高速・高精度なASR(自動音声認識)サービスを提供するDeepgramというサービスがあると噂を聞いたので試してみました。
Deepgramとは
Deepgramは2015年に設立されたアメリカのスタートアップ企業です。
AIを用いた企業向けの音声認識に特化しており、スタートアップからSpotifyやNASAのような大企業まで多数のクライアントにサービスを提供しています。
公式サイトによると主な競合他社に比べて速度・精度・コストのいずれも優れており、更に日本語を含む30カ国以上の言語に対応しているとのことです。
主なプロダクトは以下の3つです。
今回はSpeech-to-Text(以下、STT) APIを利用してみたいと思います。
STT APIの機能
STT APIには多くの機能がありますが、よく使いそうなものをピックアップしてみます。
-
Diarization
- 話者分離。トランスクリプト内の各単語に話者を割り当てます
-
Find and Replace
- 送信された音声内の用語や語句を検索し、置換します
-
Keyword
- 特殊な用語や一般的ではない固有名詞を含む音声を文字起こしする場合、それらの単語をモデルに提供して、可能な予測として組み込むことができます
-
Topic Detection(英語のみ)
- トランスクリプト内の主要なトピックを特定し、テキスト セグメントと各セグメント内で見つかったトピックのリストを返します
その他の機能のうち、一部の機能については現在は英語のみの対応となっているようです。
例えばFiller words (つなぎ言葉: えーっと、うーん、など)は英語のみ対応となっています。
モデル
音声認識のモデルは複数用意されており、Deepgram上のクラウドにホストされたフルマネージドのWhisperモデルを利用することもできます。(ただし他のモデルに比べてスケーラビリティが低く、応答速度も遅いようです)
また、Enterpriseプランに限られますがトレーニング済みのモデル(Custom)を利用することもできます。
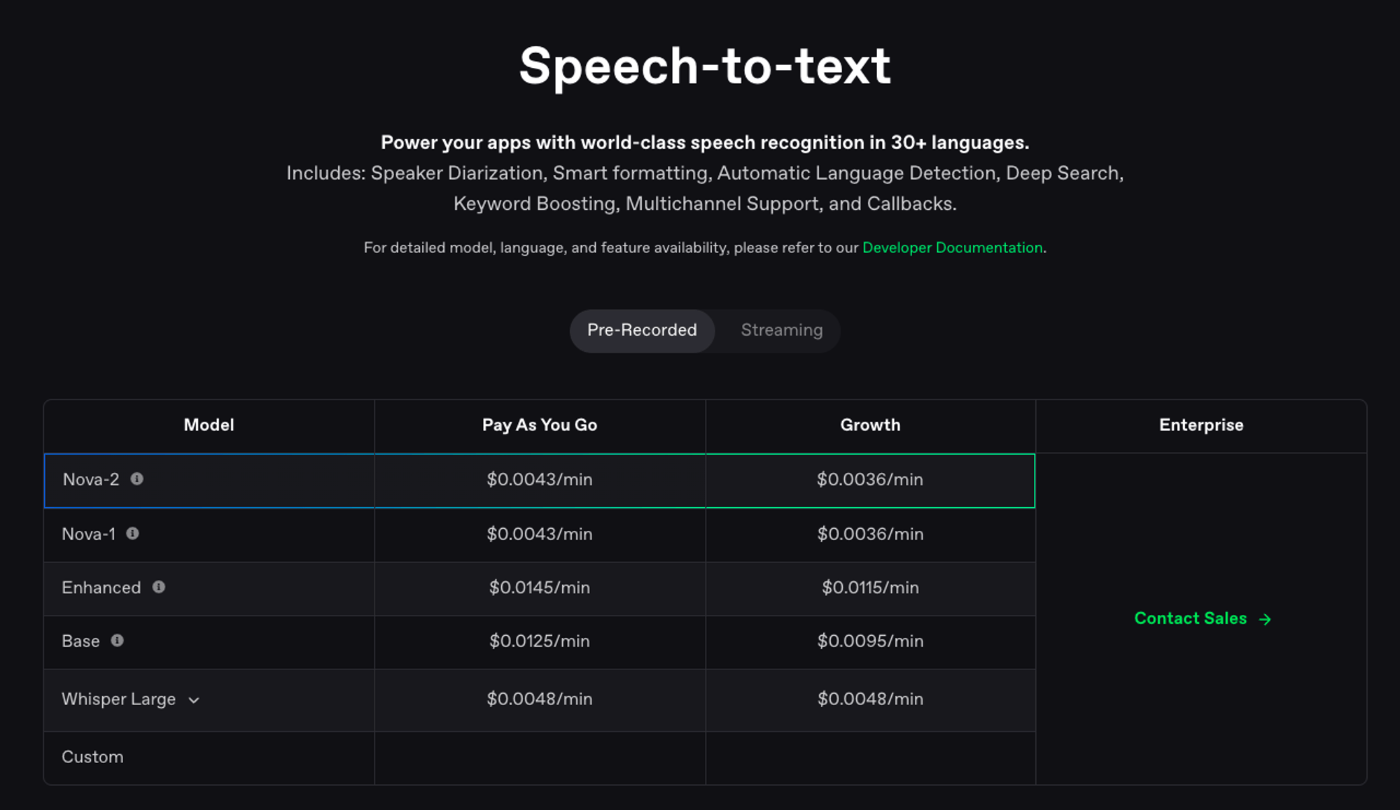
DeepgramではFreeプランにSignupすると自動的に$200のクレジットが追加されるので、検証目的であれば十分に試せそうです。
APIを使ってみる
それでは日本語の音声ファイルを使って速度や精度の検証をしたいと思います。
デモ用の音声データについて
今回用意したデータは「インサイドセールスの担当者が見込み客に電話をかけた」という想定で2人の人間が5分間ほど会話し、その内容を録音したものです。
台本から冒頭のみ抜粋すると以下のような内容です。
営業先「XX株式会社のYYです。」
セールス「お忙しいところ恐れ入ります。こちらはZZ株式会社のAAと申します。」
セールス「今日は新しいAIを利用した顧客管理ツールについてご案内させていただきたく、ご連絡をさせていただきました。」
