Llama3.2アップデート内容
Meta、Llama 3.2を発表:エッジAIとビジョンを革新するオープンでカスタマイズ可能なモデル
本記事は、Meta AI公式ブログの「Llama 3.2: Revolutionizing edge AI and vision with open, customizable models」の内容をまとめたものです。2024年9月25日に発表されたLlama 3.2の主要な特徴をまとめて解説します。
Metaが発表したLlama 3.2は、エッジAIと視覚理解タスクに革新をもたらす次世代の大規模言語モデルです。小型デバイスから高性能システムまで幅広く対応し、オープンソースで提供されることで、AIの民主化と革新の加速を目指しています。以下に、Llama 3.2の主な特徴と重要なポイントをまとめます。
主なポイント
- Llama 3.2は、小型・中型のビジョンモデル(11Bと90B)と、エッジ・モバイルデバイス向けの軽量テキストモデル(1Bと3B)を含む。
- 1Bと3Bモデルは128Kトークンのコンテキスト長をサポートし、エッジでの要約、指示遵守、書き換えタスクで最先端の性能を発揮。
- ビジョンモデルはClaude 3 HaikuやGPT4o-miniなどのクローズドモデルを上回る画像理解能力を持つ。
- Llama Stackが導入され、様々な環境での開発とデプロイを簡素化。
- 安全性強化のため、Llama Guard 3 11B VisionとLlama Guard 3 1Bを導入。
Llama 3.2の主な特徴
-
ビジョンモデル(11Bと90B):
- 画像理解タスクに対応
- 文書レベルの理解(チャートやグラフを含む)
- 画像のキャプション生成
- 視覚的な物体特定
- テキストモデルと同等の性能を維持しつつ、画像入力をサポート
-
軽量テキストモデル(1Bと3B):
- エッジデバイスや携帯端末での実行に最適化
- 128Kトークンの長いコンテキスト長をサポート
- 多言語テキスト生成機能
- ツール呼び出し機能
-
柔軟性:
- プリトレーニング済みとインストラクションチューニング済みの両バージョンを提供
- torchtuneを使用したカスタムアプリケーション向けの微調整が可能
性能評価
Llama 3.2の性能は、広範囲の言語をカバーする多様なベンチマークデータセットで評価されました。軽量モデル(1Bと3B)とビジョンモデル(11Bと90B)の両方について、具体的なベンチマーク結果を示します。
ビジョンLLM(11Bと90B)のベンチマーク結果:
-
MMMU (val, 0-shot CoT, micro avg accuracy):
