GopherがRust入門したので違いをまとめてみた
はじめに
ウホウホ。
Rustを使い始めてちょうど2年くらい経って、すこしRustのことがわかってきたので、改めてGoとRustのそれぞれの違いを整理したいなと思いこの記事を書きました。
筆者はウェブ開発の経験しかないので、ウェブを中心にまとめています。
気づいたらかなりな量になってしまったのとGopher向けにRustを紹介するような記事になってしまいましたが、よければ読んでみてください。
筆者について
Goを使い始めて7年ほど経っていて、これまでCLI/TUIツールをいくつか作ってきました。
スペシャリストではないですが、プロダクトでGoを書く分には特に問題ないレベルかなと思います。
Rustは2022年夏ころから使い始めてちょうど2年ほど経ちました。
なにかツールを作ったわけではないですが、勉強がてらにいくつか作ったもの・書いた本があります。
普通にRustを書く分には問題ないですが、設計やプロダクト経験はまだ浅いというレベル感です。
初心者を抜けたといった感じでしょうか。
言語仕様
Goの言語仕様は他の言語と比べてシンプルといわれています。
自分は他の言語の仕様書を読んだことがないのですが、1ページにまとめられているくらいなのでおそらくそのとおりかなと思っています。
Goはシンプル・イズ・ベストを地で行くような言語で、仕様もそうですが構文や変数の命名規則からもそれが伺えます。
これは、大規模なシステム開発でもスケールするように言語の利便性よりも安全性と信頼性を重視しているからです。
より詳細はGo at Google: Language Design in the Service of Software Engineeringを参照してください。
Rustの場合は正式な言語仕様書はまだなく、最近仕様書を書くチームが発足して取り掛かり始めたところです。
2024/07/20時点ではまだ執筆が開始されていないようでした。
ただ、The Rust Referenceというものがあり、一応こちらでシンタックスなど色々と確認できます。
Rustの仕様はGoと比べて複雑です。
その複雑さの要因として、主に次があるかなと思っています。
- 所有権・ライフタイムによるGCなしでメモリ安全
- 非同期処理
- マルチパラダイム
Rustはユーザがメモリをalloc/freeする必要がなく、その代わりに所有権とライフタイムでメモリ安全を実現しています。[1]
この所有権とライフタイムは非同期処理と絡み合うとさらに複雑になります。
また、Rustは手続き型プログラミング・関数型プログラミング・オブジェクト指向ができるマルチパラダイムなプログラミング言語です。
柔軟性が高いため、設計や実装がしやすい部分もありますが、ゆえに理解すべき概念や覚えることが多くGoと比べて学習コストが高いです。
ドキュメントなどに明記はされていないんですが、上記の側面とRustを使っている感触として、Goとは違ったアプローチで安全性と信頼性、利便性を重視している印象があります。
特に安全性と信頼性をすごく意識している感覚があります。
少し例を紹介していきます。
所有権
Goでは次のコードは有効ですが、Rustで同じことをやろうとするとコンパイルエラーになります。
func main() {
v1 := "apple"
v2 := v1
fmt.Println(v1, v2) // apple apple
}
fn main() {
let v1 = "apple".to_string();
let v2 = v1;
println!("{} {}", v1, v2);
}
エラー内容
$ cargo run
Compiling anyhow v1.0.75
Compiling hello v0.1.0 (/Users/skanehira/dev/github.com/skanehira/sandbox/rust/hello)
error[E0382]: borrow of moved value: `v1`
--> src/main.rs:4:23
|
2 | let v1 = "apple".to_string();
| -- move occurs because `v1` has type `String`, which does not implement the `Copy` trait
3 | let v2 = v1;
| -- value moved here
4 | println!("{} {}", v1, v2);
| ^^ value borrowed here after move
Rustの場合、v1は"apple"を所有してるが、v2に代入すると"apple"の所有権がv2に移ることになります。
それ以降、v1は"apple"を持っていないので、v1を出力しようとするとvalue borrowed here after moveというコンパイルエラーになるという感じです。
この問題を回避するためにはclone()を使って、値をコピーすればよいです。
動きの違いとしては、Goは代入時にコピーが発生するが、Rustは代入時コピーではなく値が移動する感じですね。[2]
let v1 = "apple".to_string();
let v2 = v1.clone();
ライフタイム
GoとRustは値への参照を取ることができて、この参照にはライフタイムが存在します。
ライフタイムとは参照が有効になるスコープのことです。つまり生存期間ということですね。
Goの場合、参照はどこからも使われなくなったら次のGCのタイミングでメモリから消されますが、それまでは生存します。
RustはGCがない代わりに、確保した値と参照はスコープを抜けるとメモリから消されます。
たとえばGoでは次のコードは有効ですが、Rustで同じことをやろうとするとコンパイルエラーになります。
func main() {
var r *int
{
x := 5
r = &x
}
fmt.Printf("f: %s", *r) // f: 5
}
fn main() {
let r;
{
let x = 5;
r = &x;
}
println!("r: {}", r);
}
エラー内容
$ cargo run
Compiling hello v0.1.0 (/Users/skanehira/dev/github.com/skanehira/sandbox/rust/hello)
error[E0597]: `x` does not live long enough
--> src/main.rs:5:13
|
4 | let x = 5;
| - binding `x` declared here
5 | r = &x;
| ^^ borrowed value does not live long enough
6 | }
| - `x` dropped here while still borrowed
7 | println!("r: {}", r);
| - borrow later used here
Goの場合は特に参照のスコープを意識する必要はないですが、Rustではxへの参照はブロックスコープ{}を抜けると消されます。
x自体は{}内でしか生存できないので、xへの参照もスコープ外からは扱えないのは自然だなと思います。
もう1つの例として、ぱっと見大丈夫そうにみえる次のコードもcreates a temporary value which is freed while still in useというコンパイルエラーになり通らないです。
fn main() {
let s = String::new().trim();
println!("{}", s);
}
上記のコードは次のコードと等価です。
trim()は参照型&strを返すのですが、その参照元がtmpなので、tmpよりも長生きはできないからですね。
let s = {
let tmp = String::new();
trim(tmp)
}
ライフタイムパラメータ
Rustはすべての参照にはライフタイムがあり、それらをコンパイラがよしなに推論してくれます。
しかし推論ができないケースも存在します。
たとえば、次のコードでは参照のライフタイムを推論できないです。
fn longest(x: &str, y: &str) -> &str {
if x.len() > y.len() {
x
} else {
y
}
}
--> src/main.rs:9:33
|
9 | fn longest(x: &str, y: &str) -> &str {
| ---- ---- ^ expected named lifetime parameter
これはライフタイム推論の仕組み上仕方ないので、
こうった場合はライフタイムパラメータ('から始まるもの)を使って、コンパイラにライフタイムを教えてあげることで回避できます。
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() {
x
} else {
y
}
}
ライフタイム推論のルールがいくつかあるので、詳細について知りたい方は次の記事を参照してください。
構文
Goの構文はとてもシンプルなので、できることは多くないです。
それによって、主に次のような利点があるかなと思います。
- 誰が書いてもおおよそ同じ書き方に収束する
- 覚えることが少ない
- 読みやすい
こういった利点があるので、何かしらプログラミング言語経験していれば入門しやすく、システムと開発体制がスケールしやすいと思っています。
一方RustはGoと比べてできることが多く、覚えることも多いです。
たとえば繰り返し処理を書く場合、Goはforしかないんですが、Rustではforとwhileとloopの3つの選択肢があります。
それぞれ利用する場面が異なるので、それらを意識して使い分ける必要があります。
ただ、できることが多いということはそれだけ場面に応じて適切な処理をかける柔軟性があるということでもあります。
こういった側面からも、RustはGoと比べて利便性を重視する割合が大きいかなと印象があります。
いくつかの構文の違いについて、少し具体例を紹介していきます。
変数の可変・不変性
Goでは定義した変数は常に可変ですが、Rustではmutキーワードを使って変数の可変性を制御できます。
変更したいときだけmutをつけることで、コードを読む際に脳への負担が減ります。
x := "hello"
// 常に可変なので変更できる
x = "world"
let x = "hello";
// 不変なので変更できない
// output: cannot assign twice to immutable variable `x` cannot assign twice to immutable variable
x = "world";
let mut x = "hello";
// 可変なので変更できる
x = "world";
変数にmutをつけた場合、mut Tという型になりmutをつけないTとは別型になります。
この仕様のよいところは、不変・可変のときのみ使えるメソッドをそれぞれ定義できるところです。
#[derive(Default)]
struct User {
first_name: String,
last_name: String,
}
impl User {
// メソッドの実装
pub fn full_name(&self) -> String {
self.first_name.clone() + &self.last_name
}
pub fn change_first_name(&mut self, name: String) {
self.first_name = name;
}
}
fn main() {
let user = User::default();
// 不変なので`full_name()`を呼べる
user.full_name();
// エラー: cannot borrow `user` as mutable, as it is not declared as mutable
// user.change_first_name("new nick name".into());
let mut user = user;
// 可変なので`change_first_name()`を呼べる
user.change_first_name("new nick name".into());
}
ちなみに、Goでは未使用の変数がある場合コンパイルエラーになりますが、Rustでは警告は出てコンパイルがとおります。
好みの分かれるところではありますが、コンパイル速度とコードの保守性を考えるとコンパイルを通さない仕様のがよいかなと思っています。
パターンマッチ
Rustではパターンマッチという構文があります。
見た目はGoのswitchに似ていますが、matchは式なので値を返すことができます。
enum Coin {
Penny,
Nickel,
Dime,
Quarter,
}
fn value_in_cents(coin: Coin) -> u32 {
match coin {
Coin::Penny => 1,
Coin::Nickel => 5,
Coin::Dime => 10,
Coin::Quarter => 25,
}
}
Goの場合似たようなことをやろうとするとswitch文を使うことになります。
type Coin int
const (
Penny Coin = iota + 1
Nickel
Dime
Quarter
)
func valueInCents(coin Coin) int {
switch coin {
case Penny:
return 1
case Nickel:
return 5
case Dime:
return 10
case Quarter:
return 25
default:
return 0
}
}
Goのswitchと比べてRustのmatchはより柔軟で、たとえば範囲マッチできたりします。
他にいろんなパターンの書き方があるので、詳細を知りたい方はこちらを参照してください。
let x = 9;
let message = match x {
0 | 1 => "not many", // 0 または 1
2 ..= 9 => "a few", // 2 ~ 9 まで
_ => "lots" // それ以外
};
match式は表現力があって柔軟に書けるので、お気に入りの構文の1つです。
Goにもぜひmatchほしいところですね。
if式
Goではifは文ですが、Rustはifは式になっていて値を返すことができます。
if式を使うことで三項演算と同等なことができるのでGoのif文と比べて便利です。
var value string
if condition {
value = "true_value"
} else {
value = "false_value"
}
let value = if condition {
"true_value"
} else {
"false_value"
};
クロージャー
RustはGoと同じくクロージャーをかけます。
次の例もの見た目もGoとさほど変わらないです。
fn main() {
let echo = |name| {
println!("hello {}", name);
};
echo("gorilla");
echo("godzilla");
}
func main() {
echo := func(name string) {
fmt.Printf("hello, %s!\n", name)
}
echo("gorilla")
echo("godzilla")
}
GoとRustのクロージャーの大きな違いとして、Rustのクロージャーは次の3種類あります。
上記の例ではechoはFnになります。
- Fn
- FnOnce
- FnMut
これは実装によってコンパイラが自動的にクロージャーの型を決定します。
クロージャーをそのまま呼び出すだけなら特に意識することはないと思いますが、引数に受け取るとき関数を定義するときに意識する必要があります。
たとえば次の例ではchange_vはFnMutになります。
これは可変なvを変更しているからです。
しかし、change_vを受け取る関数を定義する際の型はFnだとコンパイルエラーになります。
fn call_closure(f: impl Fn()) {
f();
}
fn main() {
let mut v = "value".to_string();
let change_v = || {
v = "new value".to_string();
};
call_closure(change_v);
println!("{}", v);
}
エラー
$ cargo run
Compiling hello v0.1.0 (/Users/skanehira/dev/github.com/skanehira/sandbox/rust/hello)
error[E0525]: expected a closure that implements the `Fn` trait, but this closure only implements `FnMut`
--> src/main.rs:7:20
|
7 | let change_v = || {
| ^^ this closure implements `FnMut`, not `Fn`
8 | v = "new value".to_string();
| - closure is `FnMut` because it mutates the variable `v` here
...
