Solr9 から導入されたベクトル検索ってどんな感じ?
忙しい人向けの要点
- ベクトルデータさえあれば必要な Solr 定義はたった2行
- クエリも
q,fq,rqqで使えて、指定方法もシンプル - 100万件程度のインデックスでもレスポンスタイムは数10ms~数100msなので割と使えそう
- Solr には embedding 機能はないので、インデックスデータやクエリのベクトル変換はどうにか頑張ってください

はじめに
Solr9 から、個人的に切望していた DenseVectorField フィールド型と K近傍法(KNN)クエリーパーサーによる密ベクトルニューラル検索が追加されました。
ベクトル検索を使えば、類似画像の検索やシノニム(類義語辞書)を使わずに同義語を含むドキュメントの検索など従来全文検索エンジンでは到底実現できなかった検索ができるようになります。
例えば以下のように、クエリキーワードそのものを含んでいなくても、似たような内容のドキュメントがヒットさせられるようになります。
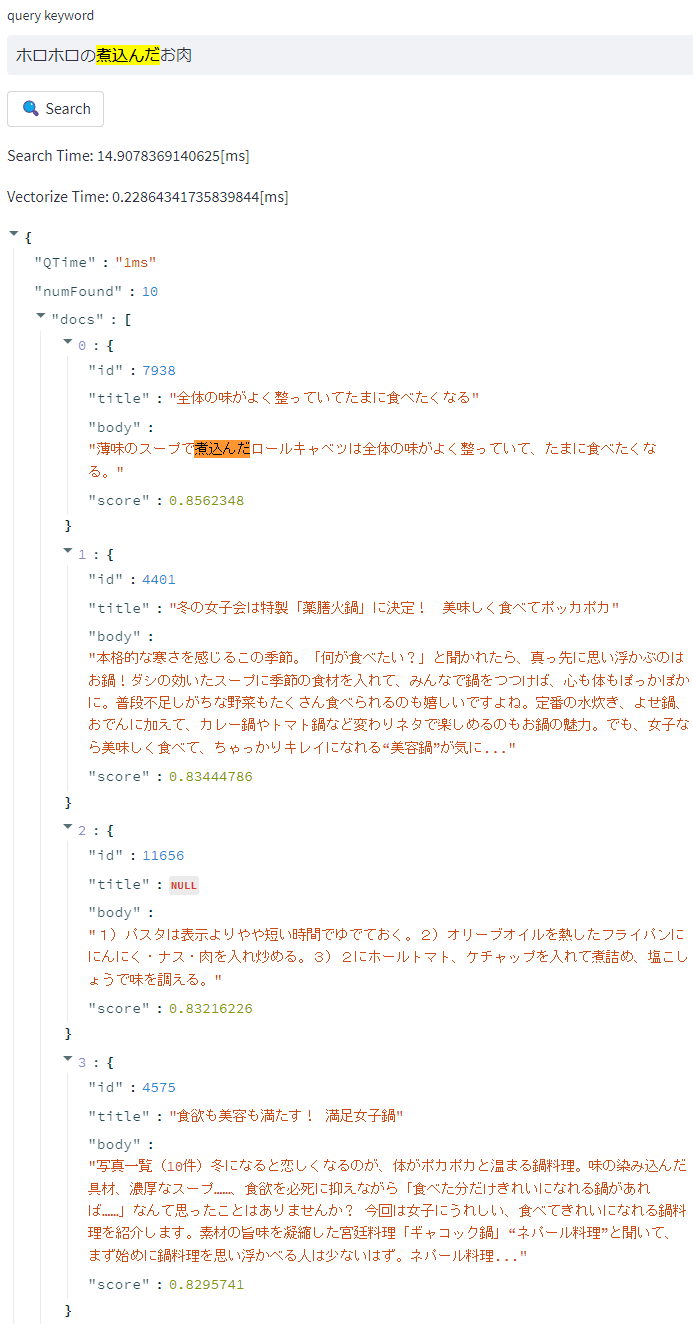
ex. テキスト to テキスト検索
それ以外にも、画像から類似した画像の検索やテキストから画像の検索などができるようになったりもします。
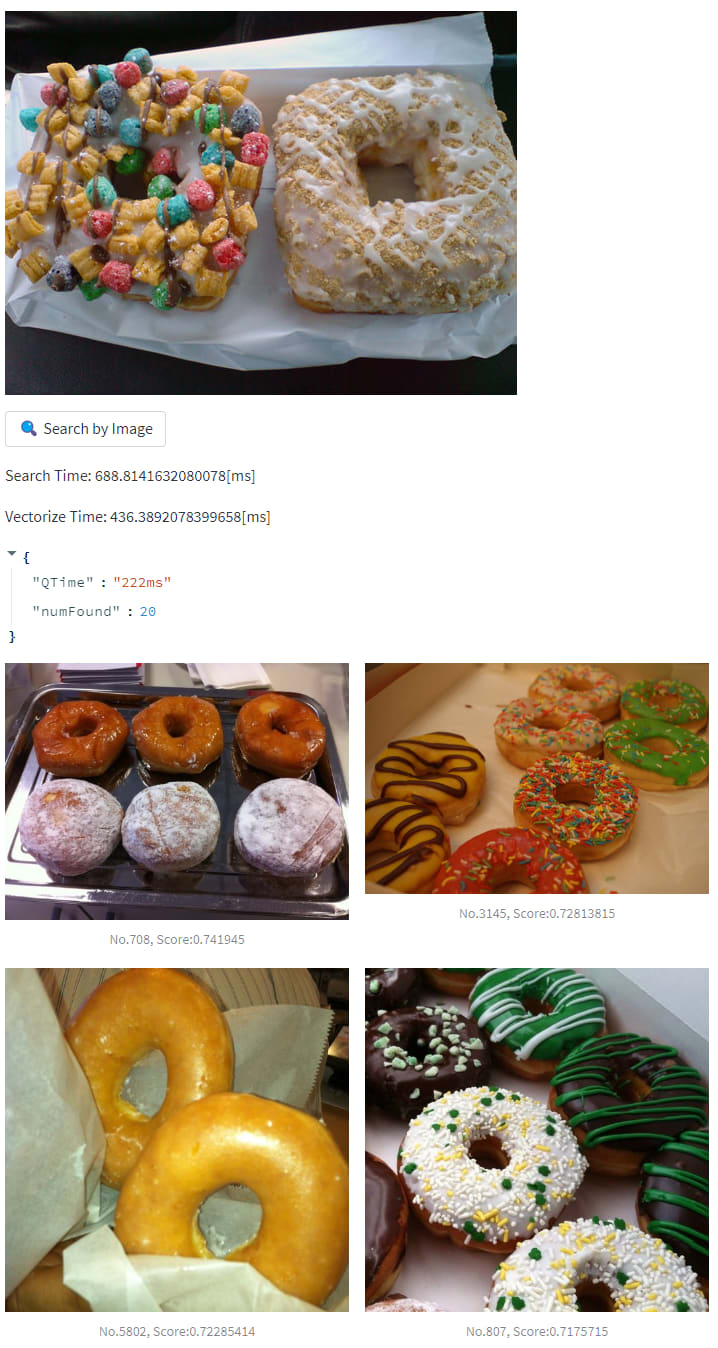
ex. 画像 to 画像検索
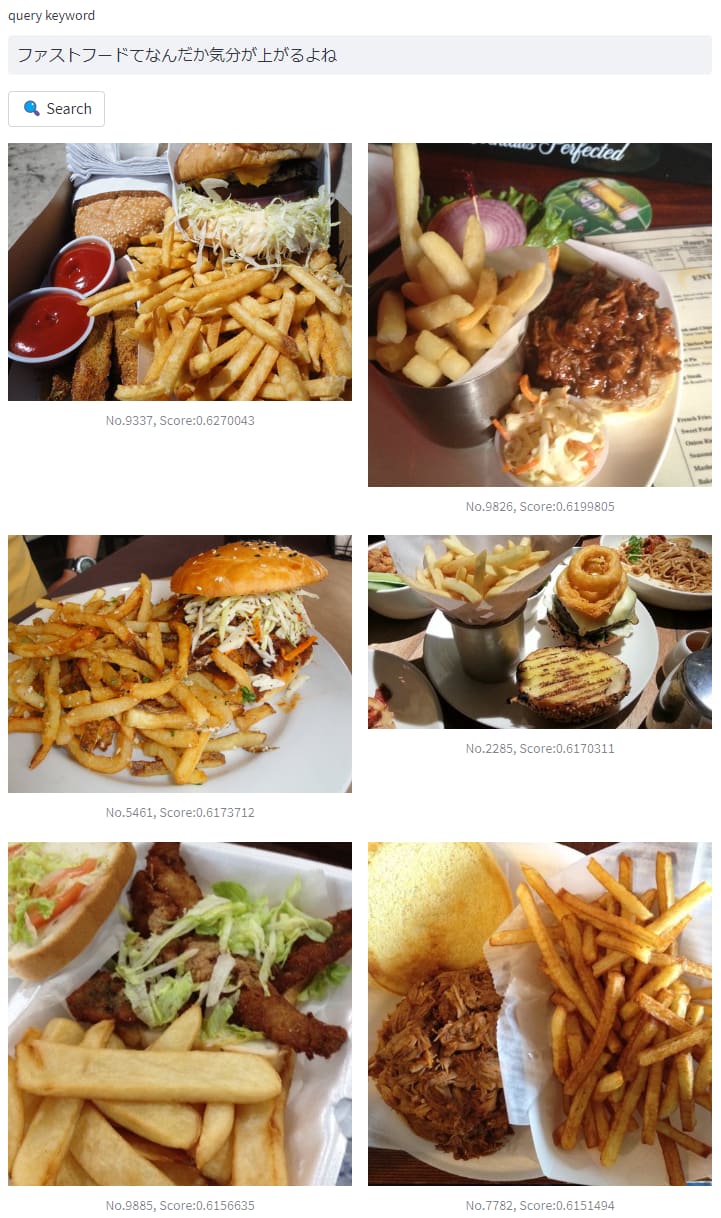
ex. テキスト to 画像検索
究極的にはベクトル情報にさえ変換されていればいいので、テキストだろうが、画像だろうが、音声、動画なんでも比較できます。
検索結果の良し悪しはあまり Solr 側では関与の余地はなく、事前にどれだけ良いベクトル変換(以下、embedding)モデルを作れるかにかかっています。
