SocialDog Analyticsチームエンジニアのuutaです。
SocialDog Analyticsチームでは主にSocialDogの分析機能の開発を行っています。
前提・問題意識
SocialDogの投稿パフォーマンス機能開発において、大量のデータを効率的に処理する必要性から、BigQueryの採用を検討しました。その過程で、既存のバッチ処理やAPIで使用しているGo言語とBigQueryを連携させる環境の構築に取り組むことになりました。
しかし、Go言語でBigQueryを扱う環境の構築に関する情報が非常に限られていたため、多くの課題に直面しました。この記事では、私たちが経験した問題と、その解決策を共有します。
この記事で紹介すること
- Go言語で利用できるBigQueryのパッケージについて
- bigquery-emulatorを導入するための簡単な説明
- ローカル開発のトラブルや解決策のtips
Go言語とBigQueryを統合したい
SocialDogのバックエンドの新機能開発では、Go言語を主に使用しています。投稿パフォーマンス機能のAPI、バッチ機能開発でもGo言語を利用するため、どのようにBigQueryと統合するかが問題になりました。当初は、ローカル開発環境をbigquery-emulator(後述)のみで完結させることを目指していましたが、現在は一部開発用のBigQueryを使用して実装を進める形に落ち着いています。
- 本番環境: BigQueryを使用
- 開発環境: bigquery-emulatorの使用、開発用に割り当てたBigQueryを一部テストで使用
Go言語で利用できるBigQueryのパッケージについて
また、BigQueryを取り扱うためのGo言語のパッケージとして、下記を採用しています。
- BigQuery REST APIを取り扱う
- BigQuery Storage Write APIを取り扱う
- BigQueryサーバーをローカル環境でエミュレートする
ローカル環境の構築
bigquery-emulatorを用いたローカル・テスト環境の構築
開発効率を上げるため、まずはbigquery-emulatorを使用したローカル環境の構築に取り組みました。bigquery-emulatorはBigQueryサーバーをローカル環境でエミュレートするためのGo製のオープンソースソフトウェアです。
goccyさんという方が開発されています。
以下は、その手順の概要です:
- Docker環境の準備
- bigquery-emulatorのコンテナ設定
- Go言語環境とのインテグレーション
SocialDogの開発ではDocker Composeを採用しており、比較的簡単にコンテナを作成することができました。
bigquery-emulator:
image: ghcr.io/goccy/bigquery-emulator:0.6
platform: linux/amd64
ports:
- "9050:9050"
- "9060:9060"
volumes:
- ../../:/var/www/html
imageは下記から選択することができます。
開発中のトラブルと解決策のtips
BigQueryとGo言語をベースにした開発環境との統合に関する情報が少なく、開発環境構築には苦慮しました。今も課題はありますが、開発中に直面した課題とチームで採用した解決策について紹介したいと思います。項目は下記の通りです。
- bigquery-emulatorで関数が動作しない問題
- テストデータの永続化の問題
- BigQuery Storage Write APIとの統合
- 開発環境と本番環境の出し分け
- レコードの読み込み
- レコードの書き込み
1. bigquery-emulatorで関数が動作しない問題
bigquery-emulatorを使用する中で、いくつかの関数が動作しないという問題に直面しました。具体的にはDATETIME_BUCKET、MAX_BY、MIN_BYなどの関数が使用できませんでした。
理由は、bigquery-emulatorが依存している goccy/go-zetasqlite で、上記の関数が現状サポートされていなかったためです。MAX_BYやMIN_BYなどの関数は、BigQueryが提供する比較的新しいクエリであり、サポート外の関数が出るのは避けられない印象です。