11 | call_closure(change_v);
| ------------ -------- the requirement to implement `Fn` derives from here
| |
| required by a bound introduced by this call
|
note: required by a bound in `call_closure`
--> src/main.rs:1:25
|
1 | fn call_closure(f: impl Fn()) {
| ^^^^ required by this bound in `call_closure`
この場合は次のように修正します。
diff --git a/hello/src/main.rs b/hello/src/main.rs
index f0e568b..595b50f 100644
--- a/hello/src/main.rs
+++ b/hello/src/main.rs
@@ -1,4 +1,4 @@
-fn call_closure(f: impl Fn()) {
+fn call_closure(mut f: impl FnMut()) {
f();
}
このように、Rustではクロージャーの型が自動決定されるので、どういったケースでどの型になるのかを理解しておく必要があります。
Rustのクロージャーの詳細はこちらの記事をぜひ参照してください。
大変わかりやすいです。
一方でGoはクロージャーを受け取る関数を定義するときは、書いたとおりの型をかけばいいだけなので、とてもシンプルです。
func callClosure(f func()) {
f()
}
func main() {
v := "value"
echo := func() {
v = "new value"
}
callClosure(echo)
fmt.Println(v)
}
ただ、RustのクロージャーのよいところはFnかFnMutかで、データ変更が起きるかどうかが分かるという点ですね。
こういったことができると柔軟に関数の設計ができます。
好みが分かれるところではありますが、自分は比較的にRustのクロージャーのが好みです。
Rustのほうがより柔軟に設計できて安全にかけるからです。
Drop
Goにはdeferという関数の呼び出し元に戻る前に指定した関数を遅延実行する機能があります。
これは大変便利なもので、たとえばファイルを開いて中身を読み取ったら閉じるといった処理を書くときによく使います。
func readFile(file string) (string, error) {
f, err := os.Open(file)
if err != nil {
return "", nil
}
defer f.Close() // readFileを抜ける際に`f.Close()`を実行する
b, err := io.ReadAll(f)
if err != nil {
return "", err
}
return string(b), nil
}
一方Rustの場合はDropというトレイト[3]で似たことができます。
Dropトレイトのメソッドは、オブジェクトがスコープを抜けた際に自動で呼ばれます。
https://doc.rust-jp.rs/rust-by-example-ja/trait/drop.html のコードをそのまま示します。
struct Droppable {
name: &'static str,
}
impl Drop for Droppable {
fn drop(&mut self) {
println!("> Dropping {}", self.name);
}
}
fn main() {
let _a = Droppable { name: "a" };
{
let _b = Droppable { name: "b" };
{
let _c = Droppable { name: "c" };
let _d = Droppable { name: "d" };
println!("Exiting block B");
}
println!("Just exited block B");
println!("Exiting block A");
}
}
実行すると、スコープを抜けた際にdrop()が実行されているのがわかります。
$ cargo run -q
Exiting block B
> Dropping d
> Dropping c
Just exited block B
Exiting block A
> Dropping b
> Dropping a
Goのdeferは関数スコープなので、たとえばforで繰り返しファイルを開いて処理して閉じるといった処理を書く際、うっかり次のように書いてしまうときがあります。
これだとループごとにファイルは閉じないので、関数を抜けたタイミングでクローズされます。
for _, filename := range []string{"file1", "file2", "file3"} {
file, err := os.Open(filename)
if err != nil {
// error handling
continue
}
// do something with the file
defer file.Close()
}
Rustだと次のループの前にdropされるので、特に何も意識する必要はないです。
個人的にスコープで遅延処理ができるのがちょっと便利かなと思っています。
for filename in vec!["file1", "file2", "file3"] {
let file = std::fs::OpenOptions::new().open(filename).unwrap();
// do somethign with file
}
マクロ
Rustにはマクロとういう機能があります。
マクロは簡単にいうとコンパイル前にコード生成する機能です。
たとえば次のvec![]はマクロになります。
let list = vec![1, 2, 3];
vec![]マクロは最終的に次のコードに展開されます。
let list = <[_]>::into_vec(#[rustc_box] ::alloc::boxed::Box::new([1, 2, 3]));
Rustのマクロは大きく分けて次の2つになります。
- 宣言的マクロ
- 手続きマクロ
宣言的マクロはさきほど説明したvec!がそれにあたります。
マクロを定義する際は次ような感じで書きます。
コードをDRYにできてかつ手軽に定義できるので、宣言的マクロは使う場面が多いです。
#[macro_export]
macro_rules! my_vec {
( $( $x:expr ),* ) => {
{
let mut temp_vec = Vec::new();
$(
temp_vec.push($x);
)*
temp_vec
}
};
}
fn main() {
// 展開後はこんな感じになる
// let v = {
// let mut temp_vec = Vec::new();
// temp_vec.push(1);
// temp_vec.push(2);
// temp_vec.push(3);
// temp_vec.push(4);
// temp_vec.push(5);
// temp_vec
// };
let v = my_vec![1, 2, 3, 4, 5];
println!("{:?}", v);
}
手続きマクロはさらに次の3種類があります。
- derive マクロ
- attribute マクロ
- function like マクロ
derive マクロは構造体につけます。
具体的に次のように書きます。
// #[derive(ここにマクロ名)]
#[derive(Debug)]
struct S(String);
標準ではいくつか便利なderiveマクロが提供されていて、上記の例ではDebugトレイトを自動実装してくれるマクロとなっています。
展開後のコードは次のようになります。
struct S(String);
#[automatically_derived]
impl ::core::fmt::Debug for S {
#[inline]
fn fmt(&self, f: &mut ::core::fmt::Formatter) -> ::core::fmt::Result {
::core::fmt::Formatter::debug_tuple_field1_finish(f, "S", &&self.0)
}
}
attributeマクロは関数や構造体につけます。
たとえばtokioを使うときに#[tokio::main]をつけていたんですが、これがattributeマクロになります。
#[tokio::main]
async fn main() {
// .awaitで関数の実行が終わるまで待つ
async_hello().await;
println!("Thread finished!")
