ドーモ、株式会社ソーシャルPLUS CTO の サトウリョウスケ (@ryosuke_sato) です ✌︎('ω')✌︎
今日は弊社プロダクトにまつわる開発の話をしてみたいと思います 🔧
導入
弊社では CRM PLUS on LINE という Shopify App を提供しています。
平たくいえば ソーシャルPLUS の「ソーシャルログイン機能」と「LINEメッセージ配信機能」を EC サイトにサクッと導入できるアプリで、運用不要な自動配信も充実しているため、インストールするだけで結構な売り上げにつながるという素晴らしいプロダクトになっており、身近なところだと「ちいかわマーケット」さんにもご利用頂いています(宣伝)。
さて、そんな CRM PLUS on LINE は裏側で Shopify の API にすごい数のリクエストを送っている訳ですが、当然 API rate limit も設定されている訳で、節度を持って正しく扱う必要があります。
一般的な API rate limit の取り扱い
API rate limit を超過するというのは、単位時間あたりの API リクエスト回数が多いとか、GraphQL のクエリが重くて 1 回のリクエストに必要なコストが高いとかが原因だったりする訳で、以下のような対応でだいたい解決できます:
- API の実行結果を Redis や RDB にキャッシュする
- 更に webhook を使えばキャッシュの情報を更新することもできます
- GraphQL でコストの高いクエリを発行しない
- リアルタイムに処理しなくて良いならジョブで少しずつ実行させる
- 万が一 rate limit を超過した際もリトライしやすいです
一方で、このような対策をしても冒頭で紹介した「ちいかわマーケット」さんのように数百万件のフォロワーが存在するストアでは一斉告知の際に rate limit を超過してしまう場合がありました。以下は DataDog で計測しているストア毎の API リクエストの許容量ですが、約一時間半ものあいだ枯渇していたことがわかります:
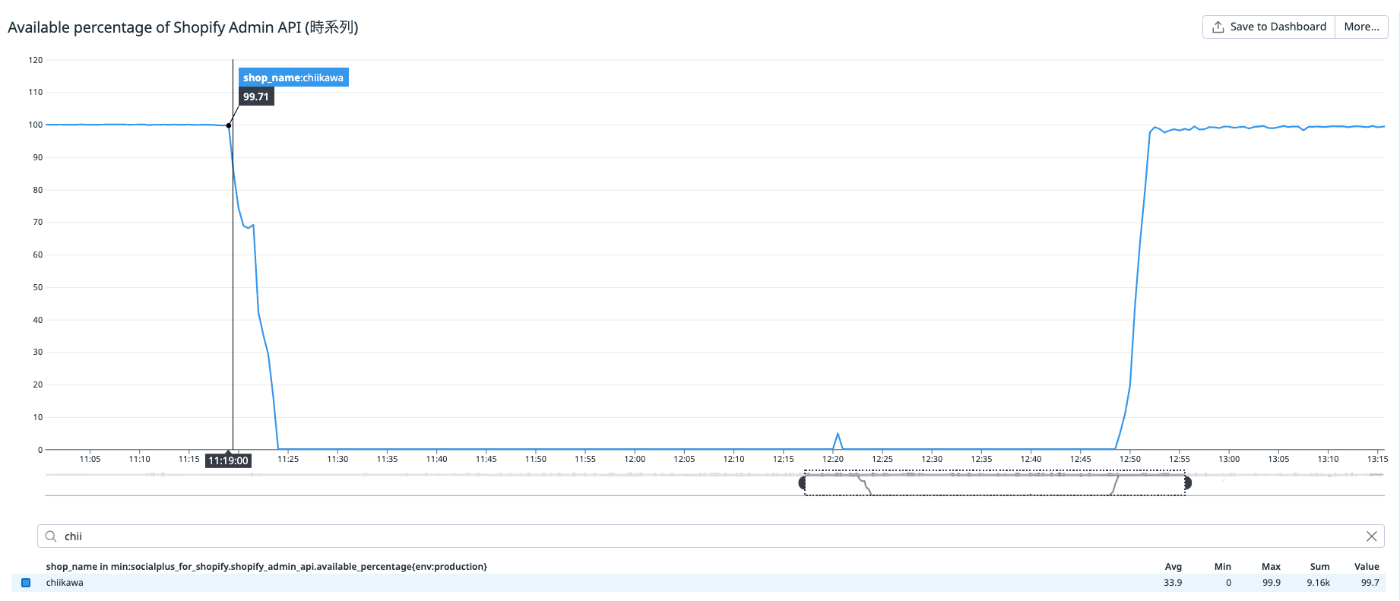
許容量はリアルタイムに回復するため、不安定ながらもサービスは稼働し続けることができました。偶然なんですが、ジョブで消費する実行コストの方がコントローラーで消費するコストより大きかったので、 rate limit を超過するエラーの大半はジョブでのみ発生していたのです。とはいえ再発は防止したいので何らかの対策が必要です。
普通の対応ではダメでした
原因を調査すると以下のことがわかりました:
- アクセス負荷に応じてスケールアウトが発生してジョブの並列実行数が増えたために単位時間内に実行される API リクエストが増えた
- ジョブの実行中に rate limit エラーが発生すると自動的にリトライするように実装しているが、許容量が枯渇した状態でもリトライが実行されるため、許容量の回復を妨げていた
前述の対策が完全に裏目に出てしまったようです 😇
もっと賢く API rate limit と向き合うには
プロセス・スレッド間で API rate limit の残量を共有する
元々の対応も方向性としては良かったと思いますが、もっと賢く実行させる必要があります。一番の原因は、非同期に実行しているジョブ間で API rate limit の残量が共有されていないという点にあります。Shopify Admin API はレスポンスに rate limit についての情報があるので、 API リクエスト前に前回の API リクエスト結果を把握できていれば制御ができそうです。
"extensions": {
"cost": {
"requestedQueryCost": 101,
"actualQueryCost": 46,
"throttleStatus": {
"maximumAvailable": 1000,
"currentlyAvailable": 954,
"restoreRate": 50
}
}
}
CRM PLUS on LINE の場合は redis-objects を使用して Redis に前回の Admin API レスポンスの情報を記録するようにしました。この情報はサービス内のあらゆるプロセスから参照できるので、 API リクエスト前に API rate limit の残量がどの程度あるのかを把握することができます。
API の許容量が減った時の実行戦略
次に、 API の許容量が一定水準を下回った際にどのような実行戦略を取るのかを検討しました。
-
:raise- 例外を発生させて API リクエストを中断させる
- ジョブで処理を実行しているケースを想定
- 一定時間経過後にリトライする
-
:sleep-
sleepを実行して処理を待機させる - ジョブで処理を実行しているケースを想定
-
-
