レポート:Cross Data Platforms Meetup #1 DatabricksとSnowflakeで作るデータプラットフォーム
"様々なサービスが日々生まれているデータ分析プラットフォームにおいて、特定のサービスによらない事例の共有や議論の場を提供する会"として設立されたコミュニティ、『Cross Data Platforms Meetup』。
今回、その記念すべき1回目のイベントが2025年04月22日(火)に開催されました。
個人的にもこの辺りのテーマは気になっていたところでしたので参加申し込み。現地オフラインのみの開催でしたので現地参加の雰囲気なども交えてレポートしたいと思います。
開催会場はdocomo R&D OPEN LAB ODAIBA。私個人的にも最近この会場で開催されているイベントに何回か足を運んでいますが、この場所良いですよねぇ。



参加者は受付で「使った事があるDWH(データウェアハウス)」のリストバンドを身に付ける形になっていました。どの色がどのサービスであるかは明言されてはいませんでした("赤いサービス、青いサービス、それ以外")。

会場風景。こちらの写真自体は開始20分前くらい、まだ参加者が集まり切る前に撮ったものですが、当日は最終的には椅子やテーブルを追加で設置するくらい(最終的には5〜60人以上?)多くの方々が現地に集う形となっていました。

オープニング
- 登壇者:こみぃさん( @kommy_jp )

今回は1回目ということもあり、会の趣旨周りについて少し長めに時間を取る形で説明がありました。
とその前にスポンサーの紹介アリ。飲食スポンサーにtruestarさん、会場提供にdocomoさんのお力を借りる形となりました。ありがとうございます!


そして会のコンセプトを説明。
-
現代のデータプラットフォーム構築は「ツールの併用」が基本
- 様々な選択肢に対して、各社事情に合わせた最適なツールを選びたい。
-
「併用の事例」を狙って収集するのは非常に困難
- SnowflakeとDatabricksは競合サービスと呼ばれているが、実際は併用している例も多い
- 勉強会やイベントではどちらかのサービスに寄ったコミュニティが運営することが多く、そういった事例に出会えないことも多い
- という思いからこのコミュニティ(Cross Data Platforms Meetup)を作った
- 特定サービスに寄らない事例の共有の場を作ろう!
- 非推奨行為:あまりにも目に余る行為を見掛けたら退場処分、次回以降の会を出禁とする
要はこういうことですね。

こみぃさんのイベント(開催)に対する思いは下記のブログでも詳細に述べられています。
DatabricksとSnowflakeをつなぐ最新データ相互利用術
- 登壇者:manabianさん ( @manabian )

登壇資料(のベースになったブログエントリ)はこちら:
- DatabricksとSnowflake間における構造化データの統合手法について話します
- 近年、異なるDWH間でのでのデータ統合と相互運用性の確保が注目されている。その基本的な概念を整理したうえで実際の統合手法の具体例を紹介
- manabianさんのアウトプット:上流から下流に至るまでの記事を投稿
-
データ統合について
- データ統合:組織内に散在するデータを一貫した形式で集約するプロセス。
- データ統合と相互運用性についてはDMBOKにおいても重要な領域の1つとして考えられている
-
データ統合の2分類
- 物理データ統合:データを事前に移動・集約
- 仮想データ統合;データを移動せず仮想的に統合
-
上記の分類は特性が異なる。目的や利用シーンに応じた適切な使い分けが不可欠。仮想データ統合に関しては性能やコスト面での注意が必要
画像引用:DatabricksとSnowflakeをつなぐ最新データ相互利用術 #Databricks - Qiita
DatabricksとSnowflake間のデータ統合の実施に向けて
-
DWHへのデータローディングパターンが幾つかあり、DWH間でデータ統合に必要となる機能も色々ある
-
データ統合方法の機能と整理
- 機能:実装パターンに応じた機能の検討が要る

