はじめに
Pumaがどのように動作するのか、ざっくりとコードリーディングをしてみました。体系的な(或いは教科書的に)Webサーバについての知識をまとめたわけでもなく、筆者自身が気になった部分にフォーカスして記事を書いています。また専門的な知識を持ち合わせているわけでもないので、記事内に間違いがあるかもしれません。とはいえ、PumaなどWebサーバの仕組みって面白いなという思いもあるので、何かのご参考になれば幸いです。
アーキテクチャ
はじめにPumaのドキュメントを参考にアーキテクチャの概要について確認します。まずは何となくのイメージを掴むことを目的とします。
概要
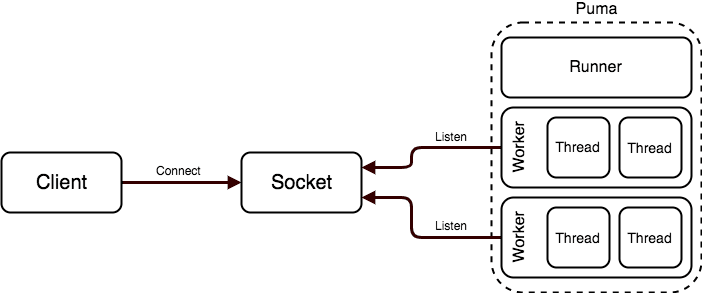
Pumaでは、マスタープロセスをforkした子プロセスをワーカーと呼称します。上記の図におけるポイントは何でしょうか。まず複数のワーカーは単一のソケットをリッスンすることが分かります。そして各ワーカー内ではさらに複数のスレッドが起動します。
リクエストの受信
ワーカーとその内部で起動しているスレッドがどのようにリクエストを処理するかを示したのが下記の図です。

ワーカー内には「Receive Thread」が存在しており、リクエストをAcceptするとTodoに追加しています。この「Receive Thread」やTodoはワーカー内で単一です。つまりワーカ内のスレッドで共有されます。スレッドは、Todoに積まれたリクエストを順番に捌きます。
図には登場しませんが、「Reactor」の役割も重要です。Reactorは名前の通りReactorパターン[1]に基づいており、ノンブロッキングI/Oとバッファリングの仕組みを支えます。リクエスト全体が完全に受信されてからTodoに格納する役割です。Reactorの詳細についても後述します。
概要を確認するだけでは、全く持って意味不明なのでここからはより具体的に確認していきます。
プリフォーク
Pumaを起動すると、config/pumaの設定に従って必要なプロセスとスレッドを事前に起動します。ワーカー2、スレッド3の設定でbundle exec pumaを実行してみました。
# ps aux | grep puma
root 679 2.7 0.4 82892 22044 pts/3 S+ 06:41 0:00 puma 6.3.0 (tcp://0.0.0.0:9292) [ruby]
root 680 0.9 0.5 697100 26104 pts/3 Sl+ 06:41 0:00 puma: cluster worker 0: 679 [ruby]
root 681 0.9 0.5 697112 26176 pts/3 Sl+ 06:41 0:00 puma: cluster worker 1: 679 [ruby]
プロセスが3つ存在しています。その内の1つはマスタープロセスなので、2つのワーカープロセスが起動していることが確認できました。プリフォークによって、接続毎にコストのかかるforkを実行する必要がありません。
さらにワーカー内のスレッドも起動しています。
# top -p 680 H
680 root 20 0 697100 26104 4340 S 0.0 0.5 0:00.21 ruby3.0
682 root 20 0 697100 26104 4340 S 0.0 0.5 0:00.00 puma wrkr check
688 root 20 0 697100 26104 4340 S 0.0 0.5 0:00.00 puma srv tp 001 # 👈 Thread Pool
689 root 20 0 697100 26104 4340 S 0.0 0.5 0:00.00 puma srv tp 002 # 👈 Thread Pool
690 root 20 0 697100 26104 4340 S 0.0 0.5 0:00.00 puma srv tp 003 # 👈 Thread Pool
694 root 20 0 697100 26104 4340 S 0.0 0.5 0:00.00 puma reactor # 👈 Reactor
695 root 20 0 697100 26104 4340 S 0.0 0.5 0:00.15 puma srv thread
696 root 20 0 697100 26104 4340 S 0.0 0.5 0:00.00 puma srv thread
697 root 20 0 697100 26104 4340 S 0.0 0.5 0:00.00 puma srv # 👈 Receive Thread
698 root 20 0 697100 26104 4340 S 0.0 0.5 0:00.04 puma stat pld
スレッドは3で指定したので、puma srv tp 001、puma srv tp 002、puma srv tp 003がThread Poolで実行されるスレッドであることが分かります。他にも前述のReceive Thread、Reactorの役割を担うスレッドも確認できました。その他のスレッドについてはこの記事では取り扱いませんがいずれもPumaの仕組みを理解する上で重要です。
シーケンス
詳細は省いているものの大枠の流れを下記に示します。
スレッドプールの役割は、Todoに積まれたクライアントを処理することです。データが16KBより大きい場合は、一旦読み取りをやめてリアクターの監視対象に入ります。リクエストを完全に受信すると、再度Todoに積まれてスレッドプールが処理します。そしてRailsなどのRackアプリケーションに処理が渡ります。シーケンス図を正しい記法で書けているか怪しい(多分書けていない)かもしれません。ここからは各スレッドのメインとなる処理を確認していきたいと思います。
レシーブスレッド
このスレッドで動く処理は下記の通りです。詳しくは後述しますが、IO.selectによって接続可能なソケットが見つかったら、accept_nonblockを実行して接続を受け付け、新しいソケットを作成します。そしてClientインスタンスを生成して、スレッドプールのTodoに格納します。