}
function likeマクロは宣言的マクロと使い方似ていて、次のように書きます。
let sql = sql!(SELECT * FROM posts WHERE id=1);
マクロの詳細を書くとそれだけで一冊の本ができてしまうので、もう少し詳しく知りたい方はこちらを参照してください。
マクロは大変便利な一方、多用は可能な限り避けるとよいかなと思います。
使う分には便利ですが、コードリーディングする際はマクロがどのようなコードを展開するのかを脳内でイメージするので認知負荷が高いです。
無理にマクロで全部やらずうまく使い所を見つけていくのがよいかなと思います。
型の表現力
Goと比べてRustの型のが表現力があるかなと思います。
たとえば、Goではオプショナルな値を表現したいときや処理が失敗しうる関数を定義するときによくnilを使います。
しかし、nilな変数をアクセスするとinvalid memory address or nil pointer dereferenceエラーになりプロセスが止まってしまいます。
そのため、nilな変数は必ずチェックする必要がありますが、チェックを忘れたとしてもコンパイルはとおります。
Rustではオプショナルな値を表現するときはOption型、処理結果が失敗しうる関数を定義するときはResult型を使います。
これらを使うとチェック漏れが発生せず、安全にエラーハンドリングしたり値を扱えます。
ちなみにOptionとResultはともにEnum型となっていて、Enum型は値をもつこともできます。
具体的な例をもとに説明します。
オプショナルな値を表現する場合
たとえば入力でNickNameが必須じゃない場合Goでは次のように表現します。
type Input struct {
Name string
NickName *string
}
nilチェックをしなくて*input.NickNameでデリファレンスできますが、NickNameがnilの場合チェック忘れてもコンパイルがとおります。
// nilの場合はpanicする
// コンパイルエラーにならない
nickName := *input.NickName
Rustでは次のように表現します。
struct Input {
name: String,
nick_name: Option<String>,
}
値を扱うときに基本的にmatch式を使って、値があるときはSome(...) => { ... }の分岐に、ない場合はNone => { ... }の分岐に入ります。
match input.nick_name {
Some(nick_name) => {
// do something
}
None => {
// do something
}
}
match式を使う場合、すべての分岐を網羅しないとmissing match arm: None not coveredといったコンパイルエラーが発生します。
つまり、必ず値が存在・しない場合の処理を記述しなければ行けないので、実質Goにおけるnilチェックを強制している感じです。
ちなみにOption型はunwrap()を使うと値を取り出してくれますが、Noneの場合はpanicが発生します。
unwrap()は何かしらの理由で値があることは確定だとユーザが認識したときに使うものなので、テスト以外ではほぼ使うことはないです。
失敗しうる処理を表現する場合
Goでは失敗しうる関数を次のように定義することが多いかと思います。
func readFile(file string) ([]byte, error) {
f, err := os.Open(file)
if err != nil {
return nil, err
}
defer f.Close()
return os.ReadFile(file)
}
エラーハンドリングも次のようにやるのが一般的です。
bytes, err := readFile("tmp.txt")
if err != nil {
// handle error
}
しかし、errは無視できてしまいます。
// 無視する場合
bytes, _ := readFile("tmp.txt")
RustではOptionと同様、処理結果を扱うなら基本的にmatch式を使います。
それによってエラーハンドリングを強制します。
use std::io::Read as _;
fn read_file(file: String) -> Result<Vec<u8>, std::io::Error> {
let mut file = std::fs::File::open(file)?;
let mut buffer = Vec::new();
file.read_to_end(&mut buffer)?;
Ok(buffer)
}
let result = read_file("tmp.txt".into());
let bytes = match result {
Ok(bytes) => bytes
Err(e) => {
// error handling
return Err(e);
}
}
ちなみに、match式を都度書くと長くなるので?を使ったエラーハンドリングもよく使います。
?はさきほど提示したコードのシンタックスシュガーで、Optionのときも使えます。
let bytes = read_file("tmp.txt".into())?;
Enum型を使った表現
GoではEnum型がないんですが、よく使われているイデオムとして次のような実装があります。
type Status interface {
isStatus()
}
type status string
func (s status) isStatus() {}
const (
Unknown status = "Unknown"
Active status = "Active"
Inactive status = "Inactive"
)
func printStatus[T Status](status T) {
fmt.Println("Status:", status)
}
func main() {
printStatus(Unknown)
printStatus(Active)
printStatus("Foo") // output: string does not satisfy StatusEnum (missing method isStatusEnum)
}
しかし、この実装は完璧ではなく、たえば次のように書けば"Foo"を渡せてしまうという問題があります。
printStatus(status("Foo"))
Rustの場合はEnum型があるので、シンプルに次のように定義すればよいだけです。
#[derive(Debug)]
enum Status {
Unknown,
Active,
Inactive,
}
fn print_status(status: Status) {
println!("The status is {:?}", status);
}
fn main() {
print_status(Status::Active);
print_status(Status::Inactive);
}
またRustのEnumは値を持てるので、たとえば次のようにIPアドレスを表現できます。
enum IpAddr {
V4(u8, u8, u8, u8),
V6(String),
}
let home = IpAddr::V4(127, 0, 0, 1);
let loopback = IpAddr::V6(String::from("::1"));
ちなみに、OptionもResultもEnum型です。
pub enum Result<T, E> {
/// Contains the success value
#[lang = "Ok"]
#[stable(feature = "rust1", since = "1.0.0")]
Ok(#[stable(feature = "rust1", since = "1.0.0")] T),
/// Contains the error value
#[lang = "Err"]
#[stable(feature = "rust1", since = "1.0.0")]
Err(#[stable(feature = "rust1", since = "1.0.0")] E),
}
抽象化について
Goでは抽象化する際はinterfaceを使います。
Goのinterfaceに定義されているメソッドを実装したデータ構造であれば自動的にinterfaceを満たしていると判定されるので、
構文からどのインターフェイスを実装しているかを判断できないため、少しコードを追いづらいかなと思っています。
type Writer interface {
Write([]byte) (int, error)
}
type MyWriter struct {
buf []byte
}
func (w *MyWriter) Write(data []byte) (int, error) {
w.buf = append(w.buf, data...)
return len(data), nil
}
func write(w Writer, data []byte) (int, error) {
return w.Write(data)
}
Rustでは抽象化をする際はtraitというのを使います。
traitを実装する際はimpl {trait} for {struct}といった感じで書くので、どのtraitを実装しているのか構文から判断できるので、Goと比べて少しですがコード追いやすいかなと思っています。
trait Writer {
fn write(&mut self, buf: &mut Vec<u8>) -> Result<usize, String>;
}
struct MyWriter(Vec<u8>);
impl Writer for MyWriter {
fn write(&mut self, buf: &mut Vec<u8>) -> Result<usize, String> {
self.0.append(buf);
Ok(buf.len())
}
}
fn write(writer: &mut impl Writer, buf: &mut Vec<u8>) -> Result<usize, String> {
writer.write(buf)
}
また、上記のシンプルな例では大差がないですが、Rustのtraitは他に定数を定義したりメソッド実装できたりします。
その例を次に示します。
trait Currency {
// 定数を定義することで
// トレイトを実装する際は定数も必須になる
const SYMBOL: &'static str;
// メソッドを実装することでデフォルト実装を表現できる
// それにより、トレイトを実装する際はメソッドの実装は必須じゃなくなる
fn value(&self) -> f64 {
0.0
}
}
struct USD(f64);
impl Currency for USD {
const SYMBOL: &'static str = "$";
fn value(&self) -> f64 {
self.0
}
}
struct EUR(f64);
impl Currency for EUR {
const SYMBOL: &'static str = "€";
fn value(&self) -> f64 {
self.0
}
}
fn main() {
let usd = USD(100.0);
let eur = EUR(85.0);
println!("The amount in USD is {}{}", USD::SYMBOL, usd.value());
println!("The amount in EUR is {}{}", EUR::SYMBOL, eur.value());
}
この例をGoで同じような実装をする場合、symbol() stringみたいなメソッドを定義することになると思いますが、Rustと比べて少し微妙かなと思っています。
他にもtraitに関連型を定義できたりしますが、ここで細かく解説するとそれだけで記事が1本できてしまうので、詳細を知りたい方はこちらを参照ください。
こういった点から、Rustのtraitは表現力が豊かで、Goのinterfaceと比べて柔軟性があるかなと思っています。
ジェネリクスについて
GoもRustもジェネリクスがありますが、Goがジェネリクスをサポートしたのは1.18(2022年3月頃)で、割と最近です。
GoとRustのジェネリクスにおいて、大きいな違いは次の点かなと思います。
| Go | Rust | 違い |
|---|---|---|
| ◯ | x | 型制約に型を使う |
| x | ◯ | メソッドに型制約を使う |
少し説明していきます。
GoとRustのジェネリクスの違いについて
Goのジェネリクスでは次のように[]byteもしくはstringを受け取るBytesというのを定義できます。
もちろんインターフェイスも制約に使えます。
func x[Bytes []byte | string](b Bytes) {
}
type Writer interface {
Write([]byte) (int, error)
}
func write[T Writer](w T, data []byte) {
w.Write(data)
}
Rustでは型をジェネリクスに使えるのはトレイトのみで、上記のような型を指定できないです。
struct S;
fn f<T: S>(_f: T) {} // expected trait, found struct `S` not a trait
trait Writer {
fn write(&mut self, data: &[u8]);
}
fn write<T: Writer>(writer: &mut T, data: &[u8]) {
writer.write(data);
}
また、Goではインターフェイスで定義したメソッドでジェネリクスが使えないのですが、Rustでは使えます。
type Processor struct {}
func (p *Processor) Process[T any](data T) T { // method must have no type parameters
return data
}
struct Processsor;
impl Processsor {
fn process<T>(&self) -> T {
// implementation
}
}
他に、たとえば複数インターフェイスを制約として使いたい場合、Goと比べるとRustの方が少し手軽に書けます。
次のように、Goではインターフェイスを定義する必要があります。
type Writer interface {
Write([]byte) (int, error)
}
type Closer interface {
Close() error
}
type WriteCloser interface {
Writer
Closer
}
func write[T WriteCloser](wc T, data []byte) {
defer wc.Close()
wc.Write(data)
}
Rustでは+で同様のことができます。
trait Writer {
fn write(&mut self, data: &[u8]);
}
trait Closer {
fn close(&mut self);
}
fn write<T: Writer + Closer>(wc: &mut T, data: &[u8]) {
wc.write(data);
}
型を制約として使えないという点では少し不便ですが、トレイトで抽象化してしまえば同等なことができるので問題ないかなと思います。
複数制約をつけたい場合の書き方はRustのが少し便利ですが、Goとそれほどの差はないかなと思います。
ジェネリクスの仕組みについて
RustとGoのジェネリクスは仕組みが少し異なります。
Rustの場合は単相化(monomorphization)といって、コンパイル時に型ごとのコードを生成します。
たとえば次のように整数と小数な値をもつOptionはコンパイル後のようになります。
// コンパイル前
let integer = Some(5);
let float = Some(5.0);
// コンパイル後
enum Option_i32 {
Some(i32),
None,
}
enum Option_f64 {
Some(f64),
None,
}
fn main() {
let integer = Option_i32::Some(5);
let float = Option_f64::Some(5.0);
}
単相化はコードがそのまま展開されコンパイルされるので、追加コストなしにそのまま実装するため実行速度のオーバーヘッドがないです。
ただ、コードが増えるのでその分コンパイル後のバイナリのサイズが大きくなるというデメリットがあります。
一方Goでは辞書を使ってジェネリクスを実現しています。
辞書には関数の実体と型情報が含まれています。
関数呼び出しは辞書を経由するので実行時にオーバーヘッドが発生しますが、コードが展開されるわけではないので単相化よりもバイナリサイズは抑えられます。
実行時のオーバーヘッドに関しては、異なる型でもGC Shapeが同じであれば型チェックと変換をしないので、その分のオーバーヘッドがないです。
GC Shapeとは「その型がアロケータ/ガベージコレクタにどのように見えるか」という意味で、「サイズ、必要なアライメント、そして型のどの部分にポインタが含まれているか」によって決まります。
表にまとめると次のような感じかなと思います。
| 言語 | 実行速度 | バイナリサイズ |
|---|---|---|
| Go | △ | △ |
| Rust | ○ | x |
もう少し詳細を知りたい方はこちらを参照してください。
テスト
GoとRustはともにテストの機能を標準で提供しています。
両者の大きな違いとしては次の点かなと思います。
| 言語 | 実行 | テストの記述 | ドキュメントテスト |
|---|---|---|---|
| Rust | 並行(直列も可能) | ファイル内とtests配下 |
あり |
| Go | 直列(並列も可能) | 別ファイルでサフィックス_testが対象 |
なし |
それぞれについてすこし説明します。
テストの記述について
まず書き方ですが、Goの場合は次の条件を満たしたものがテストとして実行されます。
- ファイル名が
_test.goであること - テスト関数は
TestXxx(t *testing.T)であること- 関数名が
Testから始まる -
*testing.Tという型の引数を受け取る
- 関数名が
上記の条件を満たす例が次のとおりです。
func TestFoo(t *testing.T) {
got := "gorilla"
want := "gorilla"
if !reflect.DeepEqual(want, got) {
t.Errorf("unexpected result got: %v, want: %v", got, want)
}
}
また、Goではt.Run(...)を使ってサブテストを書くこともできます。
func Test1(t *testing.T) {
t.Run("sub1", func(t *testing.T) {
...