- 整理:両者以下のような方法、手段が存在する

- 機能:実装パターンに応じた機能の検討が要る
-
多くの場合、業務システムからデータを取り込むところから始まる。
- 今日はDWH間でデータ統合するところについて話します
-
Databricksにてデータ統合を行う際の主要トピック
-
Snowflakeにてデータ統合を行う際の主要トピック
データ統合パターン
- 以下のケースについてそれぞれ説明されていました。
- Snowflake-Databricksでの全件連携
- Databricks-Snowflakeでの差分連携
- Databrkcks-SnowflakeでのOTFに依る連携
スライドの内容に関しては冒頭言及のあったように予めブログエントリに記載の内容をギュッとスライド形式にまとめたものとなっています。それぞれの内容について詳細深堀りしたい場合は下記エントリ(再掲)を是非ご参照ください。
Databricksをsnowflakeにつなげてみてどうだった?
- 登壇者:yumimaroさん ( @YumiMaroo )

登壇資料は無し(2025年04月24日時点)。
データ分析基盤に対して感じる課題
- 統合性に課題のあるアーキテクチャが見られる
- データ活用が進んでいる企業は少ない
- 人材確保の面も含めて
- 実際に複数プラットフォームの併用は多くの企業で必要とされている
SnowflakeととDatabricksの連携
- 簡単なアーキテクチャ概要の説明
- ユースケース
- 前提
- アーキテクチャの概要

- How to
- 接続を作成
- フォーリンカタログを作成
- あとはDatabricks内で管理しているテーブル同様に繋ぐだけ
- 実践
- DatabricksでSQLクエリを実行
- PowerBIからデータに接続
データエンジニアとしてとるべき姿勢
- 目的意識を高く持つ
- 組織の文化に溶け込む迎合能力

Snowflake×Databricks CCCグループにおける2種類のハイブリッドアーキテクチャ事例
- 登壇者:タロウさん( @TARO9652512797 )

登壇資料(SpeakerDeck)はこちら:
- 自己紹介
- ちょうど一年前にTポイント→Vポイントリニューアルしていました
- Snowflake Data SuperHeroes 2025に選出されました!
- Snowflake推しですが、今日はフラットにお話したいと思います/どっちが良い、ではなく、どういうケースで組み合わせたかについて話します
- 本セッションの事例紹介2つ

事例紹介:Vポイント分析基盤
- CCCMKホールディングスの分析基盤史について紹介
- 現在では3種のDBをSnowflakeに統合、AI基盤もDatabricksに刷新
- DB統合に関して信じ切れる性能や機能を持つプラットフォームは2022年時点ではSnowflakeしかなかった
- ポイント
- 課題:既存の基盤移行を確実に移管し、DB統合を実現したい
- 制約:インフラのライフサイクルに合わせた移行計画があり、スケジュールに合わせたプランを綿密に練った
- 予見:グループ全体でのデータ統合や社外共有構想があった
- 現在の状況:分析基盤はSnowflake、AI基盤はDatabricks

- 総括:既存基盤からの移行が最命題で、かつ難易度が高い場合は以下の方針に振ることで確実な移行と拡張性のある構成を実現出来た。
- DWH機能や移植性、クエリ性能:Snowflake
- AI領域特化:Databricks
事例紹介:書籍オープンデータ基盤
-
Catalyst Data Partnersの事例
- 2021年09月:新設された同社に参画
- 2022年04月:TSUTAYAと日販のデータを統合した新サービスのリリース目標
- ...期間が半年しか無いよ?その他開発環境やデータセット定義、各種要件なども定まっていない状況
- 色々あったけどやりきった!
https://cdp-ltd.co.jp/
-
ポイント
- 課題:限られたリソースで基盤構築を行わなければならなかった
- 制約:開発期間が半年しか無い!
- 予見:非構造化データなど、将来的に取り組む可能性
- 要件を満たせる機能やビジョンの側面で見るとDatabricksが圧倒的優位だった
-
現在の状況:分析基盤はDatabricks、分析サービスにSnowflakeを活用。

-
総括:イチからの基盤構築(特に外部商用サービス)ならば、以下のような形で強みを活かすことが出来、生産性・柔軟性が高い構成で実現できる。
- 機能充実度による開発生産性:Databricks
- DWH機能による高パフォーマンス:Snowflake
まとめ

- 総括
- どっちの製品が良い!ではなく、解決すべき課題は何なのか。
- その課題にはどのような制約や予見があるのか?
- 与えられた条件の中で最大の成果を出すための基盤設計について
- それぞれの"課題解決"を最大化する構成を追求していきましょう!
- (追伸)言いたいこと→スライド参照
SnowflakeとDatabricks両方でRAGを構築してみた
- 登壇者:亀井友裕さん( @Camay119 )

