はじめに
生成AIの分野のなかで自社のドキュメントをもとに回答を行わせたいユースケースの場合は、RAGが採用されることがほとんどです。
RAGの技術を利用するとCSVなどの構造化されているデータ以外のPDFやDocsファイルなど非構造な形式のデータも活用することができます。一方で実際の導入においては既に企業に存在しているCSVなどの表形式のデータをインプットとして利用することが、これまで実際にお客様へご支援する際に多くありました。
この記事では、FAQ形式のCSVデータのみをもとに回答させるユースケースの場合にどのような構成がより高い精度を実現できるかの比較検証を行います。
そもそも、RAGの構成について振り返り
RAGを構成する際の大きな要素として、「事前に与えたドキュメントの検索」と「検索結果にもとづく回答生成」の2つのプロセスがあります。これらの仕組みや構成については以下の記事が参考になるため、参考にしていただけると幸いです。この記事ではCSVデータのみをもとに回答させるユースケースの場合の比較検証に限った解説を行います。
参考:
今回の検証での評価の考え方
利用するデータ
LLMで作成したダミーのFAQ形式のデータを利用します。以下にダミーデータの全文を記載するため、もしよければご利用ください。
RAGに参照させるCSVデータ
Question,Answer
営業時間は何時から何時までですか?,当店の営業時間は9:00から18:00までです。
休日はいつですか?,休日は毎週日曜日と祝日です。
商品Aの価格はいくらですか?,"商品Aの価格は1,000円です。"
商品の返品は可能ですか?,未使用の場合、購入から7日以内であれば返品可能です。
オンライン注文はできますか?,はい、当社のウェブサイトからオンライン注文が可能です。
送料はいくらですか?,送料は全国一律500円です。
クレジットカードは使用できますか?,はい、主要なクレジットカードがご利用いただけます。
現金払いは可能ですか?,はい、現金払いも受け付けております。
商品の在庫はどのように確認できますか?,在庫状況はウェブサイトまたはお電話でご確認いただけます。
配送にかかる日数はどのくらいですか?,通常、発送から2〜3営業日以内にお届けします。
店頭での受け取りは可能ですか?,はい、店頭受け取りも対応しております。
サポート窓口の電話番号は何ですか?,サポート窓口の電話番号は0120-123-456です。
メールで問い合わせできますか?,はい、info@example.comまでお問い合わせください。
キャンペーンはいつ実施されますか?,キャンペーンの詳細はニュースレターまたはウェブサイトをご確認ください。
商品の保証期間はどのくらいですか?,商品の保証期間は購入日から1年間です。
製品マニュアルはどこで入手できますか?,製品マニュアルはウェブサイトからダウンロードできます。
注文のキャンセルは可能ですか?,発送前であればキャンセル可能です。
ギフトラッピングはできますか?,はい、ギフトラッピングサービスをご利用いただけます。
ポイントプログラムはありますか?,はい、購入ごとにポイントが貯まるプログラムをご用意しています。
商品のレビューはどこで確認できますか?,商品ページにレビューが掲載されています。
修理サービスはありますか?,はい、修理サービスをご提供しております。
取扱店舗を教えてください。,取扱店舗はウェブサイトの店舗一覧をご覧ください。
海外配送は可能ですか?,現在、海外配送には対応しておりません。
法人向けサービスはありますか?,はい、法人向けサービスも承っております。
商品の取り置きはできますか?,取り置きは最長7日間可能です。
再入荷の予定はありますか?,再入荷予定は商品ページでご確認いただけます。
商品Aのサイズ展開を教えてください。,商品AはS、M、Lの3サイズ展開です。
初めて利用する際の登録方法を教えてください。,ウェブサイトの「新規登録」ボタンから登録できます。
パスワードを忘れた場合はどうすればよいですか?,パスワードリセットページで手続きを行ってください。
返品時の送料は誰が負担しますか?,返品時の送料はお客様のご負担となります。
納品書はどこで確認できますか?,納品書は商品と一緒にお届けします。
領収書の発行は可能ですか?,はい、領収書の発行が可能です。
商品の特徴を教えてください。,商品の特徴は商品ページに記載されています。
法人契約について教えてください。,法人契約の詳細は専用窓口にお問い合わせください。
