🍋
『JavaScriptで学ぶ関数型プログラミング』を読んだ 03
02からのつづき
8. フローベースプログラミング
- 本章では、関数をブロックとして組み合わせるという考え方を紹介する
- 純粋性と変更の隔離を重視した関数を合成する
チェーン
- チェーン
-
チェーンとは
- condition1関数の例
-
condition1関数の例
/* condition1関数の 検証関数の結果生成する部分 */ // ... var errors = mapcat(function (isValid) { return isValid(arg) ? [] : [isValid.message]; }, validators); // ... - 返されるデータ型が次の関数の引数として使用できるように統一されているデータ型であれば、関数の合成はもっと簡単にできたはず
-
- メソッドチェーンの実装例
- メソッドチェーンを実現する魔法は、チェーン内のそれぞれのメソッドが同じホストオブジェクトの参照を返すこと
- 共通の戻り値を使う
- JavaScriptのデザインパターンとなっている
- Underscoreでは
_.tap, _.chain, _.valueがこのパターン
- 共通の戻り値を使う
-
メソッドチェーンの実装例
function createPerson() { var firstName = ""; var lastName = ""; var age = 0; return { setFirstName: function (fn) { firstName = fn; return this; }, setLastName: function (ln) { lastName = ln; return this; }, setAge: function (a) { age = a; return this; }, toString: function () { return [firstName, lastName, age].join(" "); }, }; } createPerson().setFirstName("Mike").setLastName("Fogus").setAge(108).toString(); //=> "Mike Fogus 108"
- メソッドチェーンを実現する魔法は、チェーン内のそれぞれのメソッドが同じホストオブジェクトの参照を返すこと
-
_.chain関数の例- あるオブジェクトをこの関数の後にチェーンされる(メソッドに擬態した)Underscore関数の暗黙的なターゲットとして指定できる
- _.chain関数はターゲットオブジェクトを引数に取り、ラッパーオブジェクトにターゲットオブジェクトを取り込む
- あるラッパーオブジェクトのメソッド呼び出しから次の呼び出しに渡されるのはラッパーオブジェクト自身である
- .chainへの呼び出しを終了させたい場合は、.value関数を使って結果の値を抽出する
-
chain関数の例
_.chain(library).pluck("title").sort(); //=> _ // _.chainへの呼び出しを終了させたい場合は、 // _.value関数を使って結果の値を抽出する必要がある _.chain(library).pluck("title").sort().value(); //=> ["Joy of Clojure", "SICP", "SICP"] /* _.chain関羽を使う場合、 おかしな値が返されることがある */ var TITLE_KEY = "titel"; // スペルミスとなっている _.chain(library).pluck(TITLE_KEY).sort().value(); //=> [undefined, undefined, undefined] /* Underscoreは、オブジェクトと関数を与えられると、 そのオブジェクトをターゲットして関数を実装する _.tap関数を提供している */ _.tap([1, 2, 3], note); // 情報: 1, 2, 3 //=> [1, 2, 3] /* _.chainのラッパーオブジェクトでも_.tapを 利用できるので、中間結果の値をデバッグ調査できる */ _.chain(library) .tap(function (o) { console.log(o); }) .pluck(TITLE_KEY) .sort() .value(); // [{title: "SICP" ... //=> [undefined, undefined, undefined] _chain(library).pluck(TITLE_KEY).tap(note).sort().value(); // 情報: ,, //=> [undefined, undefined, undefined] /* _.chain関数は遅延実行ができない という制限がある */ _.chain(library).pluck("title").tap(note).sort(); // 情報: SICP,SICP,Joy of Clojure //=> _ // まだ_.value関数を呼び出していないのに、チェーンの関数が // すべて実行されてしまっている
- あるオブジェクトをこの関数の後にチェーンされる(メソッドに擬態した)Underscore関数の暗黙的なターゲットとして指定できる
- condition1関数の例
-
レイジーチェーン(遅延実行を行うチェーン)
- 遅延実行版の
_.chain関数を実装する-
LazyChainの例
/* LazyChainのコンストラクタは _.chain関数と同様にターゲットオブジェクトを 引数にとり、空の配列を設定する */ function LazyChain(obj) { this._calls = []; this._target = obj; } LazyChain.prototype.invoke = function (methodName /*, 任意の数の引数 */) { var args = _.rest(arguments); this._calls.push(function (target) { var meth = target[methodName]; return meth.apply(target, args); }); return this; }; /* _calls配列の要素は、配列[2,1,3]をターゲットとした Array#sortメソッドの遅延呼び出しに対応する関数となる 後の実装のために動作をラッピングする関数のことをサンク(thunk)と呼ぶ サンクは遥か昔のALGOLにルーツを持つ */ new LazyChain([2, 1, 3]).invoke("sort")._calls; //=> [function (target) { ... }] /* LazyChain#force関数は、 レイジーチェーンの実行エンジンとなる _.reduceを使用することでトランポリンと同様の ロジックを実現する */ LazyChain.prototype.force = function () { return _.reduce( this._calls, function (target, thunk) { return thunk(target); }, this._target ); }; new LazyChain([2, 1, 3]).invoke("sort").force(); //=> [1, 2, 3] /* チェーンにさらに関数を加えても 問題なく動作する */ new LazyChain([2, 1, 3]) .invoke("concat", [8, 5, 7, 6]) .invoke("sort") .invoke("join", " ") .force(); //=> "1 2 3 5 6 7 8" /* LazyChainインスタンスで動作する 