- Llama 3.2 11B: 50.7
- Llama 3.2 90B: 60.3
- 比較:Claude 3 - Haiku (50.2), GPT-4o-mini (59.4)
-
MMMU-Pro, Vision (test):
- Llama 3.2 11B: 23.7
- Llama 3.2 90B: 33.8
- 比較:Claude 3 - Haiku (20.1), GPT-4o-mini (36.5)
-
MathVista (test/mini):
- Llama 3.2 11B: 51.5
- Llama 3.2 90B: 57.3
- 比較:Claude 3 - Haiku (46.4), GPT-4o-mini (56.7)
-
ChartQA (test, 0-shot CoT relaxed accuracy):
- Llama 3.2 11B: 83.4
- Llama 3.2 90B: 85.5
- 比較:Claude 3 - Haiku (81.7), GPT-4o-mini (データなし)
-
AI2 Diagram (test):
- Llama 3.2 11B: 91.1
- Llama 3.2 90B: 92.3
- 比較:Claude 3 - Haiku (86.7), GPT-4o-mini (データなし)
-
DocVQA (test, ANS-SH):
- Llama 3.2 11B: 88.4
- Llama 3.2 90B: 90.1
- 比較:Claude 3 - Haiku (88.8), GPT-4o-mini (データなし)
これらの結果から、以下の点が明らかになりました:
-
Llama 3.2の90Bモデルは、ほぼすべてのビジョン関連タスクでClaude 3 - Haikuを上回り、多くの場合GPT-4o-miniと同等以上の性能を示しています。
-
特に、チャートや図表の理解(ChartQA、AI2 Diagram)において、Llama 3.2モデルは非常に高い性能を発揮しています。
-
11Bモデルでさえ、多くのタスクでClaude 3 - Haikuを上回る性能を示しており、モデルサイズに対して非常に効率的な性能を実現しています。
-
文書視覚質問応答(DocVQA)タスクでは、Llama 3.2の両モデルがClaude 3 - Haikuと互角以上の性能を示しています。
-
数学的視覚推論(MathVista)においても、Llama 3.2モデルは競合モデルを上回る、または匹敵する性能を示しています。