営業先「うーん、正直、最近そういった営業のお電話多いんですよ。既に導入を検討しているシステムもありますし」
セールス「なるほど、そうでしたか。最近は多くの企業様にAIツールのご導入が進んでいますね。ただ、弊社のツールは、一般的なCRMとは一線を画していて、従来のCRMシステムでは難しかったディープラーニングによる高度な顧客分析を可能にしております。」
・・・以下略(会話が続く)・・・
このデータをローカルからDeepgramのAPIに送信して文字起こしします。
手順
APIの利用については以下のドキュメントを参考にしました。
ユーザー登録後、ダッシュボードにログインし「API Keys」の画面を開きます。
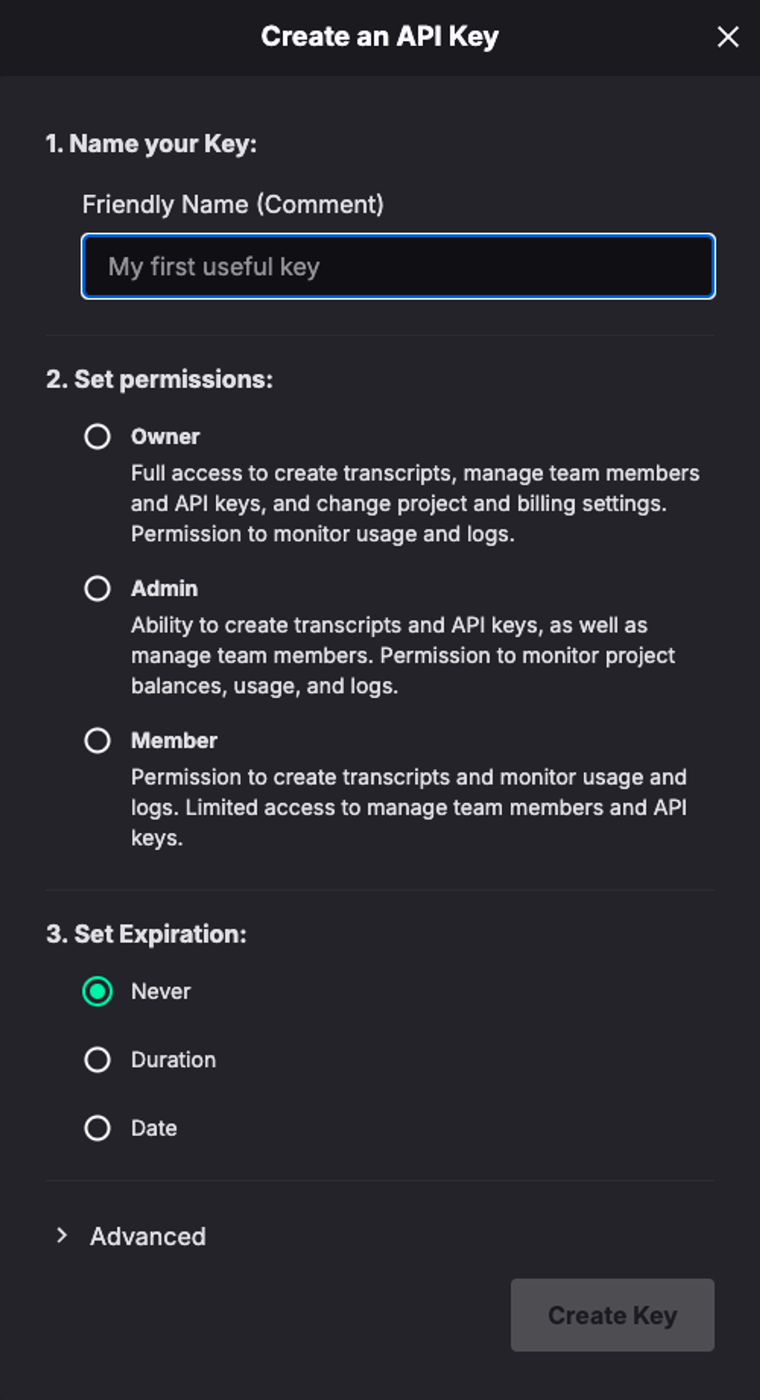
「Create a API Key」を押してAPI Keyを作ります。今回はAPIを利用するだけなのでpermissionはMemberにしました。
それでは実行してみます。
ドキュメントにはcurlでのサンプルもありますが、今回はこちらのPython SDKを利用しました。
import os
import time
from dotenv import load_dotenv
from deepgram import (
DeepgramClient,
PrerecordedOptions,
FileSource,
)
load_dotenv()
audio_file_path = os.getenv("AUDIO_FILE_PATH")
api_key = os.getenv("DEEPGRAM_API_KEY")
def main():
try:
deepgram_client = DeepgramClient(api_key)
with open(audio_file_path, "rb") as file:
buffer_data = file.read()
payload: FileSource = {
"buffer": buffer_data,
}
# Deepgramのオプションを設定
options = PrerecordedOptions(
model="nova-2-general",
detect_language=True,
)
start_time = time.perf_counter()
# 結果を取得
response = deepgram_client.listen.prerecorded.v("1").transcribe_file(payload, options)
end_time = time.perf_counter()
print(response.results.channels[0].alternatives[0].transcript)
run_time = end_time - start_time