})
t.Run("sub2", func(t *testing.T) {
...
})
}
テスト実行はgo testになります。
Rustでは単体テストの場合はファイル内、統合テストの場合はtestsディレクトリにファイルを作成して書きます。
ファイル内の場合は次のように書きます。
#[cfg(test)]
mod tests {
#[test]
fn test_foo() {
let got = "gorilla";
let want = "gorilla";
assert_eq!(got, want);
}
}
テスト実行はcargo testになります。
#[cfg(...)]は条件付きコンパイルのマクロでtestの場合は通常コンパイルの対象外になります。
他にも特定の機能のときだけ有効にするといったことも可能です。
そしてテスト関数は#[test]マクロをつける必要があります。
assert_eq!は標準で用意されている比較マクロで、基本的にテスト結果の比較はこのマクロを使います。
また、ファイル内にテストを書くということで、プライベートな関数のテストも書けます。
ここがGoとの違いの1つですね。
プライベートな関数をテストする必要はあるかどうかといった議論はあると思いますが、選択肢としてできるのはよいことかなと思います。
統合テストですが、これはGoにはない機能でtestsディレクトリ配下の#[test]がついた関数もテストとして実行されます。
ディレクトリの置き場は次のようになります
.
├── Cargo.lock
├── Cargo.toml
├── src // ソースコード
│ └── main.rs
└── tests // 結合テスト
└── integration.rs
統合テストはクレート[4]が公開している関数しか使えないため、利用者の目線としてテストを書くことができます。
Goでも同じようなことをやろうとする場合workspace機能を使って、リリースしなくてもテスト対象のパッケージに対して利用者目線でテストを書く形になるかなと思います。
利用者目線でテストを書くという点では、Rustのが少し便利かなと思っています。
ドキュメントテストについて
これはGoにない機能ですが、Rustではドキュメントに記載したコードもテストできます。
Rustの場合コードのコメントは//で書くんですが、///で書いたコメントはクレートのドキュメントとして生成されます。
ドキュメントのコードは次のように書きます。
/// This is a simple function that adds two numbers.
/// Examples
/// ```
/// use hello::add;
/// let x = 5;
/// let y = 6;
/// assert_eq!(add(x, y), 11);
/// ```
pub fn add(a: i32, b: i32) -> i32 {
a + b
}
生成されるドキュメントはこんな感じです。

これをcargo testで実行すると次のようにテスト成功したと出ます。
running 1 test
test src/lib.rs - add (line 3) ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.13s
失敗時はこんな感じです。
running 1 test
test src/lib.rs - add (line 3) ... FAILED
failures:
---- src/lib.rs - add (line 3) stdout ----
Test executable failed (exit status: 101).
stderr:
thread 'main' panicked at src/lib.rs:8:1:
assertion `left == right` failed
left: 11
right: 12
(略)
これは非常に便利な機能で、作成したライブラリのドキュメントに載せたサンプルコードがきちんとコンパイルできるかどうかを担保できます。
Goに限らずいろんな言語に入ってほしい機能ですね。
テストの実行について
Goのテストは基本的にパッケージ内は直列、パッケージ単位で並列実行です。
ただ、テスト関数でt.Parallel()を使えばパッケージ内のテストでも並行で実行できます。
サブテストでもt.Parallel()が使えます。
func Test1(t *testing.T) {
t.Parallel()
...
}
より詳細はこちらを参照してください。
一方Rustではデフォルトでスレッドを使って並行実行します。
直列で実行したい場合は次のように--test-threads=1でスレッドを1つに限定すればよいです。
cargo test -- --test-threads=1
デフォルトでテストを並行実行してくれるのはテスト時間の短縮と、
テストごとに独立して動いていることも合わせてチェックできるので、個人的にRustの方の挙動がよいかなと思っています。
非同期処理
Goの場合はgoroutineというGoランタイムに管理される軽量スレッドを使います。
goroutineを作るのには、関数の前にgoキーワードを書くだけです。
これだけで非同期処理になり、あとはGoランタイムがよしなにスケジューリングしてくれます。
func main() {
go func() {
fmt.Println("Hello from a goroutine")
}()
// goroutineが実行されるの少し待つ
time.Sleep(1*time.Second)
fmt.Println("main function exited")
}
goroutineの実行が終わるのを確実に待ちたい場合はsycn.WaitGroupを使います。
func main() {
var wg sync.WaitGroup
wg.Add(1)
go func() {
defer wg.Done()
fmt.Println("Hello from a goroutine")
}()
// goroutineの処理が終わるのを待つ
wg.Wait()
fmt.Println("main function exited")
}
Rustの場合は2つの選択肢があります。
1つはスレッドで、次のように書きます。
fn main() {
let handle = std::thread::spawn(|| {
println!("Hello from a thread!");
});
// joinでスレッドの処理が終わるのを持つ
handle.join().unwrap();
println!("Thread finished!")
}
もう1つはasync/awaitです。
async/awaitは関数の先頭にasyncキーワード、実行する場合は.awaitキーワードをつけます。
async関数を実行するには非同期ランタイムを使うのが一般的です。
次の例では非同期ランタイムであるtokioを使った例です。
async fn async_hello() {
println!("Hello from async function!");
}
#[tokio::main]
async fn main() {
// .awaitで関数の実行が終わるまで待つ
async_hello().await;
println!("Thread finished!")
}
また、asyncは関数だけではなくブロックにつけることもできます。
これはasyncブロックと呼ばれます。
#[tokio::main]
async fn main() {
let async_something = async {
1
};
println!("{}", async_something.await);
}
Goの非同期処理の仕組み
Goの非同期処理はプリエンプションという手段を取っています。
プリエンプションとはタスクの協力なしに、一時的に中断して別のタスクを実行する手法のことです。
つまりGoランタイムはgoroutineに状態(I/O待ちなど)を通知してもらう必要はなく、よしなにgoroutineを中断・再開しながら処理を行ってくれるということです。
Goランタイムはスレッドごとにワーカーとローカルキューを持っていて、スケジューラがいい感じにwork stealingしたりして、各ワーカーにgoroutineを配置して並行で処理する様になっています。
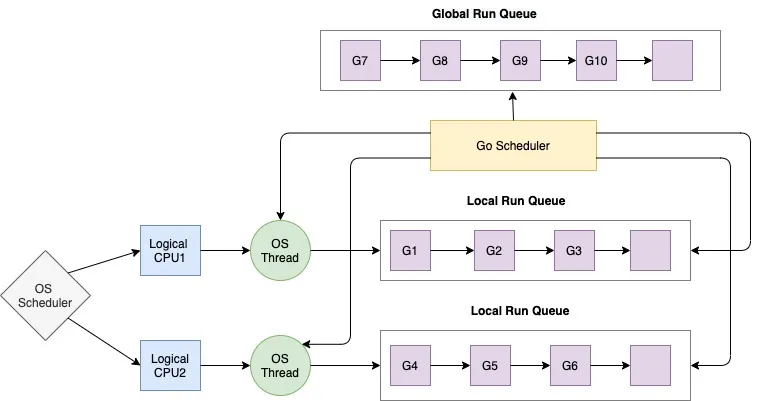
https://golangbyexample.com/goroutines-golang/ より
Goランタイムの非同期処理の仕組みについて、こちらが大変わかりやすいので、ぜひ参照してください。
Rustの非同期処理の仕組み
Rustの非同期処理はGoとは対照的でノンプリエンプティブです。
ノンプリエンプティブはタスクの協力なしに処理を中断できないです。
Rustの場合はawaitが中断ポイントになっていて、そこでタスクの切り替わりが発生します。
それまではタスクの切り替えができないので、Goと比べて少し柔軟性に欠けます。
もう少し具体的に説明していきます。
実はRustのasyncキーワードは次のFutureトレイトのシンタックスシュガーです。
Futureトレイトとは非同期タスクを抽象化して表現したものです。
pub trait Future {
type Output;
fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output>;
}
たとえば次のようなasync関数があるとします。
async fn fetch_data() -> String {
sleep(Duration::from_secs(1)).await;
"Data fetched".to_string()
}
これがコンパル時に次のようなコードに変換されます。
struct FetchData {
sleep: Pin<Box<Sleep>>,
}
impl Future for FetchData {
type Output = String;
fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output> {
let sleep = self.get_mut().sleep.as_mut();
match sleep.poll(cx) {
Poll::Ready(_) => Poll::Ready("Data fetched".to_string()),
Poll::Pending => Poll::Pending,
}
}
}
fn fetch_data() -> FetchData {
FetchData {
sleep: Box::pin(sleep(Duration::from_secs(1))),
}
}
非同期処理を書くたびに上記のようなコードを書くのはとてもつらいので、このようなシンタックスシュガーが用意されています。
Futureのpoll()を呼び出すことではじめてasync関数の処理が開始されます。
poll()関数を呼び出しはawaitで行われます。
このpoll()をいい感じに処理してくれるのが非同期ランタイムです。
Rustの場合は本体にはFutureをスケジューリングしてくれる非同期ランタイムが存在しません。
Rustの標準クレート[5]にはFutureトレイトの定義のみが宣言されていて、Futureのpoll()を呼び処理を進めるのは何かしらの非同期ランタイムの責務になります。
非同期ランタイムにはFutureを実行するExecutorが実行されていて、Executor内でpoll()を呼び出し処理を進めます。
poll()はPollというEnumを返すのですが、Poll::Pendingが返されるとランタイム側ではタスクの処理を中断して別のタスクを実行、Poll::Readyが返されるとタスク処理は完了になります。
pub enum Poll<T> {
Ready(T),
Pending,
}
これは一種のステートマシンと考えることができます。
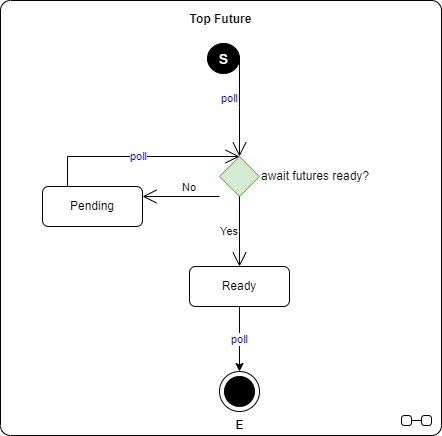
https://medium.com/@gftea/async-state-machine-in-rust-e8d46af52532 より
一例ですが、次は非同期ランタイムfutures-rsのExecutorの実装になります。
let Poll::Ready(t) = f(&mut cx)のところが味噌で、FutureのfがPoll::Readyを返すまでループしてタスクを処理してます。
そのため、poll()から戻り値が返ってくるまではタスクを切り替えることができないです。
どこまで処理して、中断してPoll::Pedingを返すかはタスクの実装次第になります。
たとえばI/O待ちが発生したらPoll::Pendingを返すような実装になっていればI/O待ちの間に別のタスクを処理できます。