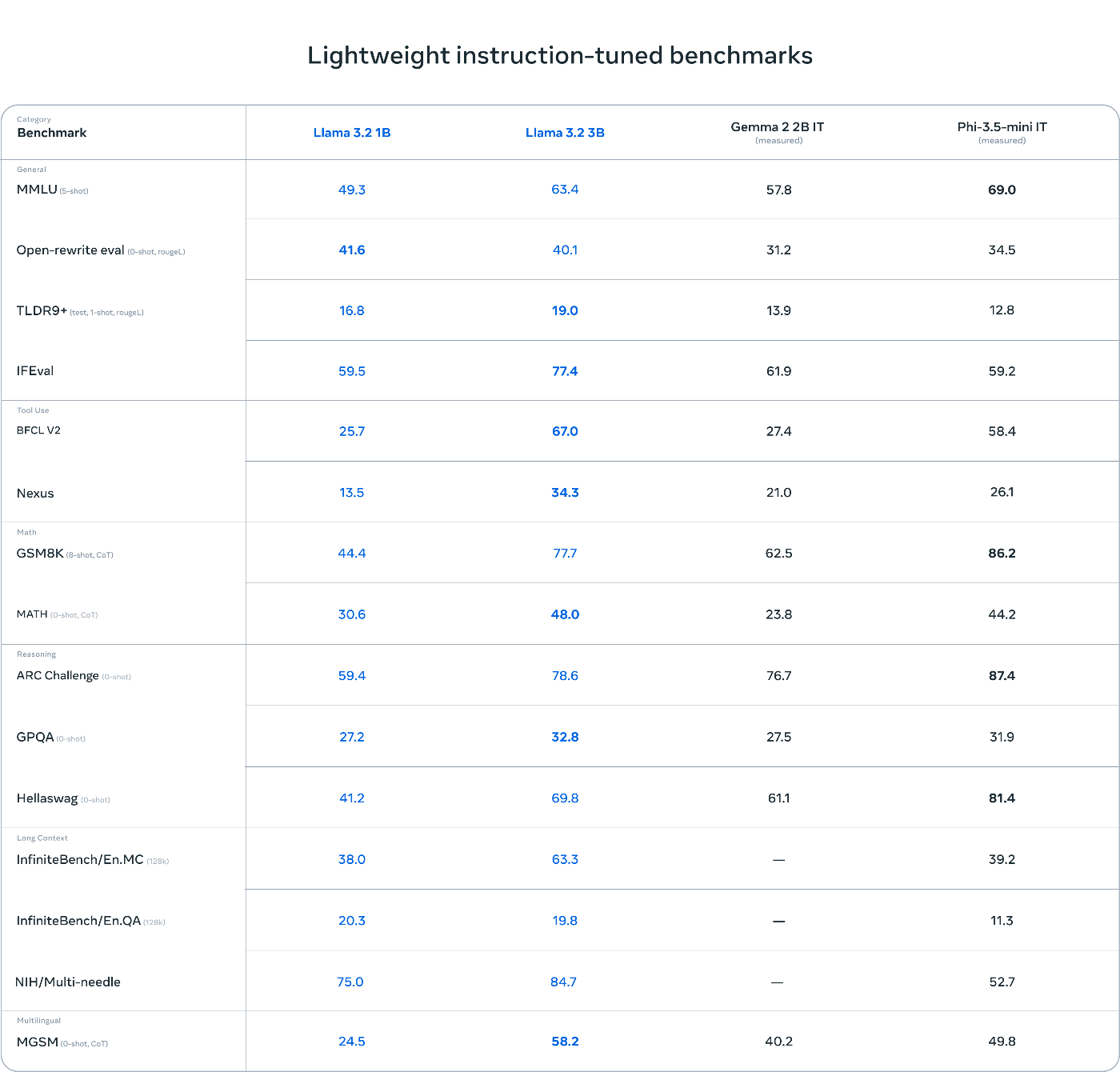
軽量モデル(1Bと3B)の主要なベンチマーク結果:
-
MMLU (5-shot):
- Llama 3.2 1B: 49.3
- Llama 3.2 3B: 63.4
- 比較:Gemma 2 2B IT (57.8), Phi-3.5-mini IT (69.0)
-
Open-rewrite eval (0-shot, single):
- Llama 3.2 1B: 41.6
- Llama 3.2 3B: 40.1
- 比較:Gemma 2 2B IT (31.2), Phi-3.5-mini IT (34.5)
-
IFEval:
- Llama 3.2 1B: 59.5
- Llama 3.2 3B: 77.4
- 比較:Gemma 2 2B IT (61.9), Phi-3.5-mini IT (59.2)
-
BFCL V2 (Tool Use):
- Llama 3.2 1B: 25.7
- Llama 3.2 3B: 67.0
- 比較:Gemma 2 2B IT (27.4), Phi-3.5-mini IT (58.4)
-
ARC Challenge (0-shot):
- Llama 3.2 1B: 59.4
- Llama 3.2 3B: 78.6
- 比較:Gemma 2 2B IT (76.7), Phi-3.5-mini IT (87.4)
これらの結果から、以下の点が明らかになりました:
- Llama 3.2 3Bモデルは、多くのタスクでGemma 2 2B ITを上回り、Phi-3.5-mini ITと同等以上の性能を示しています。
- 特に指示遵守(IFEval)とツール使用(BFCL V2)のタスクでは、Llama 3.2 3Bが他のモデルを大きく上回っています。
- Llama 3.2 1Bモデルも、そのサイズを考慮すると非常に競争力のある性能を示しており、特にOpen-rewrite evalタスクではより大きなモデルを上回っています。
- 複雑な推論を必要とするARC Challengeでは、Llama 3.2 3Bが非常に高いスコアを達成し、より大きなモデルに匹敵する性能を示しています。
これらの評価結果は、Llama 3.2が軽量モデルからビジョンLLMまで、幅広い用途で高い性能を発揮することを示しています。特に、3Bモデルと90Bモデルは多くのベンチマークで同等以上のパラメータ数を持つモデルを上回る性能を示しており、エッジデバイスやモバイルアプリケーション、そして高度なビジョンAIタスクにおいて非常に有効であることが分かります。Llama 3.2は、オープンソースモデルでありながら、一部の商用クローズドモデルを上回る性能を達成しており、AIの民主化と革新の加速に大きく貢献する可能性を示しています。
