はじめに
この記事について
こんにちは、zomysan(ぞみ) です。今回は私の所属するソーシャルPLUSのフロントエンドチームがどのようなことを考えてテストを作っているのかを紹介します。
フロントエンドのテスト手法については素晴らしい本や記事がすでにたくさん存在しますが、限られたリソースの中で、実務としてどうテストをこなしているのか、という具体的な事例として楽しんでいただければ幸いです。
テスト運用における課題や改善点も率直に紹介しますので、「うちではこうやって解決しているよ」といったご意見があればぜひコメント欄で教えてください!
対象読者
- フロントエンドのテスト運用に悩んでいる方
- フロントエンドのテストってどういうものなのか興味がある方
- ソーシャルPLUSに入社したフロントエンドメンバー
この記事に書いていないこと
- すべてのチームにとっての最適解は提示していません
- 弊チームにとっても折り合いをつけて妥協しているものも含みます
- ツールのインストール手順、網羅的な設定内容などは紹介していません
チームについて
テストの方針はプロジェクトやチームの規模感や性質によって大きく変わるものなので、まずは弊社のそれらについてさらっと紹介します。まずはチームについて。
弊社の開発チームはバックエンド・フロントエンド・インフラ・デザインの4職種に分かれて開発をしています。QA専任のチームはありません。職種は分かれていますが、フロントエンドがバックエンドのAPI設計をレビューしたり、画面の仕様についてデザイナーと相談したりすることはありますので、チームとして分断されてはいません。
フロントエンドチームは現在5人(業務委託メンバー含む)で、業務委託・正社員でやることに大きな差はありません。全員が設計・実装・レビュー・テスト・リリースをします。
プロジェクトについて
ここでは作っているものの種類や規模感について簡単に紹介します。
フロントエンドチームが主に作っているのは3つのウェブアプリケーションで、すべてReactのSPAです。Next.js(Page router)やWebpackなど、そのプロジェクトが発足した当時にそれぞれ選定された技術スタックで構成されていますが、よい選択肢が出てきたらその都度乗り換え・更新を行なっています。内部パッケージの利用やライブラリの管理などを簡単にするため、すべてのアプリケーションを Yarn Workspaces + Turborepo によりモノレポで管理しています。
すべてBtoBのアプリであるため、操作するのは企業の担当者さん、または弊社のCSなどで、エンドユーザーが操作することはありません。アクセス負荷・レスポンス速度についての要件はそこまで厳しくありません。
余談ですが、エンドユーザーのリクエストや大量のジョブを受け止めるバックエンドサーバーではシビアな負荷対策や監視を行っています。よかったらそれについて色々な記事がありますので、興味のある方はぜひ読んでみてください。
こちらの記事では、外部のAPIに依存するサービスを提供するうえでは避けられないAPI Rate Limitにどのように対応するかについて触れています。
またこちらの記事では、大量のデータをDBから取り出してファイルに書き出すとき、意図しないメモリの過剰消費を起こさないための具体的な実装を紹介しています。
テストの全体像
前置きが長くなりましたが、いよいよテストの方針について話していきます。繰り返しになりますが、あくまで現状の弊社がそうであるという紹介なので、ここで紹介することが誰にとってもベストなわけではありません。
どんなテストをやっているのか?
弊チームで実施しているテストは以下のとおりです。
- 静的解析(Static)
- 対象:型の整合性、コードの品質
- 結合テスト(Integration)
- 対象:コンポーネント、ページコンポーネントの機能
- ユニットテスト(Unit)
- 対象:関数
- E2Eテスト(End to End)
- 対象:重要なシステムの主な操作
Testing Trophy には存在しないテストとして、コンポーネントカタログの作成、VRTも行っています。
- コンポーネントカタログを利用した Visual Regression Test
- 対象:コンポーネントの詳細な状態
チームで最も重視しており、数・量ともに多いのは結合テストです。理由は一般的に結合テストが選択される理由と同じようなものですが、のちに詳しく紹介します。
それぞれのテストについての詳細も後ほど紹介しますが、まずは何を考えてテストをしているかについて書きます。
テストの目的
弊チームは、大きく2つの目的でフロントエンドのテストを用意しています。1つ目は作った機能の動作が正しいことを確認するため、2つ目は将来的に機能が壊れた際、迅速に問題を発見するためです。これらが満たされることを目標にテストを作っています。
基本方針
網羅性
基本的には、全ての実装に対してなんらかのテストをしましょう、という方針です。「なんらかの」とある通り、なんらかのテストで動作が正しいことを担保できていればそれでOKです。
例えば、コンポーネント a, b, c から成るコンポーネント A があるとします。コンポーネント A のテストをした結果、コンポーネント a, b, c についても十分に検証されるようであれば、それ以上追加のテストは必要ないので、コンポーネント a, b, c のテストを用意しないこともあります。逆に、コンポーネント a, b, c が十分に検証されていれば、それらを組み合わせただけのコンポーネントAについては簡単なテストだけ用意すれば十分です。
上記ではコンポーネントの親子関係における網羅について話しましたが、テストの種別にも同じことがいえます。たとえば、コンポーネントのローディング表示についてStorybookによるカタログやVisual Regression Test(いずれも後述します)で検証されているのであれば、それについての結合テストは必要ありません。また、単体テストで関数単位の検証が十分に行われているなら、同じようなテストケースについて結合テストで再現する必要もありません。
