こんにちは、simomu です。
今日は Puma で処理待ちのまま待機しているリクエストと Puma.stats で確認できる backlog の値の関係を、Puma がワーカースレッドでリクエストを処理するまでの実装を踏まえて調査した話をします。
以降は基本的には Puma 6.6 時点での話とし、Puma はシングルモードで使用している前提の話とします。
また、最後には Puma 7.0 以降での backlog がリクエストを追加される挙動の変化について話します。
調査の経緯
弊社では Ruby on Rails のアプリケーションサーバーとして Puma を使用しています。
ある時 APM を確認したところ、 Rack アプリケーションとしての duration は大きくないものの、最終的に Puma がレスポンスを返すまでの duration が大きくなっているという現象が確認されました。
この現象に対し「Puma のワーカースレッドの空き待ちが発生しているのではないか」という仮説を立て、インフラチームに Puma の統計情報を Datadog で確認できるインテグレーションを導入してもらいました。
その時の記事が↓になります。
これにより Puma.stats でも確認できるような backlog、つまりワーカースレッドの空きが出るまで待機しているリクエストがどれぐらい存在しているのかを計測できるようになりました。
しかしながら、Rack アプリケーションの duration としては小さく、最終的に Puma がレスポンスを返すまでの duration は大きい値を示しているにも関わらず、Puma の backlog の数値は 1 Puma サーバーあたり 0 ~ 1 程度の低い値を示しているという現象が確認されました。
Rack application duration (max)
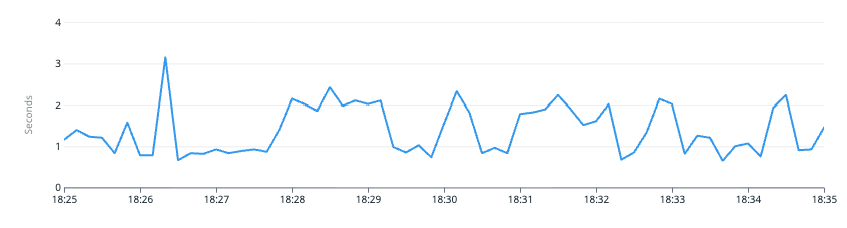
ALB target response duration (max)

Puma backlog (全 Puma サーバー合計)

1 Puma あたり 0 ~ 1 程度、詳細な台数は省略
そのため、
- Puma の backlog とは具体的にどういう値なのか?
- Puma の内部実装を踏まえて具体的に Puma のどこでリクエストが詰まっていると考えられるか?
を調査することにしました。
Puma がリクエストを処理する流れ
Puma はマルチスレッド構成な HTTP サーバーであり、受け取った HTTP リクエストの処理は各ワーカースレッドが並行に処理を行います。
具体的に Puma がリクエストをどうやって並行に処理しているのかを実際に実装を読んで、
私が理解した Puma 内部の大まかで簡易的なコードが以下のようになります。[1]
threads = THREAD_COUNT.times do
# worker thread
Thread.new do
while true
client = todo.shift # ④
data = client.read_nonblock # ソケットからリクエストのデータの読み出し
# 中略 受信したデータから Rack の env を作成し Rack を呼び出す
status, header, body = app.call(env) # ⑤
# 中略 Rack のレスポンスから HTTP レスポンスを組み立てて書き込み
client.write(res_body)
client.close
end
end
end
todo = Thread::Queue.new
server = TCPServer.new('0.0.0.0', 3000) # ①
server.listen(1024) # ソケットの接続キューサイズの設定
## server thread
while true
client = begin
server.accept_nonblock # ②
rescue IO::WaitReadable
next
end
todo << client # ③
end
-
TCPServer.new+TCPServer#listenでソケットを接続待ちにする (①)- Puma の該当実装
- ソケットに到達したリクエストを
TCPServer#accept_nonblockで accept する (②)- Puma の該当実装
- 何かしら accept したリクエストがあった場合は、それを一旦
Thread::Queueであるtodoに積む (③)。以降の処理はワーカースレッド側になる- Puma の該当実装
- ワーカースレッド側では
todoからリクエストを一つ取り出し (④)TCPSocket#read_nonblockでデータを読み出す- Puma の該当実装
- 読み出したデータから Rack アプリケーションに渡すための
envを構築し、Rack アプリケーションを呼び出す (⑤)。これ以降が Rails 側での処理になる- Puma の該当実装
- Rack から戻ってきたレスポンスを実際の HTTP レスポンスに変換し、TCPSocket に書き出して close する