print(f"実行時間: {run_time:.2f}秒")
except Exception as e:
print(f"Exception: {e}")
if __name__ == "__main__":
main()
ソースはこちらを参考に作成しています。
ローカルのデモ用の音声データの場所とDeepgramのAPI Keyは.envから取得しています。
なおモデルを指定する際、model=nova-2-optionのようにモデル名の後にモデルオプションを指定することができます。
デモ用の音声データは電話音声のため、本来は低帯域幅の音声通話用に最適化されたモデルオプション(phonecall)を指定したいところですが、まだ日本語には対応していないためgeneralを利用しています。
また、language_detect=Trueを指定して自動的に言語を検知させています。
結果
出力結果は以下のような形になりました。
話者分離や句読点などの細かなチューニングをしていないため相当見づらいですが、文脈が分かれば内容は理解出来るレベルです。
l o ok s c ol or sh の 終わり です お 忙しい ところを それ い ります こちらは z 株式会社 の a と申します 今日は 新しい ai を利用した 顧客 管理 ツール について ご案内 を させて いただき ご 連絡 を させていただきました し 最近 そういった いう の が多い んですよ すでに 老 齢 を提供 中止 して もありますし なるほど そう でした か じゃあ 今回は 新しい 多くの 企業 様に ai ツール の ご 導入 が 進んで いますね ただ 弊社 の ツール は 一般的な c r m とは 一 線を 画 していて 従来 の c r m システム では 難しかった ディー プラ ー ニング による 高度 の 顧客 分析 を 可能 に しております。
・・・以下略・・・
また、APIのレスポンスが返ってくるまでの時間ですが、何度か実行したところ平均して3秒程度でした。
これは想像以上に速くて驚きました!
まとめ
今回はDeepgramのSpeech-to-Textを試してみました。
速度に関しては同じデータをOpenAIのWhisperで試したところ18秒前後かかっていたので、それと比較すると相当速いですね。
見込み客に電話をした本人がログを確認する場合などのように、ユースケースによっては「精度はそこそこで良いので速く文字起こしされたものが欲しい」というケースもあると思うので、そのようなケースでは利用に耐えられそうです。
また、別のモデルを使用すれば違う結果になるかもしれませんので、話者分離などと合わせて次回以降の記事で試してみようと思います。
次回以降の予定
- 話者分離を試す
- 他のモデルやオプションを試す
- OpenAIのWhisperなど競合サービスと精度・速度を比較する
続く

Discussion