コード単位のカバレッジの計測はしていません(1度テスト全体でどれくらいカバーできているか計測してみたい気持ちはあります)。テストが十分に行われているかどうかはレビュー時に開発メンバーによって担保されます。レビュー漏れによるテスト不足のほか、テスト方針は都度改善されていいるため、とくに昔実装された機能にはテストが不足しているものもあります。気づき次第、無理なくメンテナンスしていきます。
自動化
テストは できるかぎり自動化する(CIで回せるテストにする) 方針です。手動のテストは形骸化・ヒューマンエラーのおそれがあり、リソースも必要で、開発者の頭に負担をかけます。自動化は最初こそ大変ですが、最初に適切なテストコードを書いてしまえばその後の運用は楽に行えるので、結果的に効率的です。
フロントエンドのテストを自動化するためのしくみやツールは多数用意されているので、弊チームでもそれらを使って楽をしています。(具体的な内容は後ほど紹介します)
どうテストを実装するか
ここでは、テストを実装するにあたっての方針をざっくり書いていきます。
テストは先でも後でもOK
自動テストというとテストファースト(先にテストを書いて、そのテストが通るように実装していく)のイメージがありますが、必ずしもそのやり方で進めなくても問題ありません。
もちろんテストファーストで実装しても問題ありません。とくにStory(後述するコンポーネントカタログ・Storybookの1つのパターン)を先に書いておけば、動作確認がしやすくなります。
Pull Request は必要なテストをそろえてからレビューに出す
Pull Request(PR)を出すときにはできる限り必要なテストを一緒に書きます。これには2つのメリットがあります。
まず、テストを書く過程で(テストが落ちるまでもなく)不具合や実装漏れを発見できます。テストを用意するときは、実装中よりも機能について網羅的に検証する考え方がより強くなります。これによって、テストを作る過程で見逃していたパターンに気付けます。
次に、レビュワーの負担が軽減されるためです。テストが通っており、そのテストケースも十分であれば、とりあえず正しく動いていることは保証できているPRとなります。そうなれば、実装が要件を満たしているかというチェックは一旦スキップして、実装のやり方に目を向けることができます。
テストの実装コストと恩恵のトレードオフを意識する
モックしづらい外部への依存を含むコンポーネントのテストなど、自動化しづらいテストというのはどうしても存在します。このようなときは、実装にかかるコストと、受ける恩恵のバランスを見て実装するか判断します。
「テストの目的」でも書いた通り、「ちゃんと動くことの確認」「壊れたときにすぐに気づける」がテストの目的です。「ちゃんと動くことの確認」は機能開発中にあれこれ手元で動作確認しているはずなので、自動化していなくても達成されます。いっぽうで、「壊れたときにすぐに気づける」は違います。作ってしまえばその機能を積極的に触る人はチーム内にいなくなるので、何かがあって壊れたときにも気づけません。
つまり、実装しづらいテストに出会したときは、「いつの間にか壊れていた」のリスク評価(発生しうるのか、発生したらどれくらいのインパクトがあるのか。etc)と、テスト実装コストを天秤にかけて判断します。実際に弊チームでも「ここは自動化しない」と判断しているテストも多々あります。
コードの品質はテストで保証したいですがプロダクトを前に進めることも重要なので、トレードオフを意識して判断する必要があります。
テストコードは愚直に書く
テストを実装するときは、抽象化や再利用を考えずに、素直にテストしたいことをそのまま書きましょう。具体的には、モックデータを作るのにループやif文などのロジックを使ったり、入力とアサーションに使う値を共通の変数から取り出したりすることを避けるべきです。その結果テストコードが冗長になったとしても全く問題ありません。
テストコードにロジックを入れてしまうと、そのテストが正しいことを担保するためのテストが必要になります(以下繰り返し)。テストコードに最も大切なのは、簡潔・スマートに実装されていることではなく、なにをテストしているか一目でわかることです。
ただし、テスト手順やテストデータが冗長になった場合、その意図をテストのケース名やコメントで伝えることは重要です。ボタンを何度も連打しているようなテストコードだとなにをしているのかわかりませんが、「追加ボタンをN回押すとdisabledになる」のようなテストケース名がついていればわかりやすいですよね。
それぞれのテストについて具体的に紹介
ここからは、それぞれのテストについてどのように実施しているか、使っているツールやライブラリなどについてもまじえて紹介していきます。
静的解析
弊チームでは静的解析として以下を実施しています。CIでもこれらをチェックし、通っていることがマージ条件となっています。
- ESLint による静的解析
- Prettier によるフォーマット解析
- TypeScript の型チェック
また、型チェックに関連して、APIリクエストについても型付けを実施しています。また、望ましくない実装が増えないよう、ESLintルールやアノテーションを使って警告を出しています。
それぞれについて詳細に見ていきます。
ESLintによる静的解析
ESLint による静的解析を活用しています。ルールはモノレポの内部に定義したパッケージとして共通化し、3つの主要なアプリケーションで一貫したルールをベースにしています。
ESLintのルールは定番のルールをextendしています。
...