同様の図が Puma リポジトリの docs でも確認できます: https://github.com/puma/puma/blob/v6.6.1/docs/architecture.md#queue_requests
Puma.stats などで取得できる Puma の backlog は Puma::ThreadPool の @todo のサイズになります。上記のサンプルであれば Thread::Queue.new で作成した todo のサイズに相当します。
そして、Datadog APM などで確認できる Rack アプリケーション単位の Duration は ⑤ の内部でかかっている時間に相当します。
ここまで見る限りでは、Puma 内部でリクエストがどれぐらい保留されているのかを確認するのにあたって Puma の backlog を見るのは妥当そうに見えます。
Puma のどこでリクエストが詰まっていたのか?
Puma の実装を見る限りでは Puma の backlog は、文字通り Puma のワーカースレッドで処理される前に保留されているリクエストの数のように見えます。
一方で実際に Puma backlog に値として現れないということは、
- Puma がリクエストを
@todoに積む前 -
@todoからリクエストを取り出してから Rack アプリケーションを呼び出すまで
のどこかで詰まっていることが考えられました。
その観点で Puma の実装を確認したところ、Puma 6.6 時点では Puma がソケットから接続要求を accept する前に以下のような実装が入っていることがわかりました。
ポイントとなるのは 367行目の pool.wait_until_not_full で、具体的には Puma::ThreadPool に以下のような実装がされています。
busy_threads はリクエストを処理しているスレッド数、@max は設定されている最大ワーカースレッド数を示します。
つまり、最大ワーカースレッド数に対して空きが存在するまで接続要求の accept を待機するようです。
## server thread
while true
client = begin
wait_until_not_full # ワーカースレッドの空きが出るまで accept を待機
server.accept_nonblock # ②
rescue IO::WaitReadable
next
end
todo << client # ③
end
accept される前の接続要求は OS 側で保留され、そのキューの最大サイズは TCPServer#listen の引数で指定されます。[2]
保留されている接続要求の数は、Linux であれば ss コマンド等で表示される一覧のなかで、 state が LISTEN のものの Recv-Q の値がそれに該当します。
$ ss -tnl
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 15 1024 0.0.0.0:3000 0.0.0.0:*
下記の図でいうところの左側で待機しているということです。

そのため、Puma のサーバー全体で見たリクエストが保留されている数を計測する際は Puma の backlog だけでは不十分であり、TCP の backlog も計測する必要があることがわかりました。
2023年に書かれた↓の記事でも似たような記述が存在します。
Coming back to Puma stats, there's a backlog counter, and its a bit misleading. Backlog represents the number of requests that have made it to a worker but yet to be processed. The value will normally be zero, as requests queue on the TCP/Unix socket in front of the master Puma process, but not in the worker thread pool. More on this in Puma's PR. So, backlog metric on itself does not provide us with enough insight.
(機械翻訳) Pumaの統計情報に戻ると、backlogカウンターがありますが、少し誤解を招く可能性があります。バックログは、ワーカーに到達したもののまだ処理されていないリクエストの数を表します。リクエストはマスターPumaプロセスの前のTCP/Unixソケットにキューイングされますが、ワーカースレッドプールにはキューイングされないため、通常はこの値は0になります。この点については、PumaのPRで詳しく説明しています。つまり、バックログ指標だけでは十分な情報が得られません。
上記の記事で紹介されている Puma の PR は↓です。
Puma のサーバー全体で見たリクエスト保留数の計測には TCP backlog も必要ということがわかったため、インフラチームに Puma サーバーの TCP backlog もメトリクスとして確認できるようにしてもらったところ、実際に Puma サーバーでリクエストが詰まっていると思われる時間帯で TCP backlog の値が大きくなっていることが確認できました。
TCP backlog (ある特定の Puma サーバー)