注文履歴はどこで確認できますか?,注文履歴はマイページでご確認いただけます。
発送完了の通知はもらえますか?,はい、発送完了時にメールで通知いたします。
購入時の注意点を教えてください。,商品説明をよくお読みの上でご購入ください。
予約注文はできますか?,予約注文は対応しておりません。
商品の開封後でも返品できますか?,開封済み商品の返品はお受けできません。
特定の商品に関するお問い合わせ方法を教えてください。,商品ページのお問い合わせフォームからご連絡ください。
現在の在庫状況はどこで確認できますか?,ウェブサイトまたは店舗に直接お問い合わせください。
追加注文は可能ですか?,はい、追加注文は可能です。
配達日時の指定はできますか?,配達日時の指定が可能です。
保証書の再発行はできますか?,保証書の再発行は対応しておりません。
クーポンコードはどこで入力しますか?,クーポンコードは決済画面で入力できます。
配送業者を選ぶことはできますか?,配送業者の指定は承っておりません。
大量注文の場合の割引はありますか?,大量注文の場合は別途ご相談ください。
試供品は提供していますか?,一部商品に試供品をお付けしております。
商品の生産国を教えてください。,商品の生産国は商品ページに記載されています。
修理費用はいくらですか?,修理費用は内容によりますのでお問い合わせください。
店頭での支払い方法を教えてください。,店頭では現金、クレジットカードがご利用いただけます。
商品が破損していた場合どうすればよいですか?,商品到着後7日以内にご連絡ください。
商品が届かない場合はどうすればよいですか?,お問い合わせ窓口までご連絡ください。
顧客情報の取り扱いはどのようにされていますか?,顧客情報はプライバシーポリシーに従い厳重に管理されています。
会員登録には費用がかかりますか?,会員登録は無料です。
購入前に商品の実物を見ることはできますか?,店頭にて商品の確認が可能です。
保証期間延長サービスはありますか?,保証期間延長オプションがございます。
商品の到着日時を変更できますか?,配送日時の変更は発送前であれば可能です。
分割払いは可能ですか?,分割払いはクレジットカードで対応可能です。
法人向けの特典はありますか?,法人向けに特別なプランをご用意しています。
新商品の入荷情報はどこで確認できますか?,新商品の入荷情報はニュースレターでお知らせします。
商品の比較はどこでできますか?,商品比較機能がウェブサイトにございます。
古いモデルの商品は購入できますか?,在庫があれば購入可能です。
購入後のサポート内容を教えてください。,購入後も電話やメールでサポートを提供します。
リサイクルサービスはありますか?,はい、リサイクルサービスを実施しています。
商品の配送状況を追跡できますか?,配送状況は追跡番号で確認できます。
配送先の変更は可能ですか?,発送前であれば配送先の変更が可能です。
購入手続きが完了しません。どうすればよいですか?,サポート窓口までご連絡ください。
ギフトカードは販売していますか?,はい、ギフトカードを販売しております。
購入に関するトラブルがあった場合はどうすればよいですか?,カスタマーサポートにご相談ください。
再販商品について教えてください。,再販情報は商品ページでご確認いただけます。
商品の組み立てサービスはありますか?,はい、組み立てサービスを提供しております。
定期購入サービスはありますか?,定期購入サービスをご用意しています。
セール情報はどこで確認できますか?,セール情報はウェブサイトの特設ページでご覧いただけます。
在庫切れ商品を注文できますか?,在庫切れ商品の予約は承っておりません。
支払い方法の変更は可能ですか?,注文確定前であれば変更可能です。
問い合わせの対応時間を教えてください。,対応時間は9:00から18:00までです。
メールマガジンの登録方法を教えてください。,ウェブサイトから簡単に登録できます。
メールマガジンの解除方法を教えてください。,メールの解除リンクから手続きできます。
購入履歴の削除はできますか?,購入履歴の削除は対応しておりません。
保証対象外の条件を教えてください。,事故や誤使用による故障は保証対象外です。
商品の使用方法について教えてください。,使用方法は製品マニュアルをご覧ください。
引き取りサービスはありますか?,はい、引き取りサービスを実施しています。
お客様相談窓口はどこにありますか?,ウェブサイトまたはお電話でお問い合わせいただけます。
