SocialDog Analyticsチームエンジニアの中村です。
SocialDog Analyticsチームでは主にSocialDogの分析機能の開発を行っています。
SocialDogでは新しく「投稿パフォーマンス」という分析機能をベータリリースしました!
この新しい分析機能では、 月間約7,000万行 のデータ増加が見込まれています。
このデータ基盤に、BigQueryを採用しました。この記事では次についてご紹介していきます。
- どのようにデータ基盤を検討したか
- なぜBigQueryを採用したか
- BigQueryを使う上で気をつけていること
前提
従来SocialDogではポスト(投稿)ごとに累計エンゲージメント数を表示していました。
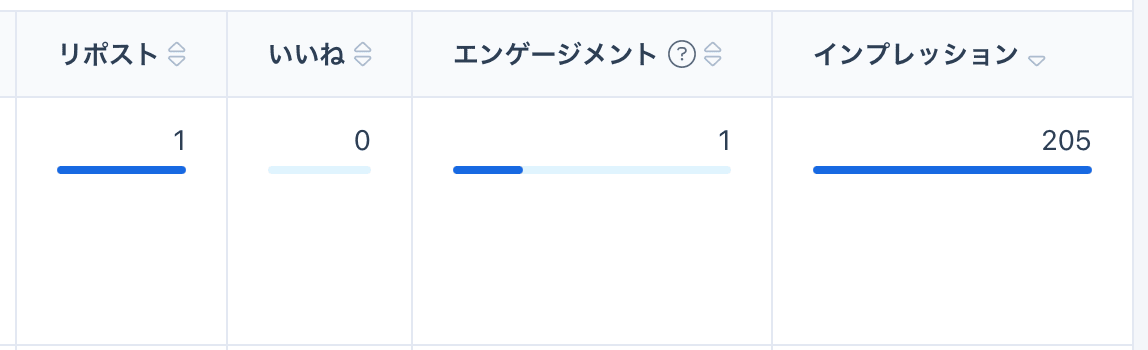
新しい分析機能では、昨年契約したX Enterprise APIを使って1時間単位でいいね、エンゲージメントなどのデータを取得できるようになりました!
そのAPIを使うことで「投稿パフォーマンス」では「時間」という軸でも分析できます。
「時間」軸も分析できるようになったので、必要なデータ量が爆発的に増加することになりました。
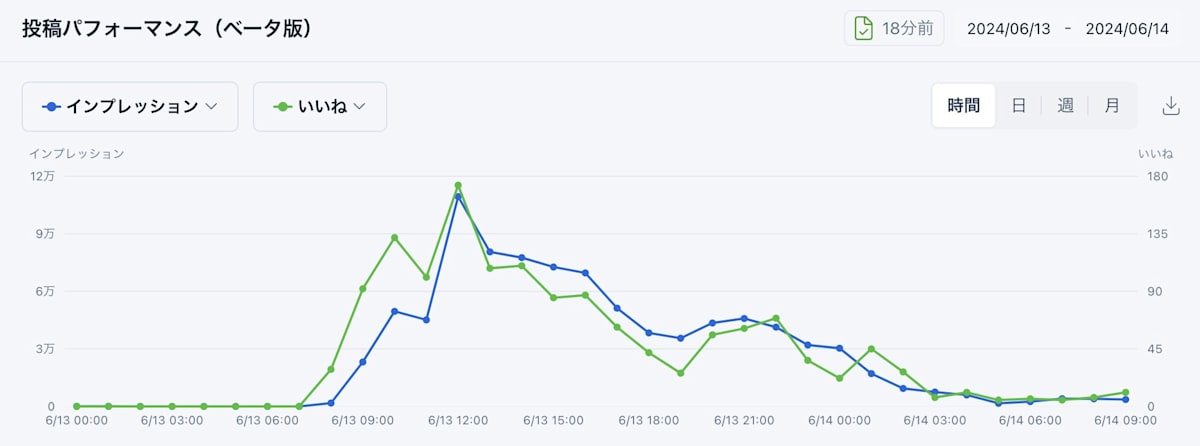
SocialDogの会員数や投稿などから月間の想定データ数を試算したところ、7000万行に達することが予想されました。
そこで、月間7000万行を保存することができるデータストアについて検討しました。
検討
今回の開発でデータストア関連の要件として上がったのは以下の点です。
- 今回作る仕組みは向こう5年ぐらいは使いたい。
- 柔軟で大量のデータを入れるスケーラブルさ、列の追加などの拡張性を持たせたい。
- SNSプラットフォームによる仕様変更に迅速に追従できるようにしたい。
- SNSプラットフォームを横断して複数のSNSアカウントの数値を分析できるようにしたい。
- 将来パフォーマンスの問題に悩まされないようにしたい。
上記の要件を満たすことのできるデータストアとして2つのサービスを検討しました。
- CloudSQL
- BigQuery
上記のデータストアで膨大なデータ量を現実的な時間で扱うために必要なことを検討し、それぞれのメリットとデメリットを出して検討を行いました。
表にしてまとめると以下のようになります。
| メリット | デメリット | |
|---|---|---|
| CloudSQL | ・使い慣れたCloudSQLを使うことができる。(学習コストが低い) ・開発環境の準備や利用料金も特別に検討することはない。 |
・列の追加がかなり難しい。 ・indexの貼られていない列でソートしたい時クエリが遅くなってしまう。 |
| BigQuery | ・パフォーマンスについて考えることが少ない。 ・可用性が高い。 ・今後機能追加する際に柔軟に対応できる。 |
