streamlitでニュース要約アプリ作成し、Hugging spaceで無償公開する
想定読者
- 自然言語処理の初歩を学びたい方
- sreramlitでWebアプリを作成、公開してみたい方
はじめに
隙間時間にネットニュースを読むのですが、特定の分野の記事ばかり読んでしまうため、あまり関心のない分野の記事も読むきっかけが欲しいなと思っていました。そこで、ふと頭に浮かんだ単語を検索し、意味が近い単語が含まれるニュース記事が検索できれば、予想しない記事との運命的な出会いへの面白さを楽しみながら記事を読めるのではないかと思いました。
そこで今回は、検索ワードを入力すると、類似した単語が含まれるニュース記事の要約文が表示されるアプリをstreamlitで作成し、Hugging spaceで無償公開してみたいと思います。
公開したアプリはこちらです。
処理の流れ
- スクレイピングによりニュース記事を5件取得
- 各記事から代表する単語を5つ抽出
- 検索ワード(今回は名詞のみ)との類似度が高い単語が含まれる記事を特定
- 特定した記事を要約
- 要約文、url、類似度が高かった単語を画面に出力
プロジェクトの構造
はじめに、HuggingFaceSpacesで、リポジトリを作成し、ローカルにクローンしてください。
基本操作については、以下の記事で丁寧に解説されておりますので、参照ください。
今回のリポジトリ名はnews_summarizerとしました。クローンしてくると、リポジトリ名のディレクトリが作成されます。ディレクトリ内の配置は、以下のようになります。
news_summarizer
├── README.md
├── requirements.txt
├── app.py
├── news_scraper.py
├── tfidf_calculator.py
├── cosine_similarity_calculator.py
├── summerizer.py
└── ja/
├── ja.bin (cos類似度の計算で使用する学習済みモデルファイル)
├── ja.bin.syn0.npy
└── ja.bin.syn1neg.npy
開発環境
PC
OS:macOS14.4.1
プロセッサ:2.6 GHz 6コアIntel Core i7
メモリ:16 GB 2667 MHz DDR4
Python環境
注意点ですが、Pythonのバージョンは必ず3.8.Xにしてください。後述しますが、使用するgensimというライブラリをバージョン3.8.Xでインストールする必要があるためです。今回は3.8.2としました。エディタはPycharm、仮想環境はvirtualenvを使用しました。
ライブラリ
requirement.txtを次の通りとし、pip install -r requirements.txtを実行してください
beautifulsoup4==4.12.3
gensim==3.8.3
mecab-python3==1.0.9
requests==2.32.3
scikit-learn==1.3.2
sentencepiece==0.2.0
streamlit==1.35.0
torch==2.2.2
transformers==4.41.2
unidic-lite==1.0.8
HuggingFaceSpacesの開発環境の設定
HuggingFaceSpacesでは、Pythonのバージョンがデフォルトで3.10(2024/6/25時点)のため、バージョンを3.8.2に指定する必要があります。README.mdにpython_version: 3.8.2と記述することで、バージョンを指定できます。(他の項目は任意です)
---
title: News Summarizer
emoji: 📉
python_version: 3.8.2
colorFrom: blue
colorTo: indigo
sdk: streamlit
sdk_version: 1.35.0
app_file: app.py
pinned: false
---
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
Pythonプログラムの作成
step1~4ではニュース記事を取得し要約するまでの処理を記述したクラスの作成し、step5では、それらのクラスを使用しメイン処理を作成します。
step1:ニュース記事のスクレイピング
ニュース記事はyahooニュースの主要項目から5件取得します。
news_scraper.py
import requests
from bs4 import BeautifulSoup
import re
from time import sleep
class Scraper:
def __init__(self):
"""
Scraperクラスを初期化し、requestsセッションを作成
"""
self.session = requests.Session()
def _fetch_content(self, url):
"""
指定されたURLのコンテンツを取得する
Parameters:
- url (str): 取得するウェブページのURL
Returns:
- content (bytes): 取得したコンテンツのデータ
"""
response = self.session.get(url)
response.raise_for_status() # HTTPエラーが発生した場合は例外を投げる
return response.content