お届け先を複数設定できますか?,はい、複数のお届け先を設定できます。
請求書払いは対応していますか?,法人向けに請求書払いが可能です。
次回のセール時期を教えてください。,次回セールの詳細は未定です。
注文の受付状況を教えてください。,注文状況はマイページで確認できます。
返品した商品はいつ返金されますか?,返品後、7営業日以内に返金いたします。
商品の保証規定を教えてください。,保証規定は製品マニュアルをご確認ください。
ポイントの有効期限はどのくらいですか?,ポイントの有効期限は最終購入日から1年間です。
新商品の予約注文は可能ですか?,一部の商品で予約注文が可能です。
長期保証プランについて教えてください。,長期保証プランの詳細はウェブサイトをご覧ください。
中古商品の販売はしていますか?,一部中古商品も取り扱っています。
特典ポイントはいつ付与されますか?,購入完了後、即時付与されます。
商品の交換はできますか?,未使用品であれば交換可能です。
商品の取り扱い方法を教えてください。,取り扱い方法は商品に同梱された説明書をご覧ください。
商品ページに記載されていない情報はどこで確認できますか?,お問い合わせフォームからお気軽にお問い合わせください。
法人契約の契約条件を教えてください。,契約条件は法人向けページをご覧ください。
評価を行う際のテストシナリオ
テストシナリオとして以下の3つのパターンを検討しました。これらのシナリオを通じて、以下の観点で期待通りの動作が行われているかを評価したいと思います。
- シンプルな単一の参照先が必要となる際に正しい回答ができているか?
- 複数のデータが必要となる際に、正しく参照ができているか?
- 回答に必要な情報が存在していない際にハルシネーションが発生していないか?
実際にテストに利用する質問は以下になります。LLMにアシストしてもらいながら上記の各分類ごとに5問作成しました。
評価に利用する質問一覧
シナリオ,質問,想定回答
単一のFAQデータから回答するべきパターン,営業時間は何時から何時までですか?,当店の営業時間は9:00から18:00までです。
単一のFAQデータから回答するべきパターン,休日はいつですか?,休日は毎週日曜日と祝日です。
単一のFAQデータから回答するべきパターン,商品Aの価格はいくらですか?,商品Aの価格は1,000円です。
単一のFAQデータから回答するべきパターン,商品の返品は可能ですか?,未使用の場合、購入から7日以内であれば返品可能です。
単一のFAQデータから回答するべきパターン,オンライン注文はできますか?,はい、当社のウェブサイトからオンライン注文が可能です。
複数のFAQデータから回答するべきパターン,オンライン注文はできますか?クレジットカードで支払えますか?,はい、当社のウェブサイトからオンライン注文が可能で、主要なクレジットカードがご利用いただけます。
複数のFAQデータから回答するべきパターン,商品Aを購入したいのですが、送料と配送にかかる日数を教えてください。,送料は全国一律500円で、通常発送から2〜3営業日以内にお届けします。
複数のFAQデータから回答するべきパターン,店頭受け取りはできますか?また、支払いを現金で行うことは可能でしょうか?,はい、店頭受け取りも対応しており、現金払いも受け付けております。
複数のFAQデータから回答するべきパターン,商品Aの在庫を電話で確認後、ポイントプログラムを利用して購入できますか?,在庫状況はお電話で確認いただけ、購入ごとにポイントが貯まるプログラムをご用意しています。
複数のFAQデータから回答するべきパターン,修理サービスを依頼したいのですが、配送先の変更も可能でしょうか?,はい、修理サービスをご提供しており、発送前であれば配送先の変更も可能です。
参照データから回答ができないパターン,店舗に駐車場はありますか?,申し訳ございませんが、参照データからは回答が見つかりません。
参照データから回答ができないパターン,定休日でも電話サポートを受けられますか?,申し訳ございませんが、参照データからは回答が見つかりません。
参照データから回答ができないパターン,オンラインショップで他社製品も取り扱ってますか?,申し訳ございませんが、参照データからは回答が見つかりません。
参照データから回答ができないパターン,商品の製造年月日はどこで確認できますか?,申し訳ございませんが、参照データからは回答が見つかりません。