簡易的なシーケンスを示すと次のようなイメージになります。
Executorはなにか標準仕様があるわけではなく、非同期ランタイムによって実装がまちまちです。
シングルスレッドでFutureを実行するものあれば、マルチスレッドでFutureを実行するものもあります。
先ほど示したfutures-rsの例ではシングルスレッドですね。
Rustの非同期ランタイムはいくつかありますが、それぞれ特徴が異なります。
簡易ではありますが、主なランタイムを次の表にまとめました。
| ランタイム | 概要 |
|---|---|
| tokio | I/O boundな処理を得意とする、もっとも使われているランタイム |
| smol | 小さくシンプル、複数小さな非同期関連クレートをまとめたクレート |
| async-std | 標準クレートstdの非同期版を提供しているクレート |
| futures-rs | 非同期処理に便利なユーティリティを提供している、一応Executorも実装されている |
| rayon-rs | 並列計算(CPU bound)処理を得意とする |
Rustの非同期処理についてより詳しく知りたい場合はAsynchronous Programming in Rustを参照してください。
こちらの本は実際にExecutorを実装して理解を深めていく本となっています。
GoとRustの非同期処理の比較
先ほどの節までGoとRustの非同期処理の仕組みについて説明しました。
この節では次の観点で比較してみます。
- 難易度
- 安全性
- パフォーマンス
難易度
次の点を考えると、Goと比べてRustの非同期処理のほうが難しいかなと思います。
- Rustの非同期処理の仕組みを理解する必要がある
- 雰囲気で書ける部分もあるが、いずれ詰まってしまう場面に遭遇する
- Goの場合はランタイムの仕組みを知らなくても困ることはほとんどない
- 非同期ランタイムが外だしになっているので、ユースケースに応じて適切にランタイムを選択する必要がある
- I/Oバウンドな処理なら
tokio、並列計算ならrayon-rs - Goの場合はランタイムがよしなにプリエンプトするので、CPU or IOバウンドな処理のどちらにも柔軟に対応できる
- I/Oバウンドな処理なら
- 所有権/ライフタイムが絡むとさらに複雑になる
- Goは所有権という概念は出てこないので意識することがない
すべてを説明しきれいないので、ここでは所有権が絡む例を紹介します。
次のコードは配列を非同期タスク内で出力するシンプルな処理ですが、これはコンパイルが通らないです。
use tokio::task;
#[tokio::main]
async fn main() {
let v = vec![1, 2, 3];
task::spawn(async {
println!("Here's a vec: {:?}", v);
})
.await
.unwrap();
}
エラー
$ cargo run -q
error[E0373]: async block may outlive the current function, but it borrows `v`, which is owned by the current function
--> src/main.rs:51:17
|
51 | task::spawn(async {
| _________________^
52 | | println!("Here's a vec: {:?}", v);
| | - `v` is borrowed here
53 | | })
| |_____^ may outlive borrowed value `v`
|
= note: async blocks are not executed immediately and must either take a reference or ownership of outside variables they use
help: to force the async block to take ownership of `v` (and any other referenced variables), use the `move` keyword
|
51 | task::spawn(async move {
| ++++
For more information about this error, try `rustc --explain E0373`.
error: could not compile `hello` (bin "hello") due to 1 previous error
Rustコンパイラはとても丁寧で親切なので、コンパイルエラーに理由が書いてあります。
async blocks are not executed immediately and must either take a reference or ownership of outside variables they use
非同期ブロックはすぐには実行されず、使用する外部変数の参照または所有権を取得する必要があります
要はasyncタスクの実行タイミングはコンパイラは検知できないので、asyncブロック内で使っているvが実行時に生存していることを保証できないということです。
このようなケースはmoveで所有権をasyncブロック内に移動させることで解決します。
asyncブロック内に所有権が移動すれば、生存期間はasyncブロックと同じになるので、コンパイルがとおります。
async fn main() {
let v = vec![1, 2, 3];
- task::spawn(async {
+ task::spawn(async move {
println!("Here's a vec: {:?}", v);
})
.await
しかし、vを複数のasyncブロックで参照したい場合、所有権が移動してしまうと困ります。
そのようなケースの場合はArcというスレッドセーフな参照カウント・ポインターを使って所有権を共有します。
ちなみにシングルスレッド版はRcというのがあります。
use std::sync::Arc;
use tokio::task;
#[tokio::main]
async fn main() {
let v = Arc::new(vec![1, 2, 3]);
{
// cloneすることで参照カウントが+1される
// asyncブロックを抜けるとdropので、カウントが-1される
// カウントが0になればメモリから削除される
let v = v.clone();
task::spawn(async move {
println!("Here's a vec: {:?}", v);
})
.await
.unwrap();
}
{
let v = v.clone();
task::spawn(async move {
println!("Here's a vec: {:?}", v);
})
.await
.unwrap();
}
}
このようにRustはGCを使わず、こういった工夫をしてメモリ安全を実現しています。
一方Goの場合は所有権を考える必要がなく、もっと直感的に書けます。
func main() {
v := []int{1, 2, 3}
var wg sync.WaitGroup
wg.Add(1)
go func() {
defer wg.Done()
fmt.Printf("v: %v\n", v)
}()
wg.Add(1)
go func() {
defer wg.Done()
fmt.Printf("v: %v\n", v)
}()
wg.Wait()
}
安全性
安全に並行処理をかけるかどうか、という観点で見た場合Goと比べてRustのほうが安全かなと思います。
複数のURLからデータをダウンロードして、それをURLごと保持するためMapを用いる例を考えてみます。
Goの場合は次のように実装するかと思いますが、この実装だとデータ競合を引き起こす可能性があります。
package main
import (
"fmt"
"sync"
"time"
)
func main() {
urls := []string{
"url1",
"url2",
"url3",
}
results := map[string][]byte{}
var wg sync.WaitGroup
for _, url := range urls {
wg.Add(1)
go func(url string) {
defer wg.Done()
fmt.Printf("fetching %s\n", url)
time.Sleep(1 * time.Second)
body := []byte{} // some response body
results[url] = body
}(url)
}
wg.Wait()
fmt.Printf("%#+v\n", results)
}
$ go run .
fetching url3
fetching url1
fetching url2
fatal error: concurrent map writes
これはmapに対して、並行で書き込みをする処理でロックを書けていないからですね。
Goの場合はビルド時に-raceオプションでデータ競合を検知する処理を埋め込み実行時に検知してくれます。
$ go run -race .
fetching url3
fetching url2
fetching url1
==================
WARNING: DATA RACE
Write at 0x00c0000940c0 by goroutine 7:
runtime.mapaccess2_faststr()
略)
対処方としてシンプルにロックをかけてデータ競合を防ぎます。
@@ -13,6 +13,7 @@ func main() {
"url3",
}
+ var mutex sync.Mutex
results := map[string][]byte{}
var wg sync.WaitGroup
@@ -23,7 +24,9 @@ func main() {
fmt.Printf("fetching %s\n", url)
time.Sleep(1 * time.Second)
body := []byte{} // some response body
+ mutex.Lock()
+ defer mutex.Unlock()
results[url] = body
}(url)
}
同じ例でRustで実装してみます。
複数のasycnタスクでmapに対する所有権を共有する必要があるのでArcが必要です。
しかし、この実装ではコンパイルが通らないです。
use std::{collections::HashMap, sync::Arc, time::Duration};
use tokio::time::sleep;
#[tokio::main]
async fn main() {
let urls = vec!["url1", "url2", "url3"];
let results = Arc::new(HashMap::<String, Vec<u8>>::default());
let mut tasks = Vec::with_capacity(urls.len());
for url in urls {
let results = results.clone();
tasks.push(tokio::spawn(async move {
println!("fetching {}", url);
sleep(Duration::from_secs(1)).await;
let body = vec![]; // some response body
results.insert(url.into(), body);
}));
}
for task in tasks {
task.await.unwrap();
}
println!("{:?}", results);
}
$ cargo run
Compiling hello v0.1.0 (/Users/skanehira/dev/github.com/skanehira/sandbox/rust/hello)
error[E0596]: cannot borrow data in an `Arc` as mutable
--> src/main.rs:16:13
|
16 | results.insert(url.into(), body);
| ^^^^^^^ cannot borrow as mutable
|
= help: trait `DerefMut` is required to modify through a dereference, but it is not implement
ed for `Arc<HashMap<String, Vec<u8>>>`