遅延実行バージョンのtap関数を実装する LazyChain#tapの操作はLazyChain#invokeに似ている 実際の仕事(関数呼び出しを行いターゲットを返す)はサンクに ラッピングされているから */ LazyChain.prototype.tap = function (fun) { this._calls.push(function (target) { fun(target); return target; }); return this; }; new LazyChain([2, 1, 3]).invoke("sort").tap(alert).force(); // アラートがポップアップされる //=> [1, 2, 3] /* LazyChain#forceを呼ばない場合は どうなるか */ var deferredSort = new LazyChain([2, 1, 3]).invoke("sort").tap(alert); deferredSort; //=> LazyChain {_calls: [function (target) { ... }], _target: [2, 1, 3]} // まだ実行されていない /* 明示的にforceメソッドで実行するまで、 deferredSortをいつまでも保持しておくことができる これはPromiseの働きとよく似ている */ deferredSort.force(); // アラートがポップアップされる //=> [1, 2, 3] /* LazyChainを拡張して、レイジーチェーンに 別のレイジーチェーンをつなげることができるようにする LazyChainインスタンスとはただのサンクの配列であることを 認識した上で、他のLazyChainインスタンスが引数として 渡された場合に、そのサンク配列を結合できるように、 LazyChainコンストラクタを変更する */ function LazyChainChainChain(obj) { var isLC = obj instanceof LazyChain; this._calls = isLC ? cat(obj._calls, []) : []; this._target = isLC ? obj._target : obj; } LazyChainChainChain.prototype = LazyChain.prototype; /* コンストラクタに渡された引数がLazyChainのインスタンスであれば、 そのチェーンとターゲットオブジェクトを新しいインスタンスに設定する これで、最終結果を気にすることなく、個別動作を実装したライブラリの 構築ができるようになる */ new LazyChainChainChain(deferredSort).invoke("toString").force(); // アラートがポップアップされる //=> "1,2,3"
-
- 遅延実行版の
-
Promise
- LazyChainは遅延実行に有用ではあるが、Promiseも有用となる
- メインプログラムと並行して動作する非同期オペレーションのためのAPIを提供してくれる
- promiseは未消化のタスクを表している
- LazyChainとPromiseの違い
- レイジーチェーンも複数のサブタスクによって構成されるタスクの集合を表すが、一度実行(force)されると常にチェーンの順番に実行される
- promiseはゆるく関連したタスクの集まりを扱うだけ
- jQueryのPromiseの例
-
jQueryのPromiseの例
var longing = $.Deferred(); longing.promise(); //=> Object longing.promise().state(); //=> "pending" longing.resolve("<3"); longing.promise().state(); //=> "resolved" longing.promise().done(note); // NOTE: <3 //=> (promiseを返す) /* jQueryのPromiseと レイジーチェーンの違い 開始時間のことなく3つの非同期処理を実行する */ function go() { var d = $.Deferred(); $.when("") .then(function () { setTimeout(function () { console.log("sub-task 1"); }, 5000); }) .then(function () { setTimeout(function () { console.log("sub-task 2"); }, 10000); }) .then(function () { setTimeout(function () { d.resolve("done done done done"); }, 15000); }); return d.promise(); } var yearning = go().done(note); yearning.state(); //=> "pending" // (コンソール) sub-task 1 yearning.state(); //=> "pending" // (コンソール) sub-task 2 // (5秒後) // 情報: done done done done yearning.state(); //=> "resolved"
-
- LazyChainは遅延実行に有用ではあるが、Promiseも有用となる
-
チェーンとは
パイプライン
- パイプライン
- チェーンはオブジェクトやメソッドの呼び出しまわりのAPIを構築するために有用なパターンである
- ただ、関数型APIのためにはそこまで有用というわけではない
- メソッドチェーンの欠点
- オブジェクトのsetとgetのロジックが堅く連結されてしまうこと
- コマンドとクエリの分離ができない
- ひとつの呼び出しから次の呼び出しに移る際に、共通の参照を変更してしまうことが、一番の問題である
- 関数型APIでは参照ではなく値そのものを操作し、データを変換して新しい結果値を返すから
- 理想的には、関数に渡されたオリジナルのデータは実行後もオリジナルのまま残るべき
- これはパイプラインを合成可能な状態に保つために必要となる
- 関数型のコードにおけるチェーンは、期待されるデータちが入力されると、非破壊的変換を行い、また、新しいデータを返す動作が最初から最後まで連続している
- オブジェクトのsetとgetのロジックが堅く連結されてしまうこと
- 関数のパイプラインと効果的な使用法
- 本書で定義されている関数はパイプラインで動作するように設計されている
- パイプラインは遅延実行を行わず、参照ではなく値そのものを扱う
- パイプラインは合成された関数に近い
- 遅延実行させるにはパイプラインを関数にカプセル化するだけでよい
- パイプラインを使うことによって、あいまいになりがちなデータフローをより明確にすることができる
- 関数型プログラミングは、ある関数から次の関数へ流れるにしたがってデータを変換することに焦点を当てているものの、関数参照や深い入れ子によってその焦点があいまいになることがあるから
- ただ、パイプラインはすべての場合において適切となる選択肢ではない
- I/OやAjaxコール、変異などの副作用を伴う場面では、戻り値がないケースが多いため
- 副作用のある不純関数をパイプラインのような構造の一部として合成する方法を次節で説明する
-
pipeline関数