# lib/puma/server.rb
def handle_servers
# -
while @status == :run || (drain && shutting_down?)
begin
ios = IO.select sockets, nil, nil, (shutting_down? ? 0 : nil) # I/Oの多重化
break unless ios
ios.first.each do |sock|
if sock == check
break if handle_check
else
pool.wait_until_not_full
pool.wait_for_less_busy_worker(@options[:wait_for_less_busy_worker])
io = begin
sock.accept_nonblock # ノンブロッキングにaccept(2)を実行
rescue IO::WaitReadable
next
end
drain += 1 if shutting_down?
# poolは、ThreadPoolのインスタンス
pool << Client.new(io, @binder.env(sock)).tap { |c|
c.listener = sock
c.http_content_length_limit = @http_content_length_limit
c.send(addr_send_name, addr_value) if addr_value
}
end
end
# -
end
# -
end
スレッドプール
前述の通り<<メソッドで@todoにClientインスタンスが格納されました。起動中のスレッドが行うのは、@todoからFIFO(先出し先入れ)でClientインスタンスを引数にして、blockに登録されたPuma::Server#process_clientを実行することです。
# lib/puma/thread_pool.rb
def <<(work)
with_mutex do
# -
@todo << work
# -
end
end
def spawn_thread
todo = @todo
th = Thread.new(@spawned) do |spawned|
Puma.set_thread_name '%s tp %03i' % [@name, spawned]
# -
while true
work = nil
mutex.synchronize do
# -
work = todo.shift # todoに格納されたClientインスタンスを取り出す
end
# -
begin
@out_of_band_pending = true if block.call(work) # block = Puma::Server#process_client
rescue Exception => e
STDERR.puts "Error reached top of thread-pool: #{e.message} (#{e.class})"
end
end
end
@workers << th
th
end
リクエストデータの受信
Puma::Server#process_clientメソッドは、Clientインスタンスのeagerly_finishを実行して、falseが返却される(読み取りが完了しない)とReactroのキューに積みます。
# lib/puma/server.rb
def process_client(client)
# -
begin
if @queue_requests && !client.eagerly_finish # リクエストデータを読み取る
client.set_timeout(@first_data_timeout)
if @reactor.add client # Reactorのキューに積む
close_socket = false
return false
end
end
# -
while true
@requests_count += 1
case handle_request(client, requests + 1)
# -
end
end
true
# -
end
Clienインスタンスにおけるデータの読み取りは下記の通りです。read_nonblock[2]はノンブロッキングな読み取りを行うメソッドです。@ioが読み取り可能でない場合は、IO::WaitReadableエラーが発生するので、それをrescueしてfalseを返却します。16KBずつ読み取りを行い、全てのデータの読み取りが完了しなければfalseを返却しています。
# lib/puma/client.rb
def eagerly_finish
# -
try_to_finish
end
def try_to_finish
# -
begin
data = @io.read_nonblock(CHUNK_SIZE) # CHUNK_SIZE = 16 * 1024
rescue IO::WaitReadable
return false
rescue EOFError
# Swallow error, don't log
rescue SystemCallError, IOError
raise ConnectionError, "Connection error detected during read"
end
# -
@parsed_bytes = @parser.execute(@env, @buffer, @parsed_bytes)
if @parser.finished? && above_http_content_limit(@parser.body.bytesize)
@http_content_length_limit_exceeded = true
end
if @parser.finished?