instruction-tuningについてはこちらの記事をご参照ください
技術的詳細
ビジョンLLMの開発プロセス
- プリトレーニング済みのLlama 3.1テキストモデルに画像エンコーダーとアダプターを追加
- 大規模なノイズの多い(画像、テキスト)ペアデータでプリトレーニング
- 中規模の高品質な領域内および知識強化された(画像、テキスト)ペアデータで訓練
- 教師あり微調整、棄却サンプリング、直接選好最適化による複数ラウンドのアライメント
軽量モデルの開発手法
-
プルーニング:
- Llama 3.1 8Bモデルを基に、構造化プルーニングを一発で適用
- ネットワークの一部を系統的に削除し、重みと勾配の大きさを調整
- 元のネットワークの性能を維持しつつ、より小さく効率的なモデルを作成
-
知識蒸留(Knowledge Distillation):
- Llama 3.1 8Bと70Bモデルのロジットをプリトレーニング段階で活用
- 大きなネットワークの知識を小さなネットワークに伝達
- プルーニング後に適用し、性能を回復
-
ポストトレーニング:
- プリトレーニング済みモデルに対して複数ラウンドのアライメントを実施
- 各ラウンドは教師あり微調整(SFT)、棄却サンプリング(RS)、直接選好最適化(DPO)で構成
- 128Kトークンのコンテキスト長サポートへのスケーリング
- 高品質な合成データ生成と慎重なデータ処理・フィルタリングを実施
これらのプロセスにより、Llama 3.2の軽量モデルは、エッジデバイスでの効率的な実行を可能にしつつ、高い性能を実現しています。

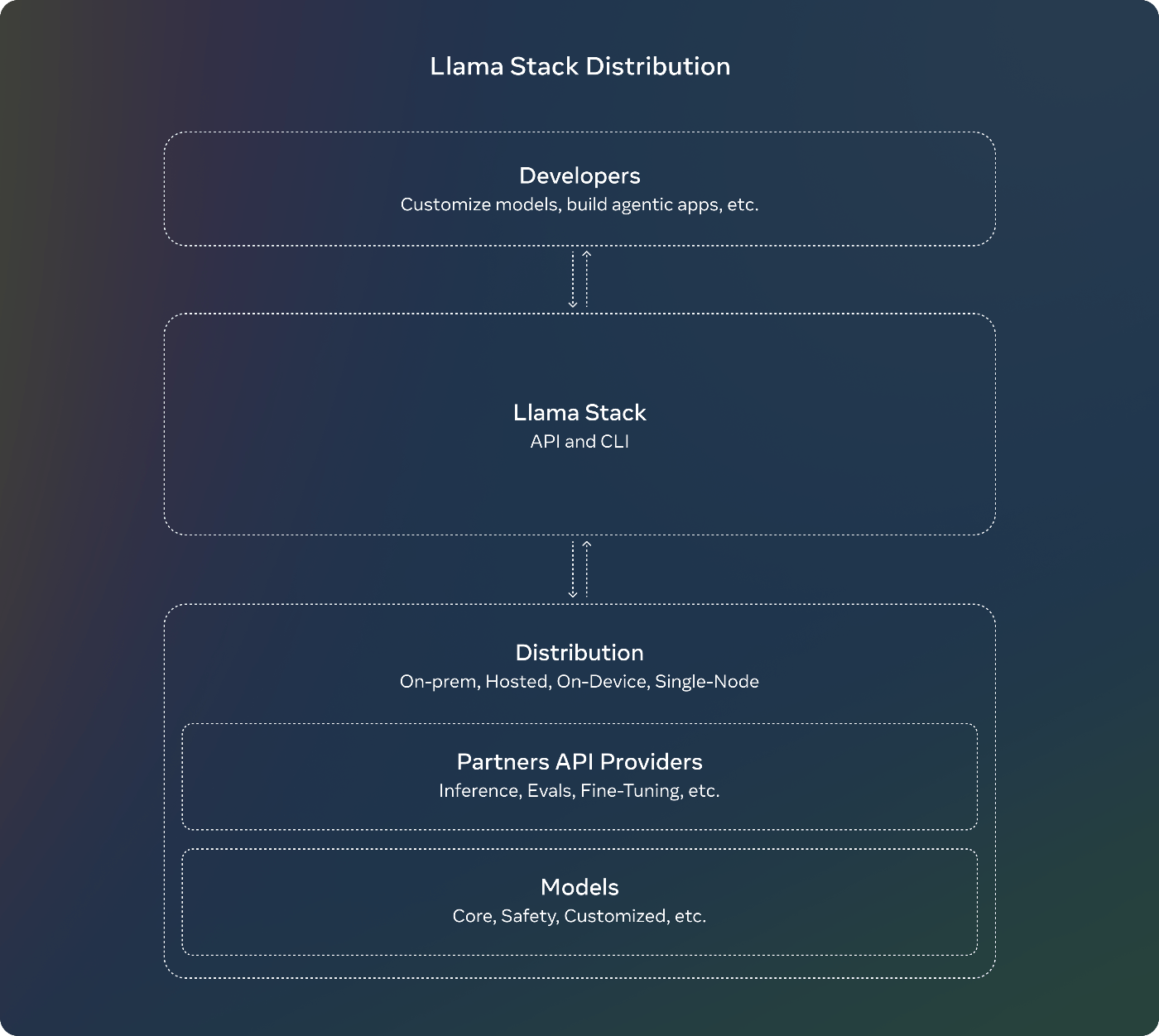
Llama Stack
Llama Stackは、開発者がLlamaモデルを様々な環境で簡単に利用できるようにする統合開発・デプロイメント環境です。
主な特徴:
- Llama CLI:Llama Stack distributionsの構築、設定、実行用
- 複数言語(Python、Node、Kotlin、Swift)のクライアントコード
- Llama Stack Distribution ServerとAgents API ProviderのためのDockerコンテナ
- 複数の配布形態:
- 単一ノード:Meta内部実装とOllama
- クラウド:AWS、Databricks、Fireworks、Together