/* 本来のpipeline関数の実装は 自然とLazyChain#forceと似たものになる */ function pipeline(seed /*, 任意の数の関数 */) { return _.reduce( _.rest(arguments), function (l, r) { return r(l); }, seed ); } pipeline(); //=> undefined pipeline(42); //=> 42 pipeline(42, function (n) { return -n; }); //=> -42 /* パイプラインを 遅延実行させる */ function fifth(a) { return pipeline(a, _.rest, _.rest, _.rest, _.rest, _.first); } fifth([1, 2, 3, 4, 5]); //=> 5 /* パイプラインを使って構築した抽象を 他のパイプラインに挿入するという 強力なテクニックもある */ function negativeFifth(a) { return pipeline(a, fifth, function (n) { return -n; }); } negativeFifth([1, 2, 3, 4, 5, 6, 7, 8, 9]); //=> -5 /* このパイプラインの仕組みを使って 流暢なAPIを構築することができる */ function firstEditions(table) { return pipeline( table, function (t) { return as(T, { ed: "edition" }); }, function (t) { return project(T, ["title", "edition", "isbn"]); }, function (t) { return restrict(T, function (book) { return book.edition === 1; }); } ); } firstEditions(library); //=> [{title: "SICP", edition: 1, isbn: "0262010771"}, // {title: "Joy of Clojure", edition: 1, isbn: "1935182641"}] /* pipeline関数の問題は、 パイプラインないの関数が引数をひとつしか取らない ということ しかし、関係演算子は1つ目の引数がテーブルデータ、2つ目のが 変更内容という一貫性のあるインターフェイスを持っている これを利用して、curry2関数を使ってカリー化した関係演算子を 作成できる オブジェクトRQL(Relational Query Language)を名前空間として カリー化した関数を格納する */ var RQL = { select: curry2(project), as: curry2(as), where: curry2(restrict), }; function allFirstEditions(table) { return pipeline( table, RQL.as({ ed: "edition" }), RQL.select(["title", "edition", "isbn"]), RQL.where(function (book) { return book.edition === 1; }) ); } allFirstEditions(library); //=> [{title: "SICP", edition: 1, isbn: "0262010771"}, // {title: "Joy of Clojure", edition: 1, isbn: "1935182641"}]
- チェーンはオブジェクトやメソッドの呼び出しまわりのAPIを構築するために有用なパターンである
データフロー対コントロールフロー(制御構造)
- データフロー対コントロールフロー
-
合成することを念頭に置かずに定義された関数を合成する場合は、どうすればいいか
- LazyChainやpipelineは安定して連続処理が可能となっていたが、合成できる関数を使用することが前提となっていた
- もし型が一致しなければ期待通りの動作を行うことができない
- 解決方法としては、処理間の流れるデータの形状を一定にする方法を見つけること
-
型が一致しない場合の例
/* 型が一致しない場合、 期待通りの動作をしない noteの実行時にデータ型がundefinedに変わってしまう例 */ pipeline(42, sqr, note, function (n) { return -n; }); // 情報: 1764 //=> NaN /* 実際にこれを正しく動作させようとすると、 手動で行う必要がある note関数を、与えられたものをそのまま返すように 変更することもできるが、対症療法にすぎない */ function negativeSqr(n) { var s = sqr(n); note(n); return -s; } negativeSqr(42); // 情報: 42 //=> -1764
- 遅延実行を行う新しい種類のパイプラインを使って合成するテクニックを紹介していく
- これらのテクニックはactionsと呼ばれる
- LazyChainやpipelineは安定して連続処理が可能となっていたが、合成できる関数を使用することが前提となっていた
-
共通の形をみつける
- オブジェクト型の中に何を入れるかを考えることで共通の形を決める
- actions関数
- 異なる形をもつ関数を合成するための一般的な手段となる
-
actions関数の例
/* negativeSqr関数の例で 必要となるオブジェクトの中身 */ { values: [42, 1764, undefined, -1764]; } /* 上記の他に持っていて便利なデータは、 状態か、もしくは処理間で共通のターゲットオブジェクトである */ { values: [42, 1764, undefined, -1764], state: -1764, } /* これらの中間状態を管理するactions関数の実装は pipelineとlazyChainのハイブリッドとなる actions関数は、関数の配列actを引数に取り、 ある値seedを初期状態として中間状態オブジェクトを 使用する関数を返す この返された関数を実行すると、配列に格納されている すべての関数を順番に実行し、中間状態オブジェクトを構築する answer値は関数呼び出しの結果に対応し、state値はそれぞれの アクションが実行された後の新しい状態を保持する noteのような関数はstateを変更しないが、 answerはundefinedになるため、actionsはこれらをフィルタして 除去する 最後に、actionsはフィルタされた値(keep)とstateをdone関数に 渡して、最終結果を得る */ function actions(acts, done) { return function (seed) { var init = { values: [], state: seed }; var intermediate = _.reduce( acts, function (stateObj, action) { var result = action(stateObj.state); var values = cat(stateObj.values, [result.answer]); return { values: values, state: result.state }; }, init ); var keep = _.filter(intermediate.values, existy); return done(keep, intermediate.state); }; } /* アクションの適切な呼び方は モナドとなる(JavaScriptにおけるモナドっぽい書き方) */ function mSqr() { return function (state) { var ans = sqr(state); return { answer: ans, state: ans }; }; } var doubleSquareAction = actions([mSqr(), mSqr()], function (values) { return values; }); doubleSquareAction(10); //=> [100, 10000] // 実行結果にはすべての中間結果が含まれている // これだけではpipelineとほぼ同じ機能となる /* 異なる形を持った関数を混ぜるときに actions関数の真価が発揮される */ function mNote() { return function (state) { note(state); return { answer: undefined, state: state }; }; } function mNeg() { return function (state) { return { answe: -state, state: -state }; }; } var negativeSqrAction = actions( [mSqr(), mNote(), mNeg(0)], function (_, state) { return state; } ); negativeSqrAction(9); // 情報: 9 //=> -81
-
アクションの生成をシンプルにする関数
- この節では、
liftという小さい関数を定義する-
liftは2つの関数を引数に取り、1つ目は値を与えられて何かのアクションの結果を提供する関数、そして2つ目は新しいstateを提供する関数となる -
lift関数は、actinsの中間状態をあらわす状態オブジェクトの管理と抽象そのものを分離するために使われる -
liftやactions関数で管理することで、異なる形の関数を合成する
function lift(answerFun, stateFun) { return function (/* 任意の数の引数 */) { var args = _.toArray(arguments); return function (state) { var ans = answerFun.apply(null, construct(state, args)); var s = stateFun ? stateFun(state) : ans; return { answer: ans, state: s }; }; }; } /* liftはカリー化されており、 柔軟なインターフェースを提供する sqr関数とneg関数は、answerとstateが同じ値となるが、 note関数のanswerはundefinedを返すため、_.identityを 使ってパススルーのアクションを設定する */ var mSqr2 = lift(sqr); var mNote2 = lift(note, _.identity); var mNeg2 = lift(function (n) { return -n; }); var negativeSqrAction2 = actions( [mSqr2(), mNote2(), mNeg2()], function (notUsed, state) { return state; } ); negativeSqrAction2(100); // 情報: 100 //=> -10000 /* liftとactionsを使って スタック動作を行うstackAction関数を 実装する */ var push = lift(function (stack, e) { return construct(e, stack); }); var pop = lift(_.first, _.rest); var stackAction = actions([push(1), push(2), pop()], function (values, state) { return values; }); /* actions関数を使うと、連続したスタックイベントを まだ実現していない値としてキャプチャしておくことができる */ stackAction([]); //=> [[1], [2, 1], 2] /* stackAction関数はただの関数なので、 他の関数と合成できる これはほとんど魔法のようなもの */ pipeline([], stackAction, _.chain).each(function (elem) { console.log(polyToString(elem)); }); // (コンソール) [1] // stackActionのpush(1)後のスタック // (コンソール) [2, 1] // stackActionのpush(2)後のスタック // (コンソール) 2 // stackActionのpop()後のスタック
-
- 共通の中間形を定義して、liftやactionsのような関数で管理することで、異なる形の関数を合成することができるようになった
- コントロールフロー内で型を一定に保つという問題を、データフローの問題に転換することができた
- この節では、
-
合成することを念頭に置かずに定義された関数を合成する場合は、どうすればいいか
まとめ
- 本章では、ひとつの動作を連続したステップとして見ることでの可能性の広がりを探った
- チェーン
- メソッドチェーンは、
this参照のみを返すオブジェクトメソッドを描くことで、ルールを共有するメソッドを連続して呼ぶことができる仕組みである -
promiseや_.chain関数でチェーンの概念を説明した - ある共通のターゲットに対して連続したメソッド呼び出しを遅延実行するレイジーチェーンを説明した
- メソッドチェーンは、
- パイプライン
- パイプラインは、一方からデータを入力すると、変換されたデータを反対側から出力するような関数呼び出しの連続である
- チェーンとは異なり、共通の参照ではなく、配列やオブジェクトといったデータを扱う
- パイプラインは純粋性を持ち、元データが破壊されることはない
- アクション
- チェーンとパイプラインは既知の参照もしくはデータ型を扱うが、アクションの連続はデータ型に制限されることはない
- actions関数を型として実装して、内部のデータ構造の管理詳細を隠蔽し、異なる型の引数をとり、異なる型の値を返す関数をミックスできる
- (モナド的なデザインパターンによって、状態を持つ処理を安全に合成できるようにする)
- チェーン
- 次章では、関数型プログラミングがクラスを使わないプログラミングスタイルをどのように容易にし、なぜそれを使うといいのかを説明する
9. クラスを使わないプログラミング
- JavaScriptにおける関数型プログラミングとオブジェクト指向
- JavaScript言語に実装されている最小限のツール(関数、オブジェクト、プロトタイプ、配列)に初めて接すると、多くの人ががっかりする
- そして人々は開発に必要なクラスベースのシステムを探し出してきたり、原始の海から自分の手でその再発明を行うようになる
- 関数型プログラマーは、関数型とオブジェクト指向の考え方をうまく併用する方法を考える
- 関数型プログラマーは、データと関数に基づいた考え方をベースにして、個別の動作をミックスすることで、より複雑な動作を組み立てる
- そして、そのようなカスタム化の詳細をユーザーから隠蔽するような関数型のAPIをを記述する手段について説明する
- JavaScript言語に実装されている最小限のツール(関数、オブジェクト、プロトタイプ、配列)に初めて接すると、多くの人ががっかりする
データ指向
- データ指向
-
本書のこれまでのやり方
- 型の階層を生成することを意図的に避けて高位のデータモデルを組み立ててきた
- 主にJavaScriptのプリミティブや配列、オブジェクトを使ってきた
- メソッドよりも関数に集中してAPIを提供してきた
- 関数型APIを使うと、チェーン内の処理の間にどのような型のデータが流れているか気にする必要がない