extends: [
'airbnb',
'eslint:recommended',
'plugin:@typescript-eslint/recommended',
'plugin:import/typescript',
'plugin:functional/recommended',
'plugin:react/recommended',
'prettier',
],
...
これらに加え、いくつか独自のルールも設定しています。これについては困りごともあり、のちほど「課題と展望」で紹介します。
Prettier によるフォーマットチェック
リポジトリで共通の prettierrc.js を定義し、コードのフォーマットチェックと、開発中の自動修正を行なっています。
module.exports = {
singleQuote: true,
trailingComma: 'all',
bracketSameLine: true,
};
VSCode を使う場合、Prettier の Extensionがおすすめです。フォーマット自動修正があることで、コードスタイルに気を使わず実装の内容に集中できます。
開発中の自動修正に加え、CIによるマージ前チェックも行っているため、メインブランチにチェックインされるコードはすべて規定通りのフォーマットに保たれます。
TypeScript の型チェック
tsconfig.json に strict フラグを設定し、型について厳密にチェックしています。
{
...
"compilerOptions": {
"strict": true,
...
}
}
strict フラグを true にすると、型チェックにまつわる色々なルールがまとめて有効になります。TypeScriptの型システムによる恩恵を受けるため、true にしておくのがおすすめです。
strictフラグは、プログラムの正しさを強く保証するための幅広い型チェックの挙動を有効化します。 このオプションの有効化は、以降で述べるすべてのstrict モードファミリーオプションの有効化と等価です。 必要に応じて、個別の strict モードファミリーを無効化できます。
APIリクエストに型付けする
REST API であるバックエンドへのリクエストおよびそのレスポンスに型付けをしていると、リクエスト・レスポンスのtypoや誤記、取り違えがなくなります。これを実現するために、OpenAPI と aspida を利用しています。
OpenAPIスキーマの定義は、プロダクトによりますがバックエンド・フロントエンド両方が行います。aspida はOpenAPI のスキーマからHTTPクライアントを生成できるライブラリです。生成されたクライアントを使うことで、エンドポイントが型補完され、リクエスト・レスポンスの型もそれに連動して付くようになります。
APIドキュメントどおりのレスポンスを返すことはバックエンド側のテスト・レビューによって担保されており、APIドキュメントから正しくスキーマが起こされていることはスキーマ作成時のレビューなどによって担保されているので、ランタイムで型通りのレスポンスが来ることは前提として実装し、チェックはしていません。
ここでは社内の REST API とのやりとりについて書きましたが、一部のアプリは外部サービスの GraphQL サーバーとやりとりをします。そちらは graphql-codegen で型付けしています。
静的解析で実装を縛る
この項はちょっと具体的な話になります。使って欲しくないコンポーネントや関数を使ったら警告が出るようにしておくと、コーディングルールやコメントに頼らずに実装を縛ることができます。(もちろんなぜ使って欲しくないかを併記する必要はありますが)
no-restricted-imports ルールを使うと、使ってほしくない何かを import したときに ESLint で警告を出せます。たとえば、外部ライブラリの Table を拡張した独自の Table コンポーネントを定義しており、基本的には独自の Table を使ってほしいとき、外部ライブラリの Table を import したら警告を出すよう設定する、といったことができます。
module.exports = {
root: true,
...
