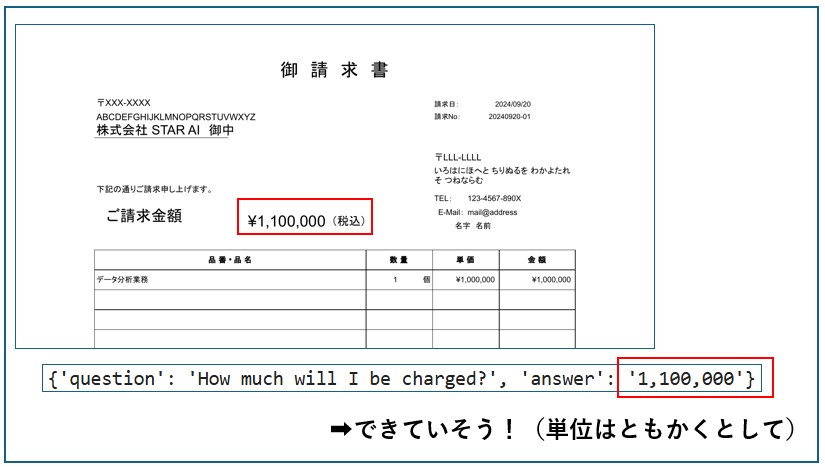
こちらは入力文書画像を理解して質問に答えるタスク。タスクプロンプトに「"<s_docvqa><s_question>{user_input}</s_question><s_answer>"」と設定({user_input}に実際の質問が入る)してあげるとこのタスクがこなせるようになる。こちらもクラス分類同様上手くいくのかどうか疑問だったがちゃんと答えることができている(OCRのほうでは金額をとるのをミスっていたような気もするが…、そこは見なかったことにしよう)!
こうみるとかなりの精度でこういったタスクがこなせるようになっていているんだなぁと改めて実感する(なお、デモ画像のほうは省略、スクリプトのほうには残している)。
5.3 所感
かなり文書理解のほうにも踏み込んでくれているイケてるOCRモデルだと思った。特に英語で何かやるときはかなり役に立ちそう。日本語は一部対応という感じなので今後の発展に期待(自分で作ろう)。
かなり発展的なモデルなので、将来的にいろいろ使えそうであるが、今のOCRタスク(日本語込み)に直接使えるかというと、そこはなかなか難しいというのが使ってみての正直な感想。最終的には、文書画像投げて、○○のデータを抽出して、みたいな感じで一気通貫でOCR~データ抽出タスクをこなしてくれるくらいのポテンシャルを感じる。
ちゃんとOCRの機能もあるので、画像だけ読み込んでタスクの結果だけ出して終わりみたいな感じではないというところも好印象。
6. AzureAI Document Intelligence (Read model/Custom model)
今回はAzureAI Document Intelligenceの一部についてまとめました。
こういったOCRサービスは他にも(Google Cloud Visionなど)あるとは思いますが、今回はたまたまこれを触ったという理由でこれだけの紹介になりますスミマセン。
また、AzureAI Document Intelligenceの基本的な使い方については説明は省略します。
Azure Portalからリソースを作成し、キーとエンドポイントを取得しているという前提で話を進めます。
6.1 モデル概要(というよりサービス概要)