参照データから回答ができないパターン,海外からの注文方法を教えてください。,申し訳ございませんが、参照データからは回答が見つかりません。
評価に利用するシステム構成
構成ごとの制度評価を行いたいため、評価を行う際の構成としては3つのパターンで評価を行います。これらのパターンの中で想定される回答と同等の回答を出力することができる構成はどれかを検証します。
パターン1. KendraのFAQs機能を利用する
KendraにはFAQsという機能がありこの機能を利用すると特定のレイアウトのCSVデータを、行ごとに分割して取り扱いを行ってくれます。そのため、非構造なデータはS3などの特定のデータソースから利用を行い、構造化されているFAQデータはFAQsを利用することが想定されているようです。今回は非構造な文書データは利用しないため、このパターンではFAQsに設定したデータのみを参照し回答することになります。
パターン2. CSVデータをS3にそのまま配置して、データソースとする
RAGの参照先とするCSVデータに対して、前処理を行わずにそのまま利用するパターンです。RAGの構築を行う際にCSVデータを利用する場合はファイルの分割を行うことが基本かと思います。ただ、前処理を行う場合運用コストが高くなることから、そのままのデータをS3に配置した際の精度はどのようになるかを検証してみます。
パターン3. CSVデータに前処理を行ったうえでデータソースとする
S3に配置するCSVデータを行ごとに分割する前処理を行ったうえでデータソースとします。上記にあるRAGの参照データの場合は、ファイル名に質問内容を設定し、コンテンツとして質問と回答内容が記載されるようにします。
前処理を行うために作成したスクリプトは以下です。こちらのスクリプトもLLMに作成してもらいました。技術検証を雑に行うためには、十分な内容ですね。
import csv
import os
import re
def split_csv_to_markdown_files(input_csv_path: str, output_dir_path: str) -> None:
"""
与えられたCSVファイルを読み込み、
行ごとにMarkdownファイルに分割して保存する関数。
Parameters
----------
input_csv_path : str
読み込むCSVファイルへのパス(data-sourceフォルダ以下にあるCSV)
output_dir_path : str
出力先ディレクトリ(data-source-outputフォルダ)
"""
# アウトプット用ディレクトリが存在しない場合は作成
os.makedirs(output_dir_path, exist_ok=True)
with open(input_csv_path, "r", encoding="utf-8-sig") as f:
reader = csv.DictReader(f)
for row in reader:
question = row["Question"].strip()
answer = row["Answer"].strip()
# ファイル名に使用できない文字を置換して安全なファイル名を生成
# (Windowsなど、一部OSで問題になる可能性のある文字列を除去)
safe_filename = re.sub(r'[\\/*?:"<>|]', '_', question)
# Markdownファイルとして保存
output_file_path = os.path.join(output_dir_path, f"{safe_filename}.md")
with open(output_file_path, "w", encoding="utf-8") as outfile:
# コンテンツ内に、質問と回答を記載
outfile.write(f"# {question}\n\n")
outfile.write(f"{answer}\n")
if __name__ == "__main__":
# 例: 実際には必要に応じてファイルパスを変更する
input_csv = "data-source/RAG_CSV_DummyData_data_source.csv" # 読み込み元のCSV (例)
output_dir = "data-source-output" # 出力先フォルダ
split_csv_to_markdown_files(input_csv, output_dir)
print("CSVの分割処理が完了しました。")