def _parse_html(self, html):
"""
HTMLコンテンツをBeautifulSoupでパース
Parameters:
- html (bytes): パースするHTMLコンテンツ
Returns:
- soup (BeautifulSoup): パースされたBeautifulSoupオブジェクト
"""
soup = BeautifulSoup(html, 'html.parser')
return soup
class YahooNewsScraper(Scraper):
base_url = "https://news.yahoo.co.jp/"
def get_news_urls(self):
"""
Yahooニュースのトップページから最新ニュース記事のURLを取得
Parameters:
- なし
Returns:
- article_url_list (list): ニュース記事のURLリスト(最大5件)
"""
content = self._fetch_content(self.base_url)
soup = self._parse_html(content)
news_list = soup.select('section.topics a') # 'topics'セクション内のすべての<a>タグを選択
article_url_list = [tag.get('href') for tag in news_list if tag.get('href')] # href属性を抽出
return article_url_list[:5] # 最初の5つのURLを返す
def get_article_url(self, index=0):
"""
指定したインデックスのニュース記事のURLを取得する
Parameters:
- index (int): 取得したい記事のインデックス (デフォルトは0)
Returns:
- article_url (str): 指定されたインデックスの記事のURL
Raises:
- IndexError: インデックスが範囲外の場合に発生
"""
article_urls = self.get_news_urls()
if index >= len(article_urls):
raise IndexError("URLが取得できませんでした") # インデックスが範囲外の場合は例外を投げる
return article_urls[index]
def get_article_detail_url(self, article_url):
"""
記事ページから詳細記事のURLを取得する
Parameters:
- article_url (str): ニュース記事のURL
Returns:
- detail_url (str): 記事の詳細ページのURL
Raises:
- ValueError: 詳細ページのURLが見つからない場合に発生
"""
content = self._fetch_content(article_url)
soup = self._parse_html(content)
detail_url_tag = soup.select_one('a:-soup-contains("記事全文を読む")') # "記事全文を読む"を含むリンクを選択
if detail_url_tag:
return detail_url_tag.get('href') # タグのhref属性を返す
else:
raise ValueError("ニュース記事が見つかりませんでした") # タグが見つからない場合はエラーを出力
def get_full_article_text(self, detail_url):
"""
詳細記事の全文を取得し、不要な文字を削除する
Parameters:
- detail_url (str): 記事の詳細ページのURL
Returns:
- full_text (str): 記事の全文テキスト
"""
content = self._fetch_content(detail_url)
soup = BeautifulSoup(content, 'html.parser')
paragraphs = soup.select('article div.article_body p') # 記事本文内のすべての<p>タグを選択
full_text = ''.join([p.text for p in paragraphs]) # すべての段落のテキストを結合
return re.sub(r"[\u3000\n\r]", "", full_text) # 不要な文字を削除
def scrape_article(self, index=0):
"""
指定されたインデックスの記事をスクレイプし、全文を取得する
Parameters:
- index (int): スクレイプする記事のインデックス (デフォルトは0)
Returns:
- full_text (str): スクレイプされた記事の全文テキスト
"""
article_url = self.get_article_url(index)
sleep(1) # サーバー負荷を避けるために1秒待機
detail_url = self.get_article_detail_url(article_url)
sleep(1) # サーバー負荷を避けるためにさらに1秒待機
article_text = self.get_full_article_text(detail_url)