rules: {
'@typescript-eslint/no-restricted-imports': [
'error',
{
name: 'ui-lib-name',
importNames: ['Table'],
message: "共通コンポーネントの 'src/components/Table' を使ってください。",
},
]
]
}
TypeScript の @deprecated アノテーションも便利です。まだ使っているところが多いから廃止はできないけど、新しい実装では使って欲しくない関数やプロパティに設定しておくとよいでしょう。
以下で実際の動きを確認できます。
結合テスト
結合テストの目的
結合テストの目的は、コンポーネントやページが正しく機能するかを確認することです。ユーザー操作やバックエンドから受け取ったデータに対して、画面のフィードバックやバックエンドへのリクエストが期待通りに動作しているかをチェックします。
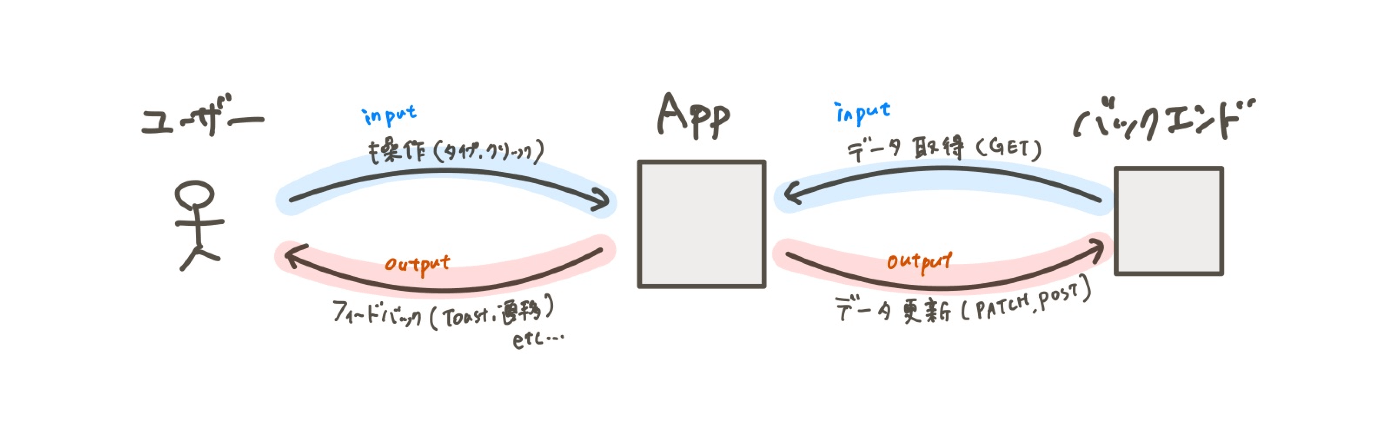
これは実際にアプリケーションが使われるときと同じインプット・アウトプットであり、結合テストは内部の実装などの影響を受けにくく、本質的に確認したいことを確かめることができるテストといえます。なので、弊チームでは結合テストを重視しています。
E2Eテストでも同様の確認はできますが、E2Eテストには統合テストにはないメリットがあるいっぽうで、動作の重さやバックエンドやインフラの整備のコスト、フロントエンドに起因しない不具合で落ちる(これは全体を通して確認できるという意味でメリットでもありますが)などのデメリットもあります。これらを総合して考えて、結合テストを重視しています。
使っているライブラリ・ツール
テストランナーは現在 Jest を利用していますが、一部プロジェクトでは Vitest をお試しで導入中です。
ユーザーの操作を再現し、画面上へのフィードバックを確認するにあたっては、React Testing Library を使います。また、バックエンドサーバーのモックは Mock Service Worker で実装します。
また、モックの実装には mswpida というライブラリを利用しています。このライブラリを使うと、MSWのハンドラーをOpenAPIスキーマに沿って型付けされた状態で書くことができます。リクエスト・レスポンスやエンドポイントURLに誤りがあると型エラーで気づくことができるので、テストを書く上で非常に便利です。OpenAPIを採用しているチームにはぜひ一度触ってみてほしいライブラリです。
ちなみに、このライブラリはフロントエンドチームリーダーが作ってくれました!紹介記事もありますので、ぜひごらんください。
単体テスト
単体テストの目的
単体テストの目的は、結合テストで扱いにくい細かいロジックや動作を保証することです。細かい計算やデータ形式の変換、画面に表示する文言のフォーマットなど、ややこしい仕事を切り出した関数を単体テストで検証します。
結合テストで多くのパターンを網羅しようと思うと、ユーザー操作の記述やモックの定義をパターンごとに行うこととなり、テストの実装コストがかさみ、実行にも時間がかかります。こうした場合にはテストケースの抜け漏れを防ぎつつ見通しを良くするためにテーブルテストを用います。見通しがよいだけでなく、一般的に単体テストは結合テストより短い時間で終わるので、テスト実行時間の短縮にもつながります。
使っているツール・ライブラリ