:log- 特別な対応はせず、ログに許容量が減っていることだけを記録する
- Controller で処理を実行しているケースを想定
中断が可能なジョブでは API 許容量を消費しないように実行を遅延させ、中断できない Controller の処理に許容量を回しているという訳ですね。
:raise と :sleep の使い分けですが、 GraphQL では結果が複数ページで返されるケース があり、 :raise で中断するとまた最初のページから実行し直さないといけなくなるので、ページネーションの場合は :sleep するようにしています。
実行戦略をどのように選択させるか
さて、肝心なのは処理によってどうやって実行戦略を切り替えるのか、という点です。CRM PLUS on LINE の場合、Shopify Admin API はモデルで実装しており、ジョブとコントローラー両方からアクセスされる可能性があります。現在の API リクエストはどの実行戦略に基づいているかをなるべくシンプルな方法で設定したいです。
ここでは ActiveSupport::CurrentAttributes を使用することにしました。Kaigi on Rails 2023 でも取り上げられた Rails の機能 ですが、正しく使えば非常に便利です。
以下のように ActiveSupport::CurrentAttributes を継承したクラスを定義して:
module GraphqlExecutor
class Config < ActiveSupport::CurrentAttributes
attribute :strategy
end
end
ApplicationController とApplicationJob の before callback から実行戦略を設定するだけです:
class ApplicationController < ActionController::Base
before_action do
GraphqlExecutor::Config.strategy = :log
end
end
class ApplicationJob < ActiveJob::Base
before_perform do
GraphqlExecutor::Config.strategy = :raise
end
end
ページネーションを利用する場合は .set を使って一時的に実行戦略を変更します:
GraphqlExecutor::Config.set(strategy: :sleep) do
# ページネーションが発生する API リクエスト
end
実際の実装とは異なりますが Admin API の実行ロジックでは以下のようになっています:
class GraphqlExecutor
include Redis::Objects
value :admin_api_extension_cache, marshal: true, expireat: -> { 1.minute.since }
def execute_query
verify_available_ratio
result = api_request
persist_extensions(result)
end
def verify_available_ratio
return if admin_api_available_ratio > 0.3
message = "Admin API capacity is low. (Available: `#{admin_api_available_ratio * 100}%`)"
case Config.strategy
when :raise
raise Errors::CapacityLow, message
when :sleep
# NOTE: 実装を割愛していますが、実際には admin_api_extension_cache の値から消費した
# コストを回復するために必要な時間を計算して sleep を実行しています。
sleep(1.0)
else # :log
Rails.logger.warn(message)
end
end
def persist_extensions(result)
admin_api_extension_cache.value = result&.extensions
end
def admin_api_available_ratio
currently = admin_api_extension_cache.value&.dig('cost', 'throttleStatus', 'currentlyAvailable').to_f
maximum = admin_api_extension_cache.value&.dig('cost', 'throttleStatus', 'maximumAvailable').to_f
return 1.0 if maximum.zero?