return article_text, detail_url
プログラムの冗長性を考えて、スクレイピングの基本処理をまとめたScraperという親クラスを作成し、子クラスのYahooNewsScraperで継承しています。他サイトからスクレイピングする際は、子クラスを増やすことで、拡張できるようにしました。メインプログラムには、scrape_articleメゾットから記事のテキストとurlを返します。
step2:MeCabによる記事の代表ワードの取得(TF-IDF値の計算)
記事を代表するワードを抽出します。代表するワードの評価には、ワード検索やテキストマイニングの分野で使用されるTF-IDF値を用います。値の大きい上位5単語をその記事の代表する単語と定義します。
tfidf_calculator.py
import MeCab
import re
from sklearn.feature_extraction.text import TfidfVectorizer
class JapaneseTextVectorizer:
def __init__(self):
"""
MeCabのTaggerとTF-IDFベクトライザーを初期化
"""
self.mecab_tagger = MeCab.Tagger()
self.tfidf_model = TfidfVectorizer(token_pattern='(?u)\\b\\w+\\b', norm=None)
self.vocab_list = []
def _extract_nouns(self, text):
"""
テキストから名詞を抽出
Parameters:
- text (str): 名詞を抽出する対象のテキスト
Returns:
- nouns (list): 抽出された名詞リスト
"""
node = self.mecab_tagger.parseToNode(text)
nouns = []
while node:
word = node.surface
hinshi = node.feature.split(",")[0]
if hinshi == "名詞":
if (not word.isnumeric()) and (not re.match(r'^[\u3040-\u309F]+$', word)):
# 名詞が数値と平仮名のみの場合は除き、それ以外の名詞を保存
nouns.append(word)
node = node.next
return nouns
def fit_transform(self, text):
"""
テキストをTF-IDF表現に変換
Parameters:
- text (str): TF-IDF表現に変換する対象のテキスト
Returns:
- tfidf_dict (dict): 単語とそのTF-IDF値を格納した辞書
"""
nouns = self._extract_nouns(text)
self.tfidf_model.fit(nouns)
vocab_text = " ".join(nouns)
tfidf_vec = self.tfidf_model.transform([vocab_text]).toarray()[0]
tfidf_dict = dict(zip(self.tfidf_model.get_feature_names_out(), tfidf_vec))
tfidf_dict = {word: num_val for word, num_val in tfidf_dict.items() if num_val > 0}
# TF-IDF値で辞書をソートし、上位5つの要素を取得
top_tfidf = dict(sorted(tfidf_dict.items(), key=lambda x: x[1], reverse=True)[:5])
return top_tfidf
まず、_extract_nounsメゾットでスクレイピングで取得した記事を読み込みます。読み込んだ記事を、Mecabによって形態素解析していきます。具体的にはnode = self.mecab_tagger.parseToNode(text)で行っています。続いて、 while node:以降の処理で名詞を抽出します。
fit_transformメゾットで各単語のTF-IDF値を計算し、値の高い上位5単語をtop_tfidfに格納し、メインプログラムに返します。
step3:検索ワードと記事の代表ワードとのcos類似度を求める
ユーザーが入力した検索ワードとstep2で記事から所得したTF-IDF値の高い上位5単語とのcos類似度を計算します。cos類似度の計算には、Word2Vecアルゴリズムを実装できるライブラリgenismを用いました。日本語の学習済みベクトルは、以下のgithubからモデルをダウンロードさせていただきました。
画像の黄色枠のモデルをダウンロードし、ダウンロードしたモデル(jaというディレクトリ)をプロジェクトの直下に配置してください。
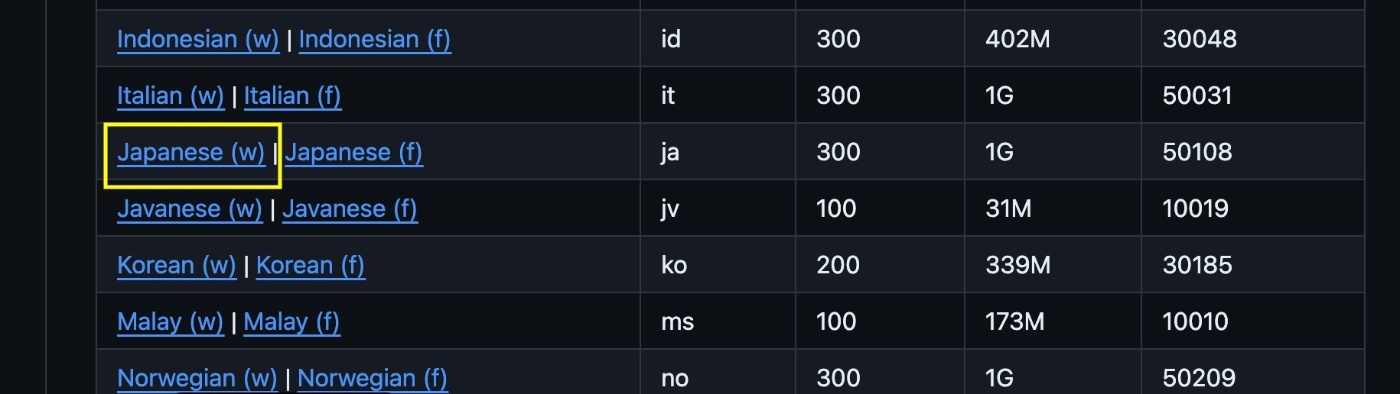
また、このモデルは、gensim.models.Word2Vec.loadで読み込む必要があるのですが、genismの最新版では対応しておらず、gensim==3.8.3を用いる必要があります(そのため、Python3.8.3とする必要がありました)。詳細は、こちらの記事を参考にさせてもらいました。https://qiita.com/omuram/items/6570973c090c6f0cb060