- オンデバイス:PyTorch ExecuTorchを使用したiOS実装
- オンプレミス:Dellがサポート
安全性への取り組み
Llama 3.2の発表に合わせて、新しい安全対策が導入されました:
-
Llama Guard 3 11B Vision:
- ビジョンLLMの新しい画像理解機能をサポート
- テキスト+画像入力プロンプトやそれに対する応答をフィルタリング
-
Llama Guard 3 1B:
- オンデバイス用に最適化
- Llama 3.2 1Bモデルをベースに開発
- プルーニングと量子化により、サイズを2,858 MBから438 MBに削減
これらの安全対策は、リファレンス実装、デモ、アプリケーションに統合され、オープンソースコミュニティが初日から利用できるようになっています。
利用可能性とパートナーシップ
- モデルのダウンロードが可能なサイト:
- llama.com: https://www.llama.com/
- Hugging Face: https://huggingface.co/meta-llama
- AMD、AWS、Databricks、Dell、Google Cloud、Groq、IBM、Intel、Microsoft Azure、NVIDIA、Oracle Cloud、Snowflakeなど、25社以上のパートナー企業のプラットフォームで即時開発が可能
- Arm、MediaTek、Qualcommとの協力により、オンデバイスサービスを提供
Llamaの進化と成長
- Llama 3.1発表からわずか2ヶ月で、Llama 3.2を発表
- 最初のLlama発表から1年半で、10倍の成長を達成
- 責任ある革新のための標準となり、オープン性、修正可能性、コスト効率で業界をリード
オープンソース戦略の意義
Metaは以下の理由からオープンソースアプローチを重視しています:
- より多くの人々がAIの機会にアクセスできるようにする
- 少数の手に力が集中するのを防ぐ
- 社会全体でより公平かつ安全に技術を展開する
将来の展望
- Llama 3.2により、AIテクノロジーがより広く、より安全に社会全体に展開されることが期待される
- エッジデバイスでのAI処理能力の向上と、視覚理解タスクへの対応拡大により、AIの応用範囲が大きく広がる可能性
- Metaは引き続きオープンソースコミュニティとの協力を重視し、責任あるAI開発を推進
Llama 3.2の発表は、AIの民主化と革新の加速に向けた重要な一歩となります。Metaは、オープンな開発アプローチが、開発者、Meta自身、そして世界全体にとって有益であると確信しています。
Discussion