SolrでもRAGできるもん!
はじめに
この記事は、情報検索・検索技術 Advent Calendar 2023 の 23日目の記事です。
本記事では、Solrをバックエンドにして、最近流行りの RAG をしてみます。
RAGとは
再三多くの記事で解説されているので今さら説明するまでもなさそうですが、ユーザからの質問に回答するために必要そうな内容が書かれた文章を検索し、その文章を LLM への入力(プロンプト)に付け加えて入力する手法です。
さまざまな問いかけに答えてくれる ChatGPT の能力に驚かされますが、知らない知識に関しては当然のことながら答えられません。 例えば、ChatGPT の無料版である GPT-3.5 については、2021 年 9 月までの Web 上の情報をもとに学習をしているので、それ以後に世に出た情報については知りません。 また、Web 上に公開されている情報源に関してしか知らないので、自社のサービス固有の情報に関する回答や社外秘情報に関しては当然ながら答えられません。
わからないことについては、一律答えられませんと言ってくれればまだいいのですが、それより厄介なことも起こり得ます。 ハルシネーション(幻覚)と呼ばれる現象で、誤った回答であるにもかかわらず、自信満々に真実であるかのように回答してしまうことがあるのです[1]。
お勉強用途で LLM が返してきたサンプルコードを動かしたらエラーで動かなかった程度で済めばまだいいですが、プロダクトとしてリリースしたものが嘘八百状態では会社の信用問題にかかわるので致命的です。 仮に追加で知識が付与できたとしても、AI はそれが真実であるか否かは関知しないので、ハルシネーションを完全に防止することはできません。
これへの対応策として今一番注目されている手法が、RAG(Retrieval Augmented Generation)と呼ばれる手法です[2]。
RAG は、 プロンプトと呼ばれる LLM への入力情報にモデル外部の情報源からの検索結果を付加して、検索結果に基づいた回答をさせています。 モデルはプロンプトに含まれているリファレンス情報をもとにユーザからの要望に回答すればいいので、知識にないことであっても正確に答えられるようになるのではないかという発想です。

このリファレンス情報の取得のために検索エンジンへのリクエストを投げるステップがあります。
SolrでRAGをする
Qdrant などのベクトル検索に特化しているエンジンはもちろん、Elasticsearch についてもLangchain との連携が公式にサポートされています[3][4]。
特にこだわりなければ、すなおにこれらを使うのが開発コストがかからずいいと思います。
そこを本記事ではあえて Solr をバックエンドに使おうと思います。
理由は私が Solr を使っているからです。それだけです。
最近はすっかり Elasticsearch に人気を取られがちですが、いろいろなしがらみで Solr を使っている人もいると思います。
本記事はそんな人に届けばいいなと思います。
さて、Solr と Langchain の連携状況ですが、現在 issue は出ているもののの公式にはまだサポートされていません[5]。
ただ、有志の方が作ったライブラリはありました[6]。
pipで簡単に入れられます。
$ pip install eurelis-langchain-solr-vectorstore
Qdrant や Elasticsearch でサポートされているような基本的なインターフェイスは用意されています。
ですので、他検索エンジンと同じように Solr とも連携できそうです。
本記事では、これを使って、Solr をバックエンドにRAGができるか試してみたいと思います。
Usage
ちょっと README を見ただけだと使い方がわかりにくいので解説します。
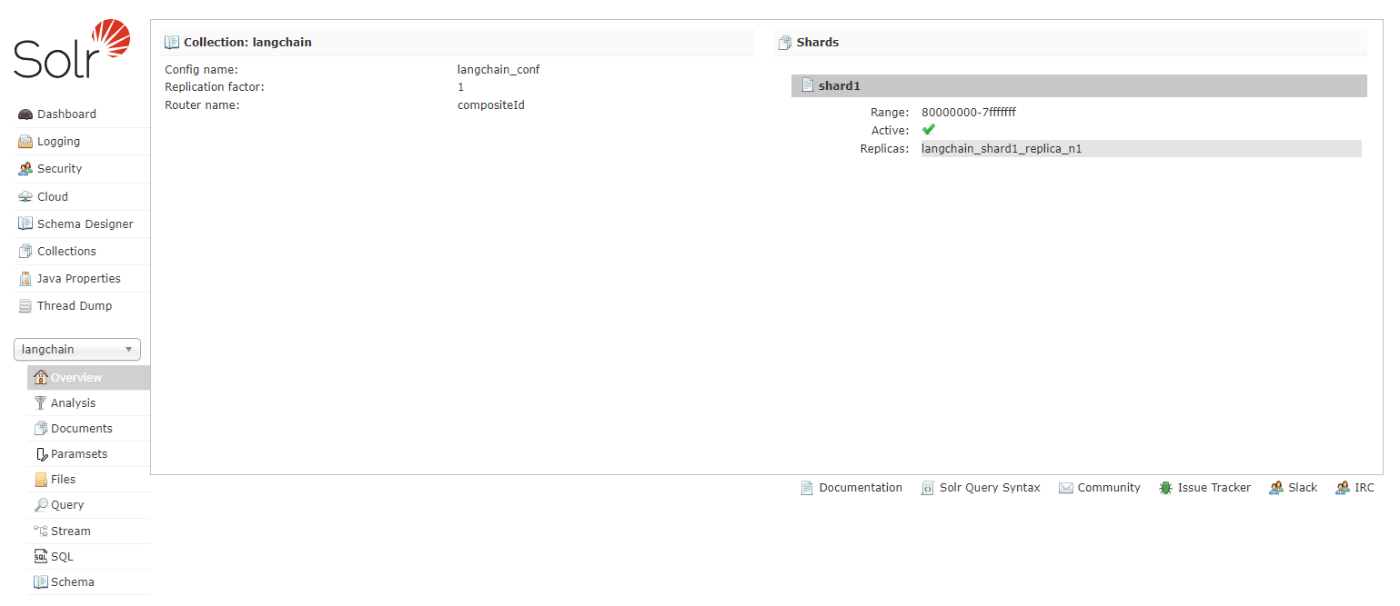
まずは、Solr 側で事前にフィールドの設定をします。
この辺りは以前に解説した記事があるので、これらを参考にコレクションの作成を行っておきます[7]。
例えば、テキストデータとそのベクトルデータを格納するフィールドを用意しておきます。
<field name="text" type="string" indexed="true" stored="true"/>
<field name="vector" type="knn_vector" indexed="true" stored="true"/>