テストのプラットフォームは結合テストと共通です。結合テストと単体テストの区別はつけていません。
繰り返しにはなりますが、テストランナーは Jest、モックには Mock Service Worker および mswpidaを使っています。日付を固定するためにMockDateを使っているテストもあります。
コンポーネントカタログ(Storybook)
コンポーネントカタログとして、Storybook を利用しています。
コンポーネントカタログの必要性
コンポーネントカタログを利用することで、ページやコンポーネントのとりうる状態を、アプリケーションを操作することなく一望できるようになります。たとえば、あるコンポーネントが以下のような状態を持つとします。
- ローディング中
- データをフェッチしたが、データが空だったとき
- データをフェッチして、それをテーブルに表示しているとき
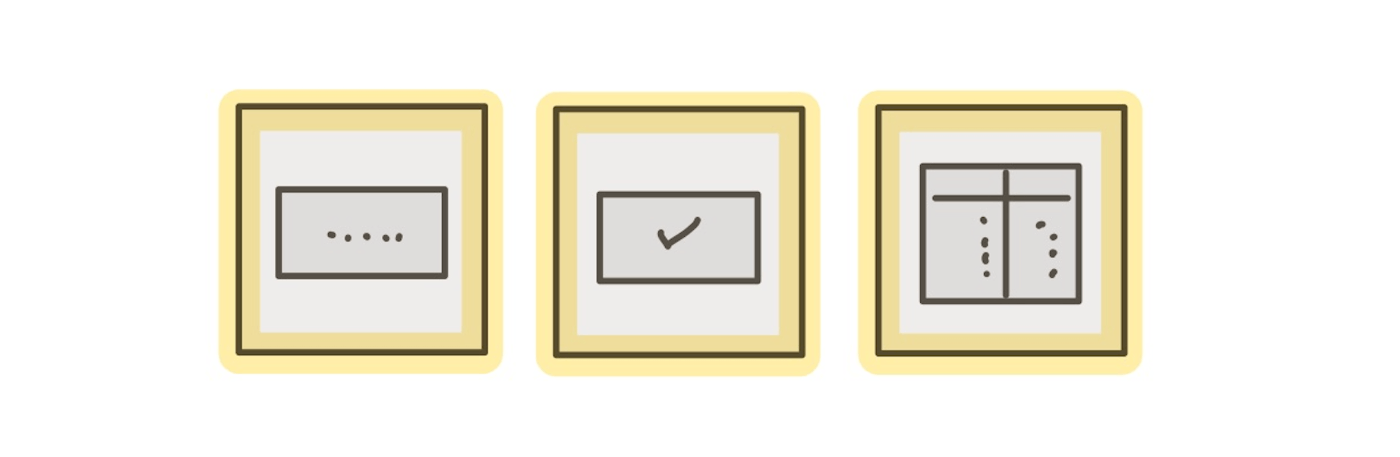
Storybookでは、こういった1つ1つの状態を再現したものStoryと呼びます。一度これらの状態をカタログに登録しておけば、バックエンドサーバーに自由に接続できない状況(フロントエンドの開発を先行して進めているときなど)にも役立ちます。
そうでなくても、バックエンドのデータを変更することなく、いつでもコンポーネントのすべての状態を確認できるので大変便利です。たとえばUI側の実装についてレビューする際は実際のアプリよりもStorybookを確認するほうがレビューしやすいこともあります。前述のとおりStorybookはChromaticにアップロードしているため、レビュワーはStorybookをローカル環境でビルドすることなく、PRから直接Chromaticに移動して確認できます。
Storybook 関連のツールについて
Storybookでビルドしたコンポーネントカタログは、Chromaticへアップロードし、それぞれのPRから簡単にアクセスできるようにしています。
ちなみに弊チームでは、ローディング状態のStoryを楽に作るために、専用のmswのリクエストハンドラを用意しています。これについては以下の記事で紹介していますので、ぜひ読んでみてください👍
Visual Regression Test(VRT)
VRT の必要性
Storybookはコンポーネントカタログとして利用するだけでなく、 Visual Regression Test (VRT) にも活用しています。
VRTでは、比較元のある時点(たとえばPull Requestの派生元commit)について、すべてのコンポーネントのスクリーンショットを保持しておき、比較したいもう1つの時点(たとえば、Pull Requestの最先端のcommit)のすべてのコンポーネントのスクリーンショットと1つ1つすべて比較し、すべての視覚的な差分を検出します。
VRTは、単体試験や結合試験でカバーしにくい視覚的な要素についての不具合を検出することに役立ちます。たとえば複数のコンポーネントで繰り返し同じような実装が行われており、その処理を共通化した際など、意図しないスタイルや見た目の変更を引き起こしていないかを網羅的に確認できます。
実際のイメージ
PRを作成すると、reg-suit からGitHubにコメントが届くよう設定しています。(設定方法は後述)
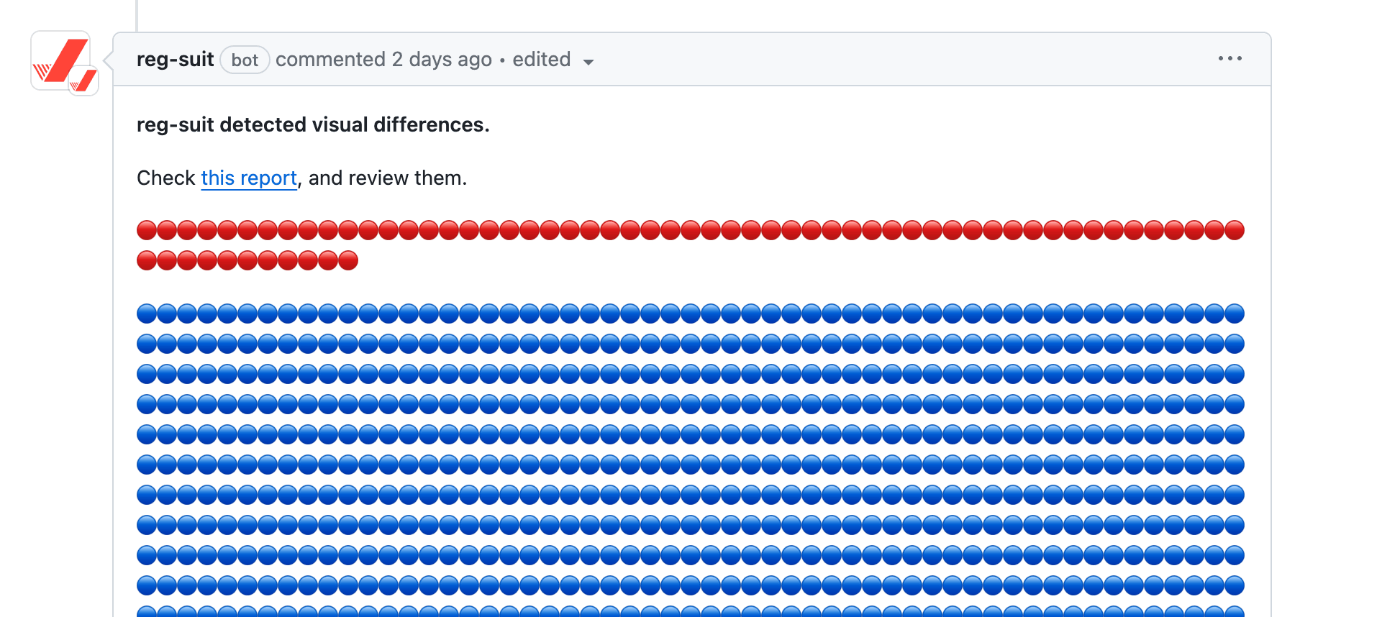
