はじめに
前回の記事ではDeepgramのSpeech-to-Text機能を使って文字起こしをしてみました。
今回は同じSpeech-to-Text機能のオプションを使って話者分離を試してみます。
話者分離機能の利用
話者分離機能を利用するため、前回の記事で使用したコードのPrerecordedOptionsにdiarizeとutterancesの2つのオプションを追加します。
話者分離だけであればdiarizeで足りますが、話者分離したうえで話者の発話ごとにレスポンスをまとめるためにutterancesも指定しています。
import os
import time
from dotenv import load_dotenv
from deepgram import (
DeepgramClient,
PrerecordedOptions,
FileSource,
)
load_dotenv()
audio_file_path = os.getenv("AUDIO_FILE_PATH")
api_key = os.getenv("DEEPGRAM_API_KEY")
def main():
try:
deepgram_client = DeepgramClient(api_key)
with open(audio_file_path, "rb") as file:
buffer_data = file.read()
payload: FileSource = {
"buffer": buffer_data,
}
# Deepgramのオプションを設定
options = PrerecordedOptions(
model="nova-2-general",
detect_language=True,
diarize=True,
utterances=True,
)
start_time = time.perf_counter()
# 結果を取得
response = deepgram_client.listen.prerecorded.v("1").transcribe_file(payload, options)
end_time = time.perf_counter()
for u in response.results.utterances:
print(f"[Speaker: {u.speaker}] {u.transcript}")
run_time = end_time - start_time
print(f"実行時間: {run_time:.2f}秒")
except Exception as e:
print(f"Exception: {e}")
if __name__ == "__main__":
main()
実行結果
[Speaker:X]のラベルをつけて話者を区別しています。
音声自体は読み取れていない箇所もところどころありますが、話者分離は概ね出来ていそうです。
[Speaker: 0] l o ok s c ol or sh の 終わり です
[Speaker: 1] お 忙しい ところを それ い ります こちらは z 株式会社 の a と申します
[Speaker: 1] 今日は 新しい ai を利用した 顧客 管理 ツール について ご案内 を させて いただき ご 連絡 を させていただきました し 最近 そういった 色 目 が多い
[Speaker: 0] んですよ すでに 老 齢 を提供 中止 して もありますし
[Speaker: 1] なるほど そう でした か じゃあ
[Speaker: 1] 今回は
[Speaker: 1] 新しい 多くの 企業 様に ai ツール の ご 導入 が 進んで いますね ただ 弊社 の ツール は 一般的な c r m とは 一 線を 画 していて 従来 の c r m システム では 難しかった ディー プラ ー ニング による 高度 の 顧客 分析 を 可能 に しております。
[Speaker: 1] 例えば お客様 の 購 買 履歴 だけでなく
[Speaker: 1] お客様 の サポート 履歴 や お問い合わせ 履歴 も 組み合わせて 次の アクション を ai が 提案 する 機能 など 非常に 高度 な サポート が可能 です。
[Speaker: 0] そう なんですね。
---以下略---
その他のオプション
| オプション | 概要 | デフォルト値 | 言語 |
|---|---|---|---|
| smart_format | トランスクリプトに追加の書式設定を適用して、人間が読みやすいように最適化します | false | すべて |
| punctuate | 句読点を有効にします | false | すべて |
| replace | 単語やフレーズを検索し置換します | なし | すべて |
smart_formatを指定するとaiやcrmなどの単語が大文字になりましたが、他には目立つ変化はありませんでした。また、punctuateに関してはほとんど変化はありませんでした。
[Speaker: 0] L o ok s C ol or sh A re sh の 終わり です
[Speaker: 1] お 忙しい ところを それ い ります こちらは Z 株式会社 の A と申します
[Speaker: 1] 今日は 新しい AI を利用した 顧客 管理 ツール について ご案内 を させて いただき ご 連絡 を させていただきました し 最近 そういった ユーロ円 が多い
[Speaker: 0] んですよ すでに 労 力 検査 中止 でもあります
[Speaker: 1] し
[Speaker: 1] なるほど そう でした か じゃあ
[Speaker: 1] 今回は