cosine_similarity_calculator.py
import gensim
from sklearn.metrics.pairwise import cosine_similarity
class CosineSimilarityCalculator:
model_path = 'ja/ja.bin'
def __init__(self):
"""
CosineSimilarityCalculatorクラスを初期化し、
事前トレーニング済みのWord2Vecモデルをロード
Parameters:
- なし
Returns:
- なし
"""
self.model = gensim.models.Word2Vec.load(CosineSimilarityCalculator.model_path)
def _convert_to_2d_array(self, vector):
"""
埋め込みベクトルを2次元配列に変換
Parameters:
- vector (numpy.ndarray): 変換する1次元配列のベクトル
Returns:
- vector_2d (numpy.ndarray): 変換後の2次元配列のベクトル
"""
return vector.reshape(1, -1)
def _calculate_cosine_similarity(self, embedding1, embedding2):
"""
cos類似度を計算
Parameters:
- embedding1 (numpy.ndarray): 1つ目の単語ベクトル(2次元配列)
- embedding2 (numpy.ndarray): 2つ目の単語ベクトル(2次元配列)
Returns:
- similarity (numpy.ndarray): cos類似度
"""
return cosine_similarity(embedding1, embedding2)
def calculate_similarity(self, search_word, article_keyword_list):
"""
指定された検索ワードと記事のキーワードリストの間のcos類似度を計算
モデルにない単語の場合はエラーメッセージを出力しブレイクする
Parameters:
- search_word (str): 検索ワード
- article_keyword_list (list): 記事のキーワードリスト
Returns:
- similarities (dict): 記事キーワードとそれぞれの検索ワードのcos類似度を含むdictを作成
モデルにない単語の場合はNoneを返す
"""
# 検索ワードの埋め込みベクトルを取得
if search_word in self.model.wv:
search_embedding = self.model.wv[search_word]
else:
return None
similarities = {}
# 記事キーワードの埋め込みベクトルを取得し、cos類似度を計算
for keyword in article_keyword_list:
if keyword in self.model.wv:
keyword_embedding = self.model.wv[keyword]
search_embedding_2d = self._convert_to_2d_array(search_embedding)
keyword_embedding_2d = self._convert_to_2d_array(keyword_embedding)
similarity = self._calculate_cosine_similarity(search_embedding_2d, keyword_embedding_2d)
similarities[keyword] = similarity[0][0]
else:
similarities[keyword] = None
return similarities
calculate_similarityで、モデルから検索ワードのベクトルを引き当て、TF-IDF値の上位5単語とのcos類似度を計算し、計算結果をメインプログラムに返します。
step4:ニュース記事の要約
step1~3の処理の後、メインプログラムでは、5つの記事の代表ワードである5単語(IF-IDF値の高い上位5単語)、すなわち、計25単語の中から検索ワードと最もcos類似度が高い(値が1に近い)単語を抽出します。その単語を含む記事が目的の記事となります。step4では、その記事を要約する処理を記述していきます。テキスト処理には、transformersを使用し、sonoisa/t5-base-japaneseのモデルを活用させていただきました。
summerizer.py
from transformers import pipeline, T5Tokenizer, T5ForConditionalGeneration
class TextSummarizer:
model_name = "sonoisa/t5-base-japanese"
tokenizer_name = "sonoisa/t5-base-japanese"
def __init__(self):
"""
TextSummarizerクラスを初期化し、トークナイザ、モデル、パイプラインを設定
Parameters:
- なし