近年は ChatGPT の登場によって検索に破壊的な影響を及ぼしていますが、社内の独自データを含む自社のサイト内の検索エンジンが近々に ChatGPT に取って代わられるということはまだないでしょう。
ベクトル検索は自社サービスの検索体験をより良くするための1キラー技術になり得ると思います。
まずはベクトル検索を使ってみたいという方は、 Google Cloud パートナーである Groovenauts によって開発されたデモサイトやロンウィットの KandaSearch によるデモサイトを触ってみるとその威力が体感できると思います。
特に KandaSearch のデモサイトは裏では今回紹介する Solr によるベクトル検索が使われています。[1]
インデックス編
Solr 定義
使い方は思いのほか簡単です。
公式ドキュメントでしっかりとチュートリアルがあるので、それに従えば使えてしまいます。
まずは、スキーマ定義にベクトル検索用の型とフィールドを定義します。
<?xml version="1.0" encoding="UTF-8" ?>
<schema name="example" version="1.6">
<field name="_version_" type="plong" indexed="false" stored="false" />
<field name="_root_" type="int" indexed="true" stored="false" docValues="false" />
<uniqueKey>id</uniqueKey>
<field name="id" type="int" indexed="true" stored="true" required="true" />
<field name="vector" type="knn_vector" indexed="true" stored="false" /> <!-- フィールド定義 -->
<fieldType name="int" class="solr.TrieIntField" precisionStep="0" positionIncrementGap="0" />
<fieldType name="plong" class="solr.LongPointField" docValues="true" />
<fieldType name="knn_vector" class="solr.DenseVectorField" vectorDimension="4" similarityFunction="cosine" /> <!-- 型定義 -->
</schema>
vectorDimensionはインデックスするベクトルの次元数です。
現状指定できるのは最大1024次元までです。
similarityFunctionには類似度計算の方法を定義します。デフォルトはユークリッド距離になっていますが、公式の推奨はコサイン類似度です。
2023年2月25日現在、使用できる計算手法は以下の3つです。
DenseVectorField は indexed と stored が指定できます。Solr9.1 時点では multiValued はサポートされていません。
なので、複数のモデルで embedding したベクトルを持たせるといったことはできません。
基本的にはここまでを定義しておけばOKです。
より緻密にパフォーマンスチューニングをしたいときは、細かいパラメータを指定します。
高度な設定をしたいときは以下の行を solrconfig.xml に追加しておきます。
<config>
<codecFactory class="solr.SchemaCodecFactory"/>
...