実際にテストケースをもとに評価してみる
評価させた結果としては、FAQsを利用したパターンが最も評価が高い結果になりました。
やはりCSVをそのまま利用する場合だと、正答率が下がる傾向にあります。詳しい要因分析までは行っていませんが、おそらくKendraから取得される検索結果にノイズ(不要な情報)が記載されることから精度悪化につながったことが考えられます。
正誤判定サマリー
| 構築パターン | 正答数 | 誤答数 |
|---|---|---|
| 1. FAQsを利用したパターン | 14 / 15 | 1/15 |
| 2. CSVをそのまま利用したパターン | 11/15 | 4/15 |
| 3. CSVに前処理を利用したパターン | 13/15 | 2/15 |
1. FAQsを利用したパターンの誤答
| 質問 | 想定回答 | FAQsを利用したパターンの回答 | 誤答理由 |
|---|---|---|---|
| 商品Aを購入したいのですが、送料と配送にかかる日数を教えてください。 | 送料は全国一律500円で、通常発送から2〜3営業日以内にお届けします。 | 配送にかかる日数については、通常、発送から2〜3営業日以内にお届けします。送料に関する情報は、参考ドキュメントに含まれていないため、回答できません。送料について知りたい場合は、具体的に「商品Aの送料はいくらですか?」というように質問していただくと、より適切な回答ができる可能性があります。 | 送料の情報が提供されていない |
2. CSVをそのまま利用したパターンの誤答
| 質問 | 想定回答 | CSVをそのまま利用したパターンの回答 | 誤答理由 |
|---|---|---|---|
| 商品の返品は可能ですか? | 未使用の場合、購入から7日以内であれば返品可能です。 | 開封済み商品の返品はお受けできません。 | 未使用の場合、返品可能である情報が記載されていない |
| 商品Aの在庫を電話で確認後、ポイントプログラムを利用して購入できますか? | 在庫状況はお電話で確認いただけ、購入ごとにポイントが貯まるプログラムをご用意しています。 | はい、購入ごとにポイントが貯まるプログラムをご用意しています。ただし、商品Aの在庫確認や電話での確認については、参考ドキュメントに情報がないため、お答えできません。具体的な商品名や在庫確認方法についてお尋ねいただくと、より正確な情報をお伝えできる可能性があります。 | 正しくは在庫状況は電話で確認可能であるが、誤った回答が行われている |
| 修理サービスを依頼したいのですが、配送先の変更も可能でしょうか? | はい、修理サービスをご提供しており、発送前であれば配送先の変更も可能です。 | 発送前であれば配送先の変更が可能です。 | 修理サービスについての言及がない |
| 海外からの注文方法を教えてください。 | 申し訳ございませんが、参照データからは回答が見つかりません。 | 現在、海外配送には対応しておりません。 | 対応可否については参照先ドキュメントに記載がないため、「わからない」が正解 |
3. Markdown化したCSVの誤答
| 質問 | 想定回答 | Markdown化したCSVの回答 | 誤答理由 |
|---|---|---|---|
| 商品Aの在庫を電話で確認後、ポイントプログラムを利用して購入できますか? | 在庫状況はお電話で確認いただけ、購入ごとにポイントが貯まるプログラムをご用意しています。 | はい、商品Aの在庫を電話で確認後、ポイントプログラムを利用して購入することができます。在庫状況はウェブサイトまたはお電話でご確認いただけます。また、購入ごとにポイントが貯まるプログラムをご用意しています。このポイントプログラムを利用して商品を購入することが可能です。 | 在庫状況がWebサイトで確認可能であることは情報が提供されていない |
| 海外からの注文方法を教えてください。 | 申し訳ございませんが、参照データからは回答が見つかりません。 | 現在、海外配送には対応しておりません。 | 対応可否については参照先ドキュメントに記載がないため、「わからない」が正解 |
評価結果のまとめ
今回の検証に利用した参照データの場合、KendraのFAQsを利用した場合が最も高い精度となりました。Kendraの各種パラメーターやLLMに対するプロンプトを改善すれば、CSVをデータソースに設定する場合でも精度向上が見込める可能性はありますが、同じパラメータとプロンプトを設定した場合では、FAQs > Markdown化したCSVの回答 > CSVをそのまま利用したパターンの回答 の評価結果となりました。