Arcはスレッドセーフな参照カウントポインタですが、可変ではないためです。
この場合はGoと同様でMutex[6]を使います。
Mutex::lock().awaitで可変なHashMapを取得できるので、それを使ってデータ書き込みを行います。
ちなみに、ロックの解放はasyncブロック内のresultsがdropされるときに行われます。
use std::{collections::HashMap, sync::Arc, time::Duration};
-use tokio::time::sleep;
+use tokio::{sync::Mutex, time::sleep};
#[tokio::main]
async fn main() {
let urls = vec!["url1", "url2", "url3"];
- let results = Arc::new(HashMap::<String, Vec<u8>>::default());
+ let results = Arc::new(Mutex::new(HashMap::<String, Vec<u8>>::default()));
let mut tasks = Vec::with_capacity(urls.len());
for url in urls {
@@ -13,7 +13,7 @@ async fn main() {
println!("fetching {}", url);
sleep(Duration::from_secs(1)).await;
let body = vec![]; // some response body
- results.insert(url.into(), body);
+ results.lock().await.insert(url.into(), body);
}));
}
@@ -21,5 +21,5 @@ async fn main() {
task.await.unwrap();
}
- println!("{:?}", results);
+ println!("{:?}", results.lock().await);
}
このようにコンパイルが通ればある程度は安心できます。
しかし、Rustのコンパイラも完璧ではないので、デッドロックが発生するコードでもコンパイルが通ることがあります。
こちらの例を紹介します。
use std::sync::Arc;
use tokio::sync::Mutex;
struct A;
impl A {
pub async fn do_something(&self) -> Result<(), ()> {
Err(())
}
}
async fn lock_and_use(a: Arc<Mutex<A>>) {
match a.clone().lock().await.do_something().await {
Ok(()) => {}
Err(()) => {
println!("trying again");
// ここロック待ちになる
let _ = a.clone().lock().await.do_something().await;
}
}
}
#[tokio::main]
async fn main() {
println!("begin");
let a = Arc::new(Mutex::new(A));
lock_and_use(a.clone()).await;
println!("end");
}
この実装ではdo_something()がエラーを返すともう一度ロックを取得しますが、そこでロック待ちになってデッドロックが発生します。(コンパイルはとおります)
これはmatch a.clone().lock().await.do_something().awaitで取得したロックはmatch式が抜けるまで保持しているため、match式内でさらにロックを取得しようとしてもロック開放するまで待つからです。
この場合はロックの期間を短くすればよいので、次のように一度変数に代入すればロックが開放された状態でmatch式を評価します。
async fn lock_and_use(a: Arc<Mutex<A>>) {
- match a.clone().lock().await.do_something().await {
+ let value = a.clone().lock().await.do_something().await;
+ match value {
Ok(()) => {}
Err(()) => {
println!("trying again");
非同期処理において、Goと比べてRustのほうが安心できる部分もありますが、コンパイラは完璧ではないのでそこだけ留意して使っていったほうがよいかと思います。
パフォーマンス
RustとGoの非同期処理のパフォーマンスの比較はちょっと難しいかなと思っていて、
というのも、Rustの非同期ランタイムは差し替えが可能なので単純な比較はできないからです。
たとえば、CPUバウンドな処理のベンチマークを取るにしてもtokioとrayon-rsではスコアが異なるはずです。
そのため、どのようなベンチマークを取りたいかによってランタイムの選択を意識する必要があるかなと思います。
本記事では具体的なパフォーマンス比較はせず、そのうち別途記事を書こうと思っています。
モジュールシステム
Goではgo mod、RustではCargoを使ってモジュールを管理します。
それぞれの違いを細かく説明するとそれだけで記事が1本になってしまうので興味ある方は次のリンク先を読んでみてください。
本節では主な違いについて説明します。
概念について
説明するまえに、GoとRustのモジュールシステムの概念の違いがあるので、そこについてまず説明します。
まず、Goではパッケージとモジュールがあります。
| 用語 | 意味 |
|---|---|
| パッケージ |
*.goファイルの集まり、ディレクトリ単位 |
| モジュール | パッケージの集まり、go.modがある |
| ワークスペース | モジュールの集まり |
次の図がわかりやすいかなと思います。
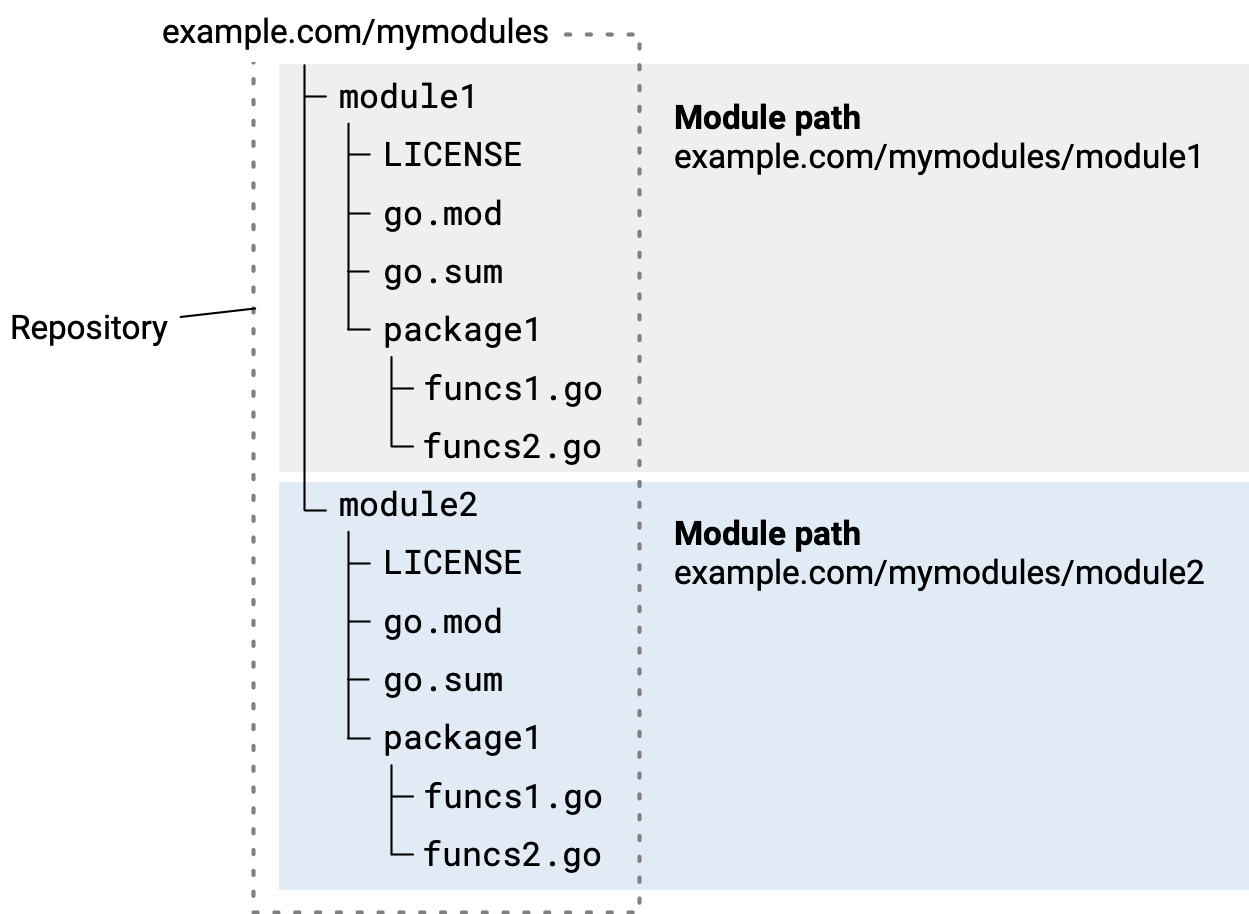
https://stackoverflow.com/questions/61940117/go-modules-vs-package より
Rustではパッケージとクレート、モジュールがあります。
| 用語 | 意味 |
|---|---|
| モジュール |
*.rsファイルの集まり、Goのパッケージに相当する |
| クレート | 複数のモジュールをもつ、Goのモジュールに相当する |
| パッケージ | 1つ以上のクレートを含む、Cargo.tomlがある |
| ワークスペース | 1つ以上のパッケージを含む、Cargo.tomlがある |
RustのクレートはGoと少し違っていて、ライブラリクレートとバイナリクレートがあります。
他のクレートから利用されることを前提としたのがライブラリクレートです。lib.rsがあるとライブラリクレートになります。
実行可能なプログラムを提供するのはバイナリクレートです。main.rsがあるとバイナリクレートになります。
バイナリクレートは複数作れますが、ライブラリクレートは1つのみです。
次の図がわかりやすいかなと思います。

https://users.rust-lang.org/t/cargo-package-structure-cheat-sheet/47984 より
go.modとCargo.toml
Cargo.tomlはモジュールの管理やビルドオプションなどを記述するファイルで、Goのgo.modに相当します。
[package]
name = "hello"
version = "0.1.0"
edition = "2021"
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
[dependencies]
ライブラリを追加したい場合は[dependencies]に記述するかcargo addコマンドを実行します。
次の例ではrandというライブラリを追加しています。
[dependencies]
rand = "0.8.5"
Goではgo.modという独自のフォーマットのファイルを使ってモジュールを管理しています。
module hello
go 1.22.0
ライブラリを追加する場合は基本的にgo getを使います。
go get github.com/google/go-cmp
そうするとgo.modのrequireが追加されます。
module hello
go 1.22.0
require github.com/google/go-cmp v0.6.0
go.modとCargo.tomlの一番大きいな違いは、Cargo.tomlはモジュール管理に閉じないことです。
Cargo.tomlには依存ライブラリの記述以外にも、コンパイラのオプションやlinterの設定などを変更できます。
このように細かくいろいろな設定ができるのはよいですね。
[profile.dev]
opt-level = 1 # 最適化のレベル
[lints.rust]
unsafe_code = "deny" # unsafe を禁止
Rustのモジュールについて
RustのモジュールはGoのパッケージに相当すると書きましたが、1つ大きな違いがあります。
Rustの場合、ファイルfoo.rsはfooというモジュールになりますが、実はファイル内でさらにモジュールを作れます。
たとえば次の例ではuhouho.rsファイル内にfooというモジュールを定義して、それを同じファイル内のcall_bar()で使用できます。
mod foo {
fn bar() {}
}
pub fn call_bar() {
foo::bar();
}
改めてテスト節で説明した単体テストを見るとモジュールを作ってその中にテストコードを描いていることがわかります。
#[cfg(test)]
mod tests {
#[test]
fn test_foo() {
let got = "gorilla";
let want = "gorilla";
assert_eq!(got, want);
}
}
テストを書く際は基本的にこうやってモジュールを作成しますが、それ以外でモジュールを作成することは個人の経験上ないので、正直どういったケースで便利なのかわかっていないところではあります。
ただ1つのファイル内で複数の名前空間を作れるので、そういうことをしたいときに便利と思います。
たとえばfoo.rs内でしか使わない複数のヘルパー関数を定義したいとき、helperモジュールを作成してそこに関数を閉じ込めるといった使い方ができるかなと思います。
featureフラグについて
Rustのfeatureフラグは、プロジェクト内の特定の機能をオプションとして定義し、ビルド時にそれらの機能を有効にする仕組みです。
これにより、依存関係やコードの一部を条件付きでコンパイルできて、より柔軟なビルド設定を実現できます。
featureフラグはCargo.tomlに定義し、それらをビルド時に--featuresで選択的に有効化できます。
たとえば次の例では、featureXというfeatureフラグを定義している例です。
[features]
default = []
featureX = []
fn main() {
println!("Default build");
feature_x();
}
#[cfg(feature = "featureX")]
fn feature_x() {
println!("Feature X is enabled");
}
#[cfg(not(feature = "featureX"))]
fn feature_x() {
// `featureX`が有効でない場合のデフォルト動作
}
# デフォルトのコンパイル
$ cargo run -q
Default build
# --features で feature フラグを指定して実行する
$ cargo run -q --features featureX
Default build
Feature X is enabled
Goではビルドタグを使用して、条件付きコンパイルを行うことで同等なことができます。
//go:build !featureX
package main
func featureX() {
// Feature X is not enabled, so do nothing
}
//go:build featureX
package main
import "fmt"
func featureX() {
fmt.Println("Feature X is enabled")
}
package main
import "fmt"
func main() {
fmt.Println("Default build")
featureX()
}
$ go run .
