はじめに
昨今IT業界では生成AIを活用した問題解決が盛り上がってきていますよね!
その中でRAG(Retrieval-Augumented Generation)という手法をご存知でしょうか?
ChatGPTをはじめとする通常のLLM(Large Language Models)ではWeb上に公開されている、学習に利用されているデータからしか回答ができません。生成AIを企業で活用する際には、社内データに回答可能なチャットボットを構築したいというモチベーションが高く、その際にはRAGという技術が利用されます。
今回そのようなRAGをAWSのKendra,Bedrockなどのサービスを用いて構築し、特定分野に特化したカスタマーチャットボットを構築したのでその方法について詳しく記載いたします。
想定する読者
- RAGに関して、聞いたことはあるが実施に構築したことのない方
- 通常のAPIでのLLMの利用だけでなく、他の利用方法を身に付けたい方
- RAGを利用して何か実用的なシステムを構築してみたい方
この記事での到達目標
- RAGを用いて独自に用意したデータに基づいた回答をするSlackのチャットボットの作成
構成
本システムは以下の主要なコンポーネントで構成されています:
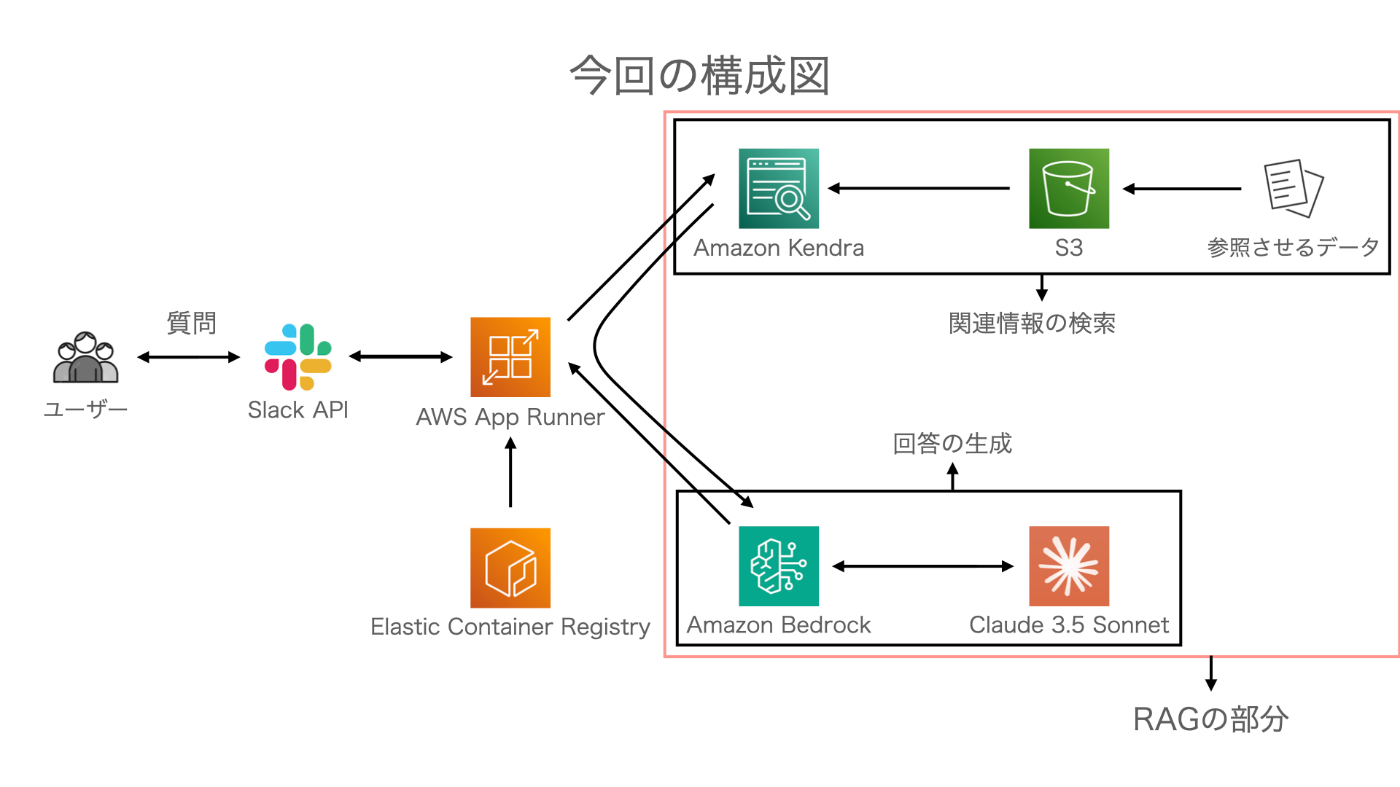
- Slack App:ユーザインタフェースとして機能し、ユーザーからの質問を受け取り、プログラムで作成した内容に基づき回答します。Slack Appにメンションされたことをトリガーとして後述するApp Runnnerのエンドポイントにリクエストを送るシステムとしています。
- AWS App Runner:アプリケーションのホスティングとスケーリングを担当します。今回はPyhonで書いたプログラムをDockerにて作成したコンテナをECRに保存、デプロイしております。
- AWS S3(Simple Storage Service):LLMに学習させるデータの保存する場所です。今回はダミーとしてChatGPTにDummyPCという架空のPCのマニュアルを作成してもらいPDF化、アップロードしております。
- Amazon Kendra:ドキュメント検索エンジンとして機能し、用意したデータから回答に必要な情報を取得します。S3からデータを取得しその情報を元にインデックスを作成。情報が要求された時に最適な回答や関連ドキュメントを提供することができます。
- Amazon Bedrock:kendraから抽出されたデータを元にLLMを利用し、ユーザーに渡す回答を生成します。今回はAnthropicのClaude 3.5 Sonnet v2というモデルを使用しました。
- AWS ECR(Elastic Container Registry):コンテナイメージを保存・管理・配信するためのコンテナレジストリサービスです。今回用意したコードをDockerにてコンテナ化、ECRにpushすることでApp Runnerと結びつけております。
Slack Appの作成と設定
Slack APIにアクセスし、任意名前のAppを作成していきます。
OAuth&Permissionsにてapp_mentions:readやchat:writeなどの権限を付与しておきます。

