SREホールディングス株式会社 でデータサイエンティストをやっている井上です。
私は、新NISAを活用するにあたって個別株投資も行っているのですが、銘柄選びのための企業分析をするにあたって毎回、企業のHPから有価証券報告書のPDFを持ってきて財務指標などを確認していました。この作業は毎回手間と時間がかかりとても大変でした。。。
そこで、必要なデータを効率的に確認できないかと思って調べたところ金融庁が提供しているEDINETというシステムを発見しました。こちらのシステムを活用することで企業の財務データ等を自動で収集し、統一されたフォーマットでの一元管理を行えるようです。今回はEDINETからデータを取得するまでの流れと、実際に取得したデータを使って企業の財務状況を確認していきます。
対象読者
- 個別株投資に興味のある方
- 有価証券報告書の確認を効率的に行う方法を知りたい方
扱う内容
- EDINETから有価証券報告書を入手する方法
- 特定の項目を有価証券報告書から取り出す方法
扱わない内容
- 本格的な財務分析
- 株価チャートのテクニカル分析(特定の指標を用いた意思決定を行うための分析)
EDINETとは?
EDINETは金融庁が提供している「金融商品取引法に基づく有価証券報告書等の開示書類に関する電子開示システム」のことです。企業や法人は有価証券報告書や四半期報告書などの開示書類を電子的に提出しています。
提出された資料は、無料で取得して確認することができます。
有価証券報告書は企業が年に一度提出する法定の書類で、会社の財務状況や経営成績、リスクなどに関する重要な情報が掲載されています。貸借対照表(企業の資産、負債、および株主資本)や損益計算書(企業の収益と費用)についてもこちらで確認できます。
XBRLとは?
eXtensible Business Reporting Languageの略称で、
財務・経営・投資などの様々な情報を作成・流通・利用できるように標準化されたXMLベースのコンピュータ言語です。
XBRLは、大きく2つの要素で構成されます。
-
インスタンス文書
実際の財務データやその他の報告データを含む文書。特定の時点または期間に関する企業の財務状態や業績を表す。 ⇒
~.xbrlファイル -
タクソノミ (Taxonomies):
インスタンス文書で使用されるデータ要素の分類体系。タクソノミは会計基準に基づいて構築され、財務諸表に使用される要素(例えば、収益、費用、資産、負債等)の定義、属性、関係性を提供する。⇒
.xsb/xmlファイル構成は以下の通りです。
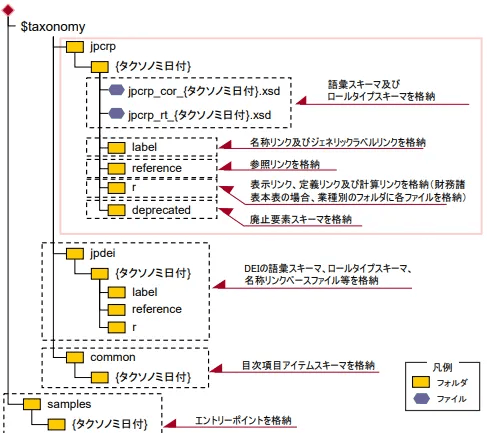
「提出者別タクソノミ作成ガイドライン 図表 2–1–18 EDINET タクソノミのフォルダ構成(1)」より引用
つまり、タクソノミは報告書の「設計図」であり、インスタンス文書はその設計図に基づいて構築された「建物」と理解できます。
(※XBRLについては、この記事の投降者の理解度が低いため間違えたことを書いている可能性が十二分にあるのでXBRL Japan様のHPをご確認ください。)
全体の流れ
- APIキーを発行してEDINETにアクセスする
- 実際に有価証券報告書をダウンロードする
- ダウンロードした有価証券報告書から財務3表の内、BS/PLを取り出す
- 実際に可視化して確認
1.APIキーを発行してEDINETにアクセスする
2024年8月21日よりcsvの追加、認証機能の強化等を行ったAPIが提供されており、これからEDINET APIを使用する方はAPI Keyをこちらで発行してもらう必要があります。
必要なものはメールアドレスと電話番号です。
(電話番号は080-XXXX-XXXXという番号の場合、 +81(Japan)を選ぶので、フォームのところには80-XXXX-XXXXとしていないとメッセージが届きませんのでご注意ください)
「EDINET API機能追加に係る利用者向け説明会
資料」より引用
API Keyを発行出来たので、実際に使用して実際にEDINETにアクセスし2024年9月11日にアップロードされている決算関連書類の一覧を取得します。
[コード]
import requests
import json
# APIのエンドポイント
url = 'https://disclosure.edinet-fsa.go.jp/api/v2/documents.json'
api_key = "発行したAPI Key"
# パラメータの設定
params = {
'date': '2024-09-11',
'type': 2, # 2は有価証券報告書などの決算書類
"Subscription-Key": api_key
}
# APIリクエストを送信
response = requests.get(url, params=params)
# レスポンスのJSONデータを取得
data = response.json()
# フォーマットされたJSONデータをファイルに保存
with open('edinet_data.json', 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, indent=4)