今回は、下記の方法を用いてBigQueryへのリクエストを表現することにしました。
- CREATE FUNCTIONを使用して、必要な関数を擬似的に作成
- BigQuery本体でクエリを実行し、結果を確認する方法を併用
まず、1に関して、udfsというstring型のスライスの中にCREATE FUNCTIONを入れ、擬似的にTIMESTAMP_BUCKETが利用できる形にしました。以下はCREATE FUNCTIONをGoで実装する例です。
func CreateFunction(ctx context.Context, c *bigquery.Client) error {
// 追加したいユーザー関数を定義
udf := `
CREATE FUNCTION TIMESTAMP_BUCKET(datetime TIMESTAMP, int INTERVAL) AS (
CASE int
WHEN INTERVAL 1 HOUR
THEN datetime
WHEN INTERVAL 1 DAY
THEN TIMESTAMP(EXTRACT(DATE FROM datetime))
WHEN INTERVAL 7 DAY
THEN TIMESTAMP_SUB(TIMESTAMP(EXTRACT(DATE FROM datetime)), INTERVAL EXTRACT(DAYOFWEEK FROM datetime) - 1 DAY)
END
)
`
q := c.Query(udf)
j, _ := q.Run(ctx)
j.Wait(ctx)
return nil
}
また、2に関して、BigQueryに用意した開発用のデータを用いて直接クエリを叩いて結果を確認しながら開発を進める方法を部分的に採用しています。
2. テストデータの永続化の問題
次に直面したのは、開発で使用するテストデータをどのように挿入・維持するかという問題です。最初は、bigquery-emulatorに存在する—databaseと —data-from-yaml というコマンドでデータの挿入と永続化を試みましたが、下記のエラーにより期待する動作が得られませんでした。
BigQuery error in query operation: Error processing job '<job_id>': failed to
scan rows: failed to decode value: illegal base64 data at input byte 4
一旦、compose.ymlファイルに—data-from-yamlを追加して、ymlファイルからDocker Composeを起動するたびに、bigquery-emulatorに特定のデータを挿入するという形にしています。
bigquery-emulator:
image: ghcr.io/goccy/bigquery-emulator:0.6
platform: linux/amd64
ports:
- "9050:9050"
- "9060:9060"
volumes:
- ../../:/var/www/html
command: bigquery-emulator --project=<project-name> --data-from-yaml=<data.yaml>
暫定的な策ですが、開発で使用するデータをymlファイルを通して入れることができました。
3. BigQuery Storage Write APIとの統合
データの書き込みは、BigQuery Storage Write APIを利用する形にしました。Google公式のドキュメントに記載のメリットがあるように思えたからです。
Storage Write API は、古い insertAll ストリーミング API よりも大幅に低コストです。さらに、1 か月あたり最大 2 TiB を無料で取り込むことができます。- BigQuery Storage Write API の概要 | Google Cloud
問題は、BigQuery Storage Write APIをGo言語に組み込むための情報が不足していたことです。体系的に解説する記事が当時は存在しなかったため、ここら辺を参考に実装を進めました。
- https://github.com/bucketeer-io/bucketeer/blob/19548c4f783869040b51fb0eddde5d9b25adcdab/pkg/storage/v2/bigquery/writer/client.go