検証のまとめ
今回の検証のまとめとしては、Kendraを利用する場合、FAQsを利用することでCSVファイルのみをもとに回答させる場合は最も正解率が高い結果となりました。また、CSVファイルをそのまま利用するのではなく、マークダウン形式へ変換することが正答率を高めることに寄与することがわかりました。
実運用を加味すると、非構造データはS3などのデータソースに配置して構造化されたCSVデータを利用する場合はFAQsを活用することで運用コストを減らしRAGの構築ができそうです。
これからRAGを構築する方への参考になれば幸いです。
(参考)開発者向けメモ
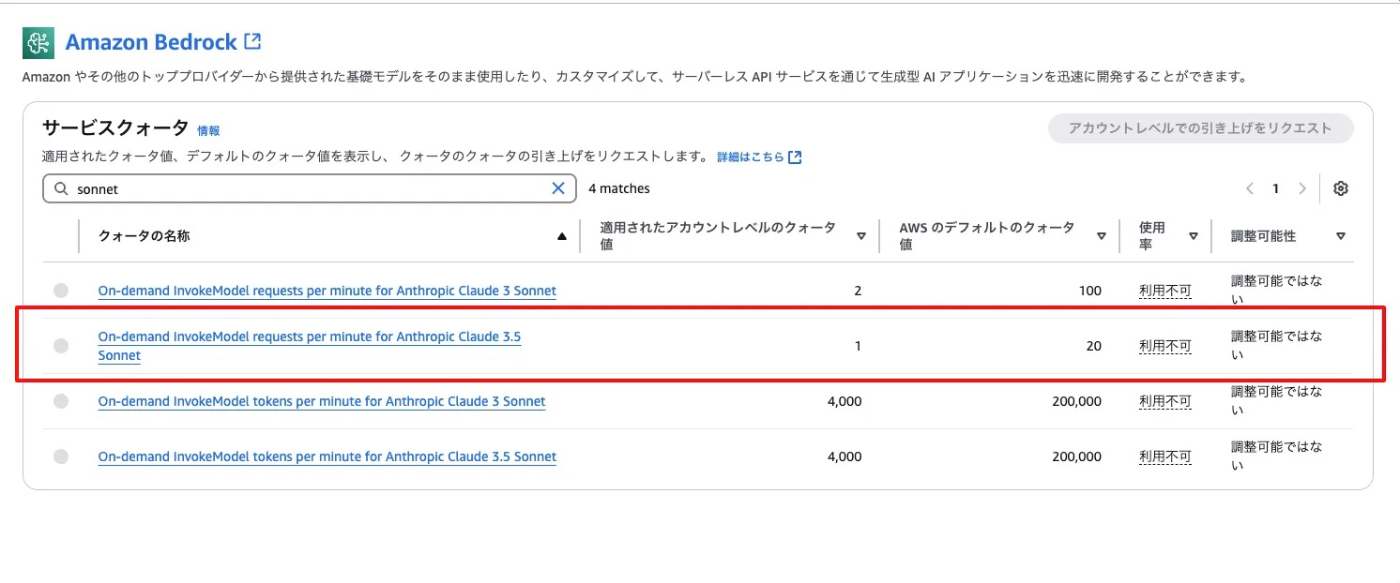
- 今回の検証ではAWSのリージョンは ap-northeast-1 を利用し、LLMはSonnet3.5を利用しましたが、このリージョンではSonnet3.5のレートリミットがかなり厳しく私の環境では、too many requestsのエラーが頻発しました。アカウントレベルによって異なるようですが本運用を検討する際には別のリージョンの採用なども検討の余地があると思います。
- FAQsを利用する場合とS3などのデータソースを利用する場合で、レスポンスに含まれるJSONのスキーマが異なります。そのため、回答生成時にFAQsの情報とデータソースの情報を別扱いできるため、回答生成のプロンプトに埋め込む際に使い勝手がいいと感じました。
- FAQsから取得される情報の場合、FAQのファイル名は含まれずファイルに対して付与されるIDが返却されます。そのため、ファイル名を利用者へのレスポンスに含めたい場合は工夫が必要になる印象です。
(参考)検証に利用したソースコード全文
今回の検証に利用した主な処理を行っているソースコードの全文です。もしお手元で検証される際には参考にしていただけると幸いです。inputフォルダ以下に存在するCSVの1列目を質問として読み取りRAGの回答結果がoutputフォルダに出力されるようになっています。
import csv
import json
import os
import time
import boto3
from dotenv import load_dotenv
load_dotenv()
# 環境変数からKendra・Bedrockの設定を取得
KENDRA_INDEX_ID = os.environ.get("KENDRA_INDEX_ID")
BEDROCK_MODEL_ID = os.environ.get("BEDROCK_MODEL_ID")
# Boto3クライアントの初期化
kendra = boto3.client('kendra', region_name='ap-northeast-1')
bedrock = boto3.client('bedrock-runtime', region_name='ap-northeast-1')
def extract_rag_info(search_results: list) -> list:
"""
検索結果のレスポンス(JSONリスト)から、
Type が 'QUESTION_ANSWER' または 'DOCUMENT' の要素を対象に
下記情報を抽出して返す関数。
【抽出情報】
- 共通:
"Type"(検索結果のタイプ),
"FileName"(DocumentIdをベースにしたファイル名),
"ScoreConfidence"
- Type = "QUESTION_ANSWER" の場合:
"QuestionText", "AnswerText"
- Type = "DOCUMENT" の場合:
"DocumentId", "DocumentTitle", "DocumentExcerpt"
"""
extracted_data = []
for item in search_results:
item_type = item.get("Type")
if item_type not in ["QUESTION_ANSWER", "DOCUMENT"]:
# 指定以外の Type の場合はスキップ
continue
# DocumentId から「ファイル名」を抽出
doc_id = item.get("DocumentId", "")