また、ここで作成されるBot User OAuth TokenとSigning Secretに関しては後ほどプログラムで使用するので控えておくと便利です。
AWS App Runnerの設定
今回はPythonのFastAPIというフレームワークを用いて構築しました。
内容としてはSlack Appにメンションされた質問を受け取り、Kendraにて関連する情報を検索。また、BedrockにてKendraで検索された情報を元に回答文を作成し、再度Slack Appに回答の情報を渡す処理をしています。
RAGは、Retrieval-Augmented Generationの略であり、詳しい意味は
- Retrieval(検索): ユーザーの質問に関連する情報を、外部のデータベースやドキュメントから検索するフェーズ。
- Augmented(拡張): 検索された情報を基に、モデルの回答生成を「拡張」すること。
- Generation(生成): 最終的に、大規模言語モデル(LLM)によって回答を生成するフェーズ。
特に今回では、質問から関連するデータをKendraにて検索し(Retrieval)、その情報を元に(Augumented)、Bedrockにて回答を生成する(Generation)一連の流れがRAGに該当する部分です。
Pythonコード全文
import os
from fastapi import FastAPI, Request
from slack_bolt import App
from slack_bolt.adapter.fastapi import SlackRequestHandler
import boto3
import json
import re
# 環境変数からSlackトークンと署名シークレットを取得
SLACK_BOT_TOKEN = os.environ.get("SLACK_BOT_TOKEN")
SLACK_SIGNING_SECRET = os.environ.get("SLACK_SIGNING_SECRET")
KENDRA_INDEX_ID = os.environ.get("KENDRA_INDEX_ID")
BEDROCK_MODEL_ID = os.environ.get("BEDROCK_MODEL_ID")
# それぞれクライアントの設定
slack_app = App(token=SLACK_BOT_TOKEN, signing_secret=SLACK_SIGNING_SECRET)
handler = SlackRequestHandler(slack_app)
kendra = boto3.client('kendra', region_name='us-east-1')
bedrock = boto3.client('bedrock-runtime', region_name='us-east-1')
app = FastAPI()
# ヘルスチェック用のエンドポイント
@app.get("/")
def health_check():
return {"status": "ok"}
# ユーザーからのメンションに対応する処理を設定するエンドポイント
@slack_app.event("app_mention")
def handle_mention(event, say):
user_query = event['text']
user_query = re.sub(r"<@[^>]+>", "", user_query).strip()
# Kendraでドキュメント検索
try:
response = kendra.query(
QueryText=user_query,
IndexId=KENDRA_INDEX_ID,
PageSize=10,
AttributeFilter={
# 日本語で質問するための言語設定
'EqualsTo': {
'Key': '_language_code',
'Value': {
'StringValue': 'ja'
}
}
}
)
except Exception as e:
say(f"ドキュメント検索中にエラーが発生しました: {str(e)}")
return
documents = []
for doc in response.get('ResultItems', []):
if doc['Type'] == 'DOCUMENT':
title = doc.get('DocumentTitle', {}).get('Text', 'タイトル不明')
excerpt = doc['DocumentExcerpt']['Text']
uri = doc.get('DocumentURI', 'URI不明')
documents.append(f"タイトル: {title}\nURI: {uri}\n抜粋:\n{excerpt}")
context = "\n".join(documents)
if not context:
say("関連する情報が見つかりませんでした。")
return
# Bedrockで回答生成
try:
bedrock_response = bedrock.invoke_model(
body = json.dumps(
{
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 500,
"system": "あなたはカスタマーチャットボットです。",
"messages": [
{
"role": "user",
"content": f"ユーザの質問に追加情報情報を参照して答えてください。また文末では参照したファイル名を記述してください。質問:{user_query},追加情報:{context}"