Puma backlog (↑と同じ Puma サーバー)

Puma 7.0 での変化
Puma のリクエスト詰まりに関する調査をしている最中に、Puma 7.0 がリリースされました。
変更内容の中に以下のものがあります。
詳細は省略しますが、この PR の変更によって従来ではソケットから接続要求を accept する際にワーカースレッドの空きが出るまで待機していたのが、稼働中のワーカースレッド数と Reactor[3] に積まれているコネクションの数を元に計算した時間分待機するというものに変わっています。
ワーカースレッドの空きを待たなくなったため、この変更は Puma backlog へリクエストが積まれやすくなったように見えます。
実際に、Puma 7.0 へのアップデート以降では Puma backlog の値が有意に現れるようなったことを確認しました。
Puma backlog (Puma 7.x)
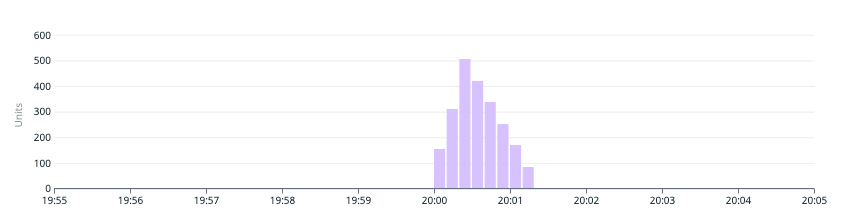
ALB response duration (max)

一方で、TCP backlog の値が不要になるのかというとそうともいい切れず、リクエストの傾向[4]によっては TCP backlog のほうが高い値を示すこともあり、弊社の開発チームでは現在も引き続き TCP backlog の値も要観察状態としています。
まとめ
今回は Puma の内部実装を読み、リクエストが処理される流れを追いながら Puma 内部のどこでリクエストが詰まりうるのかを調査し、Puma の backlog だけではなく TCP backlog も計測するのが良さそうということがわかりました。
今回実装を読んだ範囲は Puma のごく一部であり、実際の細かい挙動を理解するにはまだまだ不十分です。
もっと詳細な Puma のコードリーティングに関しては別途機会があればまとめようと思います。
参考
- Monitoring Puma web server performance
- Meter calling accept(2) with available pool capacity by evanphx · Pull Request #1278 · puma/puma
- Pumaの内部実装を調査してみた
- 第29回 Reactorで非同期処理をやってみよう(1) | gihyo.jp
- Meter calling accept(2) with available pool capacity by evanphx · Pull Request #1278 · puma/puma
-
当然ながら実際の Puma はこれほどシンプルではなく、今回の事象の説明のために大きく省略しています。
例えば、ワーカースレッド側でread_nonblockを実行した際にまだ readable な状態ではない場合はコネクションをワーカースレッドから Reactor に追加し、
Reactor 側ではNIO::Selector#selectを実行し、 readable な状態になったものがあれば再度 todo に戻す、
という流れがあったりします。 ↩︎ -
listen(2)の第2引数と同様。指定できる最大サイズは OS によって制限される ↩︎ -
いわゆる Reactor パターンにおける "Reactor"。参考: https://gihyo.jp/dev/serial/01/ruby/0030#sec3 ↩︎
-
例えば、大量ではあるが一つ一つは軽量なリクエスト ↩︎

Discussion