AzureAI Document Intelligence(旧称:Form Recognizer)は、Microsoft Azureが提供するクラウドベースのサービスで、AIを活用して文書から情報を自動的に抽出することができるというもの。このサービスでは、機械学習、ディープラーニング技術を活用し、領収書、請求書、IDカード、ビジネスカード、論文など、さまざまなフォーマットの文書を効率的かつ高精度に処理(テキスト抽出~構造化など)することができる。pythonのサンプルコードなども準備されており、GUIだけでなく、pythonと連携して様々なサービスを作ることもできる(ここではpythonで実行した例を掲載)。
ここでは、2つのモデルを紹介
- Read model: 普通にOCRして、文書画像内のテキスト抽出を行うシンプルなモデル(あらかじめAzure側で準備されていてお手軽に使うことが可能)。
- Custom extraction model: 予め画像内でアノテーションを与えて、文書内の特定の情報を直接抽出することをできるようにするモデル(あらかじめ学習が必要)。先に、バウンディングボックスを与え、この領域は○○という変数に格納するという指示(アノテーション)を与えてあげないといけない。これを指定したのちモデルを学習、実際の画像に適用することで、文書内で抽出したい情報を(変数に格納してくれるので)直接取得できるようになる。アノテーションコストやレイアウトが崩れた場合の影響などはあるが、フォーマットが固定されているなど特定の状況ではかなり強力なOCRツールとなりうる(以下はアノテーションなど簡単な使い方の例、片手落ち感ありますがご容赦ください)。
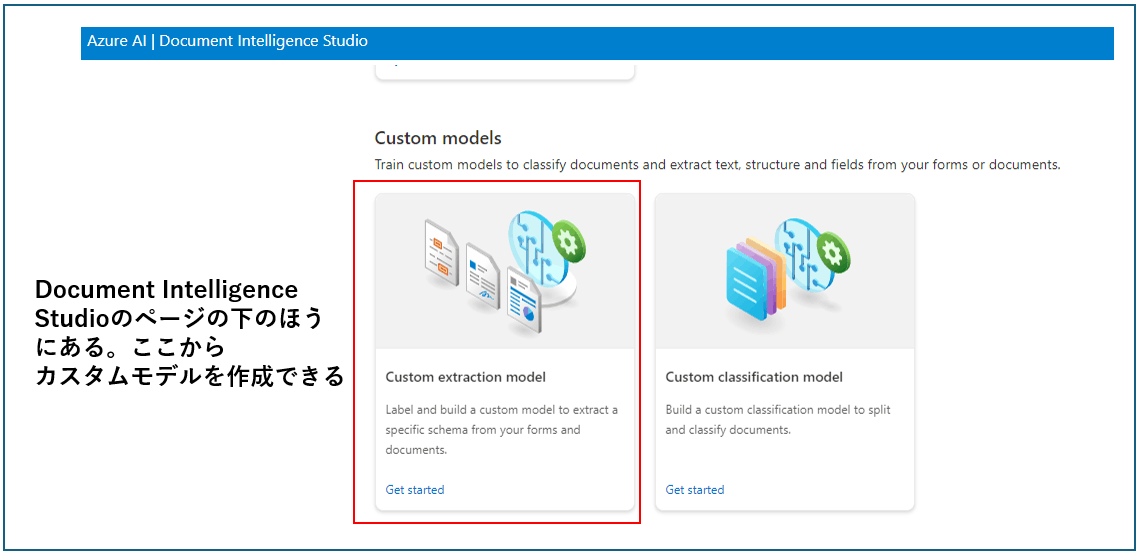
↓
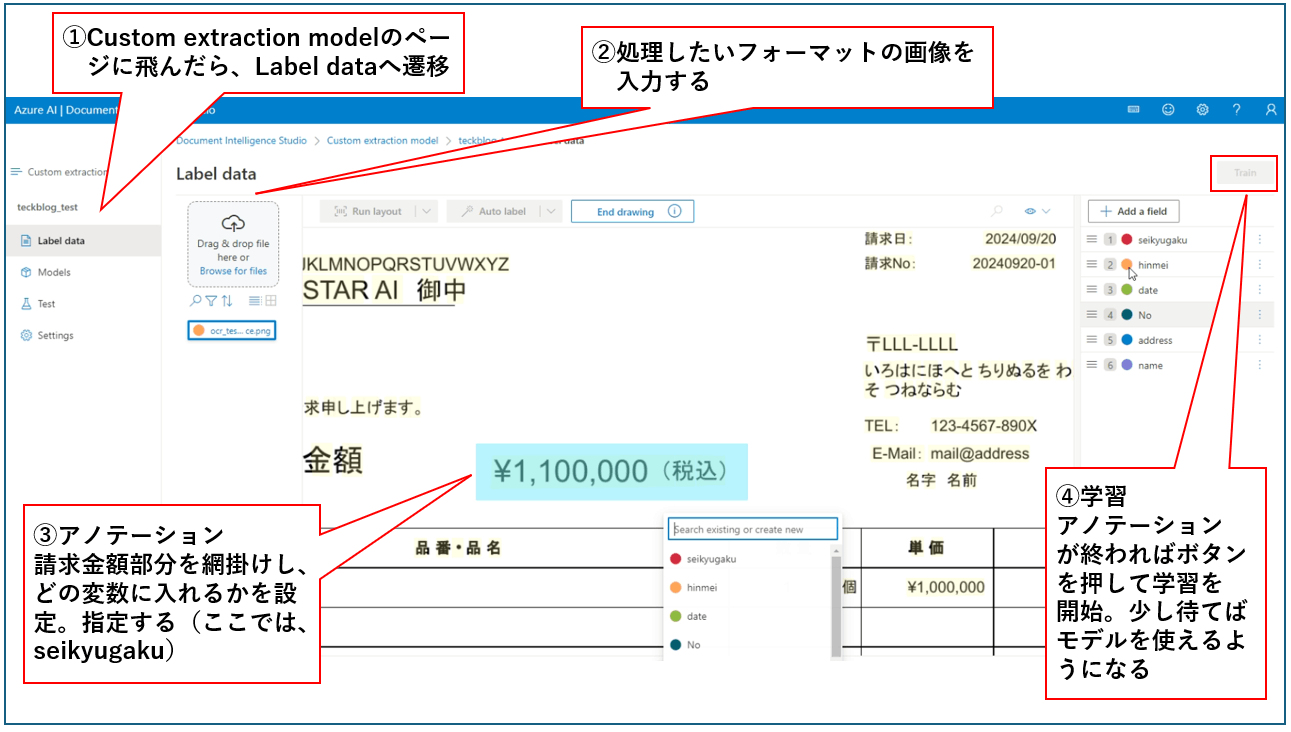
↓
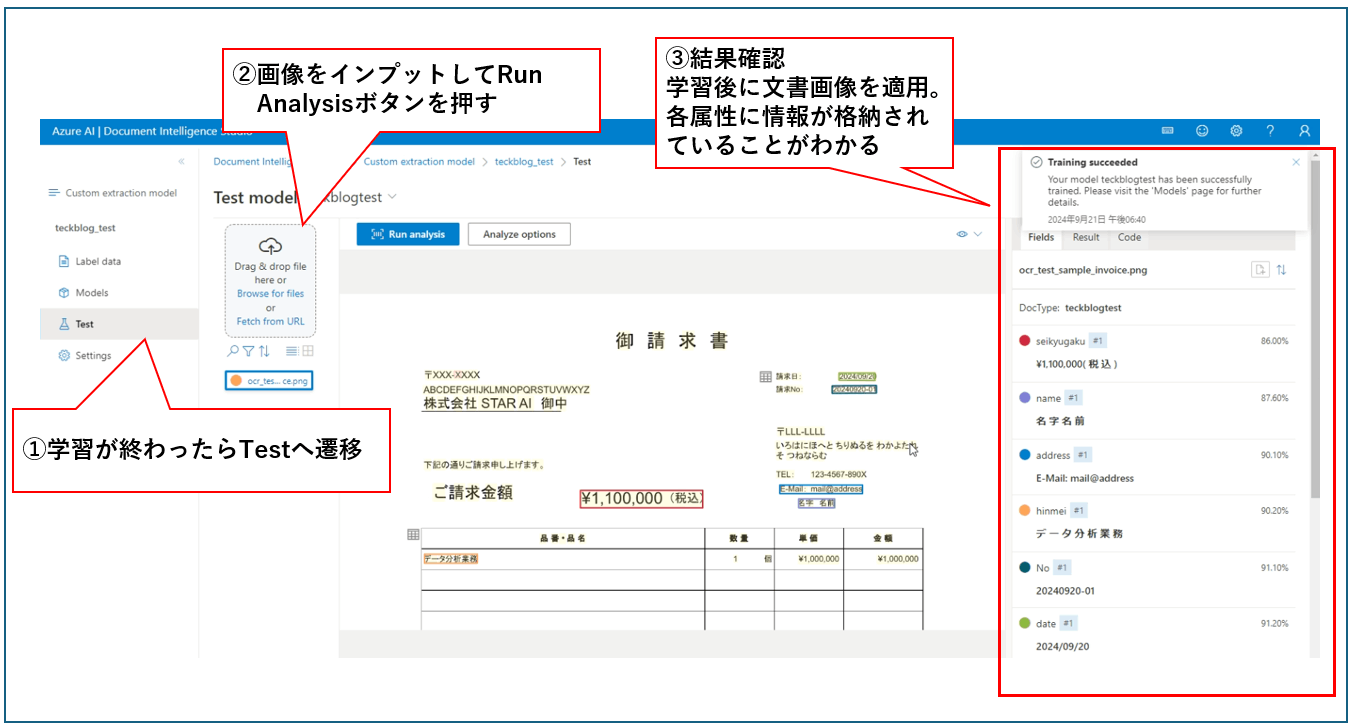
6.2 サンプルコード
コード内のendpointやkeyは、自分のものを設定してください。
read model