}
]
}
),
modelId=BEDROCK_MODEL_ID,
accept='application/json',
contentType='application/json'
)
response_body = json.loads(bedrock_response['body'].read())
generated_answer = response_body['content'][0]['text']
except Exception as e:
say(f"回答生成中にエラーが発生しました: {str(e)}")
return
say(generated_answer)
# Slackからイベントを受信し処理するエンドポイント
@app.post("/slack/events")
async def slack_events(request: Request):
return await handler.handle(request)
簡単な解説
- リージョンに関しては、今回us-east-1を使用しました。Kendraやその他今回使用するサービスに対応しているリージョンを選択してください。
- Kendraのクエリパラメータで言語設定を忘れないでください。デフォルトではen(英語)に設定されているため、情報処理を行うことができません。
- また、デプロイが完了しURLが設定された後、SlackのEvent Subscriptionsにてエンドポイントの設定をします
- 今回に関してはDockerにてコンテナ化、ECR経由でApp Runnerに結びつけています
データソースの準備(AWS S3)
Kendraにて検索するデータを保存するために、AWS S3バケットを作成します。
今回はPDFのデータを用いましたが、マークダウン、csvなどそのほかのデータ形式にも対応しており、それぞれKendraから検索する際に検索精度が変化します。
今回は以下のようなプロンプトをChatGPTに入力し、ダミーデータを作成してもらいました
架空のPCのマニュアルを作成してください
名前はdummy PCです。
Notionにそのまま貼り付けるので添付しやすいように整形してください
作成されたデータ
# Dummy PC マニュアル
## 目次
1. **製品概要**
2. **セットアップ手順**
3. **基本操作**
4. **トラブルシューティング**
5. **サポート情報**
---
## 1. 製品概要
**Dummy PC**は、日常の作業やエンターテイメントを快適にサポートする高性能なPCです。以下は主な特徴です:
- **CPU**: Quad-core DummyChip 3.5GHz
- **メモリ**: 16GB DDR4
- **ストレージ**: 512GB SSD
- **ディスプレイ**: フルHD 15.6インチ
- **OS**: DummyOS 1.0
> 注意: 詳細な技術仕様については、製品同梱の技術仕様書をご参照ください。
>
---
## 2. セットアップ手順
### 2.1 内容物の確認
1. Dummy PC本体
2. ACアダプターと電源コード
3. ユーザーマニュアル
### 2.2 初期設定
1. **電源を接続**:
ACアダプターをPCに接続し、電源に差し込みます。
2. **電源を入れる**:
PCの右上にある電源ボタンを押して起動します。
3. **OSのセットアップ**:
初回起動時に表示されるガイドに従って、以下を設定します:
- 言語と地域
- Wi-Fi接続
- アカウント情報
4. **アップデートの確認**:
[設定] → [更新とセキュリティ]からシステムアップデートを確認してください。
---
## 3. 基本操作
### 3.1 電源管理
- **スリープモード**: スタートメニューから「スリープ」を選択。
- **シャットダウン**: スタートメニュー → 「電源」 → 「シャットダウン」を選択。
### 3.2 ファイル操作
- **新しいファイルを作成**:
1. デスクトップまたはフォルダーを右クリック。
2. 「新規作成」を選択し、必要なファイルタイプを選びます。
- **ファイルの削除**:ファイルを右クリックして「削除」を選択します。
### 3.3 インターネットブラウジング
1. スタートメニューから「Dummy Browser」を起動します。
2. アドレスバーにURLを入力し、「Enter」キーを押します。
---
## 4. トラブルシューティング
### 4.1 起動しない場合
1. **電源コードの確認**: ACアダプターが正しく接続されているか確認します。
2. **バッテリーの状態**: バッテリー残量があるか確認してください。
### 4.2 Wi-Fiに接続できない場合
1. **Wi-Fiスイッチの確認**: デバイス右側のWi-Fiスイッチがオンになっているか確認します。
2. **再起動**: PCとルーターを再起動してみてください。
### 4.3 サポートへの連絡が必要な場合
- Dummy PCサポートセンター: **0123-456-789**
- 営業時間: 平日 9:00~18:00
---
## 5. サポート情報
公式サイト: [www.dummypc.com](http://www.dummypc.com/)
FAQページ: www.dummypc.com/faq
ソフトウェアアップデート: www.dummypc.com/update
---
**注意**: このマニュアルは定期的に更新される可能性があります。最新版は公式サイトでご確認ください。
作成したデータをPDF化し、S3にアップロードします。