print("データが 'edinet_data.json' に保存されました。")
[レスポンス]
"metadata": {
"title": "提出された書類を把握するためのAPI",
"parameter": {
"date": "2024-09-11",
"type": "2"
},
"resultset": {
"count": 182
},
"processDateTime": "2024-09-11 18:59",
"status": "200",
"message": "OK"
},
"results": [
{
"seqNumber": 1,
"docID": "S100UCCT",
"edinetCode": "E13447",
"secCode": null,
"JCN": "2010401045054",
"filerName": "SBIアセットマネジメント株式会社",
"fundCode": "G15330",
"ordinanceCode": "030",
"formCode": "04A000",
"docTypeCode": "030",
"periodStart": null,
"periodEnd": null,
"submitDateTime": "2024-09-11 09:00",
"docDescription": "有価証券届出書(内国投資信託受益証券)",
"issuerEdinetCode": null,
"subjectEdinetCode": null,
"subsidiaryEdinetCode": null,
"currentReportReason": null,
"parentDocID": null,
"opeDateTime": null,
"withdrawalStatus": "0",
"docInfoEditStatus": "0",
"disclosureStatus": "0",
"xbrlFlag": "1",
"pdfFlag": "1",
"attachDocFlag": "1",
"englishDocFlag": "0",
"csvFlag": "1",
"legalStatus": "1"
}
レスポンスデータの内容で把握しておくべき内容はざっくりと以下の通りです。
| 項目名 | 項目ID | 型 | 説明 |
|---|---|---|---|
| 連番 | seqNumber | number | ファイル日付ごとの連番 |
| 書類管理番号 | docID | string | 書類管理番号 |
| 提出者EDINETコード | edinetCode | string | 提出者のEDINETコード |
| 提出者証券コード | secCode | string | 提出者の証券コード |
| 府令コード | ordinanceCode | number | 書類の提出根拠となる指令 |
| 様式コード | form_code | string | 書類の様式 |
詳しいことはEDINET公式ページからページの下にあるEDINETコードリストCSVファイルをダウンロードしてご確認ください。
2.実際に有価証券報告書をダウンロードする
ここまでで、EDINETに提出された資料について種類・管理番号などの含めた情報を取得することができました。
次に、これらの情報からresultsの提出書類を絞り込みます。
ordinanceCode(府令コード)と form_code(様式コード)を使用してデータの抽出を行います。
今回は有価証券報告書を対象とするため、ordinanceCodeが010、form_codeが030000の提出書類からdocIDを取り出してみます。
for num in range(len(json_data["results"])):
ordinance_code= json_data["results"][num]["ordinanceCode"]
form_code= json_data["results"][num]["formCode"]
if ordinance_code == "010" and form_code =="030000" :
securities_report_doc_list.append(json_data["results"][num]["docID"])
コードはこちらを参考にさせていただきました。
最後に、絞り込んだ中からdocIDを使用して、有価証券報告書を入手します。
docid = "上記で取得したdocID"
zip_path = os.path.join(folder_path, f"{docid}.zip")
url = f"https://disclosure.edinet-fsa.go.jp/api/v2/documents/{docid}"
api_key = "発行したAPI Key"
params = {"type": 1, # リクエストパラメータ: 監査報告書、XBRLファイルを取得(2はpdf)
"Subscription-Key":api_key}
try:
print(f"Downloading {docid}...")