<fieldType name="string" class="solr.StrField" sortMissingLast="true" docValues="true"/>
<fieldType name="knn_vector" class="solr.DenseVectorField" vectorDimension="768" similarityFunction="euclidean"/>
続いて Langchain から Solr と接続するクライアントインスタンスを用意します。
from langchain.embeddings import HuggingFaceEmbeddings
from eurelis_langchain_solr_vectorstore import Solr
model_name = "pkshatech/GLuCoSE-base-ja"
embeddings = HuggingFaceEmbeddings(model_name=model_name) # you are free to use any embeddings method allowed by langchain
vector_store = Solr(embeddings, core_kwargs={
'page_content_field': 'text', # field containing the text content
'vector_field': 'vector', # field containing the embeddings of the text content
'core_name': 'langchain', # core name
'url_base': 'http://localhost:8983/solr' # base url to access solr
}) # with custom default core configuration
embeddings には使用したい Embedding モデルをしていします。
HugginFace で公開されているモデルはおおよそ使えます。
日本語LLMまとめというすばらしいまとめがありましたので、ここからお好みのものを選ぶとよいと思います。
Solr の引数にはそれぞれ接続先の Solr の設定情報を定義していきます。
-
page_content_field: ベクトル検索の結果として、このフィールドの値が取得される。通常、ベクトルデータの元になったテキストデータフィールドを指定する。flで取得できる必要があるので、Solr 側でstored="true"などに設定しておく必要がある。 -
vector_field: ベクトル検索の対象となるフィールド名を指定する。 -
core_name: 検索対象とする Solr のコア名を指定する。 -
url_base: 接続先の Solr のエンドポイントを指定する。
インデックス
接続クライアントが用意出来たら、 Langchain のインターフェイスを使ってテキストの Embedding からインデックスができます。
vector_store.add_documents を使えば、テキストを渡すだけで元のテキストとその Embedding 結果をインデックスしてくれちゃいます。
from langchain.docstore.document import Document
docs = [{"text": "SolrでもRAGできるもん!"}]
metadatas = [{"tag": "solr"}]
indexes = [Document(page_content=doc["text"], metadata=metadata) for doc, metadata in zip(docs, metadatas)]
vector_store.add_documents(indexes)
add_documents には LangChain で用意されている専用の型である必要があるので、あらかじめこの型形式に変換しておきます。
page_content に Embedding をさせたいテキストデータを渡しておきます。
厚くラップされているので、機械学習関連の処理がよくわかっていなくても、たった2行だけで使えてしまいます。
その他のフィールドについてもメタデータとして渡せばインデックスできます。

検索
検索についても簡単です。
インデックスのときと同じ Embedding モデルを指定してクエリを渡すだけです。
query = "Solrでのベクトル検索の始め方を教えてください。"
retriever = vector_store.as_retriever()