return setup_body
elsif @parsed_bytes >= MAX_HEADER
raise HttpParserError,
"HEADER is longer than allowed, aborting client early."
end
false # 読み取りが完了していなかったら、最終的にfalseを返却する
end
リアクター
Reactorクラスは、LIFO(先入れ後出し)でClientインスタンスの読み取りを実行します。このキューの仕組はQueueクラス[3]やNio::Selctor[4]クラスを用いて実現していますが詳細は割愛します。
# lib/puma/reactor.rb
def add(client)
@input << client
@selector.wakeup
# -
end
def select_loop
close_selector = true
begin
until @input.closed? && @input.empty?
timeout = (earliest = @timeouts.first) && earliest.timeout
@selector.select(timeout) {|mon| wakeup!(mon.value)} # mom.value = 登録されているClientインスタンス
unless @input.empty?
until @input.empty?
client = @input.pop
register(client) if client.io_ok?
end
@timeouts.sort_by!(&:timeout_at)
end
end
# -
end
def register(client)
@selector.register(client.to_io, :r).value = client
# -
end
def wakeup!(client)
if @block.call client # block = Puma::Server#reactor_wakeup
@selector.deregister client.to_io # 読み取りが全て完了したら登録を外す
# -
end
Puma::Server#reactor_wakeupは、データの読み取りを実行して完了したら、スレッドプールのTodoにClientインスタンスを格納するメソッドです。読み取りが完了しなければ、引き続きReactorの監視対象となり、全ての読み取りが完了するまで繰り返されます。
def reactor_wakeup(client)
# -
# try_to_finishは前述のメソッド。全ての読み取り完了したらtureを返却する。
if client.try_to_finish || (shutdown && !client.can_close?)
@thread_pool << client
# -
end
ここまででリクエストデータの受信をPumaがどのように取り扱うのか一連の流れを確認することができました。ここからはより個別のトピックを取り上げることにします。
I/Oの多重化
前述のIO.selectは、select(2)システムコールを実行するメソッドです。再度コードを確認してみましょう。IO.selectは接続可能なソケットを返却します。接続可能なソケットが存在しない場合、ループがbreakされsock.accept_nonblock は実行されません。accept_nonblockメソッドは、accept(2)を呼び出すメソッドですが、それなりにコストがかかります。接続可能なソケットのみaccept(2)の実行を制限しているのです。
# lib/puma/server.rb
def handle_servers
# -
while @status == :run || (drain && shutting_down?)