res = requests.get(url, params=params, verify=False)
if res.status_code == 200:
with open(zip_path, 'wb') as f:
for chunk in res.iter_content(chunk_size=1024):
f.write(chunk)
if zipfile.is_zipfile(zip_path):
with zipfile.ZipFile(zip_path) as zip_f:
zip_f.extractall(os.path.join(folder_path,docid))
print(f"Extracted {docid} in {folder_path}")
os.remove(zip_path) # ZIPファイルを削除
else:
print(f"{zip_path} is not a Zip File")
except Exception as e:
print(f"Error downloading or extracting {docid}: {e}")
3.ダウンロードした有価証券報告書から財務3表の内、BS/PLを取り出す
ここまででEDINETにアクセスして、有価証券報告書を取得することができました。

取得したXBRL形式のデータを解析していくことでBS(貸借対照表)や、PL(損益計算書)から企業の財務健全性・収益のパフォーマンスを確認することができます。
XBRLからBS/PLを取得するコードはこちらを参考にさせていただきました。
財務諸表や報告書内での要素の表示順序やグルーピングを定義するプレゼンテーションリンクベース(_pre.xml)を確認すると、presentationLink要素(と子要素であるloc要素、presentationArc要素)は有価証券報告書における大項目の構造を定義しています。
presentationLink要素内の構造は目次項目(href属性のidがHeadingで終わる項目)をルートとした木構造となっており、この構造を読み込むことで各勘定項目の値と関係を把握することが可能になります。
私も理解しきれていないのですが、以下に簡単なXBRLの構造を定義するタブと属性の関係性をまとめました。
プレゼンテーションリンクベース内の主要なタブとそれらの役割

プレゼンテーションリンクベース(_pre.xml)の構成図
これらのタブでは、以下の属性が使用されています。これらの属性を理解することで、XMLファイル内の各要素間の関係性や役割をより深く理解できます。