登壇資料(SpeakerDeck)はこちら:
- 自己紹介
- 今日は事例ベースでの話ではないです
- 単純にRAG周りの機能を試してみた的な内容です
- (オープニングの話を聞いて)もしかしたら出禁的な内容に抵触する...?(全然だいじょうぶでしたよ
RAGって何?
- RAG(Retrieval Augmented Generation)
- LLMへの問い合わせの際、外部のドキュメントやデータベースから関連情報を検索し、LLMの回答に反映させる技術
- ベクトルインデックスの作成から回答の生成まで、8つのステップを経てパイプラインが実行される
- ソースとなるドキュメントを保存
- ドキュメントを小さなチャンクに分割
- チャンクをベクトルに変換
- 後の検索に備えてベクトルをストレージに保存
- ユーザーからの質問入力
- チャンクの取得
- プロンプト作成
- 回答生成
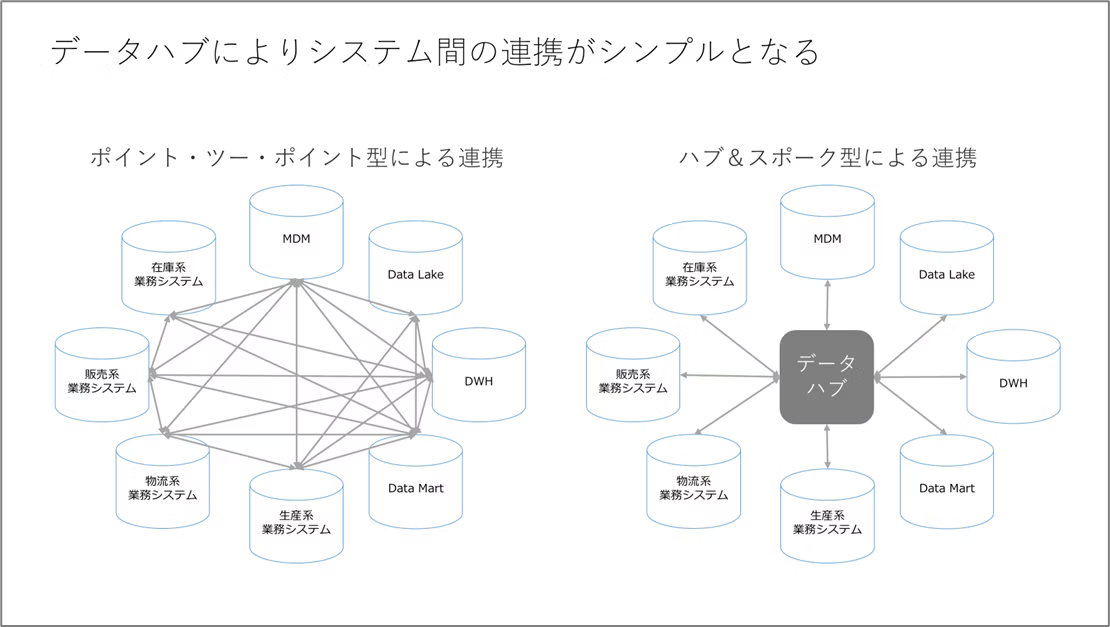
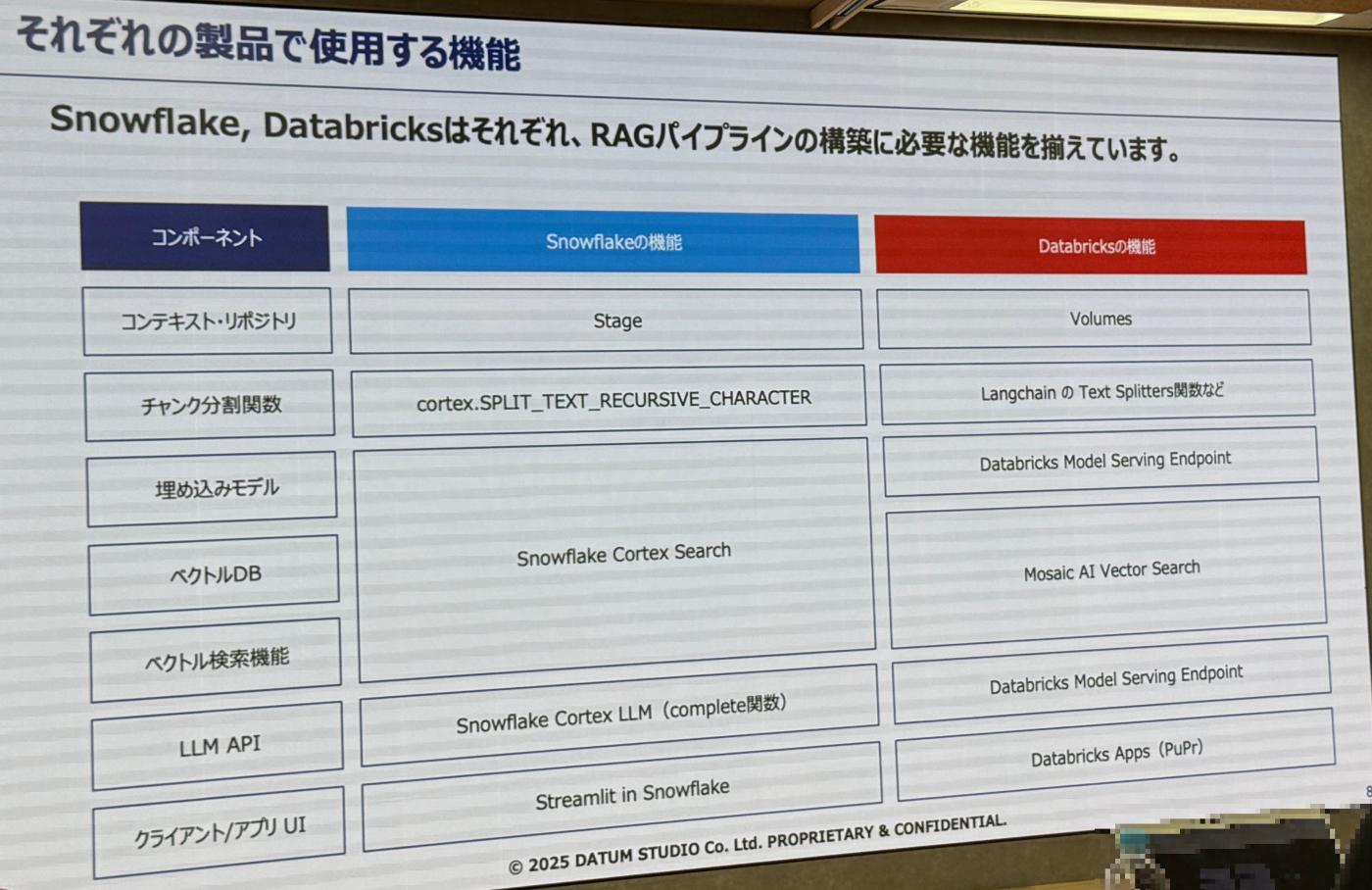
- RAG構築に必要なコンポーネントがあり、SnowflakeとDatabricksはそれぞれ必要な機能を備えている。
実際に作ってみよう
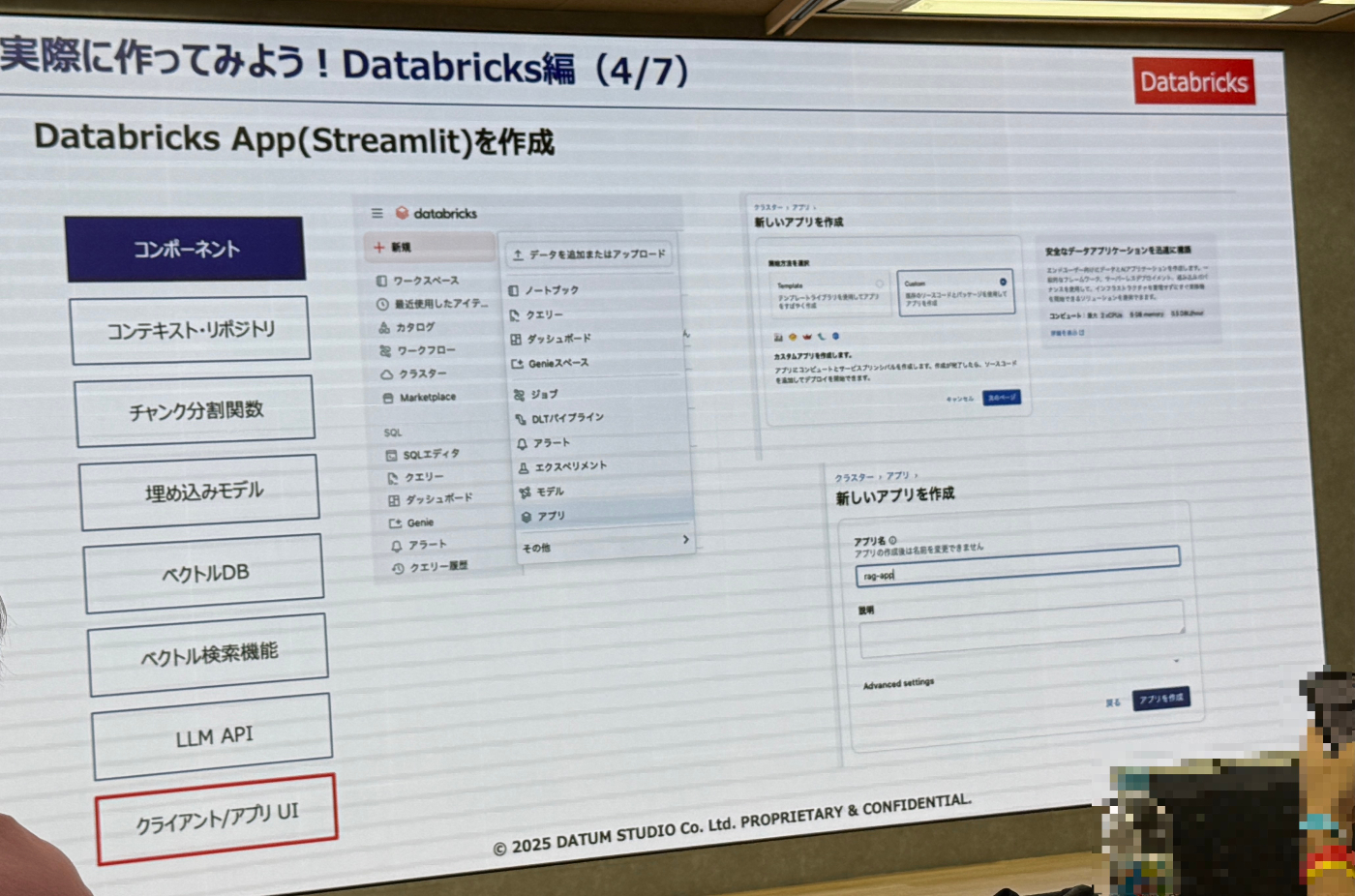
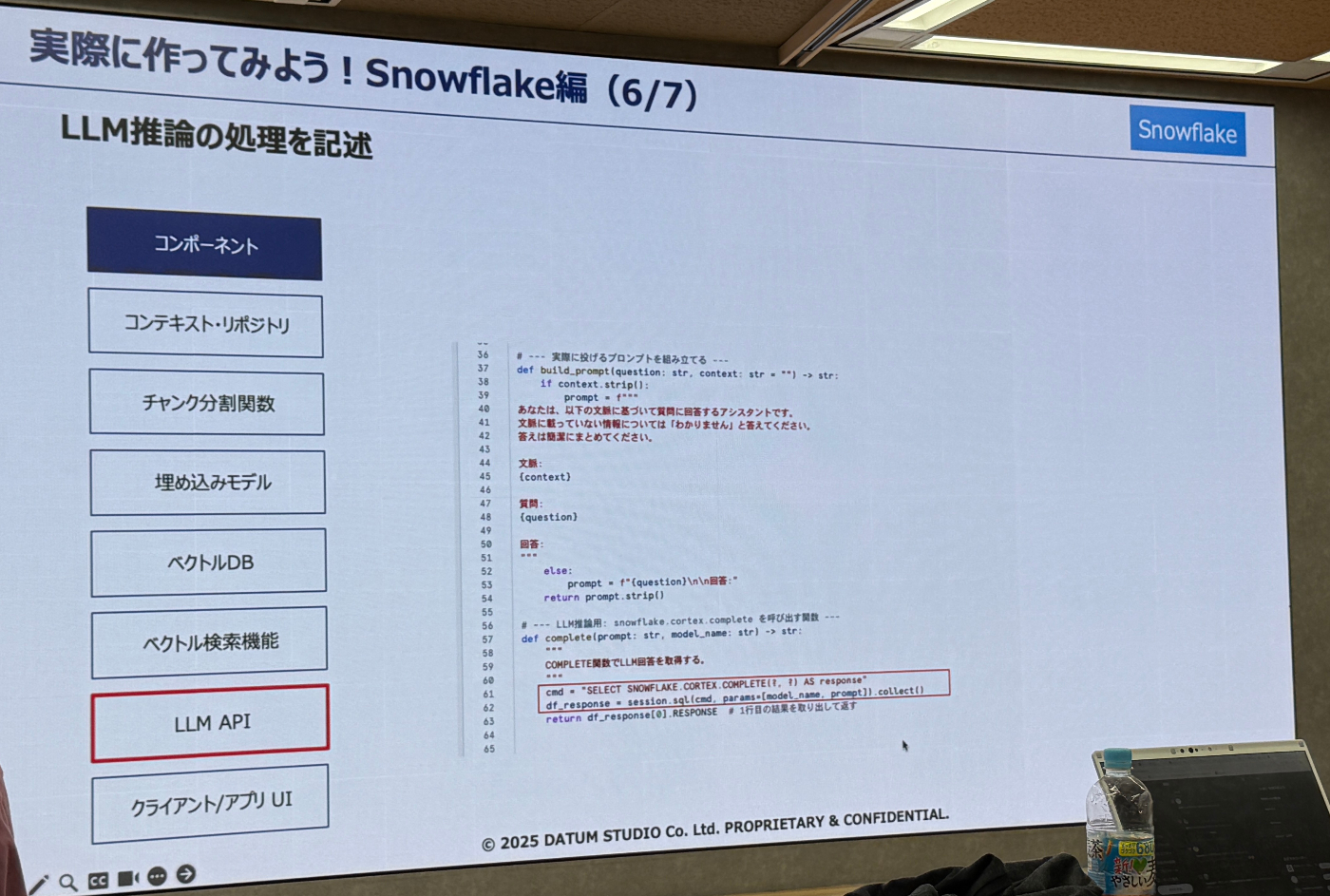
- 上述8つのパートをそれぞれなぞる形でSnowflake、Databricks共に実施した内容を流しながら解説を行っていました。
比較してみる
以下3つの観点でまとめて締め。
- 開発体験
- デフォルトで使用できるLLMモデル