以下は実際のreg-suitによる差分検出の様子です。こちらは本来カードとDividerの間にスペースがあるべきなのに密着してしまっていたという不具合を解消したPRで検出された差分です。

このように実装時に意図した差分についてももちろん検出されるので、レビュワーに対して「このPRでアプリの見た目がこんなふうに変わったよ」と一目瞭然で伝えられます。
VRTをどう実施しているか
VRTを実現するために、storycapとreg-suit を使用しています。storycap は Storybook のすべての Story を画像としてキャプチャし、reg-suit は2つのキャプチャセットを比較して差分を検出します。
それぞれのcommitのスナップショットは、 reg-publish-s3-plugin を利用してAWS S3に保存しています。それぞれのPRにおけるVRTの結果をGitHubに通知するために reg-notify-github-plugin でを利用しています。
E2Eテスト
E2Eテストについて
E2Eテストではアプリにアクセスし、キー入力やボタン押下などの操作を行い、フィードバック内容を確認します。
結合テストでも同じような確認を行いますが、結合テストではモックサーバーへのリクエストを確認して終わりです。いっぽうで、E2Eテストでは実際のバックエンドにリクエストが行われるので、操作した内容が実際にアプリ上に現れます。結合テスト以上に、本来のアプリの動作を本質的に確認できるテストといえます。
現時点ではあまりE2Eテストを重視していない
現時点の弊チームでは、E2Eテストを実施しているのはごく限られた機能についてのみです。フロントエンドのアプリについてはE2Eテスト以外で十分に担保しており、バックエンド・インフラはそれぞれのテスト・監視で十分に担保しているため、E2Eテストでないとテストできない・E2Eテストがどうしても必要という状況がないためです。
アプリのうち、壊れたらすぐ気づきたい機能のハッピーパス(エラーケースなどを除く、もっとも一般的な操作の流れ)についてのみ、E2Eテストを導入しています。
本番環境を対象に実施
E2Eテストは本番環境を対象として実施しています。E2Eテスト用の環境を用意することもできますが、複雑な開発環境をE2Eテスト用にもう1つ作成・運用するコストに対し、それによって得られる恩恵が見合わないという判断で環境は用意していません。
また、本番環境を対象とすることで、「本番環境が(ハッピーパスにおいては)ちゃんと動いていること」の確認にもなります。
実行タイミング
テストの実行タイミングは、本番デプロイの終了後と毎日の定時実行です。本番デプロイ後に実行することで、フロントエンドのデプロイに起因する不具合によってアプリケーションが壊れていないことを確認しています。毎日の定時実行では、フロントエンドのデプロイに依らない変更(バックエンドやインフラ、その他の外部要因)によってアプリケーションが壊れていないことを確認しています。
Playwright について
E2EテストはPlaywrightでキー入力やボタン押下などの操作をモックします。Playwright のいいところは色々ありますが、導入してみた感触としては Auto-waiting や Trace viewer の恩恵がけっこう大きいなと感じています。テストを書くのも、書いた結果を確認するのも簡単です。
細かい話になりますが、デフォルトから変更してよかった項目について紹介します。
CircleCI の Test タブにテスト結果が表示されるよう、CIでは junit 形式でテスト結果のレポートが出力されるよう設定しています。(参考: CircleCIのドキュメント)