if "://" in doc_id and "/" in doc_id:
# S3 パスや URL などの場合はパスの末尾をファイル名として扱う
filename = doc_id.split("/")[-1]
else:
filename = doc_id
# ScoreConfidence の抽出
score_confidence = item.get("ScoreAttributes", {}).get("ScoreConfidence", "")
# 返却用の共通データ
data_item = {
"Type": item_type,
"FileName": filename,
"ScoreConfidence": score_confidence
}
# Type = QUESTION_ANSWER の場合は QuestionText, AnswerText を追加
if item_type == "QUESTION_ANSWER":
question_text = ""
answer_text = ""
for attr in item.get("AdditionalAttributes", []):
if attr.get("Key") == "QuestionText":
question_text = attr["Value"]["TextWithHighlightsValue"]["Text"]
elif attr.get("Key") == "AnswerText":
answer_text = attr["Value"]["TextWithHighlightsValue"]["Text"]
data_item["QuestionText"] = question_text
data_item["AnswerText"] = answer_text
# Type = DOCUMENT の場合は DocumentTitle, DocumentExcerpt 等を追加
elif item_type == "DOCUMENT":
doc_title = item.get("DocumentTitle", {}).get("Text", "")
doc_excerpt = item.get("DocumentExcerpt", {}).get("Text", "")
data_item["DocumentId"] = doc_id
data_item["DocumentTitle"] = doc_title
data_item["DocumentExcerpt"] = doc_excerpt
extracted_data.append(data_item)
return extracted_data
def process_query(user_query: str) -> str:
"""
1. Kendraでクエリを投げて関連ドキュメントを取得
2. 取得したドキュメントをコンテキストとしてBedrockに投げ、回答を生成
3. 回答文字列を返す
"""
# --- Kendraでドキュメント検索 ---
try:
response = kendra.query(
QueryText=user_query,
IndexId=KENDRA_INDEX_ID,
PageSize=10,
AttributeFilter={
# 日本語で質問するためのフィルタ(_language_code == 'ja')
'EqualsTo': {
'Key': '_language_code',
'Value': {
'StringValue': 'ja'
}
}
}
)
except Exception as e:
return f"ドキュメント検索中にエラーが発生しました: {str(e)}"
document = []
extracted_rag_info = extract_rag_info(response.get('ResultItems', []))
extracted_rag_info_text = json.dumps(extracted_rag_info, ensure_ascii=False)
# --- Bedrockで回答生成 ---
try:
# BedrockへのリクエストボディをJSON文字列化
bedrock_payload = json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 500,