- コスト
ディスカッション
このパートはディスカッションという名前の懇親会でした。冒頭(受付時)に付けていたリストバンドが良い話のきっかけになったのか、セッション本編の熱量同様にこのパートも大いに盛り上がる形となっていました。私個人としても非常に楽しく話をしながら楽しむことができ、久し振りにお会いする方がいたり、お仕事ではお付き合いがあったのですが長年実際にお会いすることがなかった方ともお会い出来たりと有意義な時間を過ごすことが出来ました。
まとめ
という訳で『Cross Data Platforms Meetup』第1回目のイベント参加レポートでした。冒頭説明にあったように、昨今のデータを取り巻く環境は環境の統合、ツールの併用は普通に検討しうる、あり得る状況です。この側面だけを見るとユーザー的には『星取表』的なものが欲しくなりますね。
そこはまぁ分からんでも無いですが、突き詰めていくと他社製品を貶める、DISる的な側面も出てきがちな部分があるのでこのコミュニティで掲げているようなコンセプトのもと「サービスの併用」という側面にスポットを当てたイベントが開催されたのはありがたい限りです。
そして個人的にはDatabricksはまだ触ったことは無かったのですが、今回のこのイベントに参加したことで興味関心が一気に湧いてきました。Snowflake同様、Databricksも色々と触っていきたいと思います。
『Cross Data Platforms Meetup』については2回目以降の開催も是非心待ちにしたいところですね。イベントに関わられた皆様、ありがとうございました!
※当日のイベント関連X投稿もまとめています。あわせてご参照ください。
Discussion