- https://github.com/luci/luci-go/blob/3f7339cdf0b0747619d469d92b84725a9006e050/resultdb/bqutil/storagewrite.go
BigQuery書き込み用のNewWriter関数とbigquery-emulator書き込み用のNewEmulatorWriter関数の2種類を用意し、環境に応じて接続先を変えられるように実装しました。下記は実装の例です。
type WriteClient struct {
c *managedwriter.Client
projectID string
datasetID string
}
type NewWriteClientFunc func(context.Context) (*WriteClient, error)
func newWriteClient(c *managedwriter.Client, projectID, datasetID string) *WriteClient {
return &WriteClient{c: c, projectID: projectID, datasetID: datasetID}
}
func NewWriter(projectID, datasetID string, opts ...CreateOption) NewWriteClientFunc {
return func(ctx context.Context) (*WriteClient, error) {
c, err := managedwriter.NewClient(
ctx,
projectID,
)
if err != nil {
return nil, fmt.Errorf("failed to create new bq client: %w", err)
}
return newWriteClient(c, projectID, datasetID), nil
}
}
func NewEmulatorWriter(projectID, datasetID, serverURL string) NewWriteClientFunc {
return func(ctx context.Context) (*WriteClient, error) {
c, err := managedwriter.NewClient(
ctx,
projectID,
option.WithoutAuthentication(),
option.WithEndpoint(serverURL),
// bigquery-emulator接続時はtlsを無効にする。
option.WithGRPCDialOption(grpc.WithTransportCredentials(insecure.NewCredentials())),
)
if err != nil {
return nil, fmt.Errorf("failed to create new bq emulator client: %w", err)
}
return newWriteClient(c, projectID, datasetID), nil
}
}
上記のコードに記載の通り、bigquery-emulator接続時はtlsを無効にする必要がありました。
// bigquery-emulator接続時はtlsを無効にする。
option.WithGRPCDialOption(grpc.WithTransportCredentials(insecure.NewCredentials())),
ここで苦慮したのが、BigQuery Storage Write APIのどのストリームを使用して書き込みを行うかです。書き込み方法には下記の4種類があります。
- デフォルトタイプ: デフォルトの方法。書き込んだ情報をすぐに利用できる
- 保留タイプ: ストリームをcommitするまでレコードが保留状態になる方法。commit次第、保留中のデータを全て読み取ることができる
- コミットタイプ: ストリームにレコードを書き込み次第、レコードをすぐに読み取ることができる方法
- バッファタイプ: 行レベルでcommitが行われ、ストリームがフラッシュされるまでレコードがバッファされる方法。通常は使用しない
