はじめに
こんにちは、松尾研GENIACプロジェクト、チームビジネスの角谷あおいです。
東京大学松尾研究室にて、経済産業省によるGENIACの国産大規模言語モデル(Large Language Model: LLM)開発に参加しています。早くもPhase1が終了しましたが、開発過程や知見を外部に発信していくこととなりました。今回は、チームビジネスにおけるInstruction-Tuning手法についてご紹介します。
Instruction-Tuningとは
LLMは、一般的に以下のようなプロセスで構築され、事前学習が完了したモデルには、教師ありデータセットを用いたInstruction-Tuningが行われます。
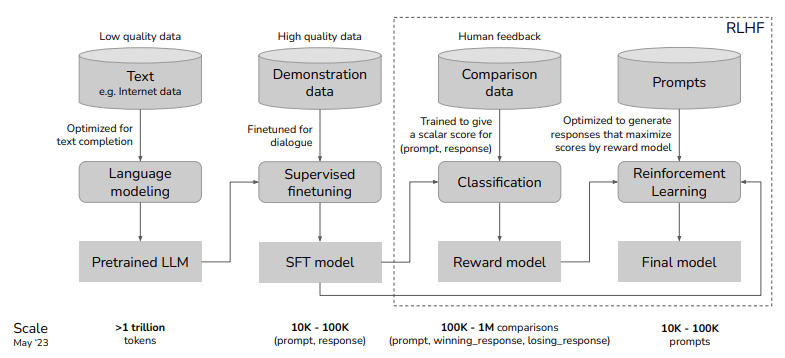
モデル生成時には、入力に対して適切な応答が求められますが、事前学習の段階では主に最適な次の単語を予測するように学習されています。この問題を解決するために、モデルに一般的な指示に従う能力を向上させ、より有用で正確な応答を引き出すことを目的として、Instruction-Tuningが行われます。
Self-Instructによるデータセット作成
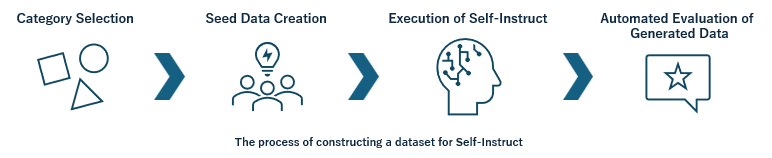
今回の検証では、公開されているInstruction-Tuning用データセットに加え、Self-Instructに基づくデータセットの作成をメンバー間で行いました。Self-Instructとは、モデル自身がInstruction-Tuningデータを生成し、それを活用する手法で、多様で質の高い指示データを通じて精度向上が期待されます。

一部のモデル(OpenAIなど)には規約や禁止事項が存在するため、今回は以下の手順に基づき、Mixtral8*22Bモデルを使用してInstruction-Tuningデータを作成しました。
- Category Selection(カテゴリ選定):
まず、どのようなデータセットを作成すべきかを検討し、WandBのホワイトペーパーも参考にしながらカテゴリ分けを行いました。今回は約20のカテゴリを定めました。 - Seed Data Creation(種データの作成):
それぞれのカテゴリで10個程度の種データを作成しました。これは、Self-Instruct時の生成データに一貫性を持たせるためであり、Few-Shotプロンプトの考え方に基づいています。 - Execution of Self-Instruct(Self-Instructの実行):
Mixtral8*22Bを用いて、それぞれ数百から数千のデータセットが作成されました。 - Automated Evaluation of Generated Data(生成後データの自動評価):
生成後のデータは必ずしも完璧ではないため、Mixtralによる自動評価を行いました。この自動評価では、良し悪しの判断だけでなく、修正も行い、データ量の確保にも注意を払いました。
なお、最終的に以下のようなデータセットが作成されました。

Instruction-Tuningの結果
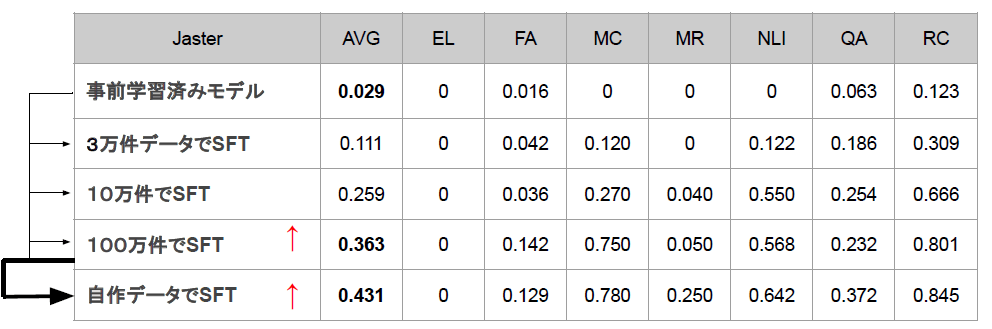
Instruction-Tuningの結果は以下の通りです。データセットのサイズが増えるほど、Jasterのスコアが向上しました。また、Self-Instructのデータセットもスコア向上に寄与しました。
一方で、スコアがあまり向上しないカテゴリも存在しました。これには、評価データセット自体がスコア向上しにくいものであることや、Instruction-Tuning内にこれらのタスクに一致するようなデータが存在しないことが原因として考えられます。
後者の場合、Instruction-Tuningではベンチマークに合わせた形式で学習させることでスコア向上が見込まれますが、それは1つのベンチマークにフィットしたモデルに過ぎません。本来目指すべき基礎能力の向上やビジネス用LLMの開発とは目的が異なるため、今回はこの戦略を採用しませんでした。
最後に
本記事では、チームビジネスにおけるInstruction-Tuning手法についてご紹介しました。まだ解明されていない点も多いため、今後も検証と調査を続けていきたいと考えています。
ここまでお読みいただき、ありがとうございました!
参考
この成果は、NEDO(国立研究開発法人新エネルギー・産業技術総合開発機構)の助成事業「ポスト5G情報通信システム基盤強化研究開発事業」(JPNP20017)の結果得られたものです。
![東大松尾・岩澤研究室 | LLM開発 プロジェクト[GENIAC]](https://storage.googleapis.com/zenn-user-upload/avatar/f9404760b8.jpeg)
東京大学 松尾・岩澤研究室が運営する松尾研LLMコミュニティのLLM開発プロジェクト[GENIAC] の開発記録、情報発信になります。 各種リンクはこちら linktr.ee/matsuolab_community
Discussion