"system": "あなたは最高のアシスタントとして、ユーザーの質問に答えてください。",
"temperature": 0.0,
"messages": [
{
"role": "user",
"content": f"""
あなたはユーザの質問に答えるAIアシスタントです。
以下の手順でユーザの質問に答えてください。手順以外のことは絶対にしないでください。
<回答手順>
* <参考ドキュメント></参考ドキュメント>に回答の参考となるドキュメントを設定しているので、それを全て理解してください。
* <回答のルール></回答のルール>を理解してください。このルールは絶対に守ってください。ルール以外のことは一切してはいけません。例外は一切ありません。
* チャットでユーザから質問が入力されるので、あなたは<参考ドキュメント></参考ドキュメント>の内容をもとに<回答のルール></回答のルール>に従って回答を行なってください。
</回答手順>
<参考ドキュメント>
{extracted_rag_info_text}
</参考ドキュメント>
<回答のルール>
* 雑談や挨拶には応じないでください。「私は雑談はできません。通常のチャット機能をご利用ください。」とだけ出力してください。他の文言は一切出力しないでください。例外はありません。
* 必ず<参考ドキュメント></参考ドキュメント>をもとに回答してください。<参考ドキュメント></参考ドキュメント>から読み取れないことは、絶対に回答しないでください。
* <参考ドキュメント></参考ドキュメント>をもとに回答できない場合は、「回答に必要な情報が見つかりませんでした。」とだけ出力してください。例外はありません。
* 質問に具体性がなく回答できない場合は、質問の仕方をアドバイスしてください。
* 回答文以外の文字列は一切出力しないでください。回答はJSON形式ではなく、テキストで出力してください。見出しやタイトル等も必要ありません。
</回答のルール>
<ユーザーからの質問>
{user_query}
</ユーザーからの質問>
"""
}
]
})
bedrock_response = bedrock.invoke_model(
body=bedrock_payload,
modelId=BEDROCK_MODEL_ID,
accept='application/json',
contentType='application/json'
)
# Bedrockレスポンスのボディを読み込む
response_body = json.loads(bedrock_response['body'].read())
generated_answer = response_body['content'][0]['text']
return generated_answer
except Exception as e:
return f"回答生成中にエラーが発生しました: {str(e)}"
def main():
"""
input.csv のA列にある質問を順に処理し、
生成された回答を含む output.csv を出力する
"""
input_csv = "input/input.csv"
output_csv = "output/output_faq_data_source.csv"
with open(input_csv, mode="r", encoding="utf-8", newline="") as fin, \
open(output_csv, mode="w", encoding="utf-8", newline="") as fout:
reader = csv.reader(fin)
writer = csv.writer(fout)
# ヘッダを書き込む(必要に応じて列名を変更してください)
writer.writerow(["Question", "Answer"])
for row in reader:
if not row:
continue # 空行などスキップ
question = row[0] # A列を質問とみなす
answer = process_query(question)
writer.writerow([question, answer])
print(f"回答: {answer}")
# レートリミット対策
time.sleep(70)
if __name__ == "__main__":
main()

Discussion