Returns:
- なし
"""
# トークナイザを個別に初期化し、legacy=Falseを指定
self.tokenizer = T5Tokenizer.from_pretrained(self.tokenizer_name, legacy=False)
# モデルを個別に初期化
self.model = T5ForConditionalGeneration.from_pretrained(self.model_name)
# パイプラインを初期化
self.summarizer = pipeline("summarization", model=self.model, tokenizer=self.tokenizer)
def summarize(self, text, max_length=20, min_length=10):
"""
テキストを要約
Parameters:
- text (str): 要約する対象のテキスト。
- max_length (int): 要約の最大長 (デフォルトは20)
- min_length (int): 要約の最小長 (デフォルトは10)
Returns:
- summary_text (str): 要約されたテキスト
"""
summary = self.summarizer(text, max_length=max_length, min_length=min_length, do_sample=False)
return summary[0]['summary_text']
コメントが多いですが、実際にテキストを読み込み要約の処理を行っているのは、わずか7,8行程度です。この記述量の少なさで、要約処理ができてしまうのが、transformersの凄いところですね。流れとしては、パイプラインをコンストラクタの部分で組んでしまい、summarizeでテキスト(記事)を渡して、要約文を返します。要約文の文字数は、あまり長くすると文章を繰り返して表示してしまう傾向があったため、デフォルトで最大20文字、最小10文字としました。
step5:アプリのメイン処理
最後にstep1~4で作成したクラスをメインプログラムで呼び出して、一連の処理を完成させていきます。
app.py
import streamlit as st
from news_scraper import YahooNewsScraper
from tfidf_calculator import JapaneseTextVectorizer
from cosine_similarity_calculator import CosineSimilarityCalculator
from summerizer import TextSummarizer
st.title("最新ニュース要約アプリ")
# 初期化
best_article_text = None
best_article_url = None
best_max_word = None
max_word = None
best_max_value = -1 # cos類似度は0以上なので、初期値を-1に設定
num_news = 5
# セッションステートの初期化
if 'news_fetched' not in st.session_state:
st.session_state['news_fetched'] = False
st.session_state['article_text_list'] = []
st.session_state['article_url_list'] = []
if st.button('最新ニュース取得'):
with st.spinner('ニュースを取得中...'):
# yahooニュースをスクレイピング
scraper = YahooNewsScraper()
article_text_list = []
article_url_list = []
for i in range(num_news):
article_text, detail_url = scraper.scrape_article(i)
article_text_list.append(article_text)
article_url_list.append(detail_url)
st.session_state['news_fetched'] = True # 処理完了フラグを設定
st.session_state['article_text_list'] = article_text_list # セッションステートに保存
st.session_state['article_url_list'] = article_url_list
st.write("取得完了しました")
if st.session_state['news_fetched']:
search_word = st.text_input('名詞', placeholder='名詞を入力してください', max_chars=10, help='10文字以内の名詞')
if st.button('要約作成'):
if search_word.strip() == '':
st.error('名詞を入力してください。')
elif len(search_word) > 10:
st.error('名詞は10文字以内で入力してください。')
else:
with st.spinner('ニュースの要約を作成中...'):