- 関数型インターフェースだと、計算の最初と最後だけに気を配る必要があり、中間データのデータ型はあまり問題にならない
- そして、中間データは必要に応じて進化(もしくは退化)させることができる
- 上手く設計されたAPIは、中間データ型を抽象化し、合成を可能にする
- しかし、どうしてもオブジェクト中心の考え方がどうしても必要な場合がある
- その例としてのLazyChain関数
- ターゲットオブジェクトに対するメソッドの遅延実行を実装した
- LazyChain型のインスタンスの生成を直接操作する必要があった
- JavaScriptを活用してLazyChain型を生成しない方法
-
LazyChain型を生成しない方法
/* LazyChain型を生成しない方法 ・関数呼び出しによってレイジーチェーンが初期化される ・コールチェーン(calls配列)がプライベートデータである ・LasyChain型が明示的に存在しない */ function lazyChain(obj) { var calls = []; return { invoke: function (methodName /*, 任意の引数 */) { var args = _.rest(arguments); calls.push(function (target) { var meth = target[methodName]; return meth.apply(target, args); }); return this; }, force: function () { return _.reduce( calls, function (ret, thunk) { return thunk(ret); }, obj ); }, }; } var lazyOp = lazyChain([2, 1, 3]) .invoke("concat", [7, 7, 8, 9, 0]) .invoke("sort"); lazyOp.force(); //=> [0, 1, 2, 3, 7, 7, 8, 9]
-
- その例としてのLazyChain関数
- JavaScriptを活用して、名前付きデータ型や型階層を作らないで実現する方法の代表例
- プリミティブデータ型
- 複合型(オブジェクトと配列)
- ビルトインデータ型を使用する関数
- メソッドを格納できる無名オブジェクト
- 型付きオブジェクト
- クラス
- 下図の上下を反転させて、クラスの構築から初めてしまうと、抽象化のために残されている余裕を最初から使い切ってしまうことになる
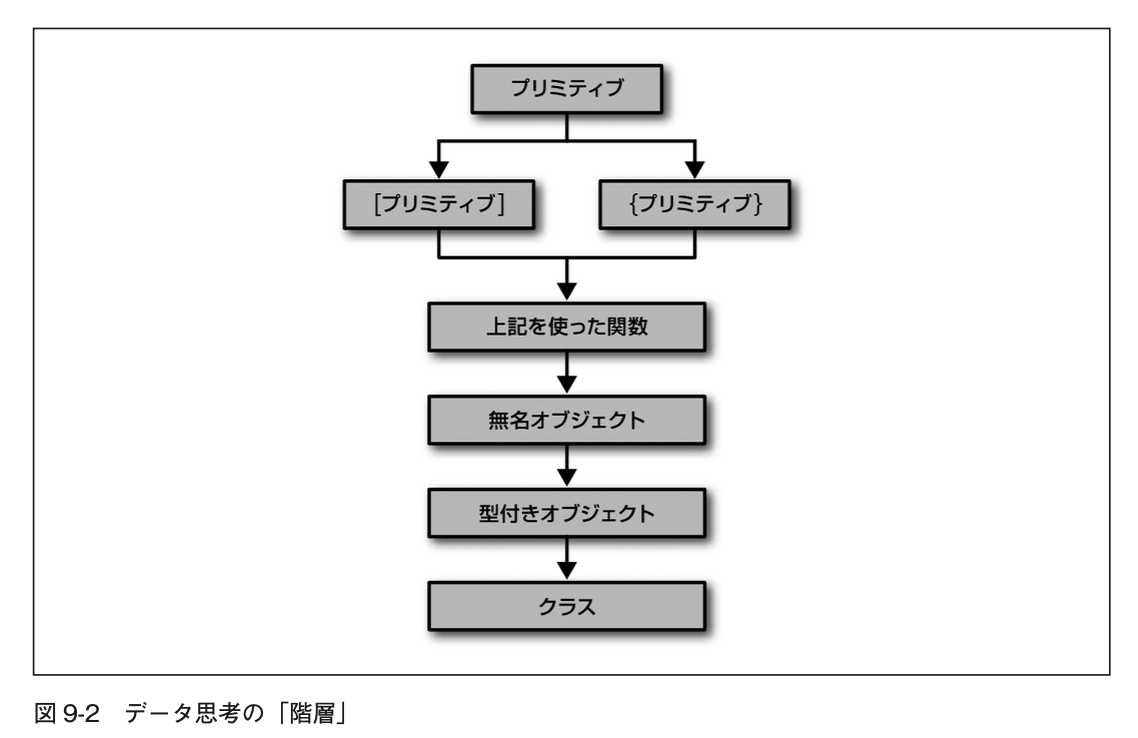
- ビルトインのデータ型から考え始めて、関数型のAPIと組み合わせることから始めることを選択すると、拡張のための柔軟性が手に入る
- 型の階層を生成することを意図的に避けて高位のデータモデルを組み立ててきた
-
関数型を目指して構築
- プログラミングにおける作業では、何らかの計算のさなかに発生するアクティビティが最も大切(Elliott 2010)
- フォームに入力された文字列を読み込んで、検証して、別のデータ型に変換し、計算処理をして、計算した新しい値を文字列に変換して送る、という一連の動作を考えてみる
- 文字列を読み込む動作と、文字列に変換する動作は、検証とデータ処理の部分に比べると比較的小さいものとなる
- これらのタスクを満たすためにこれまでは関数型とオブジェクト指向のミックスでツールを構築してきた
- 関数型を目指してリファクタリングするとソリューションをさらに進化させることができる
- オブジェクト中心の考え方だったレイジーチェーンをリファクタリングする
-
フォーム入力から新しい値を返す例
/* レイジーチェーンの生成を関数に格納しておくことにより、 オブジェクトのデータ型に依らないように遅延実行する オペレーションを汎用化することができる */ function deferredSort(ary) { return lazyChain(ary).invoke("sort"); } var deferredSorts = _.map( [ [2, 1, 3], [7, 7, 1], [0, 9, 5], ], deferredSort ); //=> [<thunk>, <thunk>, <thunk>] /* サンクを実行するために、メソッド呼び出しをカプセル化して 関数で使えるようにする */ function force(thunk) { return thunk.force(); } /* メソッド呼び出しを関数型アプリケーションの世界まで 引き上げることができる */ _.map(deferredSorts, force); //=> [[1, 2, 3], [1, 7, 7], [0, 5, 9]] /* 次にデータ処理の骨子となる個別の機能を 定義していく */ var validateTriples = validator( "それぞれの配列は3つの要素を持っている必要があります", function (arrays) { return _.every(arrays, function (a) { return a.length === 3; }); } ); var validateTripleStore = partial1(condition1(validateTriples), _.identity); /* 検証の動作をすべて1つの関数に集めておくことで、 チェーン内の他のステップを気にすることなく 検証内容を変更したり、他の場所で再利用できるようになる */ validateTripleStore([ [2, 1, 3], [7, 7, 1], [0, 9, 5], ]); //=> [[2,1,3], [7,7,1], [0,9,5]] validateTripleStore([ [2, 1, 3], [7, 7, 1], [0, 9, 5, 7, 7, 7, 7, 7, 7], ]); // Error: それぞれの配列は3つの要素を持っている必要があります /* そして、他の遅延実行処理の 定義を行う(ただし、必ずしも遅延実行する必要はない) */ function postProcess(arrays) { return _.map(arrays, second); } /* ここまでに定義されたパーツを集めて より高位のアクティビティを定義する */ function processTriples(data) { return pipeline( data, JSON.parse, validateTripleStore, deferredSort, force, postProcess, invoker("sort", Array.prototype.sort), str ); } processTriples("[[2,1,3], [7,7,1], [0,9,5,7,7,7,7,7,7]]"); // Error: それぞれの配列は3つの要素を持っている必要があります /* これで、このようなデータ変換を行う処理が必要な場所であれば、 どこでもこの関数で実行できるようになった */ $.get("http://example.com", function (data) { $("#result").text(processTriples(data)); }); /* レポーティングのためのロジックを抽象化する際に、 この関数をロジックの一部として利用できる */ var reportDataPackets = _.compose(function (s) { $("#result").test(s); }, processTriples); reportDataPackets("[[2,1,3], [7,7,1], [0,9,5]]"); // (Webページの要素が変更される) $.get("http://example.com", reportDataPackets);
-
