文系でもAIVTuberをやってみたい!
meboを使ってチャットbotを作成してみる
エージェントを作成する
適当に自己紹介文書いたらもうできた
これを読む
「トピック」
メインで話させたい話題のこと。例えばAIマイクラ実況者だったらマイクラの話題がここに入る感じ
「雑談表現」
本当に雑談。相槌とか。
「シナリオ」
一問一答のやりときが基本となるが、そうでない会話はシナリオでできる。
登録フローとか。
これらの会話の記録は「ログ」と呼ばれる。
これを確認すればどんな質問が来たかがわかる
会話で得られたユーザの状態に関する情報のことを、meboでは「ステート」と呼ぶらしい。
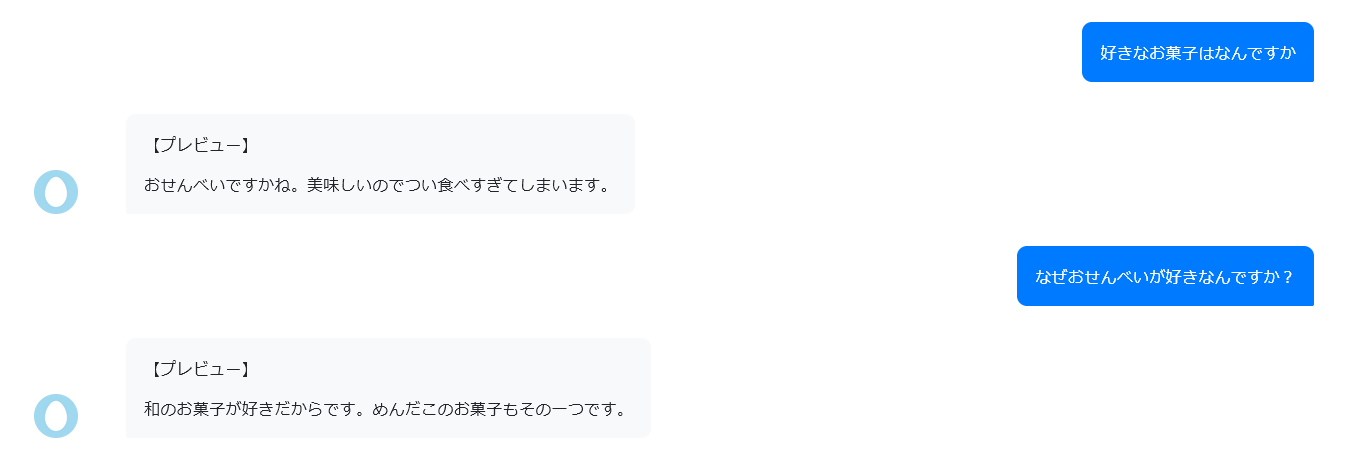
さっき書いた自己紹介文はAIによる自動応答の際に参考にするらしい。
じゃあトピックを追加してみよう
思ったけど、本番稼働しない限りはトークン消費しないの凄い優しい
やった感じ対話botに近いな、ただの会話だったらローカルでGPT回したほうが良いとかあるのだろうか
取り敢えずいくつか触ってみる
いくつか触ってノリはわかった
問題はどのような構築でいくかだと思う
構築案次第では最後まで言語モデルとか触らなくてよくなりそう
input→LLM→VOICEVOX→OBS→YouTube
になるはずだから、しばらくはVOICEVOX→OBSがどうやるかさえわかればなんとかなるのかっていうのと、長時間配信をどうすべきなのかを考えるのが先決かも
VOICEVOX→OBSはOBSのhtmlからjs読み込んでaudio.playすると再生できるっぽい
一旦整理する
input ->コメントから取得
LLM ->任意の何か
VOICEVOX ->LLMのoutputを受け取る
OBS->VOICEVOXの音声を受け取って再生する
ここで問題になるのが、どこで中央整備を行うか。
つまり、それぞれにデータを投げ、データを受け取る管制官的なポジションが必要になるはず。
具体的には以下
・Youtubeのコメントを取得してLLMに投げる
・LLMの結果を取得してVOICEVOXのAPIに投げる
・VOICEVOXの取得結果をもう一度VOICEVOXAPIに投げる
・返ってきた音声データを再生ストリームに流す
さらに単純化すると
・Youtubeのコメントを取得してLLMに投げる
・LLMの結果を取得して音声エンジンに投げる
・音声エンジンから返ってきた音声データを再生ストリームに流す
音声エンジンは大体pythonなので、pythonでYouTubeAPIやLLM、音声エンジン、再生ストリームまでのフローができれば起動するものが最低限で良く、かつローカルでできる限り完結する可能性がある
多分AIでVTuberをするということは、pythonでVOICEVOXエンジンを動かして、音声ストリームに流す行為のこととも言い換えることができそう
取り敢えずサウンドをストリームに流すことはできた
import sounddevice as sd
import soundfile as sf
import sounddevice as sd
input_device = 0
output_device = 10
sd.default.device = [input_device,output_device]
def play_sound(filepath):
sig, sr = sf.read(filepath, always_2d=True)
sd.play(sig,sr)
sd.wait() # sd.playが完了するのを待つ
play_sound("sample.wav")
sd.default.reset()
TODOとしては
・VOICEVOX APIをcurlして取得して流す
・YouTubeAPIと繋げる
・LLMと繋げて帰ってきたstringを取得する
参考になりそう。ファインチューニング
これを導入してみる
これでテストしてみることに
from transformers import pipeline