その上で、スキーマ定義でパラメータを指定します。
<fieldType name="knn_vector" class="solr.DenseVectorField" vectorDimension="4" similarityFunction="cosine" knnAlgorithm="hnsw" hnswMaxConnections="10" hnswBeamWidth="40"/>
<field name="vector" type="knn_vector" indexed="true" stored="true"/>
knnAlgorithm="hnsw" は近似近傍探索のアルゴリズムです。
Elasticsearch/Solr のコアエンジンである Apache Lucene で採用されている近似近傍探索アルゴリズムは、執筆時点では、Hierarchical Navigable Small World(HNSW) のみです。
HNSW はグラフ探索型のアルゴリズムでベクトル距離に応じて事前にグラフを構築しておきます。
探索は高速だが、事前に構築したグラフの読み込みに時間がかかるという特性があります。
また、圧縮せずに生データをそのままメモリ上に展開して処理をするので、メモリの消費量が大きくなります。
2020年に Google が ScaNN というより高速で高精度・高効率なアルゴリズムを提唱しましたが、2018年時点では million-scale のドキュメントの近似近傍探索では決定版と言われていたアルゴリズムです。

画像は[Malkov+, Information Systems, 2013]から引用
HNSW は Python 製の近似近傍探索ライブラリである nmslib や faiss にも採用されています。
Solr 上でチューニングできるパラメータは以下の2つです。
いずれも HNSW でもっとも検索結果へのインパクトの大きいパラメータと言われています。
-
hnswMaxConnections: 隣接最大ノード数(default=16)- ある程度値を大きくすると recall が向上して検索時間も短縮されるがインデクス作成時間は長くなる
- 妥当なパラメータ範囲は5~100と言われている
-
hnswBeamWidth: 探索近傍ノード数(default=100)- 値を大きくすると、recall が大きくなり検索精度が向上するが、インデックス作成に時間は長くなる
- 妥当なパラメータ範囲は100~2000と言われている (nmslibのデフォルトは 200, faiss のデフォルトは 40)
基本的に値を大きくすると全探索に近づき、その分インデックス時間やメモリ使用量が増えるようです。
詳しくは以下参照ください。
- HNSWについて
- https://www.sciencedirect.com/science/article/abs/pii/S0306437913001300 [2]
- https://arxiv.org/abs/1603.09320 [3]
- https://yusukematsui.me/project/survey_pq/doc/ann_billion_2018.pdf [4]
- https://suzuzusu.hatenablog.com/entry/2020/12/14/020000 [5]
- https://towardsdatascience.com/ivfpq-hnsw-for-billion-scale-similarity-search-89ff2f89d90e [6]
- ScaNNについて
インデックスデータの作り方
DenseVectorField 型で定義したフィールドにリスト形式でベクトルを登録します。
ここでのベクトルの次元数は vectorDimension で指定したサイズに合わせておきます。
[
{
"id": "1",
"vector": [1.0, 2.5, 3.7, 4.1]
},
{
"id": "2",
"vector": [1.5, 5.5, 6.7, 65.1]
},
{
"id": "3",
"vector": [3.0, 11.0, 13.4, 130.2]
},
{
"id": "4",
"vector": [1.0, 2.1, 3.0, 4.0]
}
]
Solr9 から実質 Data Import Handler (DIH) は廃止になってしまったので、curl などを使って投入します。
どうしても DIH を使いたいという方は先日そんな記事を書きましたので参考にしてみてください。
検索編
基本的な使い方
検索時も簡単です。
ベクトルをインデックスさせたフィールドを指定してインデックス時と同じようにリスト形式でベクトルを渡してあげます。