Default build
$ go run -tags featureX .
Default build
Feature X is enabled
Goの場合ビルドタグはファイル単位に適用されるため、機能実装を分ける場合はファイル単位で分ける必要があります。
一方Rustの行単位で条件付きコンパイルを書けるので、ファイルを分ける必要がないという点で異なります。
またRustの場合はCargo.tomlにfeatureフラグを定義するのですが、複数のfeatureをまとめて1つのfeatureとして定義できたり、デフォルトのfeatureを設定できたりといった点も異なります。
たとえば、tokioのfeatureフラグは色々ありますが、全機能入りのfullというfeatureがあります。
これは他のfeatureをすべてまとめたものとなっています。

モジュールの可視性の制御
Goでは、名前の先頭が大文字か小文字かによって公開(大文字)か非公開(小文字)かが決まります。パッケージのレベルで公開か非公開かを制御します。
一方Rustではpubキーワードを使って公開・非公開を制御し、さらにpub(crate)やpub(super)を使ってクレートや親モジュールに限定した公開も可能です。
まとめると次に表になります。
| キーワード | 範囲 |
|---|---|
pub |
制限なし完全に公開 |
pub(crate) |
クレート内で公開 |
pub(super) |
親モジュールに対して公開 |
pub(in path) |
特定のモジュールに対して公開 |
pub(in path)はちょっと分かりづらいので実例を示します。
たとえば次の例ではクレート内のfooというモジュールからのみアクセスできる関数になります。
pub(in crate::foo) fn do_something() {
println!("This function is public only within module 'a'.");
}
このようにRustはGoと比べてかなり細かく可視性の制御ができますが、そこまで細かく分けたいというケースにほぼ遭遇したことがないので、個人的にGoの仕様で十分なのとその方がシンプルでよいかなと思っています。
エコシステム
GoとRustのエコシステム周辺の主な違いを説明していきます。
モジュールのレジストリ
Goには中央集権的な公式レジストリがなく、コードのホスティングはGitHubなどの外部サービスに依存しています。
そのため、ライブラリを公開する場合は特段なにかに登録する必要はないです。
ただ、基本的にgo getでモジュールを追加する場合はGoogleが運用している次のキャッシュサーバーからダウンロードされます。
キャッシュサーバーに上がっているコードはコミット履歴がないのでデータ量が少くより高速にダウンロードできたり、ホスティングサービス上からライブラリが消えても一度キャッシュされれば使用できるといったメリットがあります。
Rustの場合はcrates.ioという公式レジストリがあり、cargo addでライブラリを追加する場合はこちらからダウンロードされます。
ただ、Rustはcrates.ioじゃなくても直接ホスティングサービスを指定できます。
リポジトリだけじゃなくて、ブランチやタグ、コミットも指定可能です。
[dependencies]
regex = { git = "https://github.com/rust-lang/regex.git", branch = "next" }
ライブラリを公開する場合はいくつか手順を踏む必要があります。
詳細は次のドキュメントを参照してください。
公式レジストリがあることで、RustはGoと比べてすこし便利な部分があります。
たとえばCargo --yankは公開したクレートを取り下げることができます。
取り下げはコード削除ではなく、新規でクレートを追加しようとしたときに取り下げたバージョンは使われなくなります。
Goは公開する手順を踏む必要がない分手軽で楽ですが、取り下げの機能がないので動かないライブラリを間違えて公開した場合は新しいバージョンを公開するしかないです。
ただ、公開済みのバージョンのコードを削除できない点においては共通なので、取り下げてもあんまり変わらないかなと思っています。
なので個人的に公開手順が不要なGoのほうが気楽で好みです。
ツールチェイン
GoとRustのツールチェイン周りはほぼ同等なものがあります。
簡単に表にまとめると次になるかなと思います。
| ツール | Go | Rust |
|---|---|---|
| コンパイラ | go build |
cargo build(rustc) |
| フォーマッター | go fmt |
cargo fmt(rustfmt) |
| リンター | go vet |
cargo check or cargo clippy(clippy) |
| LSP | gopls |
rust-analyzer |
| カバレッジ | go test -cover |
cargo llvm-cov(llvm-tools-preview) |
| ベンチマーク | go test -bench |
cargo bench(cargo-bench) |
| ドキュメント | go doc |
cargo doc(rustdoc) |
Rustは基本的にcargoのサブコマンド経由になりますが、カッコの中にあるのが実体でcargoはそれをプロキシしている感じです。
llvm-covに関しては標準ではなく、ツールのインストールが必要になります。
リンターに関してはcargo checkではなく一般的にcargo clippyを使うことがほとんどだと思います。
cargo clippyはRust界隈ではclippy先生と呼ばれるほど素晴らしいリンターで、どこが良くないのか、どのように修正すればいいのかを丁寧に教えてくれます。
また、ここまで検知してくれるのかと驚くこともあったりします。
次がリントの例です。
warning: writing `&Vec<_>` instead of `&[_]` involves one more reference and cannot be used with non-Vec-based slices
--> src/lib.rs:1:28
|
1 | fn sum_squares(values: &Vec<i32>) -> i32 {
| ^^^^^^^^^ help: change this to: `&[i32]`
|
= note: `#[warn(clippy::ptr_arg)]` on by default
= help: for further information visit https://rust-lang.github.io/rust-clippy/master/index.html#ptr_arg
Goのリンターはgo vetを使うことはありますが、他にもgolangci-lintやstaticcheckといったものがあります。
golangci-lintは厳密にはいろんなリントツールをまとめたものです。
ツールチェインの管理ですが、Rustではツールチェインの管理はrustupを使います。
たとえばrustup updateでコンパイラも含めツールチェインを更新できます。
rustupの詳細についてはこちらを参照してください。
GoはLSP以外はすべてgoコマンドのサブコマンドとして提供されているので、Goのバージョンを上げればツールチェインも更新されます。
こういったツールチェインは基本的にあんまり管理したくないので、Goのようにほぼすべてサブコマンドで提供しているのが個人的に嬉しいポイントです。
ライブラリ
統計を取ったわけではないのですが、GoはRustと比べてライブラリが豊富な印象があります。
特にGoの標準ライブラリのカバー範囲はかなり広く、主に次のものがあります。
- ファイル関連
- ネットワーク関連
- 文字列関連
- CLI関連
- 暗号関連
- 画像関連
- 日付関連
- エンコード関連
- ロック関連
- 正規表現
- 乱数
- ロガー
- DB
これだけあれば、大抵のことは標準ライブラリで物足りるかなというと思います。
一方Rustは標準ライブラリはとても薄く、プリミティブなものがほとんどです。
たとえばネットワーク関連の機能はTCP/UDPしかないです。
Goと比較すると次のような感じです。
| 機能 | Go | Rust |
|---|---|---|
| ファイル関連 | ○ | ○ |
| ネットワーク関連 | ○ | ▲ |
| 文字列関連 | ○ | ○ |
| CLI関連 | ○ | ▲ |
| 暗号関連 | ○ | x |
| 画像関連 | ○ | x |
| 日付関連 | ○ | x |
| エンコード関連 | ○ | x |
| ロック関連 | ○ | ○ |
| 正規表現 | ○ | x |
| 乱数 | ○ | x |
| ロガー | ○ | x |
| DB | ○ | x |
本体ライブラリが薄いので、基本的にプロダクトを作る場合はサードパーティ製ライブラリを使うことになります。
簡単ではありますが、ユースケースごとによく使われるライブラリを次の表にまとめました。
| ユースケース | Rustのライブラリ |
|---|---|
| Webフレームワーク |
actix-web, axum, warp
|
| HTTPクライアント | reqwest |
| DB |
diesel, sqlx, SeaORM
|
| エンコード | serde |
| 暗号関連 | ring |
| CLI関連 | clap |
| 非同期処理 | tokio |
| ロガー |
log, env_logger
|
個人的に標準ライブラリはもう少し厚くしてもよいんじゃないかなと思っていて、
Rustでウェブ開発する上でこういったサードパーティ製を使わないと行けないのは少しコミュニティに依存しすぎているかなという感覚があります。
ビルドシステム
GoとRustのビルド周りは色々と異なる点があります。
たとえばGoではコンパイラとリンカーをすべて1から作っていて、既存の資産を使っていないです。
これはすごいことで、Googleのパワーがあるからこそできることかなと思っています。
一方RustではコンパイラのバックエンドとしてLLVMを採用していて、それ経由で実行バイナリが作られます。
他の主な違いについて説明してきます。
ビルドプロファイル
Goにはない機能ですが、Rustではビルドのプロファイルという概念があります。
組み込みのプロファイルは次の4つあります。
| プロファイル | 概要 |
|---|---|
| dev | デバッグ時に使用 |
| release | リリース時に使用 |
| test | テスト時に使用 |
| bench | ベンチマーク時に使用 |
cargo buildやcargo run、cargo testはデバッグビルドで実行され、デバッグ情報を含んだバイナリが作られるのと、実行速度もリリースビルドと比べて遅いです。
cargo build --releaseとcargo benchはリリースビルドとして実行されます。本番リリース時はこちらを使用します。
各プロファイルでコンパイルの設定ができ、たとえばデバッグビルド時に最適化を無効化できたりします。
設定はCargo.tomlに記述します。
[profile.dev]
opt-level = 0
組み込み以外にも独自のプロファイルも追加できます。
[profile.release-lto]
inherits = "release"
lto = true
cargo build --profile release-lto
シンプルにビルドするだけならばGoと大差ないですが、もっと細かくカスタマイズしたいときに便利なのでRustのこういったところはよい点だなと思っています。
クロスコンパイル
GoとRustともにクロスコンパイルに対応しています。
Goの場合はGOOS=linux GOARCH=amd64 go buildといった感じで環境変数でアーキテクチャを指定します。
一方RustはGoと比べて少し手間がかかります。
まず対象アーキテクチャをターゲットに追加する必要があります。
rustup target add x86_64-pc-windows-gnu
ターゲットは、対象アーキテクチャの静的Rustライブラリ(rlib)の集まりで、コンパイル時に使われます。
$ ll ~/.rustup/toolchains/stable-aarch64-apple-darwin/lib/rustlib/x86_64-pc-windows-gnu/lib
drwxr-xr-x skanehira staff 1.1 KB 2024-08-10 09:37:39 .
drwxr-xr-x skanehira staff 96 B 2024-08-10 09:37:39 ..