- 関数を生成するということは、「解決すべき問題をパイプラインの一方から入れ、徐々にデータを変換して他方から出すこと」として考えることができる
- それぞれの変換パイプラインを個別の動作としてみなすことができる
- 互換性のあるパイプラインはフィードフォワードの作法で最初から最後までつなげることができる
- アダプタを伴ったパイプラインは入力と出力に接続できる
- パーツや中間データ型を必要に応じて変更可能とする柔軟性を残しつつ、システムを既知の小さなパーツによって構成できるようになる
- パイプラインのように変換器にデータが流れていくという考え方は、単一の関数から大きなシステム全体までをカバーできるスケーラブルな考え方となる
- オブジェクト指向の考え方が適切な場合もある
- 汎用的なmixinを伴うデータ型が、正しく抽象化されている場合
- 次章では関数抽象を作るためのmixinの考え方を紹介する
- プログラミングにおける作業では、何らかの計算のさなかに発生するアクティビティが最も大切(Elliott 2010)
-
本書のこれまでのやり方
Mixin
- Mixin
- オブジェクトやメソッドがその場における最適なソリューションである場合もある
- mixinベースの拡張というアプローチがある
-
mixinについて
- クラスベースシステムの成り立ちと似ているが、一部機能が制限されている
- 既存の動作に新しい動作を足す場合、クラスベースでは継承を利用するが、mixinは継承を使用せず関数合成によって解決する
- まず、そもそもオブジェクトで考える必要性を理解する
- オブジェクトを引数に取り、その内容を文字列に変換して返す関数polyToStringを構築してみる
-
polyToString関数の例
function polyToString(obj) { if (obj instanceof String) { return obj; } else if (obj instanceof Array) { return stringifyArray(obj); } return obj.toString(); } function stringifyArray(ary) { return ["[", _.map(ary, polyToString).join(","), "]"].join(""); } polyToString([1, 2, 3]); //=> "[1,2,3]" polyToString([1, 2, [3, 4]]); //=> "[1,2,[3,4]]" /* 別のデータ型に対応する文字列を生成しようとすると、 の度にpolyToStringにif文を追加でネストする必要がある dispatchがよりよいアプローチを提供する dispachを使うことによって、それぞれのチェックを別の関数に 抽象化し、さらなる合成による拡張につなげることができる */ var polyToString = dispatch( function (s) { return _.isString(s) ? s : undefined; }, function (s) { return _isArray(s) ? stringifyArray(s) : undefined; }, function (s) { return s.toString(); } ); polyToString(42); //=> "42" polyToString([1, 2, [3, 4]]); //=> "[1,2,[3,4]]" polyToString("a"); //=> "a" /* まともなtoStringメソッドを実装していないデータ型には まだ問題がある */ polyToString({ a: 1, b: 2 }); //=> "undefined" /* 拡張したい場合は、単純にdispatchに 別の関数を合成するだけでよい */ var polyToString = dispatch( function (s) { return _.isString(s) ? s : undefined; }, function (s) { return _.isArray(s) ? stringifyArray(s) : undefined; }, function (s) { return _.isObject(s) ? JSON.stringify(s) : undefined; }, function (s) { return s.toString(); } ); polyToString([1, 2, { a: 42, b: [4, 5, 6] }, 77]); //=> '[1,2,{"a":42,"b":[4,5,6]},77]' /* しかし、Container型の文字列化をサポートしてみると 不自然さがわかる */ polyToString(new Container(_.range(5))); //=> {"_value":[0,1,2,3,4]} /* 確かに、下記のようにもう一つの別の関数をdispatchの呼び出しチェーンに 追加することで結果を見やすく出力することはできる dispatchはシンプルな動作を提供するが、 データ型の判断が単一階層を超えてしまう場合には、 必要以上に複雑になってしまう このような場合には、オブジェクト自体にカスタムtoStringメソッドを 記述しておく方がよりよい選択肢になる しかしこのような場合に、ポリシーに反した 以下のようなことがよく行われてしまう ・コア言語のプロトタイプが変更される ・クラス構造が作られる */ // ... // function(s) { return ["@", polyToString(s._value)].join('')} // ...
- クラスベースシステムの成り立ちと似ているが、一部機能が制限されている
-
コアプロトタイプマンジング(Core Prototype Munging)
- マンジング(mung/munge): 一見なんということのない復元可能な変更をさまざまな場所に加えることにより、システム全体をいつのまにか取り返しの付かない状態まで破壊してしまうような行為のこと
- JavaScriptにおいて新しいデータ型を生成をする際には、特殊な動作が必要な場合がある
- しかし、ArrayやObjectなどのコアデータ型においてはprotypeは汚染せず、カスタム動作はカスタムデータ型に委譲した関数に隔離しておくほうがよい
- Container型の例
-
Container型にカスタム動作を追加する例
new Container(42).toString(); //=> "[object Object]" // これは期待通りの動作ではない /* Containerに特化したtoStringメソッドを そのprototypeに定義する */ Container.prototype.toString = function () { return ["@", polyToString(this._value), ">"].join(""); }; /* すべてのContainerインスタンスが同じように動作する toStringを持つようになる */ new Container(42).toString(); //=> "@42>" new Container({ a: 42, b: [1, 2, 3] }).toString(); //=> "@{"a":42,"b":[1,2,3]}>" /* もしコアオブジェクトに機能を追加したい場合は、 唯一の選択肢は、コアプロトタイプそのものに手を出すこと 問題は、こうして作成したライブラリを誰か他の人が使う場合に、 生成されたすべての配列がこの新しいArray#toStringメソッドによって 汚染されることになる したがって、ArrayやObjectなどのコアデータ型においては、 カスタム動作はカスタムデータ型に委譲した関数に隔離しておくほうがよい まさにこれがContainer#toStringメソッドが行なっていることである mixinもこのようなアプローチをとる */ Array.prototype.toString = function () { return "DON'T DO THIS"; }[(1, 2, 3)].toString(); //=> "DON'T DO THIS"