reporter: process.env.CI
? [['junit', { outputFile: 'e2e_report.xml' }]]
: [['html']],
- store_test_results:
path: apps/<app-name>/e2e_report.xml
また、テストが落ちたときにその状況を再現できるよう、traceファイルを書き出すようにしています。この設定をしておけば、テストを手元で再実行したりすることなく、何が起きたかを確認できます。Playwright公式が Trace Viewerを提供しており、大変便利です。
/* Collect trace when retrying the failed test. See https://playwright.dev/docs/trace-viewer */
trace: 'on',
- store_artifacts:
path: apps/social-login-manager/test-results
そのほか、社内の認証サーバーをスキップしてアプリケーションを利用するためにトークン情報をPlaywrightに設定したりもしています。これについては機会があれば別記事で紹介します。
課題と展望
ESLintのルール設定が複雑化している
ESLint設定は「静的解析」の項でも述べた通り、基本的にはフロントエンド開発でよく使われるルールセットをベースにしています。しかし、独自のルール設定、ルールに対する除外設定も多数記述されており、これについては歴史的経緯でかなり複雑化しています。今はもう不要になっているものもあるはずですが、なかなか整備できていません。
最初に述べた通り、主要なアプリケーションについては共通のルールを利用しているので、アプリごとにばらばらのESLint設定を運用していたときよりは幾分マシな状況ですが、おいおい整備していきたいところです。
Jest + React Testing Library の初回実行が遅くなることがある
テストランナーとしてJestを採用していますが、時折動作がとても重くなることがあります。とくに1日の最初に結合テストを動かすときなどに1分以上かかり、そのあとは早くなるということがあるのですが、原因はわかっていません(再現しないので調査がしづらく、よくわからない)。
単体テストでは発生しないため、おそらく原因はReact Testing Library側にあるのではと思うのですが、よくわかっていません。対策になるかわかりませんが、高速で軽量といわれている Vitest への乗り換えも試してみたいなと思っています。
React Testing Library の ...ByRole が遅い
React Testing Library のクエリ方法によってはテストの実行時間が伸びることも課題のひとつです。とくに ..ByRole 系の速度が問題になることが多いです。これはTesting LibraryのIssueにもなっています。
できるだけユーザーの操作に近い手順を再現したいので、テキストのみで一致するものを探すのではなく、ボタンやヘッダーといったセマンティックな要素を指定できる ...ByRole を使う方針としていますが、数が多いとタイムアウトすることが多いです。
とりあえずの対策として、テストケースごとのタイムアウト時間を規定の5秒→30秒に伸ばしています。
module.exports = {
...