.rw-r--r-- skanehira staff 398 KB 2024-08-10 09:37:39 libaddr2line-cafead5e166395dc.rlib
.rw-r--r-- skanehira staff 29 KB 2024-08-10 09:37:38 libadler-a78f8ec11f17a280.rlib
.rw-r--r-- skanehira staff 5.5 MB 2024-08-10 09:37:39 liballoc-0d87392afa62cfaa.rlib
.rw-r--r-- skanehira staff 8.6 KB 2024-08-10 09:37:39 libcfg_if-6be57f0603b9b79d.rlib
(略)
次にクロスコンパイル用のリンカーもインストーする必要があります。
たとえx86_64-pc-windows-gnuならmacOSではmingw-w64をインストールします。
brew install mingw-w64
これで事前準備が整ったのであとは--targetでターゲットを指定してビルドすれば実行バイナリが作られます。
$ cargo build --target x86_64-pc-windows-gnu
$ file target/x86_64-pc-windows-gnu/debug/hello.exe
target/x86_64-pc-windows-gnu/debug/hello.exe: PE32+ executable (console) x86-64, for MS Windows
このように、RustのクロスコンパイルはGoと比べてちょっと手間がかかります。
ただ、こういった準備不要でクロスコンパイルをもっと手軽にできるツールとしてcrossがあります。
crossを使うと次のような感じで事前準備なしにクロスコンパイルできます。
$ CROSS_CONTAINER_OPTS="--platform linux/x86_64" cross build --target x86_64-pc-windows-gnu
crossがあるとはいえ、Goと比べてRustのクロスコンパイルは少々手間がかかるので、改めてGoのクロスコンパイルの手軽さはすごいなと思います。
成果物
Goの場合はgo build実行したパスに成果物が出力されます。
Rustの場合は成果物はtarget配下に出力されますが、ターゲットとプロファイルによって出力先が異なります。
たとえばデバッグビルドの場合はtarget/debug/foo、リリースの場合はtarget/release/fooといった感じです。
ターゲット指定の場合はさらに1つ階層が深くなり、target/{target}/debug/fooという感じになります。
target配下は他にもインクリメンタルビルドの中間成果物があります。
Rustはビルド時間短縮のためインクリメンタルビルドをサポートしていて、その中間成果物をtarget配下においています。
ただ、ビルド時間は速くなる分、中間成果物は溜まるので要注意です。
プロジェクトの規模にもよりますが、筆者はきづいたら数百GBほど溜まった経験をしたことがあります。
定期的にcargo cleanでtargetを掃除するとよいかなと思います。
ビルド速度
比較データがあるわけではないですが、体感的にRustはGoと比べてビルドが遅いです。
Rustのビルドが遅いという情報や話は多いので、おそらく間違い無いかなと思っています。
そのためかRustのビルド時間を短くするためTipsがまとめられたり、ビルドが遅い問題をどのように調査したかといった記事があります。
他には次のような、ビルド速度重視/実行速度重視の設定を自動で生成してくれるツールもあります。
領域
GoとRustが使われている領域としておもにフロントエンド・バックエンド・組み込みがあるかなと思います。
フロントエンド
フロントエンド領域でGoが使われた事例として一番有名なのはやはりバンドラーのesbuildではないかなと思います。
対してRustでは最近かなりの勢いでフロントエンドのツールチェインで使われています。
有名ところでは次のようなものがあります。
| ツール | 概要 |
|---|---|
| https://biomejs.dev | リンター・フォーマッター |
| https://oxc.rs | リンター |
| https://swc.rs | トランスパイラー |
| https://rolldown.rs | バンドラー |
他にも次世代JavaScript/TypeScript RuntimeであるDenoもRust製です。
バックエンド
バックエンド領域ではRustはGoと同様、主にシステム開発と開発ツール周辺に使われていることが多い印象です。
Goの場合、有名なところでいえばDockerやk8sといったコンテナ周辺のエコシステムに使われているといったところでしょうか。
Rustの場合、そういったエコシステムよりも、REST APIやGraphQL APIを用いたシステム開発で使われている印象です。
開発ツール周辺ではRust製のものが最近増えてきたかなという印象です。
有名なところでいうと次のものといったところでしょうか。
| ツール | 概要 |
|---|---|
| https://wezfurlong.org/wezterm/index.html | ターミナル |
| https://zed.dev | エディタ |
| https://github.com/sharkdp/bat | 高機能cat |
| https://github.com/BurntSushi/ripgrep | 高速grep |
| https://github.com/Byron/dua-cli | 高機能du |
他にも色々あるので、興味ある方はこちらを見てみてください。
組み込み
筆者組み込みはまったく知らないので、紹介程度にとどめますが、GoとRustともに組み込みで使えます。
Goの場合はtinygoという組み込み向けのコンパイラが別途開発されているので、こちらを使うことになります。
Rustの場合は別途コンパイラは不要でそのまま書けるようです。
詳細はこちらを参照してください。
さいごに
色々な側面でGoとRustの違いをまとめてみましたが、結局トレードオフかなぁと思いました。
たとえば言語の利便性が上がれば、学習コストも上がるし複雑にもなっていきます。
よく考えると当たり前の話ではありますが、言語選定時に長所と短所を調べるのも大事だけど、専門領域と思想を理解しておくことも大事と思いました。
-
Rustに限らずプログラミング言語では確保した値や参照には生存期間があるので、厳密にはライフタイムは普遍的な概念と思っている。しかし、Rustではよりライフタイムを意識する必要がある、またシンタックスにもライフタイムが現れることから「ライフタイムでメモリ安全を実現している」という記述をしている。 ↩︎
-
厳密にRustでは
Copyトレイトを実装したものであれば自動でコピーされる ↩︎ -
Goでいうとインターフェイスにあたるもの ↩︎
-
Goでいうとパッケージにあたる ↩︎
-
Goでいうとパッケージに相当するもの ↩︎
-
awaitを跨いでロックを保持したい場合はtokioのtokio::sync::Mutexを使う必要がある ↩︎
Discussion
ものすごい網羅量で圧倒されました。良質なまとめをありがとうございます!
脚注6番に
とありますが、このコード例であれば
std::sync::Mutexでも問題なく動くかなと思います。また、Mutex in tokio::sync - Rustによると、
ChatGPT訳(ちょっと改変あり)↓
とあるので、今回のコード例のようにロックが.awaitをまたがないケースであれば
std::sync::Mutex(あるいはparking_lot::Mutex) を使うことが望ましいようです。非常に充実した記事をありがとうございました!
Rustはほんの少しだけ書いたことがあるだけだったので忘れたことや知らなかったことも多く、
普段よく書いているGoと比較しながら復習できるので、辞書的にも使えるとてもありがたい資料だと思いました!とても面白かったです…!
いくつか、Go側について少しだけ補足的にコメントさせていただきます!
GoとRustのジェネリクスの違いについて
についてですが、
実は、インラインでinterfaceを書くこともできます。
ただ、「interface elementが一つのみかつ、メソッドではなくtype elementのみが含まれる」ケースで使える省略記法 (
[T string|int]のようなもの) が使えないので、記法としてはやや無骨にはなってしまいますね…。テストの実行について
(基本的にと書かれているので余計かもしれませんが、) 一応、別packageのテストについてはデフォルトで並列に実行されるようです。
デフォルトの並列数は、利用可能なCPU数となります。
参考: https://engineering.mercari.com/blog/entry/how_to_use_t_parallel/
全てのテストをデフォルトで並列に実行するRustの振る舞いが理想的なのは完全に同意です (Goだとそれをデフォルトの挙動にしたら競合しまくるので…)
改めて、非常に参考になる記事をありがとうございました!
@magurotuna
なるほどー
知らなかったです!
ありがとうございます!
脚注を修正しておきました!
@syumai
おお、知らなかったです!
勉強になります
コレも知らなかったです!
ありがとうございます!
諸々追記しておきました!
大変素晴らしい記事ありがとうございます!
Rust がコンパイル時に型ごとのコードを生成しますとあってGoはそうでないように見えますが、
Goもgo shape の後にコード生成されるので実際のアセンブリコードは
それぞれ別のアセンブリに生成されているので同じことだと思います。
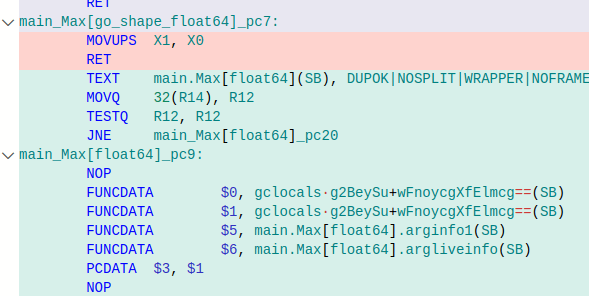
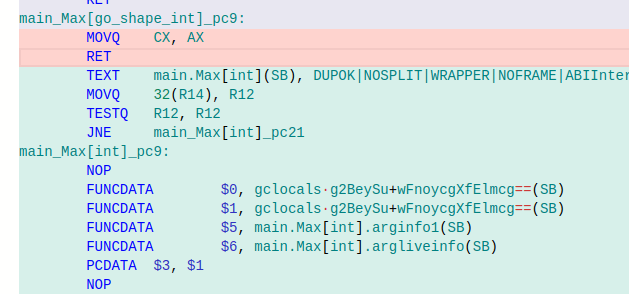
(アセンブリの
[]はただの名前に括弧が入っているだけです)自分の理解が間違っているようですが、desgin doc を読んで改めて調べてみます
ありがとうございます!
大変な力作尊敬します。すごい...
一点、表現の問題だとは思いますが、 テストの記述について のところにあった記述が気になりました。
同一ファイル内に書くかどうかは異なりますが、Go でもテストファイルのパッケージ名を同一にすることでプライベートな関数のテストが書ける点、補足できればと。(Go でプライベートな関数のテストが書けないという意味で書かれたわけではないと思いますが、念の為...)
@mythrnr
ありがとうございます!
たしかにパッケージが同じならプライベート関数のテスト書けますね
失念していました!
その旨を追記しました!
秀逸な記事ありがとうございます!
ざっと確認した限りですが、ドキュメントテストについては、GoでもRust相当のことはできるのではないでしょうか?
Goのドキュメントテストの特徴としては
といったところでしょうか。ご参考ください。