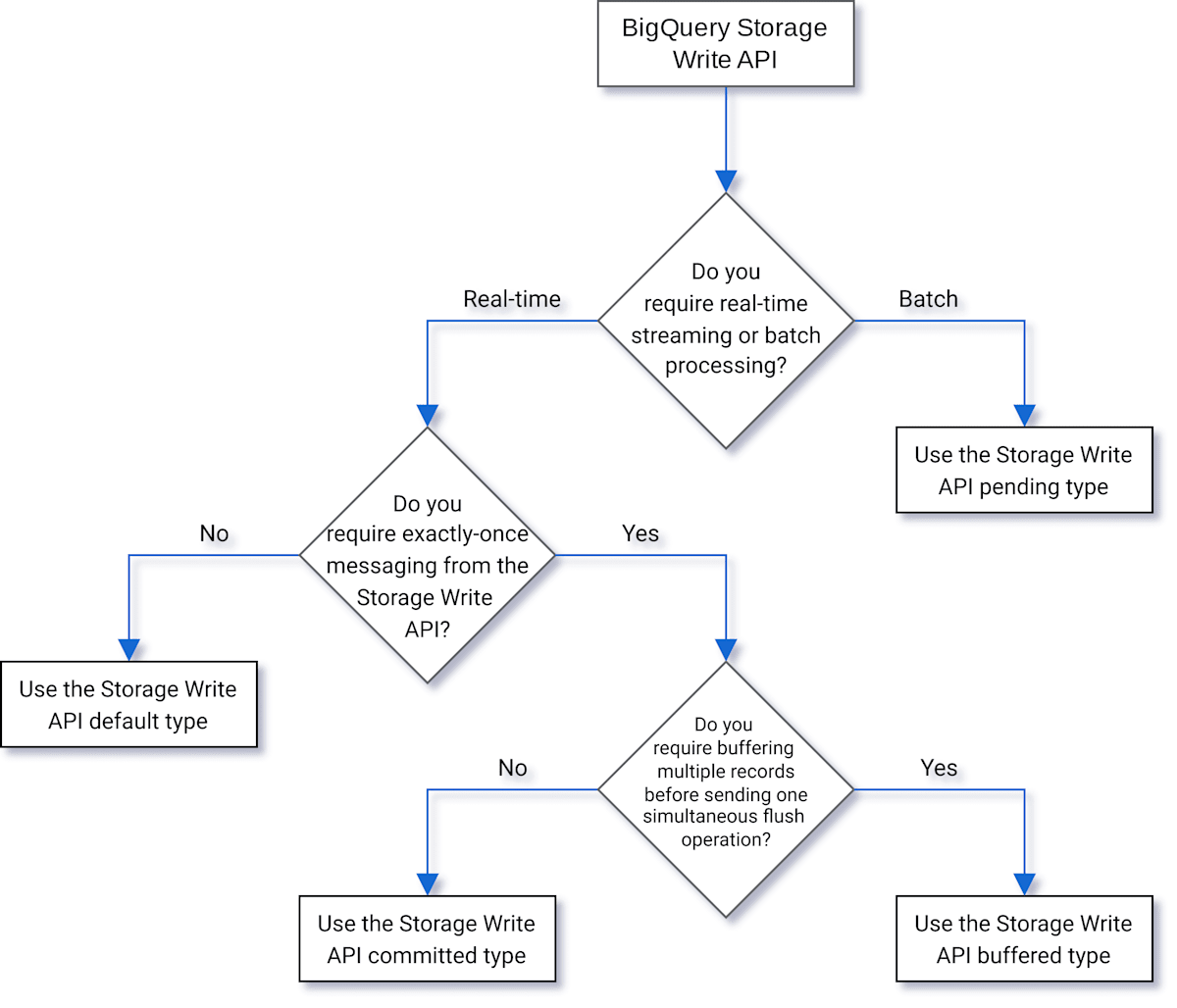
業務上は、上記のフローチャートから保留タイプが最適だと判断し、保留タイプのストリームを作成して書き込みを行いました。
pendingStream, err := wc.c.CreateWriteStream(ctx, &storagepb.CreateWriteStreamRequest{
Parent: tableName,
WriteStream: &storagepb.WriteStream{Type: storagepb.WriteStream_PENDING},
})
4. 開発環境と本番環境の出し分け
開発環境でbigquery-emulatorに、本番環境でBigQueryに接続するため、main.go内で環境変数により接続先を変える実装にしています。下記は開発環境かどうかでbigquery-emulatorに接続するかどうかを判定していますが、特定の場合に開発用のBigQueryに接続できるように条件を追加しても良いかもしれません。
var bqNewClientFunc NewClientFunc
var bqNewWriteClientFunc NewWriteClientFunc
// 接続先をbigquery-emulatorに
if IsDevelopment() {
// BigQuery REST APIクライアントの初期化
bqNewClientFunc = NewEmulatorClient(
"projectID",
"datasetID",
"http://bigquery-emulator:9050",
)
// BigQuery Storage Write APIクライアントの初期化
bqNewWriteClientFunc = bq.NewEmulatorWriter(
"projectID",
"datasetID",
"bigquery-emulator:9060",
)
bqClient := bqNewClientFunc(context.Background())
// bigquery-emulatorで対応していない関数をudfとして定義する。
CreateFunction(bqNewClientFunc)
// 接続先をBigQueryに
} else {
// BigQuery REST APIクライアントの初期化
bqNewClientFunc = NewClient("projectID", "datasetID")
// BigQuery Storage Write APIクライアントの初期化
bqNewWriteClientFunc = NewWriter("projectID", "datasetID")
}
また、開発向けに作成したNewEmulatorClient、NewEmulatorWriter の3つ目の引数でserverURLを指定しているのですが、これらはそれぞれ下記のように設定する必要がありました。
- http://bigquery-emulator:9050
- bigquery-emulator:9060
BigQuery REST APIとBigQuery Storage Write APIは、それぞれ使用しているプロトコルが異なるため、bigquery-emulatorではURLを変更する必要がありました。
- BigQuery REST API: RESTful HTTP
- BigQuery Storage Write API: gRPC
5. レコードの読み込み
レコードの読み込みはBigQuery REST APIを使用したため、下記のドキュメントのコードのようにクエリを定義し、パラメータを付与してReedメソッドを呼ぶという実装にしています。
q := client.Query(`
SELECT year, SUM(number) as num
FROM bigquery-public-data.usa_names.usa_1910_2013
WHERE name = @name
GROUP BY year
ORDER BY year
`)
q.Parameters = []bigquery.QueryParameter{
{Name: "name", Value: "William"},
}
it, err := q.Read(ctx)
if err != nil {
// TODO: Handle error.