testTimeout: 30000,
};
あまりテストの実行時間が時間が伸びるのも問題なので、タイムアウト時間を伸ばすにも限界があります。30秒のタイムアウトも超過してしまう場合は、しかたなく ...ByText などの時間がかからないクエリ方法に切り替えることもあります。
Storybook の立ち上げ・ビルドが遅い・たまに変になる
Storybook の設定のせいか、コンポーネントが多いからなのか、 storybook コマンドを実行してから1分以上かかります。基本的に開発時は立ち上げっぱなしにすることが多いので困ることは少ないですが、使いたい時にすぐ使えないのが不便に感じることがあります。
またStorybook はファイルを保存すると hot reload でカタログを更新してくれます。それは大変助かるのですが、こちらも保存してから数秒〜十数秒かかります。もっと一瞬で更新されてくれるとサクサク開発できそうです。
最後に、これは再現するときとしないときがありますが、hot reload のタイミングで MSW との接続がうまくいかず、MSWではなく実際のAPIにリクエストが飛んでしまう(その結果Storyがエラーとなる)ことがたまにあります。Storybookを開いてしばらく放っておいてから戻ると再現することが多い気がしますが、よくわかっていません。
VRT で実装と関係ない差分(ブレ)が検出される
storycap の設定によるものなのか、リソースのロード状況やMockDateの効き具合などにより、Pull Requestの変更とは関係なく視覚的な差分が発生することがあります。(社内ではこれをブレと呼んでいます)
このブレによって、スタイルや見た目に変更のないはずのPull Requestでもreg-suitに数十個の差分が出ていることが当たり前になっています。慣れてくると「ブレやすいStory」をなんとなく見慣れてきて、脳内でブレと本当の差分を選り分けることができるようになりますが、健全な状態とはいえません。視覚的な差分が発生しえないPRなら、ビシッと差分なしという結果になってほしいです。
対策としては、storycap-testrun を試してみたいです。よくあるブレの原因に対応できそうなのと、どうしても差分が出うる場所については mask できるのがとても便利そうです。
おわりに
最後までお読みいただき、ありがとうございました!1つの小さなフロントエンドチームの事例でしたが、少しでも参考になれば嬉しいです。
フロントエンドのテストは、冒頭でも申し上げたとおり、チームやプロジェクトによって色々なやり方があると思いますし、私たちもまだまだ試行錯誤の真っ最中です。この記事でお話ししたことは最初から決まっていたものは少なく、日々の開発やレビューの中で決まっていったものが大半です。
他のフロントエンドチームや、他の職種(バックエンドチームなど)のテストの話も聞いてみたいなと思いながら書きました。もしそういった資料があるよー記事書いたよーなどといった情報があれば、ぜひコメントやXなどで教えていただけたらとても嬉しいです!
おまけ: おすすめのテスト関連書籍
いずれも有名な本なので知っている方も多いと思いますが、私がフロントエンドのテストをどう書いていけばいいのかわからないぞと気づいた時に読んだ本などを紹介します。
テスト駆動開発

単体テストとは何か、テスト駆動開発とは何か、ということについて手を動かして学べます。まったくのテスト初心者でも一緒に手を動かせばテスト駆動開発について理解できると思います。が、その手を動かす言語がJavaなのでとっつきにくさはあるかもしれません。
テストを先に書きたいわけじゃないんだけど…という方にも、Red(まずは実装がない状態でテストを書いて落とす) - Green(テストが通るようにする) - Refactoring(テストを通したまま実装を改善する)の考え方は大事なのでおすすめです。「テストを書く」というのはつまり仕様を整理してどうあるべきかを規定する、という行為なので、実際にテストを書くかはさておき、まずやるべきことを整理するというやり方は良いものです。
フロントエンドの本ではありませんが、この本で学んだことはフロントエンド領域について考えるときにも大変役に立っています。
単体テストの考え方/使い方

「単体テストの」とありますが、単体テストに限らず結合テストの話も含まれます。さらにはテストという観点から広げて、良い設計についての話もたくさん含まれます。歴史的経緯や、どういったテストがなぜ望ましいのか、ということがこれでもかというくらいさまざまな視点から語られます。「なるほどそう考えたらしっくりくるのか」と何度も思いました。
なんとなくテストをしているけどあまり自信がない、という感じの方におすすめします。かわいらしい表紙ですが、ボリュームがすごいです。こちらもフロントエンドの本ではありませんが、実務でも役に立っており、読んでよかったなと思っています。
フロントエンド開発のためのテスト入門 今からでも知っておきたい自動テスト戦略の必須知識

初学者の家族に読んでもらうために購入したものの、実は私自身は通読できていないのですが🙏、フロントエンドのいまどきのテストについての事情がひととおりまとまっている良い本だと評判のようです。今回の記事ではインストール手順などの細かいステップは省略しましたが、この書籍ではハンズオン形式ですべてのテストを動かせるようになりますので、フロントエンドのテストを導入してみたい!という方にはぴったりだと思います。
おすすめの書籍は以上です!他におすすめがあればコメントなどでぜひ教えてください👍

Discussion
mswpida の紹介記事を書きました 😎
mswpida の v2.0.0 で対応しました!
ありがとうございます!本文内に追記しました 👍