currently / maximum
end
end
この対応によって API 許容量が 30% を下回ることがなくなりました 👏
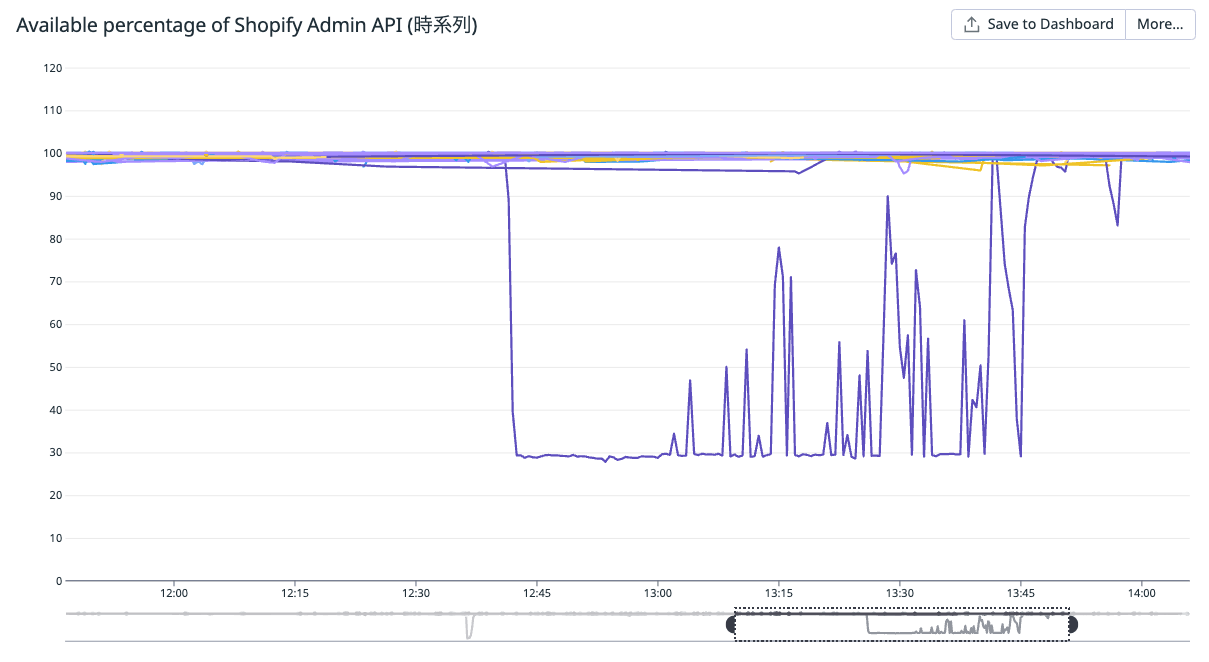
まとめ
本記事では高トラフィックなサービスにおける API rate limit の扱い方の事例を紹介しました。一般的なトラフィックであれば導入部分で紹介した対応で十分かと思いますが、より効率的な運用が求められる場合は色々と工夫が必要になります。本記事の内容が参考になりましたら幸いです 🙏
ではでは 👋

Discussion