-
クラス階層構造
- クラスベースのオブジェクト指向の方法論を使ってシステムを設計していると、慣例的にはシステムを構成するモノとそれらの関連性をまず列挙する
- オブジェクト指向のレンズを通して問題をみると、あるクラスの他のクラスへの関連の仕方は階層的なものになる
- 従業員 -> 人 -> 会計士・管理人・CEO
- これらはデータ型の階層を形作る
- クラスベースの階層で大きな抽象を実現する

-
Compare And Swapの仕組みを追加する例
function ContainerClass() {} function ObservedContainerClass() {} function HoleClass() {} function CASClass() {} function TableBaseClass() {} ObservedContainerClass.prototype = new ContainerClass(); HoleClass.prototype = new ObservedContainerClass(); CASClass.prototype = new HoleClass(); TableBaseClass.prototype = new HoleClass(); new CASClass() instanceof HoleClass; //=> true new TableBaseClass() instanceof HoleClass; //=> true new HoleClass() instanceof CASClass; //=> false // 継承は階層を遡れるが、階層を下方向へ伝うことはできない var ContainerClass = Class.extend({ init: function (val) { this._value = val; }, }); var c = new ContainerClass(42); c; //=> {_value: 42} c instanceof Class; //=> true var ObservedContainerClass = ContainerClass.extend({ observe: function (f) { note("observerを設定"); }, notify: function () { note("observersに通知"); }, }); var HoleClass = ObservedContainerClass.extend({ init: function (val) { this.setValue(val); }, setValue: function (val) { this._value = val; this.notify(); return val; }, }); var h = new HoleClass(42); // 情報: observersに通知 h.observe(null); // 情報: observerを設定 h.setValue(108); // 情報: observersに通知 //=> 108 /* CASClassインスタンスがCompare And Swap(CAS)の 仕組みを追加する クラスベースの階層で小さい動作の継承を使って組み立てることで 大きな抽象を実現できる */ var CASClass = HoleClass.extend({ swap: function (oldVal, newVal) { if (!_.isEqual(oldVal, this._value)) { fail("現在値が一致しません"); } return this.setValue(newVal); }, }); var c = new CASClass(42); // 情報: observerを設定 c.swap(42, 43); // 情報: observersに通知 //=> 43 c.swap("not the value", 44); // Error: 現在値が一致しません
- クラスベースのオブジェクト指向の方法論を使ってシステムを設計していると、慣例的にはシステムを構成するモノとそれらの関連性をまず列挙する
-
階層を変更
- 上記の方法には潜在的な問題がある
- 入力値を検証する関数を階層の真ん中に付け加えたいというような、階層を拡張する場合に困ってしまう

- ValidatedContainerのあるべき位置はObservedContainerと同じレベルである
- すべてのHoleインスタンスに検証を許したと思っても、すべての場合に確実に検証が必要とは言えない
- よりよい選択は、必要な部分だけを拡張すること
- CASクラスに検証が必要であれば、ValidatedContainerを階層上に置いて、それを拡張する
- しかし、もし新しい型が定義されて、コンペア・アンド・スワップの仕組みが必要で、一方検証は必要ない場合はこの階層構造では問題がある
- CASクラスを継承する別クラスを作るべきでもない
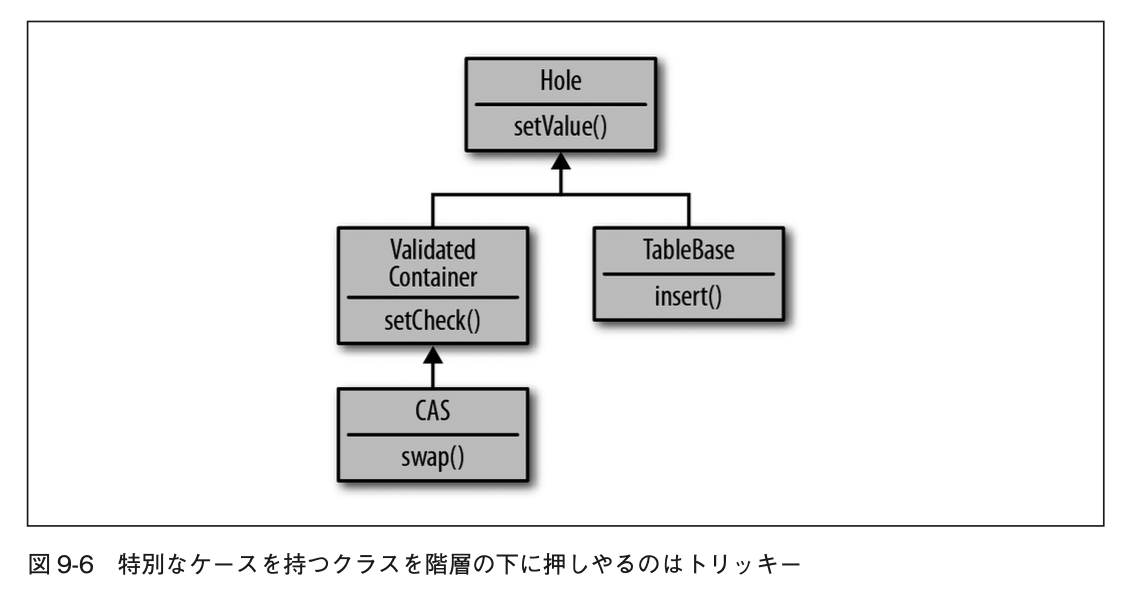
- 入力値を検証する関数を階層の真ん中に付け加えたいというような、階層を拡張する場合に困ってしまう
- クラス階層構造における大きな問題
- 階層構造というものが、あらかじめ必要とされている動作をすべて知っているという前提の上で作られていること
- オブジェクト指向のテクニックは、動作の階層から始めて、決定されたものに対してクラスを当てはめるということが暗に含まれている
- ValidatedContainer関数のように、その存在を分類することが困難な動作については対応が困難になってしまう
- 上記の方法には潜在的な問題がある
-
Mixinを使って階層を平坦化
- ここで問題をシンプルにしてみる
- Container、ObservedContainer、ValidatedContainer、Holeというそれぞれのクラスの基本の機能性をすべて同じレベルに置いてみる
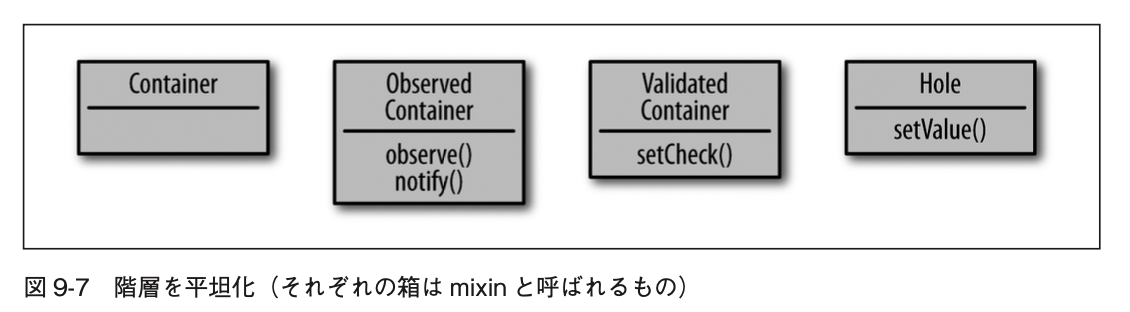
- 階層を平坦化すると、それぞれのクラス間の暗黙的な関連性はなくなり、図中の箱はデータ型とは言えなくなる
- それぞれの箱は個別の動作の集合、もしくはmixinと呼ばれる状態になる
- 新しい動作を作る場合、新たに動作を定義するか、既存の動作に混ぜ込む(mixin)ことになる
- これは、既存の関数を合成して新しい関数を生成するという考え方と同じになる
- Containerの実装をやり直してみる
- mixinプロトコル
- 拡張プロトコル(mixin拡張の際の必須メソッド・プロパティ)
init
- インターフェイスプロトコル
- コンストラクタ
- 拡張プロトコル(mixin拡張の際の必須メソッド・プロパティ)
- Containerの場合、init呼び出しはUnderscoreの_.identityに委譲することになる
-
mixinを使ったContainerの実装
function Container(val) { this._value = val; this.init(val); // このinit呼び出しがmixinの特徴となる(拡張可能なポイントを提供する) } Container.prototype.init = _.identity; var c = new Container(42); c; //=> {_value: 42}
- mixinプロトコル
- mixinの実例
- コンストラクタ呼び出しと、個別の機能の集合体をまとめて混ぜ合わせる方法で新しいデータ型を生成できる
-
mixinの実例