http://localhost:8983/solr/mini/select?&q={!knn f=vector topK=10}[1.0, 2.0, 3.0, 4.0]&fl=id score
f がベクトル検索対象フィールドで、topK が上位何件を取得するかの指定になります。
topK のデフォルトは10件です。
上記の例だと [1.0, 2.0, 3.0, 4.0] に近い順にスコアが高くなり検索上位にヒットします。
スコアは similarityFunction で指定した類似度計算の方法を使って算出された値になります。
"response": {
"numFound": 4,
"start": 0,
"maxScore": 0.9999288,
"numFoundExact": true,
"docs": [
{
"id": 4,
"score": 0.9999288
},
{
"id": 1,
"score": 0.99773216
},
{
"id": 2,
"score": 0.90716124
},
{
"id": 3,
"score": 0.90716124
}
]
}
スコア計算を cosine にしたので、id:2 と角度が同じでノルムが2倍の id:3 のドキュメントは類似度が同じになっています。
ベーシックな q パラメータだけでなくフィルタークエリ fq や リランキングクエリ rqq にも使えます。
- フィルタークエリにベクトル検索を使用する
&q=id:(1 2 3)&fq={!knn f=vector topK=10}[1.0, 2.0, 3.0, 4.0]&fl=id score
- フィルタークエリと併用する
&q={!knn f=vector topK=10}[1.0, 2.0, 3.0, 4.0]&fq=id:(1 2 3)&fl=id score
- リランキングクエリにベクトル検索を使用する
&q=id:(3 4 9 2)&rq={!rerank reRankQuery=$rqq reRankDocs=4 reRankWeight=1}&rqq={!knn f=vector topK=10}[1.0, 2.0, 3.0, 4.0]&fl=id score
また、&q={!knn f=vector topK=10}[1.0, 2.0, 3.0, 4.0]&fq={!frange cache=false l=0.99}$q のよう cache や cost などのローカルパラメータを使えば、類似度スコアを絞り込み条件にすることもできます。
"response": {
"numFound": 2,
"start": 0,
"maxScore": 0.9999288,
"numFoundExact": true,
"docs": [
{
"id": 4,
"score": 0.9999288
},
{
"id": 1,
"score": 0.99773216
}
]
}
フィルタークエリでベクトル検索を使う場合の注意点
フィルタークエリでベクトル検索を使用した場合は、フィルタークエリで絞り込まれたうえで q パラメータによる検索がなされます。
また、スコア計算は q で指定したほうで行われます。
q で使うべきか fq で使うべきかはよく考えたうえで指定しましょう。
ex. フィルタークエリでベクトル検索を使用した場合
http://localhost:8983/solr/mini/select?&q=id:(1 2 3)&fq={!knn f=vector topK=2}[1.0, 2.0, 3.0, 4.0]&fl=id score
"response": {
"numFound": 1,
"start": 0,
"maxScore": 0.54726034,
"numFoundExact": true,
"docs": [
{
"id": 1,
"score": 0.54726034
}
]
}
類似度計算結果上位2件(id: 4, 1)に対してメインクエリ q で絞り込みを行う。
ex. クエリでベクトル検索を使用した場合
http://localhost:8983/solr/mini/select?&fq=id:(1 2 3)&q={!knn f=vector topK=2}[1.0, 2.0, 3.0, 4.0]&fl=id score
"response": {
"numFound": 2,
"start": 0,
"maxScore": 0.99773216,
"numFoundExact": true,
"docs": [
{
"id": 1,
"score": 0.99773216
},
{
"id": 3,
"score": 0.90716124
}
]
}
id: 1,2,3 に絞り込んだうえで類似度上位2件をヒットさせる。(id: 2,3は同値なのでどちらが選ばれるかはランダム?)