# pip install azure-core azure-ai-documentintelligence azure-ai-formrecognizer
# pip install opencv-python pillow
from azure.core.credentials import AzureKeyCredential
from azure.ai.formrecognizer import DocumentAnalysisClient
import cv2
import numpy as np
from PIL import ImageFont, ImageDraw, Image
# Document Intelligence Studioにおけるコードを参考に記述しています
def format_bounding_box(bounding_box):
if not bounding_box:
return "N/A"
return ", ".join(["[{}, {}]".format(p.x, p.y) for p in bounding_box])
endpoint = "YOUR_FORM_RECOGNIZER_ENDPOINT"
key = "YOUR_FORM_RECOGNIZER_KEY"
img_path = "ocr_test_sample_invoice.png"
# クライアント設定
document_analysis_client = DocumentAnalysisClient(
endpoint=endpoint, credential=AzureKeyCredential(key)
)
# インプット準備
with open(img_path, "rb") as fd:
document = fd.read()
# モデル適用、結果取得
poller = document_analysis_client.begin_analyze_document("prebuilt-read", document=document)
result = poller.result()
# 以下結果出力・描画
# 日本語フォントのパスを指定
# Windowsは下記、他OSは適宜設定
font_path = 'C:/Windows/Fonts/msgothic.ttc'
font = ImageFont.truetype(font_path, 20)
# 画像に(バウンディングボックスと)テキストを描画(見やすさのため白画像に文字を置いていく感じで実装)
img = cv2.imread(img_path)
rgb_img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
#img_pil = Image.fromarray(rgb_img) # 上書きしたい場合
img_pil = Image.fromarray(np.full_like(rgb_img, 255)) # rgb_img
draw = ImageDraw.Draw(img_pil)
for page in result.pages:
print("----Analyzing Read from page #{}----".format(page.page_number))
print(
"Page has width: {} and height: {}, measured with unit: {}".format(
page.width, page.height, page.unit
)
)
for line_idx, line in enumerate(page.lines):
print(
"...Line # {} has text content '{}' within bounding box '{}'".format(
line_idx,
line.content,
format_bounding_box(line.polygon),
)
)
# format_bounding_box(line.polygon)
draw.text( (line.polygon[0][0],line.polygon[0][1]), line.content, font=font, fill="red")
# 結果画像を保存(Pillow -> cv2)
rgb_img = np.array(img_pil)
result_img = cv2.cvtColor(rgb_img, cv2.COLOR_RGB2BGR) #RGB2BGR
cv2.imwrite(img_path.split(".")[0] + "_azure_result.png", result_img)
実行結果

言うことなし!

言うことなし!