begin
ios = IO.select sockets, nil, nil, (shutting_down? ? 0 : nil)
break unless ios
ios.first.each do |sock|
if sock == check
break if handle_check
else
pool.wait_until_not_full
pool.wait_for_less_busy_worker(@options[:wait_for_less_busy_worker])
io = begin
sock.accept_nonblock
rescue IO::WaitReadable
next
end
# -
end
# -
end
ところでI/Oの多重化のテーマには、select(2)以外にもpoll(2)というシステムコールが存在します。select(2)には扱えるファイルディスクリプタが1024までという制限があります。poll(2)にはその制限がないのが違いです。しかしselect(2)もpoll(2)のいずれも監視対象のファイルディスクリプタn個をループの中で1つずつ状態確認します。その為計算量的にはO(n)になるので、ファイルディスクリプタに比例してコストが上昇します。
Linuxのepoll APIは、ファイルディスクリプタの状態をカーネルで監視していてループによる監視が不要です。なのでよりパフォーマンに優れています。linuxのepollに相当するものは、WindowsではIOCP、macOSではkqueueにあたります。それらの差異を吸収するためにNode.jsではlibuvというライブラリを用いることでパフォーマンスに優れた非同期I/Oを実現している'らしい'です。Rubyにもepollを実現するgemはあるものの、Pumaでは残念ながら導入に至っていません。
ルーティング
今回コードを読んでいて思ったのが、リクエストが処理されるワーカーとスレッドはランダムになっているのではないかということです。それはつまりある特定のワーカーにリクエストが集中することが有り得るのかどうかという疑問です。ロードバランサーが複数のサーバをどのように選択するかというテーマに近しいものですが、サーバ内においてもどのワーカープロセスにルーティングされるのかについて同様に議論になりそうです。
例えば次のように状態のケースでは、新たにリクエストが発生した場合はワーカーCに担当させたいです。しかし実際にはワーカーBのスレッド3が処理を行う可能性があるように思いました。
ワーカーA:スレッド1(使用中)、スレッド2(使用中)、スレッド3(3使用中)
ワーカーB:スレッド1(使用中)、スレッド2(使用中)、スレッド3(未使用)
ワーカーC:スレッド1(未使用)、スレッド2(未使用)、スレッド3(未使用)
Pumaはこれらを制御出来ているのでしょうか。Inject small delay for busy workers to improve requests distributionがまさに筆者の疑問をより深ぼっています。どうも制御は上手くはできていないようです。現時点では、レシーブスレッドのループの中に5ミリ秒の遅延を設けることで、ビジーなワーカーがリクエストを受け取る確率を下げています。スループットとの兼ね合いもあるので、なかなか厳しい対応と言えるかもしれません。
GVL
PumaのREADMEにも記載があるように、GVLが動作することでスレッドは実際には並列では実行されません。スレッドはパラレル(並列)ではなく、コンカレンシー(平行)に動作します。並列性はあくまでマシンのプロセス間において実現されます。スレッドの設定値の目安は、データベースのコネクション数に揃えるのが良さそう[5]であるというのもGVLに関連します。
業務でも最近Rubyが2系から3系にバージョンアップされたこともあり、Ractor[6](注:Reactorではない)によるスレッドの並列実行にも興味があるところです。しかしGVLについて掘り下げるのはボリュームがあってさらにもう一つ記事が書けてしまいそうなので、ここではやめておくことにします。
「Pumaは今後Ractorを取り入れるんでしょうか?」「当然検討はすると思いますけど、今のRailsアプリだとRackミドルウェアがRactorの上で動くようにできてないから難しいかもしれませんね: Rackミドルウェアより手前の前処理部分ならRactorで高速マルチスレッドできるかもしれませんけど」「なるほど」
出典:週刊Railsウォッチ(20200929後編)RubyKaigi Takeout 2020 感想戦@仮想松本が盛況、Puma 5のスリープソート、GitHub Codespacesほか
おわりに
ある日、2015年Webサーバアーキテクチャ序論というブログ記事に出会いました。面白い記事だなと思ったものの、普段の開発でWebサーバを意識することがそれほど多くないこともあって、なかなか理解しづらかったです。
Rubyで書かれたgemを読むのが好きだったこともあって、そうであればPumaのコードリーディングをしてWebサーバの解像度を上げようかな、ということで記事を書きました。これまでもWebサーバーについていくつかの記事を読んで学んでいたものの、今回改めて実際のコードを読むことで少しだけ深く理解することができたと思います。
参考
※本文中に記載したものを除く
Webサーバーアーキテクチャ進化論2023
Reactorで非同期処理をやってみよう(1)
Working With TCP Sockets
I/O Multiplexing(I/O多重化)
ノンブロッキングI/Oと非同期I/Oの違いを理解する
Rubyアプリケーションを毎分1000リクエストにスケールさせる: 初心者ガイド

Discussion