・結果を表示するまでに時間がかかる。 ・学習コストがかかる。 ・予期しないコストが発生するリスクがある。 ・開発環境の準備どうしよう? |
今後のメンテナンスコストやパフォーマンスについて考えることが少なく、また新しい技術にも挑戦できるという理由でBigQueryを採用することに決定しました。
BigQueryを採用するにあたり不安に感じたこと
BigQueryを採用するにあたり、エンドユーザーが利用するサービスのデータストアにBigQueryを採用している事例を調査しましたが事例が見つかりませんでした。
個人的にも従量課金制のデータベースを不特定多数のユーザーが使うのはコストの観点で不安を感じていました。
協力会社様に相談したところ、コストの観点では ユーザー数とデータ量が反比例になるように設計する 、BigQueryは 「サービス(SocialDog)にデータウェアハウスがくっついている」構成だと考えればいい とアドバイスをいただき、不安を解消することができました!
システム構成図
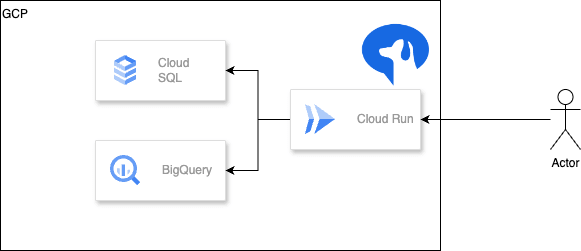
気をつけたこと
BigQueryを採用するにあたり上記のデメリットに関しては以下の対策を取るようにしました。
- パーティションとクラスタリングを適切に使う。
- パーティションフィルタを必須にする。
- BigQueryのjobIDをログ出力する。
- 開発環境はbigquery-emulatorを利用する。
パーティションとクラスタリングを適切に使う
-
パーティションとは、BigQueryのテーブルを特定の列の値を基準にして内部的にテーブルを分割する機能です。
BigQueryではフィルタに一致するパーティションがスキャンされ、残りのパーティションはスキップされます。 -
クラスタリングとは、BigQueryのテーブルの特定の列の値を基準にして並べ替えフィルタや集計のクエリを高速化する機能です。
クラスタ化列でフィルタや集計を行うクエリは、テーブルやテーブルパーティション全体ではなく、クラスタ化列に基づいて関連するブロックのみをスキャンします。 -
パーティションとクラスタリングをうまく使うと ユーザー数とデータ量が反比例になるように設計する ことが可能となります。
具体例を上げると、ユーザー・ポスト(投稿)をクラスタリング列にすることで、スキャンするブロックを関連するものだけに絞り込むことができ、パフォーマンスの向上とコストの削減ができます。
パーティションフィルタを必須にする
BigQueryでは実行したクエリの処理データ量に応じて課金されます。
パーティションフィルタを必須にすることで、where句でパーティションニングする列の条件を必須にすることができます。
where句でパーティショニング列の条件を入れ忘れてフルスキャンが走ることを防止することができます。
BigQueryのjobIDをログ出力する