まさかどちらも文句なしの結果が得られるとは…(処理対象はたった2枚なので、これをもって十分ということではないことは重々承知ではある、というか過信は厳禁)。
Custom extraction model
# pip install azure-core azure-ai-documentintelligence azure-ai-formrecognizer
# pip install opencv-python pillow
from azure.core.credentials import AzureKeyCredential
from azure.ai.formrecognizer import DocumentAnalysisClient
# 初期設定
endpoint = "YOUR_FORM_RECOGNIZER_ENDPOINT"
key = "YOUR_FORM_RECOGNIZER_KEY"
model_id = "YOUR_MODEL"
img_path = "ocr_test_sample_invoice.png"
# クライアント設定
document_analysis_client = DocumentAnalysisClient(
endpoint=endpoint, credential=AzureKeyCredential(key)
)
# 画像セット
with open(img_path, "rb") as fd:
document = fd.read()
# 属性情報抽出
poller = document_analysis_client.begin_analyze_document(model_id, document=document)
result = poller.result()
# 結果出力
for idx, document in enumerate(result.documents):
print("--------Analyzing document #{}--------".format(idx + 1))
print("Document has type {}".format(document.doc_type))
print("Document has confidence {}".format(document.confidence))
print("Document was analyzed by model with ID {}".format(result.model_id))
for name, field in document.fields.items():
#print("!", name, field)
field_value = field.value if field.value else field.content
print("......found field of type '{}' with key '{}' and value '{}' and with confidence {}".format(field.value_type, name, field_value, field.confidence))
実行結果
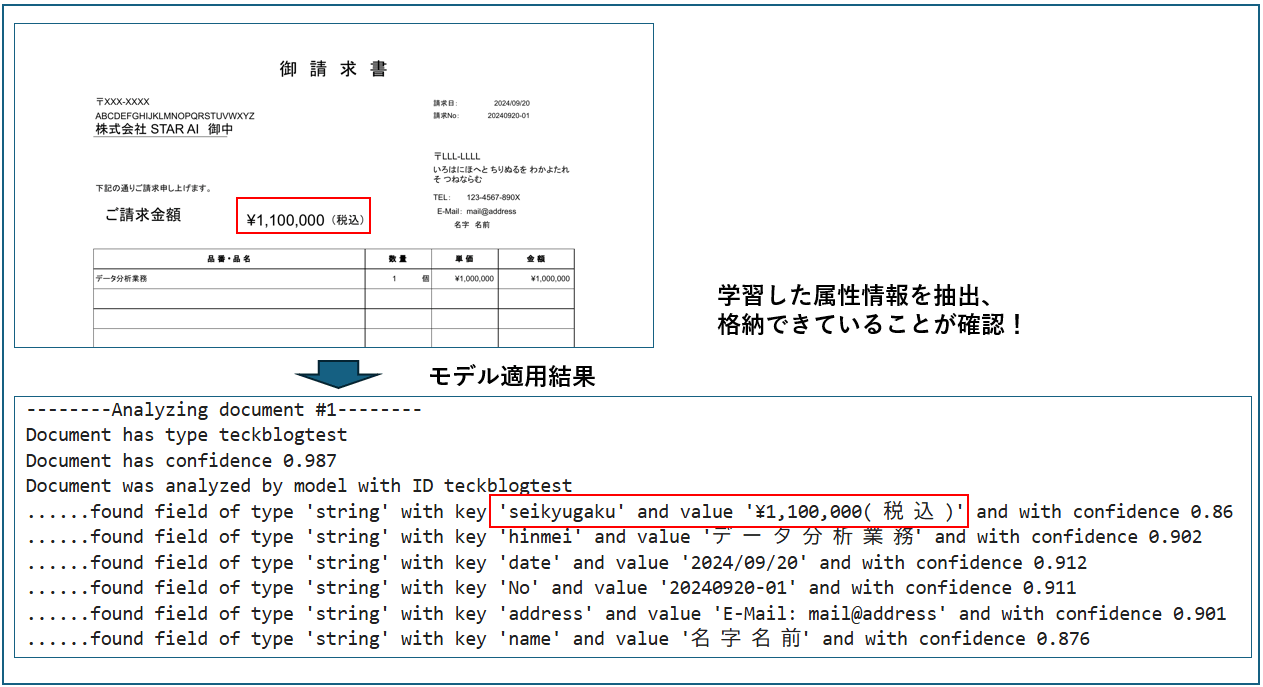
ここでは、ダミー請求書サンプルを適用し、上で簡単な使い方を説明した部分でアノテーションした請求金額の属性についてデータを抽出・格納できていることが確認できた(ほかの属性もアノテーションしているが割愛)。フォーマット決め打ちという制約はあるが、データをいきなり取りに行って格納してくれるのでかなり効率は良いと思われる(通常であれば抽出テキストから必要な情報をとりにいかないといけないが、これの処理がなくなる(コードを書かなくていい)のでメンテナンスの観点からもうれしい)。