[Speaker: 1] 新しい 多くの 企業 様に AI ツール の ご 導入 が 進んで いますね ただ 弊社 の ツール は 一般的な CRM とは 一 線を 画 していて 従来 の CRM システム では 難しかった ディー プラ ー ニング による 高度 の 顧客 分析 を 可能 に しております。
[Speaker: 1] 例えば お客様 の 購 買 履歴 だけでなく
[Speaker: 1] お客様 の サポート 履歴 や お問い合わせ 履歴 も 組み合わせて 次の アクション を AI が 提案 する 機能 など 非常に 高度 な サポート が可能 です。
--- 以下略 ---
他にもIntelligence機能として
- Sentiment Analysis(感情分析)
- Topic Detection(トピックの検出)
- Summarization(要約)
などがありますが、現在は英語のみ対応しているようです(2024/02/12時点)
Speech-to-Textで利用可能なモデル
Speech-to-Textでは今回利用したnova2以外にもいくつかのモデルが指定できます。
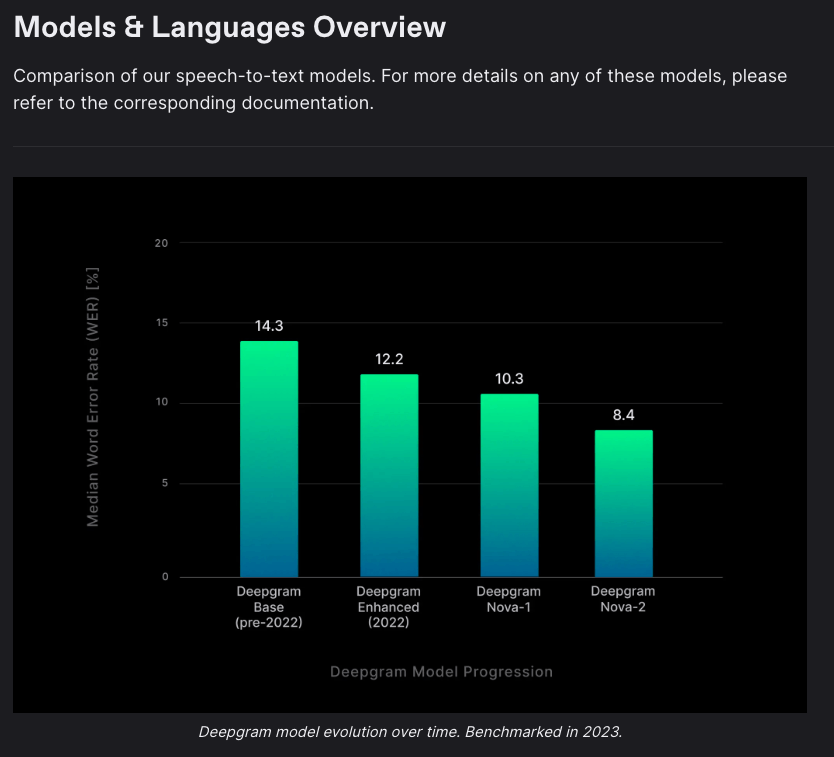
より上位のモデルであるenhancedを利用してみましたが、実行結果はほぼ変化がありませんでした。残念。
Deepgram Whisper Cloud
Deepgramの独自モデルとは別に、Deepgram上にホスティングされているWhiperのモデルを利用することもできます。これによってOpenAIのSpeech to text APIには無い話者分離などの機能をWhisperと組合せて利用することができます。
ただしライブストリーミングに対応していなかったり他のDeepgramモデルよりもスケーラビリティが低い等の欠点もあるため、利用時は注意が必要です。
なおwhisperモデルも複数のモデルから選択することが出来ます。
以下はwhisper-largeを利用した結果です。
[Speaker: 0] X 株 式 会 社 の Y です
[Speaker: 1] お 忙 しい ところ 恐 れ 入 ります こ ちら は Z 株 式 会 社 の A と 申 します
[Speaker: 0] はい 、 どう い った ご 用 件 でしょう か
[Speaker: 0] 今日は 新 しい AI を 利 用 した 顧 客 管 理 ツ ール に つ いて ご 案 内 を さ せて いただ きた く ご 連 絡 を さ せて いただ き ました う ーん 正 直 最近 そう い った エ イ ル ノ ウ デ ー は 多 い んです よ す で に 導 入 検 討 シ ス テ ム も あります し
[Speaker: 1] なるほど そう でした か
[Speaker: 1] 今回 は
[Speaker: 1] 多 く の 企 業 様 に AI ツ ール の ご 導 入 が 進 んで います ね た だ 弊 社 の ツ ール は 一 般 的 な CR M と は 一 線 を 隠 して いて 従 来 の CR M シ ス テ ム では 難 し かった デ ィ ープ ラ ーニ ング に よ る 高 度 の 顧 客 分 析 を 可能 に して お ります
[Speaker: 1] 例えば お 客 様 の 購 買 履 歴 だけ で なく お 客 様 の サ ポ ート 履 歴 や お 問 い 合 わ せ 取 り 入 れ 機 も 組 み 合 わ せて 次 の ア ク ショ ン を AI が 提 案 する 機 能 な ど 非常 に 高 度 な サ ポ ート が 可能 です
--- 以下略 ---
かなり認識精度が上がっていそうです!
ただ今回試した限りでは5分ほどの音声に対して処理時間が70〜80秒ほど(長い時はまれに300秒以上)かかってしまいました。
※他の方が試した際は平均して20秒以下に収まっていたようなので、処理時間にはかなりムラがありそうです
その結果、元のコードだと実行時にタイムアウトするようになってしまったため、APIの呼び出し時にtimeoutオプションを指定しています。
- response = deepgram_client.listen.prerecorded.v("1").transcribe_file(payload, options)
+ response = deepgram_client.listen.prerecorded.v("1").transcribe_file(payload, options, timeout=300)
上記はこちらを参考にしました。
まとめ
Deepgramで話者分離などのオプションを試してみました。
5分ほどの音声であれば10秒かからずに話者分離まで出来るのはかなり速いですね。商談等で話した後にその内容を確認してまとめたい場合など、特定のユースケースでは十分に利用できそうに感じました。
ただ要約やトピックの検出などの主要な機能のいくつかが日本語には対応しておらず、今後のアップデートに期待したいところです。
プランによっては自分でファインチューニングしたモデルを利用できるようなので、より精度を求める場合はDeepgram社に問い合わせてみると良いかもしれません。
また、前回と今回の記事ではPythonのSDKを利用して検証しましたが、DeepgramにはGUI上で検証できるPlayGroundも用意されています。
基本的な機能や精度の確認はこちらを利用するほうが手軽にできると思います。
今回は認識精度のスコアリングやコストの試算などは行っていませんが、もし機会があればそれらを他の主要な競合サービスや自前で実装した場合と比較してみるのも良さそうですね。
今回は以上です。

Discussion