docs = retriever.get_relevant_documents(query=query)
docs には、インデックス時と同じ Document 型でヒットしたドキュメントの元テキストが取得できます。
あとはこれをリファレンス情報としてLLMに渡せばOKです。
必要に応じてさまざまなオプションが指定できます。
retriever = vector_store.as_retriever(
search_type = "similarity_score_threshold", # スコア閾値を使用したいときに指定
search_kwargs = {
"k": k, # topK 件のドキュメントだけ取得する
"filter": {"tag": "solr"}, # Solr の fq の条件を指定できる。使用できるフィールドはインデックス時に metadata で渡したフィールドのみ
"score_threshold": 0.5 # score の閾値。これを上回ったドキュメントだけ取得する
}
)
RAG で回答生成をしてみる
せっかくなので、RAGを使ってモデルは絶対に知らないであろう質問に対して回答させてみます。
ここから先は Solr に限らない、汎用的なお話です。
ChatGPTでのRAGについては多くの記事で解説されているので、日本語対応しているローカルLLMでやってみます。
今回は、cyberagent/calm2-7b-chat · Hugging Face を使ってみます。
Solr 公式ドキュメントの Dense Vector Search :: Apache Solr Reference Guide の章を日本語訳してインデックスさせておきます。
この状態で、適当なテンプレートを用意しておき、ベクトル検索の結果とユーザ入力を埋め込んで LLM に入力します。
context = "ベクトル検索でヒットしたドキュメント"
query = "ユーザの入力"
prompt = """USER: 貴方はユーザーの質問に答えるAIアシスタントBotです。
ユーザーの質問に対して適切なアドバイスを答えます。
情報として、以下の内容を参考にしてください。
========
{context}
========
さて、「{query}」という質問に対して、上記の情報を元に、答えを考えてみましょう。
ASSISTANT: """.format(context=context, query=query)
ここでは、「Solrでのベクトル検索の始め方を教えてください」 と聞いてみます。
RAG なしだと Lucene に直接手を加えるような提案をしてくるのに対し、RAG ありだとちゃんとスキーマ定義の方法などを答えてくれます[8]。
ほかにも私のサークルである「もちっとカフェについて」という絶対にモデルが知らないであろう質問をしてみます。
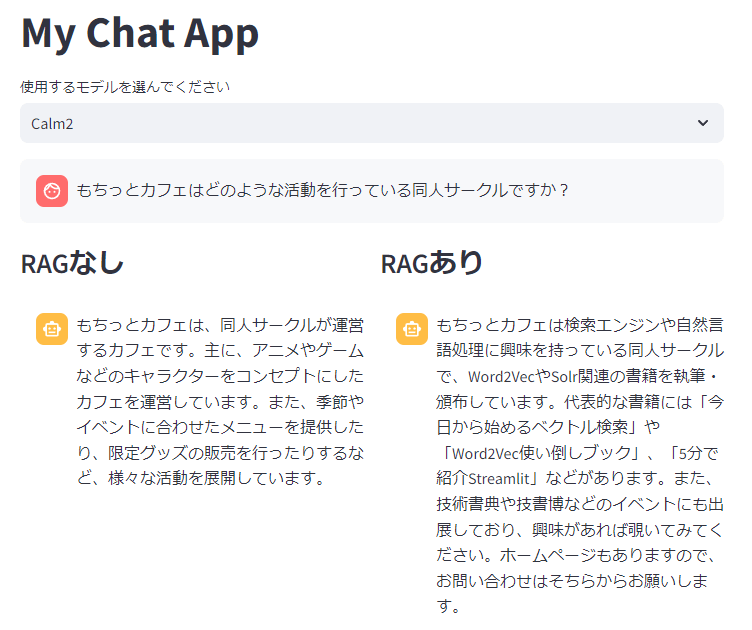
実は、この質問についてはベクトル検索の結果ヒットしたドキュメントは次のようになっています。
もちっとカフェは検索エンジンやそれにまつわる自然言語処理を中心にサークル主である「さしみもち」が興味を持ったことを日々アウトプットしている同人サークルです。Word2VecやSolr関連の書籍の執筆や頒布活動を行っています。代表的な書籍には「今日から始めるベクトル検索」や「Word2Vec使い倒しブック」、「5分で紹介Streamlit」などがあります。技術書典や技書博などのイベントにも出展しているのでご興味あれば覗いてみてください。サークルホームページもあります。(https://sashimimochi.netlify.app/)
ときどき、「RAGまでやる必要はなく、ベクトル検索の結果をそのまま返せばいいじゃん」という意見も見かけます。
これには私も一部同意することろではあります。
とはいえ、確かに情報量はヒットしたドキュメントそのものから増えていませんが、Solr でのベクトル検索の例などでは適度に要約されたり、箇条書き形式で構造化されていて読みやすくなっています。感動しました。
おわりに
本記事では Solr をバックエンドにした RAG を試してみました。
なかなか可能性を感じる結果が得られましたので、みなさんもぜひ RAG 試してみてください。
本記事ではあたかもすべてが順調にうまくいったかのように書きましたが、実は裏では結構苦労しました。
細かいソースコードやそういった苦労話については近日別記事にして投稿しようと思います。
お楽しみに。
Discussion