リランキングクエリで使う場合の注意点
リランキングクエリでベクトル検索を使用したときは、最終的なスコアはメインクエリ q と類似度スコア(に reRankWeight を掛けたもの) の合算で決まります。
ex. メインクエリをidにしたときのスコア
http://localhost:8983/solr/mini/select?&q=id:(1 2 3 4)&fl=id score
"response": {
"numFound": 4,
"start": 0,
"maxScore": 0.54726034,
"numFoundExact": true,
"docs": [
{
"id": 1,
"score": 0.54726034
},
{
"id": 2,
"score": 0.54726034
},
{
"id": 3,
"score": 0.54726034
},
{
"id": 4,
"score": 0.54726034
}
]
}
ex. メインクエリをベクトル検索にしたときのスコア(類似度)
http://localhost:8983/solr/mini/select?&q={!knn f=vector topK=10}[1.0, 2.0, 3.0, 4.0]&fl=id score
"response": {
"numFound": 4,
"start": 0,
"maxScore": 0.9999288,
"numFoundExact": true,
"docs": [
{
"id": 4,
"score": 0.9999288
},
{
"id": 1,
"score": 0.99773216
},
{
"id": 2,
"score": 0.90716124
},
{
"id": 3,
"score": 0.90716124
}
]
}
ex. リランキングスコア(=idでのスコア+類似度スコア)
http://localhost:8983/solr/mini/select?&q=id:(3 4 9 2)&rq={!rerank reRankQuery=$rqq reRankDocs=4 reRankWeight=1}&rqq={!knn f=vector topK=10}[1.0, 2.0, 3.0, 4.0]&fl=id score
"response": {
"numFound": 3,
"start": 0,
"maxScore": 0.54726034,
"numFoundExact": true,
"docs": [
{
"id": 4,
"score": 1.5471891
},
{
"id": 2,
"score": 1.4544215
},
{
"id": 3,
"score": 1.4544215
}
]
}
また、類似度スコアはメインクエリでの上位N件(reRankDocs で指定した数)のドキュメントにだけなされます。
http://localhost:8983/solr/mini/select?&q=id:(3 4 9 2)&rq={!rerank reRankQuery=$rqq reRankDocs=1 reRankWeight=1}&rqq={!knn f=vector topK=10}[1.0, 2.0, 3.0, 4.0]&fl=id score
"response": {
"numFound": 3,
"start": 0,
"maxScore": 0.54726034,
"numFoundExact": true,
"docs": [
{
"id": 2,