6.3 所感
精度もかなり良く、特に制約がないならこれを使っとけばいいんじゃないという気分にさせてくれるサービス(笑)。単にドキュメントを読むだけでなく、指定した情報を直接取りに行ったりできるカスタムモデルもあるので、色々と活用の幅は広いと思う。とはいえ、精度100%ということは絶対にないので過信はせずに、誤りを想定した処理を必ず組んでおくこと。特にCustom extraction modelは、レイアウトが崩れたりすると簡単に破綻すると思われます(ここまでの、ローカルモデルと比べると性能差はかなりあると思うので、使えるなら、ご認識への対応などの苦労はかなり少なく済むかも)。
また、DonutやLayoutLMv3のような文書理解的なサービスではないような感じ。これ単体でなく、他と組み合わせたらより高度なことができそう。
料金についても調べてみた(日本のDCでいくらかを見る、2024/09/21時点)。サービスや運用の際の指標として頭に入れておきたい。
-
Read model: 0-1M pages - ¥216.773 per 1,000 pages
- だいたい1ページあたり約0.2円
-
Custom extraction model: ¥4,335.451 per 1,000 pages
- だいたい1ページあたり約4.3円
これを見る感じ、フォーマットが決め打ちで月に扱う枚数もそこまで多くないというケースであればCustom extraction modelを使っても問題なさそう(大量に処理する場合はお財布と相談)。対して、自分で必要な部分をとってこれるようであればRead modelで十分運用できると思う(そのためには抽出結果をパースするなどして必要な情報を抽出する必要があるので、複雑なフォーマットだといろいろと大変。書類フォーマットの決定段階で手を入れられるなら、できるだけシンプルに書類を作成することをお勧めする)。
最後に
全体通しての感想
今回OCRについて、まとめて色々と調査できたのでかなり勉強になったというのが率直な感想(もちろん抜けもあるが)。とはいっても、あくまでも広く浅くみたいな感じで調べたので、それぞれのモデルをより使いこなす(精度や汎用性を上げていく)という点では不十分だったと思うので、これからまた論文やドキュメントを読んだり、コードで書いたりしてこのあたりのギャップを埋めていきたい。
個人的には、データをどこまで外に出していいかという点で制限がないならAzureAI Document Intelligence(今回紹介できなかったけどGoogle Cloud Visionとかもこれに当たるかな)でいいじゃん、という感じだが、世の中そうそう上手くはいかないので、EasyOCRやPaddleOCR、マシンスペックが問題ないならDonutとかローカル環境のOCRモデルもある程度使いこなせるようになっておいたほうがいいと思うというのが率直なところ。
次回以降に向けて
色々調べていたらこんな論文(General OCR Theory: Towards OCR-2.0 via a Unified End-to-end Model)がでてきたので、これを読んでまた記事を書こうかな(来月以降の宿題、まだまだ新しいモデルとか出てくるだろうなぁ)。あと今回は、純粋なOCRというには少し違ったためこの中には含めなかったLayoutLMv3についてもまた改めて調査をしてまとめてみたい(また画像処理になってしまう…がまあいいか。他のメンバーがきっと他テーマで投稿してくれるはず!w)。
おわり

Discussion