-
link:linkbase; xmlファイル内で下記の要素を包括するタグ。- タグの役割: XBRL文書内のリンクベースを定義。概念(Concept)間の関係を定義し、その関係を解釈するための情報を提供する。
- レシピにおいて「卵は小麦粉と混ぜてから焼く」という手順があるように、「資産は負債から引いた後、純利益として表示される」といった関係を示す
-
link:roleRef; その概念が文書内でどのような役割を果たしているかを示す。 -
link:presentationLink; 文書内の概念がどのように表示されるかが定義される。-
link:loc; プレゼンテーションリンクの開始点や終了点を定義⇒表示される概念の位置を示す。 -
link:presentationArc; 概念間のプレゼンテーションの関係を定義⇒階層関係や表示の順序が含まれる。
-
タブの中で使用されている属性については以下
link:linkbase 要素
-
xmlns:link; XMLドキュメント内でXLink(XML Linking Language)を使用するための名前空間を定義。文書やデータ間で複雑なリンク構造を設定することが可能にする。
xlink 属性は、XML文書内で特定の要素にリンクを定義するために使用され、情報の連携や参照が容易になる
-
xlink:type:
-
リンクの種類を示す。
-
linkのタイプについて
simple:
- この値は、単一のリソースを指し示す単純なリンク
extended:
- 複数のリソース間のリンクを設定するために使用され、より複雑なリンク構造を持つことができる。
locator:
- 特定のリソースを指し示すために使用され、リンクのターゲットとなるリソースの場所を示す。
arc:
- リソース間のリンク(関係)を定義するために使用される。
-
-
xlink:href:
- リンクのターゲット(リンク先)を指定、リンク先のURIやリンクセットのIDが指定される。
-
xlink:arcrole:
- アーク(Arc:要素間の関係を示すリンク)の役割を指定し、リンクの開始点と終了点の間の関係の種類を表す。
<link:presentationArc xlink:type="arc" xlink:arcrole="http://www.xbrl.org/2003/arcrole/parent-child" xlink:from="InvestmentsAndOtherAssetsAbstract" xlink:to="StocksOfSubsidiariesAndAffiliates" order="2.0" />上記の例では、概念間の親子関係を表すために、