article_text_list = st.session_state['article_text_list']
article_url_list = st.session_state['article_url_list']
try:
for temp_article_text, temp_article_url in zip(article_text_list, article_url_list):
# TF-IDF値を計算
vectorizer = JapaneseTextVectorizer()
tfidf_dict = vectorizer.fit_transform(temp_article_text)
# cos類似度を計算
word_similarity = CosineSimilarityCalculator()
article_keyword_list = list(tfidf_dict.keys())
result_word_similarity = word_similarity.calculate_similarity(search_word, article_keyword_list)
if result_word_similarity is None:
raise ValueError("単語の類似度を計算できませんでした。名詞を変更して再度試してください。")
# cos類似度の計算結果
filtered_data = {k: v for k, v in result_word_similarity.items() if v is not None}
# 最大値を持つキーとその値を取得
if filtered_data: # filtered_dataが空でないことを確認
max_word = max(filtered_data, key=filtered_data.get)
max_value = filtered_data[max_word]
# 最大値がこれまでの最大値より大きければ更新
if max_value > best_max_value:
best_max_value = max_value
best_max_word = max_word
best_article_text = temp_article_text
best_article_url = temp_article_url
is_similarity_computed = True # 類似度が計算されていれば、フラグをTrueにする
# テキストを要約
summarizer = TextSummarizer()
summary_text = summarizer.summarize(best_article_text, max_length=40, min_length=20)
st.write(f'最も類似度が高いワードは「{best_max_word}」でした')
st.write(f'url:{best_article_url}')
st.text_area("要約:", summary_text, height=20)
except ValueError as ve:
st.error(f"エラー: {ve.args[0]}")
まず、「最新ニュース取得」ボタンを押されたら、スクレイピングにより、最新ニュース記事とそのurlを5件取得するようにします。スクレイピングはstep1で作成したYahooNewsScraperクラスで行います。取得した記事、urlは、それぞれarticle_text_listとarticle_url_listに格納されます。ただ、このままですと、次に表示する「要約作成」ボタンを押すと初期化され、リストが空になってしまうので、st.session_stateに保存する必要があります。
if st.button('最新ニュース取得'):
with st.spinner('ニュースを取得中...'):
# yahooニュースをスクレイピング
scraper = YahooNewsScraper()
article_text_list = []
article_url_list = []
for i in range(num_news):
article_text, detail_url = scraper.scrape_article(i)
article_text_list.append(article_text)
article_url_list.append(detail_url)
st.session_state['news_fetched'] = True # 処理完了フラグを設定
st.session_state['article_text_list'] = article_text_list # セッションステートに保存
st.session_state['article_url_list'] = article_url_list
st.write("取得完了しました")
スクレイピングで記事を取得後に、検索ワードの入力欄と「要約作成」ボタンを表示させます。
また、検索ワードは名詞のみを入力するようユーザーに促したいので、入力欄の初期表示を設定しましょう。st.text_inputの引数に、placeholder='名詞を入力してください'を渡します。
if st.session_state['news_fetched']:
search_word = st.text_input('名詞', placeholder='名詞を入力してください', max_chars=10, help='10文字以内の名詞')