"score": 1.4544215
},
{
"id": 3,
"score": 0.54726034
},
{
"id": 4,
"score": 0.54726034
}
]
}
上記の例だと id:2 のドキュメントだけ類似度スコアが加算されています。
詳しくは ReRank Query Parser をご覧ください。
レスポンス性能
使用方法がわかったところで、実用に耐えうるか見てみます。
今回使用したマシンスペックは以下の通りです。
| CPU | Memory | JVM-memory |
|---|---|---|
| 6Core | 6GB | 2GB |
:::note warn
1台のマシンでフロントエンドも API も Solr も動かしているので、ネットワーク通信によるラグは少ないと思いますが、その分 CPU や Memory は共同なので各ミドルウェアがフルでリソースを使えているわけではありません。
:::
インデックスデータはオープンデータから17,000件ほど収集して embedding しました。
見ての通り、検索速度は数十ミリ秒ほどで結構早いです。
検索の際にはベクトルの次元数による検索速度には大きな違いはなさそうです。

200次元の場合

512次元の場合
どちらかというと、クエリのテキストや画像の embedding 時間の方がボトルネックになってきそうです。[7]
このあたりは軽量なモデルを使う、よりハイスペックなマシンや GPU を使うなど API 側の工夫次第です。
また、連続して同じクエリを投げるとおそらくキャッシュが効いてレスポンスが早くなりました。
1回目
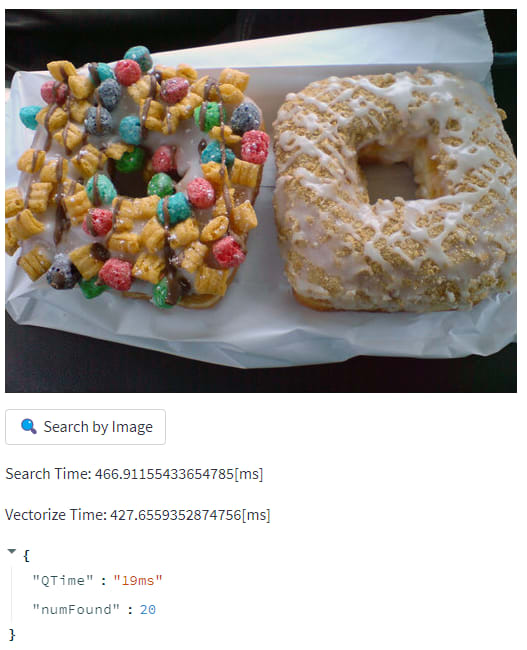
2回目
先ほどのテキストの例だと3,4回目だとほぼ0ミリ秒でレスポンスが得られるようになりました。

200次元の場合
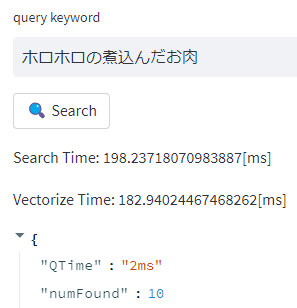
512次元の場合
embedding + 検索のトータルで数百ミリ秒なので、サービス要件がそこまできつくないサービスであれば十分組み込めそうです。
ただ、実際に Solr 運用者の方だと、数万件オーダーのドキュメントは少なすぎると思われたかもしれません。
確かに、Solr をサービスで導入している場合は、少なくとも100万件オーダー以上のドキュメントがインデックスされているケースが多いと思います。
そこで、100万件オーダーになってもこのレスポンス速度が保てるのかについても調べてみました。
インデックスデータには日本語 Wikipedia データを扱いやすくした CirrusSearch のダンプデータを使いました。
実際のデータは以下から取得できます。
ここから120万件ほどデータを集めてきてインデックスさせます。[8]
このインデックスに対して手作業で100パターンほどクエリを用意して負荷をかけてみます。
負荷試験ツールには Taurus を使用しています。
| ドキュメント数 | ベクトルの次元数 | Replica数 | Shard数 | 同時アクセス数 | QPS |
|---|---|---|---|---|---|
| 1,200,000 | 200 | 1 | 2 | 5vu | 20QPS |

平均レスポンスタイムは65msとドキュメント数が増えてもさほど影響はなさそうです。
さっきと同じ構成で、もう少し負荷を上げてみます。
| 同時アクセス数 | QPS |
|---|---|
| 5vu | 50QPS |

