StableDiffusion+Dreamboothでスタックチャンをサハラ砂漠に飛ばす



↑このような画像が生成できましたのでそのやり方をメモします。
念の為ですが、これはAIが生成した画像であって、本当にスタックチャンがサハラ砂漠に行った訳ではありません。
スタックチャンについてはこちら参照ください
やりかたといっても、ほぼ以下の記事の手順通り、Google ColabratoryのNotebook上で実行しました。無料利用の枠の中で動かせました。
とりあえず学習に使う素材画像が必要なのでまずそれを準備します。
自前のスタックチャンを色々な角度からスマホで撮影しました。以下の5枚を学習素材にしました。

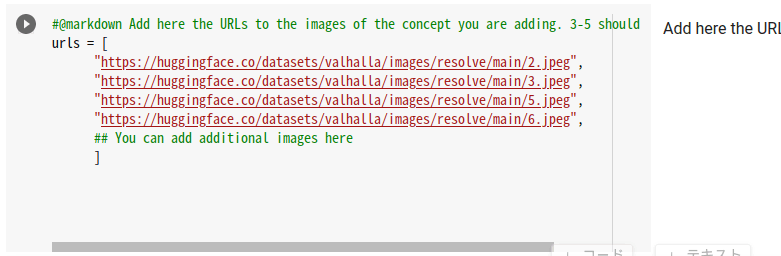
image0.jpg〜image4.jpgというファイル名で、自分のGoogleドライブの任意のフォルダに保存します。
参照記事の ◎Googleドライブから入力画像を読み込む方法 ではpngファイルを使っていますが、私は最初からjpgを使いました。たぶんそのあとの[image.save(f"{save_path}/{i}.jpeg") for i, image in enumerate(images)]でjpgに変換してるかと思います。
で、なぜか私がやったときにはそのあとのimage_grid(images, 1, len(images))で処理が終わらずランタイムから切断されてしまったので、その部分をコメントアウトしました。
ということで私の場合は以下のセルは実行せずに、
その次のセルを以下のようにして実行しました。
その次の Settings for your newly created concept はこんな感じ。

ここでinstance_promptをa photo of sks stack-chanとすればよかったかもしれませんが、robotとしたことで、あとで生成する画像のスタックチャンに、その他大勢のロボットの概念(ベクトル?)が、ちょっと染み出してきている気がしないでもないです。
そのあとは Teach the model the new concept (fine-tuning with Dreambooth) で学習を回します。30分ぐらいで終わりました。
そのあとは推論フェーズです。
Save your newly created concept? というセルがありますが、ここはよくわからなかったので実行しませんでした。
推論にはGradioというWebUIを使うパターンと、Colab上に画像表示するパターンがあります。
画像保存したい場合は2番目の Run the Stable Diffusion pipeline on Colab を使うほうがいいと思います。
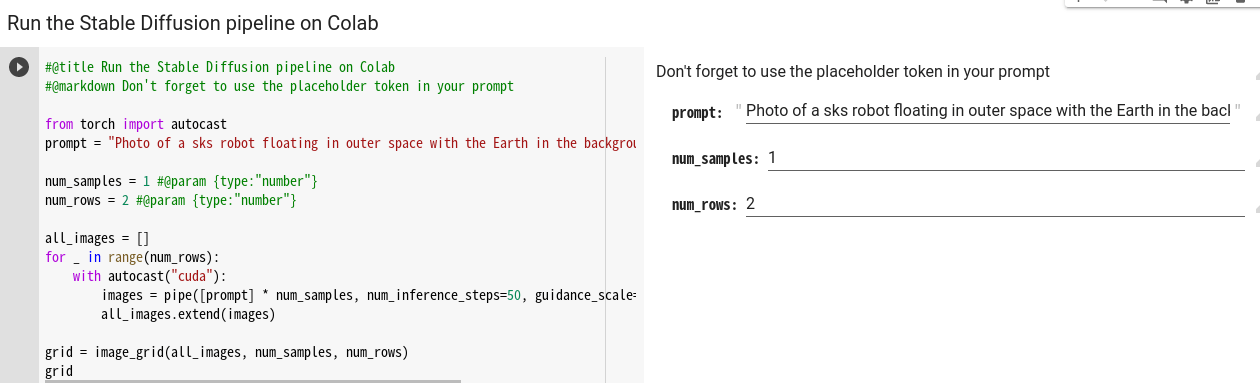
ここで右側の白背景のところにpromptを入力するのが通常だと思いますが、そこだとスペースが入力できなかったので、左側のコード部分(prompt="")に直接入力し実行しました。
完了すると以下のように画像表示されます。画像を右クリックから保存できました。
以下は"Photo of a sks robot floating in outer space with the Earth in the background"の生成結果です。
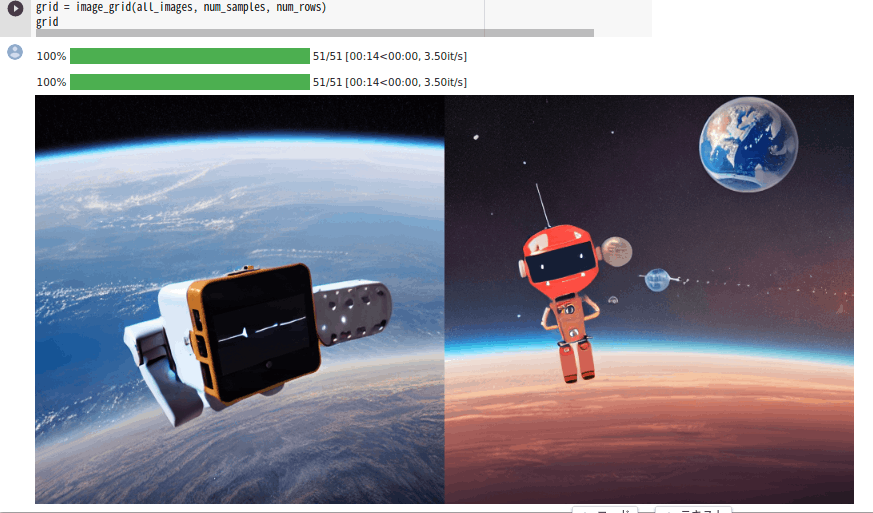
ここのコード部分でnum_inference_stepsとは画像生成に費やすステップ数、guidance_scaleプロンプトと出力画像の類似度とのことです。
↓こちらの記事参照
num_inference_stepsは50固定にしてましたが、guidance_scaleはちょこちょこいじりながら試しました。
冒頭のサハラ砂漠の画像は"sks robot in the sahara desert"で生成されました。
その他に生成できた画像と使ったpromptを以下に載せておきます。
"A photo of a robot with an aurora in the background" guidance_scale=9

"illustration of sks robot ukiyoe style" scale=7.5

"Vincent Van Gogh's sks robot oil painting" scale=7.5

"sks robot made of yarn" scale=10

"pixel art of sks robot" scale=10

"sks robot plush toy" scale=9

"illustration of sks robot with disney style" scale=7.5

"funny face sks robot"

これが顔っていうのは認識しているみたいです。
以上
見てわかる通り、学習に使った入力画像の影響が強く?入力にない向きの画像は生成されていません。
あと、顔の向きの情報は与えられてないので、front photoとか入れても正面の画像にはならなかったです。
あとなるべく強いワードを使うほうがいいようです。
例えばin Akihabaraだとうまくいかなかったんですが、in Sahara desertは強かったのかうまくいきました。
Discussion