クエリのパフォーマンスやスキャン量などを把握し改善に繋げるため、BigQueryのjobIDをログ出力するようにしました。
予期しないコストが発生した際にどのユーザーのクエリが原因であるかを特定することができます。
開発環境はbigquery-emulatorを利用する
実際に開発する時には、BigQueryの開発環境を準備するのに苦労しました。
開発環境に関してはbigquery-emulatorを利用して開発を行っています。
bigquery-emulatorは基本的なBigQueryの機能をエミュレートしてくれるのですが、すべての関数を網羅しているわけではなりません。
SocialDogでも本家BigQueryにしかない関数を使っている場所があるので、本家BigQueryの関数と同じインターフェースを持つuser-defined functionを簡単に実装して動作確認やテストを行っています。
Terraformの構成例
インフラはTerraformで管理しているので、上記の構成は以下のようになりました。
resource "google_bigquery_table" "table" {
dataset_id = "dataset_id"
table_id = "table"
clustering = ["x_id", "user_id"] # <-- クラスタリングの設定
require_partition_filter = true # <-- パーティションフィルタを必須にする
time_partitioning {
type = "DAY"
field = "datetime"
}
schema = <<EOF
[
{
"name": "x_id",
"type": "INTEGER",
"mode": "REQUIRED"
},
{
"name": "user_id",
"type": "INTEGER",
"mode": "REQUIRED"
},
{
"name": "datetime",
"type": "TIMESTAMP",
"mode": "REQUIRED"
}
]
EOF
}
その後
投稿パフォーマンス機能はベータリリースして約1か月たっています。
現在(2024年6月末)はBigQueryに1億行のデータが保存されています。
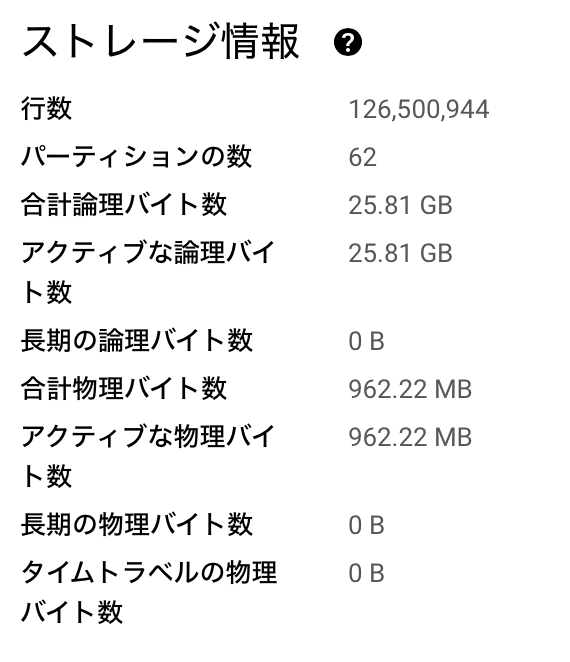
1億行から目的のデータを平均0.9秒で取得しておりとてもパフォーマンスがいいです。
SocialDogについて
株式会社SocialDogは、「あらゆる人がSNSを活用できる世界を創る」をミッションとし、SNSマーケティング運用担当者のためのオールインワンツールを提供しています。
今後はX以外のSNSのデータも集め、より高度な分析機能を開発していきます。
超大規模なデータを使ったり、モダンな技術を取り入れながら新機能開発をしたいエンジニアを募集中ですので、興味があればぜひお話ししましょう!

Discussion