すると、同じマシン上で負荷試験ツールを動かしていることもあってか、そもそもマシンスペック的に30QPSが限界のようでした。
負荷が増えて、レスポンスタイムも3倍弱ほどに増えました。
さきほど画面から見る分に、キャッシュが効いていると早そうでした。
そこで、クエリを固定して同条件で負荷をかけてみます。

やはりキャッシュが効いているのか、ちゃんと50QPSが出ており、レスポンスもかなり高速になりました。
ただ、実際にはキーワードクエリに比べて、同じベクトルのリクエストが飛んでくることは稀なので、あまりキャッシュが効くことは期待できないと思われます。
最後に、同時アクセス数を上げてベースと比較してみます。
私の手元の環境だと、まともに捌けるのは30QPSほどのようですので、この値で計測することにします。
| 同時アクセス数 | QPS |
|---|---|
| 100vu | 30QPS |
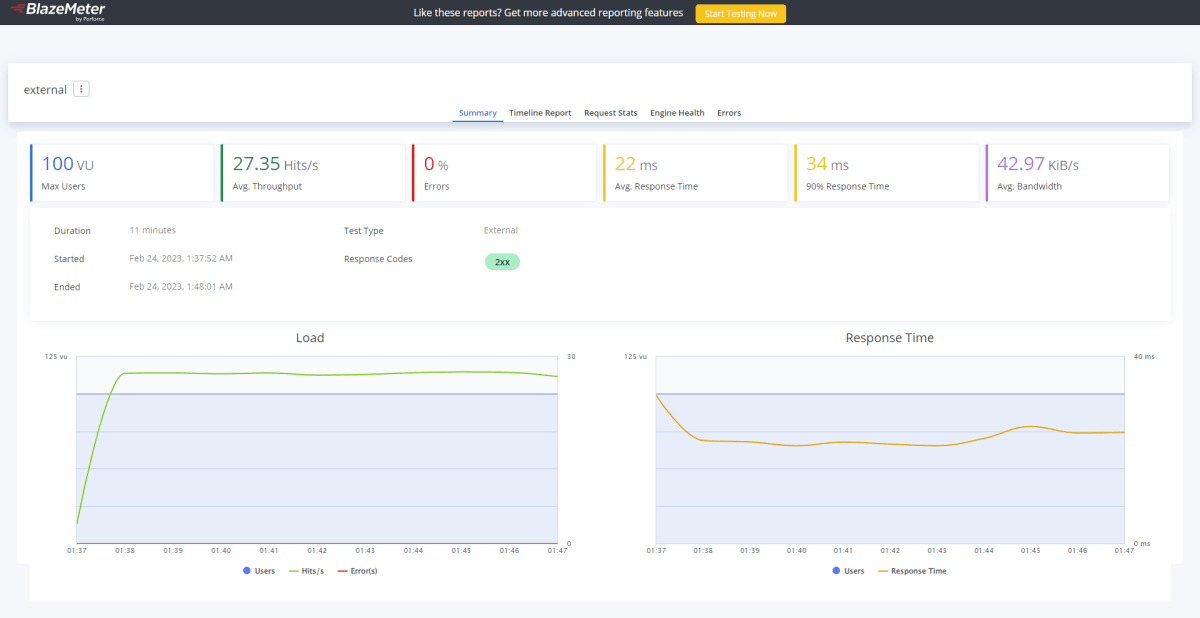
q=*:*のとき(ベース)

q={!knn ...}のとき
最初に大きな山があるので AVG が大きめに出ていますが、安定域のレスポンスタイムは120ms前後です。
やはり高負荷がかかるとどうしてもレスポンスタイムへの影響は出てくるようでした。
それでもまあまあ悪くない速度と言えるのではないでしょうか。
インデックスサイズ
インデックスサイズも測ってみました。
先ほどの Wikipedia のダンプデータ120万件に対して200次元で embedding したときのインデックスサイズは以下の通りになりました。
| ベクトルなし | ベクトルあり |
|---|---|
| 8.69G | 12.28GB |
ドキュメントのみに比べて1.5倍くらいになりました。
数値データだけとはいえ、数百次元のデータとなればそれなりのインデックスサイズになるようです。
おわりに
今回は Solr9 から導入された密ベクトル検索機能について調べてみました。
embedding さえできていれば、Solr 上での使い方は難しくなく、性能も悪くなさそうです。
Solr でのベクトル検索を使えば、全文検索エンジンのノウハウを生かしつつ、これまで全文検索では実現できなかったことができるようになります。
本記事を読んで興味を持っていただけたのなら、是非、一度検討してみては。
使用したデータセット
-
Groovenauts によるデモサイトではGCPのサービスの1つである Vertex AI Matching Engine が使われています。Vertex AI Matching Engine については、公式ドキュメントもわかりやすいですが、こちらのブログ記事が端的に良くまとまってています。https://www.topgate.co.jp/blog/google-service/20766 ↩︎
-
元論文その1 ↩︎
-
元論文その2 ↩︎
-
松井先生による解説。とってもわかりやすい ↩︎
-
Julia での実装例 ↩︎
-
Faiss での実装例を交えながら HNSW のアルゴリズム詳細を図説したブログ記事 ↩︎
-
200次元は Word2Vec を512次元は CLIP(rinna 社が日本語で pre-trained させたモデル https://huggingface.co/rinna/japanese-clip-vit-b-16 )を使っています。 ↩︎
-
ダンプデータ全体だと300万件ほどありましたが、私の手元のマシンスペック的にこれが限界でした。 ↩︎
Discussion