/* Holeという型を生成する Hole型の機能 ・ある値を保持する ・検証関数に、値の検証を委譲する ・通知関数に、値の変更時における関連先への通知を委譲する HoleMixin$#setValueメソッドは、Hole型であることに必要な セットを定義する */ var HoleMixin = { setValue: function (newValue) { var oldVal = this._value; this.validate(newValue); thijs._value = newValue; this.notify(oldVal, newValue); return this._value; }, }; /* Holeコンストラクタを実装する Holeインスタンスのthisポインタに対して Container.callを呼び出すことで、Containerコンストラクタが インスタンス生成時に行うことはすべてHoleインスタンスの コンテクストでも起こることを保証している HoleMixinのmixinプロトコル ・拡張プロトコル: notify, validate ・インターフェイスプロトコル: コンストラクタ, setValue */ var Hole = function (val) { Container.call(this, val); }; /* mixinの要求を満たしていない場合は、 エラーとなってしまう */ var h = new Hole(42); // TypeError: Object #<Object> has no method 'init' /* ObserverMixinを作成する ObserverMixinのクロージャは、_watchersオブジェクトを カプセル化してデータを隠蔽する一般的なmixinの特徴を持つ */ var ObserverMixin = function () { var _watchers = []; return { watch: function (fun) { _watchers.push(fun); return _.size(_watchers); }, notify: function (oldVal, newVal) { _.each(_watchers, function (watcher) { watcher.call(this, oldVal, newVal); }); return _.size(_watchers); }, }; }; /* ValidateMixinを作成する ValidateMixinの作成によって、Holeに求められていたinit拡張要件を 満たすことができる(初期化ステップとしてコンテナの開始の値を検証する) */ var ValidateMixin = { addValidator: function (fun) { this._validator = fun; }, init: function (val) { this.validate(val); }, validate: function (val) { if (existy(this._validator) && !this._validator(val)) { fail("不正な値を設定しようとしました: " + polyToString(val)); } }, }; /* mixinがすべて揃ったので、混ぜ込んでHole型の 要件を満たす _.extendを使うことで、すべてのメソッドをHoleき プロトタイプにコピーすることができる */ _.extend(Hole.prototype, HoleMixin, ValidateMixin, ObserverMixin); var h = new Hole(42); h.addValidator(always(false)); h.setValue(9); // Error: 不正な値を設定しようとしました: 9 var h = new Hole(42); h.addValidator(isEven); h.setValue(9); // Error: 不正な値を設定しようとしました: 9 h.setValue(108); //=> 108 h; //=> {_validator: function isEven(n) {...}, _value: 108} h.watch(function (old, nu) { note([old, "を", nu, "に変更"].join(" ")); }); //=> 1 h.setValue(42); // 情報: 108を42に変更 //=> 42 h.watch(function (old, nu) { note([["Veranderende", old, "tot", nu].join(" ")]); // オランダ語 }); //=> 2 h.setValue(36); // 情報: 42を36に変更 // 情報: Veranderende 42 tot 36 //=> 36
- ここで問題をシンプルにしてみる
-
mixin拡張を使用した新しい仕組み
- 既存のJavaScriptのデータ型に新たな機能を追加する場合に、prototypeをいじる方法を取る問題
- 簡単に動作は変えられる
- だが内部のデリケートなバランスを崩してしまうことになるのかどうかが判断できない
- Hole型に新しい仕組みを与えることで、機能を拡張するアプローチを探ってみる
-
/* setValueメソッドを低レイヤーの値操作として 使用してみる swapメソッドは、関数といくつかの引数を取る 与えられた引数と既存の値_valueを使って新しい値を 計算する 拡張プロトコル: setValue_value(プロパティ) インターフェイスプロトコル: swap */ var SwapMixin = { swap: function (fun /* ,任意の数の引数 */) { var args = _.rest(arguments); var newValue = fun.apply(this, construct(this._value, args)); return this.setValue(newValue); }, }; /* SwapMixinを単体で テストしてみる */ var o = { _value: 0, setValue: _.identity }; _.extend(o, SwapMixin); o.swap(construct, [1, 2, 3]); //=> [0, 1, 2, 3] /* Holeインスタンスの値を安全に取得するするための SnaphotMixinを作成する */ var SnapshotMixin = { snapshot: function () { return deepClone(this._value); }, }; /* 新しいHoleの仕様を 混ぜ込む */ _.extend( Hole.prototype, HoleMixin, ValidateMixin, ObserverMixin, SwapMixin, SnapshotMixin ); var h = new Hole(42); h.snapshot(); //=> 42 h.swap(always(99)); //=> 99 h.snapshot(); //=> 99
-
- mixin拡張は既存のデータ型を強化するためにも有用となる
- しかし、既存の方を拡張することは必ずしもシンプルではない
- またすべての拡張はグローバルに影響してしまうことに注意する
- 既存のJavaScriptのデータ型に新たな機能を追加する場合に、prototypeをいじる方法を取る問題
- Mixinの混ぜ込みによる新しい型
- オブジェクトやメソッドがその場における最適なソリューションである場合もある
Discussion
これは特に待っているのではないのでは……?
実質的にこれとほぼ同義みたいな処理では
(ほぼと言っているのは こっちの方が 2tick 早い可能性がある為