また、Kendraからアクセスできるように適切なIAMロールとポリシーを設定します。
ドキュメント検索の設定(Amazon Kendra)
AWSコンソールサイトからKendraにアクセスし、インデックスを作成していきます
今回はインデックスの名前と、ロール、Editionsの選択以外は変更せずに作成していきました。

データソースとしては先ほど設定したS3のバケットを選択します。この際に、言語設定をja(日本語)にすることを忘れないでください。デフォルトのen(英語)を使用してしまうと情報検索がうまくできなくなってしまいます。
Sync Nowのボタンを押すことによってデータをクロールし、情報検索しやすい形に整形されたドキュメントを作成します。
また、ここで表示されるindexIDに関しては後ほど環境変数に設定します。
回答生成の設定(Amazon Bedrock)
Amazon Bedrockのサービスにアクセスし、利用可能なモデルID(今回モデルはClaude 3.5 Sonnet v2を使用しました)を確認し、環境変数BEDROCK_MODEL_IDに設定
また、App Runner経由で使用できるようにIAMロールの作成・付与します。
使用準備
App Runnerにて環境変数であるSLACK_BOT_TOKEN、SLACK_SIGNING_SECRET、KENDRA_INDEX_ID、BEDROCK_MODEL_IDにそれぞれSlack AppやAWSコンソール画面から取得した内容を入れていきます。
特に秘匿情報が多いためAWS Secret Manegerなどで設定することをおすすめします。
また、Slack APIサイトにてEvent SubscriptionsにてAWS App RunnerのエンドポイントURLを入力し、Subscribe to Bot Eventsセクションにてapp_mentionイベントを追加します。(これによりメンションされたことを起点にプログラムが走るようになります)

最後に、用意したSlackのワークスペースにInstallします。
結果
Slackから、作成したアプリに「DummyPCの製品概要を教えてください」と聞くと以下のような回答を得ることができました。

今回用意したDummyPCに関しての情報、どのファイルを参照しているかまで含めて回答していることが確認できました。
また、念の為ChatGPTにて同じような質問をすると全く違うことを回答しているので、今回用意したデータを参照して回答していることがわかると思います。

また、別の質問として「DummyPCが起動しない場合どうすればいいですか?」と聞いてみました。

用意したデータから対処方法と、それでも解決しない場合の連絡先まで回答していることが確認できました。
まとめ
AWSのサービスを活用すれば、RAGを簡単に構築し、実際に特定分野に特化したカスタマーチャットボットを実現できます。本記事では、Slack、AWS App Runner、S3、Kendra、Bedrockを組み合わせたシステムの構築方法を詳細に解説しました。
RAGの手法を用いることで、従来のLLMを補完し、特定のデータセットに基づいた高精度な回答を提供することが可能になります。これにより、企業は顧客対応や内部サポートの効率化を図ることができるのではないでしょうか。
参考情報
今回の構成で構築するに当たって山本さんの記事を参考にさせていただきました。
いつもRAG関連のキャッチアップとして参考にさせていただいております!

Discussion