}
6. レコードの書き込み
レコードの書き込みは、BigQuery Storage Write API用のクライアントを使用しています。実装箇所が多岐に渡り全て紹介することが難しいので、断片的に重要な部分を抜粋して紹介します。
下記は実際に使用しているコードを少し修正したものです。Addメソッドに渡される[]FooAdd をJSONに変換し、BigQuery Storage Write APIに書き込みを行うWriteBatchメソッドに値を渡すことで、書き込みを実現しています。
type FooAdd struct {
Foo string `json:"foo"`
}
func (repo *FooRepository) Add(ctx context.Context, data []FooAdd) error {
w, err := repo.w(ctx)
if err != nil {
return fmt.Errorf("failed to create write client: %w", err)
}
defer w.Close()
// JSONに変換
jsonData, err := ConvertToJSON(data)
if err != nil {
return fmt.Errorf("failed to convert to json: %w", err)
}
// BigQuery Storage Write APIを使用した書き込み処理
if err := w.WriteBatch(ctx, bq.FooSchema, bq.Foo, jsonData); err != nil {
return fmt.Errorf("failed to add: %w", err)
}
return nil
}
ConvertToJSONメソッドは、ジェネリクスを使用することで任意の構造体をJSONに変換します。
func ConvertToJSON[T any](values []T) ([][]byte, error) {
var jsonData [][]byte
for _, v := range values {
data, err := json.Marshal(v)
if err != nil {
return nil, fmt.Errorf("error marshalling json: %w", err)
}
jsonData = append(jsonData, data)
}
return jsonData, nil
}
WriteBatchメソッドは、BigQuery Storage Write APIを使用してデータを書き込むためのメソッドです。
func (wc *WriteClient) WriteBatch(ctx context.Context, schema bigquery.Schema, table Table, rows [][]byte) error {
md, descriptorProto, err := descriptor(schema)
if err != nil {
return fmt.Errorf("failed to make descriptor: %w", err)
}
// jsonをprotoに変換
pbRows, err := wc.convertJSONToProto(rows, md)
if err != nil {
return fmt.Errorf("failed to convert json to proto: %w", err)
}
tableName := managedwriter.TableParentFromParts(wc.projectID, wc.datasetID, string(table))
// クライアントから書き込み用のStreamを作成
pendingStream, err := wc.c.CreateWriteStream(ctx, &storagepb.CreateWriteStreamRequest{
Parent: tableName,
// bigquery-emulatorでも接続可能にするため保留タイプのStreamにしている
WriteStream: &storagepb.WriteStream{Type: storagepb.WriteStream_PENDING},
})
if err != nil {
return fmt.Errorf("CreateWriteStream: %w", err)
}
// クライアントからNewManagedStreamを呼び出し
ms, err := wc.c.NewManagedStream(
ctx,
managedwriter.WithStreamName(pendingStream.GetName()),
managedwriter.WithSchemaDescriptor(descriptorProto),
)
if err != nil {
return fmt.Errorf("failed to establish new managed stream: %w", err)
}
defer ms.Close()
// AppendRowsでデータを書き込む
result, err := ms.AppendRows(ctx, pbRows, managedwriter.WithOffset(0))
if err != nil {
return fmt.Errorf("failed to append rows: %w", err)
}
_, err = result.GetResult(ctx)
if err != nil {
return fmt.Errorf("failed to get result: %w", err)
}
// Streamの書き込みを完了させる
_, err = ms.Finalize(ctx)
if err != nil {
return fmt.Errorf("error during Finalize: %w", err)
}
// Streamの書き込みをコミット
req := &storagepb.BatchCommitWriteStreamsRequest{
Parent: managedwriter.TableParentFromStreamName(ms.StreamName()),
WriteStreams: []string{ms.StreamName()},
}
resp, err := wc.c.BatchCommitWriteStreams(ctx, req)
if err != nil {
return fmt.Errorf("client.BatchCommit: %w", err)
}
if len(resp.GetStreamErrors()) > 0 {
return fmt.Errorf("stream errors present: %v", resp.GetStreamErrors())
}
return nil
}
上記のコードでは保留タイプの書き込みを利用して結果をコミットしていますが、デフォルトタイプではもう少し簡略化できるかもしれません。
BigQuery Storage Write APIの書き込みは自前で実装する必要があり、主に下記のドキュメントを参考に実装を進めました。
また、自前で実装される際は、GitHub上でmanagedwriter、protobuf/proto等で検索し、公開されているコードを参考に実装してみても良いと思います。
- https://github.com/search?q=managedwriter&type=code
- https://github.com/search?q=protobuf%2Fproto&type=code
まとめ
BigQueryとGo言語を用いた開発環境の統合は、数多くの課題に直面しました。Analyticsチームで環境を構築し始めた当時、ベストプラクティス的な情報が少なく、暫定的な解決策を見つけるのに試行錯誤した記憶があります。Go言語でBigQueryを導入しようとしている皆さんの参考になれば幸いです。
また、この記事は、同じチームでBigQueryの設計・実装を担当した中村さんにも監修していただいています。BigQuery採用の経緯は下記の記事にも記載されていますので、あわせてご覧ください。
SocialDogについて
株式会社SocialDogは、「あらゆる人がSNSを活用できる世界を創る」をミッションとし、SNSマーケティング運用担当者のためのオールインワンツールを提供しています。
今後はX以外のSNSのデータも集め、より高度な分析機能を開発していきます。
超大規模なデータを使ったり、モダンな技術を取り入れながら新機能開発をしたいエンジニアを募集中ですので、興味があればぜひお話ししましょう!

Discussion