if st.button('要約作成'):
「要約作成」ボタンを押下後、取得した5件の記事とurlをforループでひとつずつ取り出します。
for temp_article_text, temp_article_url in zip(article_text_list, article_url_list):
step2,3で作成したJapaneseTextVectorizerとCosineSimilarityCalculatorクラスで記事のTF-IDF値の高い上位5単語を代表するワードとし、それらのワードと検索ワードとのcos類似度を計算します。
# TF-IDF値を計算
vectorizer = JapaneseTextVectorizer()
tfidf_dict = vectorizer.fit_transform(temp_article_text)
# cos類似度を計算
word_similarity = CosineSimilarityCalculator()
article_keyword_list = list(tfidf_dict.keys())
result_word_similarity = word_similarity.calculate_similarity(search_word, article_keyword_list)
if result_word_similarity is None:
raise ValueError("単語の類似度を計算できませんでした。名詞を変更して再度試してください。")
# cos類似度の計算結果
filtered_data = {k: v for k, v in result_word_similarity.items() if v is not None}
検索ワードと最もcos類似度が高い単語を含む記事を検索対象の記事とし、その記事のテキストとurlを習得します。
# 最大値を持つキーとその値を取得
if filtered_data: # filtered_dataが空でないことを確認
max_word = max(filtered_data, key=filtered_data.get)
max_value = filtered_data[max_word]
# 最大値がこれまでの最大値より大きければ更新
if max_value > best_max_value:
best_max_value = max_value
best_max_word = max_word
best_article_text = temp_article_text
best_article_url = temp_article_url
is_similarity_computed = True # 類似度が計算されていれば、フラグをTrueにする
step4のTextSummarizerにより記事のテキストを要約します。
# テキストを要約
summarizer = TextSummarizer()
summary_text = summarizer.summarize(best_article_text, max_length=40, min_length=20)
画面にcos類似度が高いワード、その記事、urlを表示します。
st.write(f'最も類似度が高いワードは「{best_max_word}」でした')
st.write(f'url:{best_article_url}')
st.text_area("要約:", summary_text, height=20)
以上がアプリの一連の流れになります。
アプリの実行
ローカルでの動作確認
次のコマンドを実行してStreamlitを起動させます。
streamlit run app.py
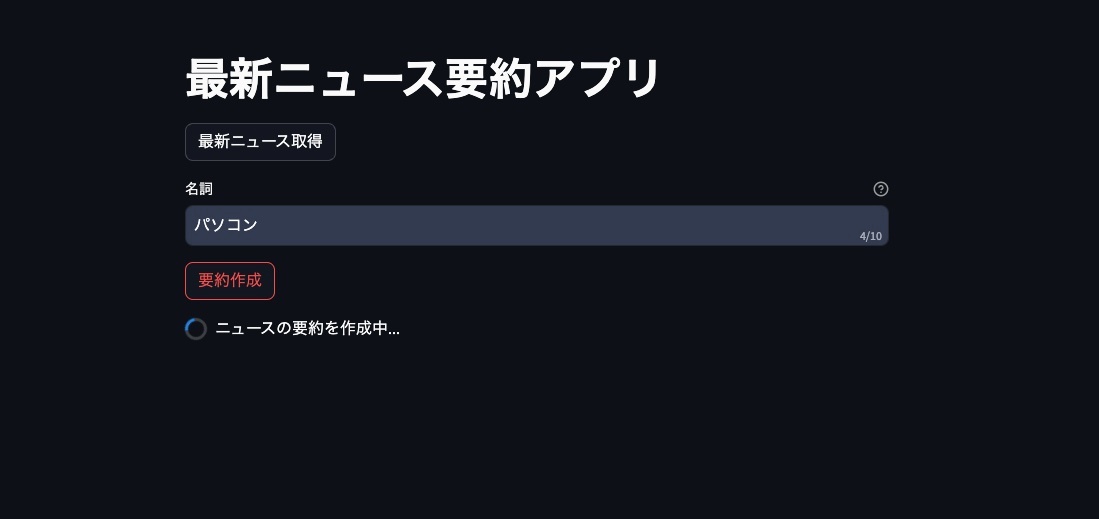
初期画面

最新ニュース取得ボタンが押されると、ニュース記事がスクレイピングされます。

スクレイピング後、検索ワード(名詞のみ)を入力し要約作成ボタンを押します。
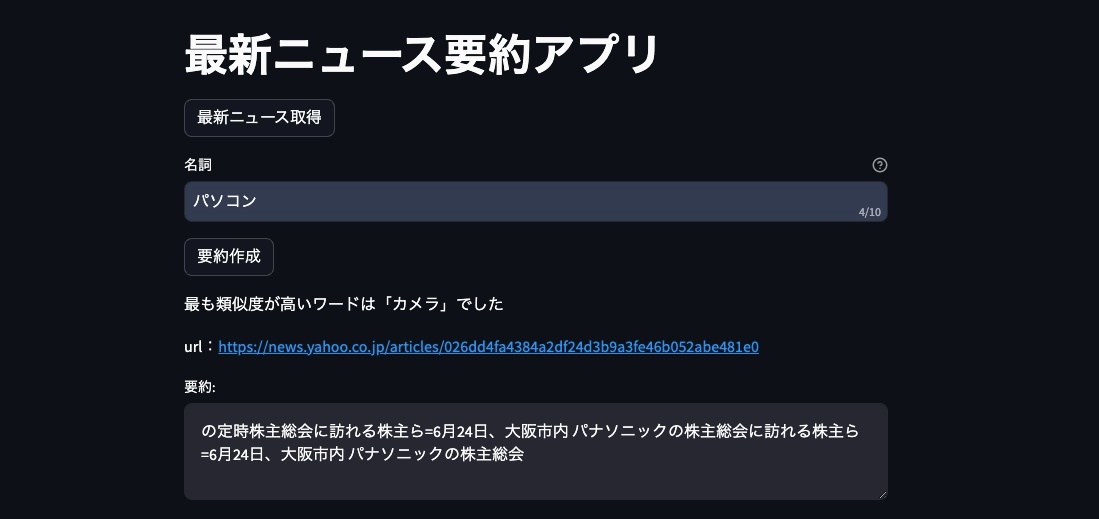
検索ワードと最も類似度が高い単語と、その単語が含まれた記事の要約文、記事のurlが表示されます。
今回の場合、検索ワード「パソコン」と最も類似度が近かった単語は「カメラ」でした(電化製品繋がり?)。
ローカルでの動作確認できましたら、HuggingFaceSpacesにPushします。
Pushの方法については、こちらの記事を参考にしてください。
今後の課題
-
要約文の精度
お気づきかもしれませんが、要約文が意味はなんとなく伝わるものの、文章としてはあと一歩です。今回、要約にはsonoisa/t5-base-japaneseのモデルを拝借しましたが、より要約の精度が上がるモデルについても、Hugging spaceの環境のスペックを考慮しながら、検討していきたいと思います。
-
単語間類似度の評価手法
類似度にはWord2Vecを用いましたが、以下の記事を参考にすると、BERTによっても単語間類似度を評価できることがわかりました。Word2VecとBERTの精度を比較し、どちらを採用すべきか検討する余地がありそうです。
まとめ
今回は、検索ワードに類似する単語が含まれるニュース記事の要約文を表示するアプリをStreamlitで作成し、Hugging Faceで公開するまでの手順を紹介しました。このアプリを活用して、運命的なニュース記事との出会いを楽しんでいただければ幸いです。
Discussion