xlink:arcrole属性でhttp://www.xbrl.org/2003/arcrole/parent-childというURIを指定。要素間の関係性が親子関係であることを明示する。 -
xlink:role:
-
リンク先がどのような役割を果たしているかを示す。例えば、
link:presentationLink要素では、xlink:role属性でhttp://disclosure.edinet-fsa.go.jp/role/jppfs/rol_ConsolidatedStatementOfChangesInEquityのようなURIを指定し、特定の財務諸表(この場合は「連結株主資本等変動計算書」)の表示ルールを定義する。<link:presentationLink xlink:type="extended" xlink:role="http://disclosure.edinet-fsa.go.jp/role/jppfs/rol_ConsolidatedStatementOfChangesInEquity"> </link:presentationLink>
-
-
xlink:from:
- アークの開始点を指定。アークがどの要素から始まるかを示す。
-
xlink:to:
- アークの終了点を指定。アークがどの要素に向かっているかを示す。
-
xlink:title:
- リンクのタイトルや説明を提供。リンクが何を表しているかを簡潔に説明するために使用される。
4.実際に可視化して確認
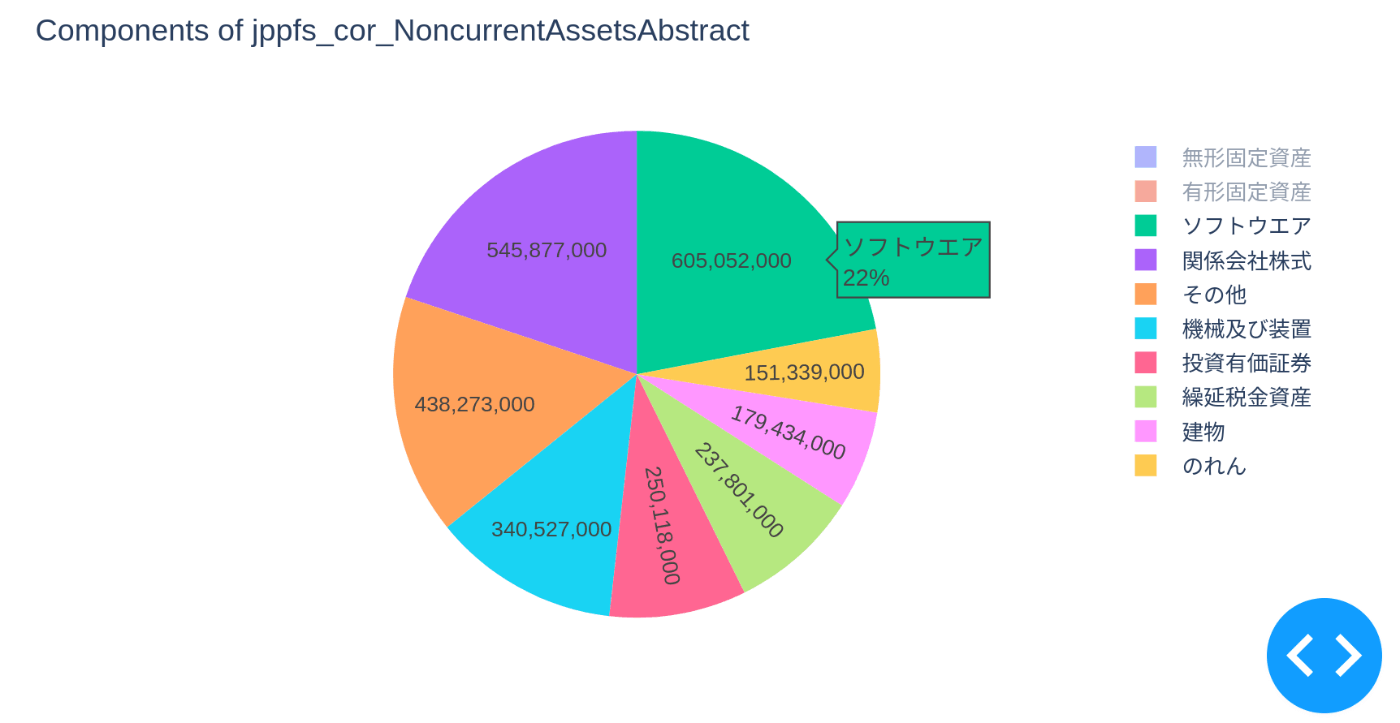
上記を活用して、実際に弊社の2022年度有価証券報告書から連結貸借対照表と連結損益計算を可視化してみました。
-
連結貸借対照表

-
流動資産の内訳(>0)
-
連結損益計算
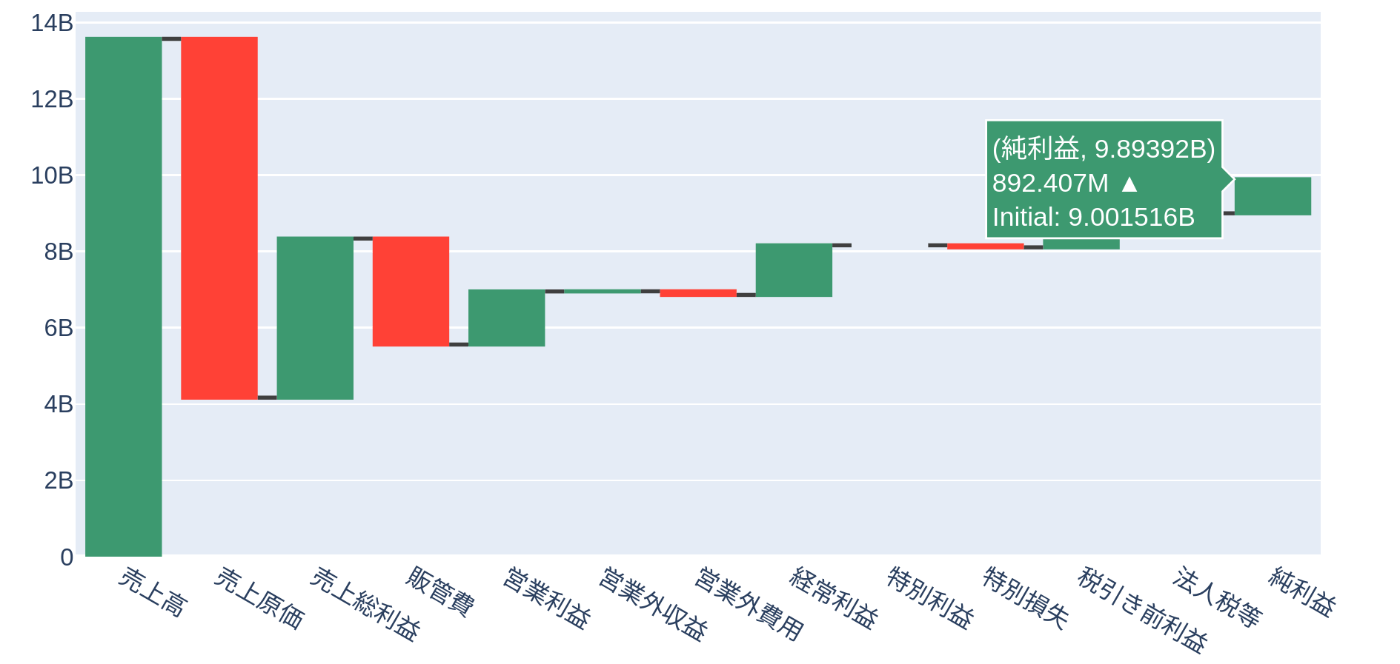
-
営業外費用の内訳

まとめ
いかがでしたでしょうか。駆け足になってしまいましたが、EDINETを使用して有価証券報告書をダウンロードして解析することで、各企業の詳細な財務健全性や実際の営業成績を簡単に確認できるようになりました。
次のステップとしては、決算内容と株価の関係性について分析してみたら面白いかと思います。

Discussion