nlp = pipeline("question-answering",model="nlp-waseda/roberta-base-japanese-with-auto-jumanpp")
print(nlp("こんにちは!あなたの好きなお菓子はなんですか?"))
jumanはインストール面倒そうだったので、ひとまずjuman不要のもので試してみることに
from transformers import AutoTokenizer, AutoModelForQuestionAnswering
tokenizer = AutoTokenizer.from_pretrained("ku-nlp/roberta-base-japanese-char-wwm")
model = AutoModelForQuestionAnswering.from_pretrained("ku-nlp/roberta-base-japanese-char-wwm")
sentence = 'こんにちは!あなたの好きなお菓子はなんですか?'
input = tokenizer.encode(sentence, return_tensors='pt')
output = model.generate(input, do_sample=True, max_length=30, num_return_sequences=3)
print(tokenizer.batch_decode(output))
こんな感じでやりたい(イメージ)
こんな感じで、必要なモデルに合わせてTokenizerだったりConfigだったり違うみたい
from transformers import AutoConfig, AutoModelForQuestionAnswering
# Download configuration from huggingface.co and cache.
config = AutoConfig.from_pretrained("bert-base-cased")
model = AutoModelForQuestionAnswering.from_config(config)
取り敢えずこれで動いた
import torch
from transformers import T5Tokenizer, AutoModelForCausalLM
class llm_adapter:
def __init__(self,tokenizer_name,model_name) -> None:
self.tokenizer = T5Tokenizer.from_pretrained(tokenizer_name)
self.tokenizer.do_lower_case = True # due to some bug of tokenizer config loading
self.model = AutoModelForCausalLM.from_pretrained(model_name)
if torch.cuda.is_available():
self.model = self.model.to("cuda")
def encode(self,sentence):
inputs = self.tokenizer.encode(sentence,return_tensors='pt')
with torch.no_grad():
output_ids = self.model.generate(
inputs.to(self.model.device),
max_length=100,
min_length=20,
do_sample=True,
top_k=500,
top_p=0.95,
pad_token_id=self.tokenizer.pad_token_id,
bos_token_id=self.tokenizer.bos_token_id,
eos_token_id=self.tokenizer.eos_token_id
# bad_word_ids=[[tokenizer.unk_token_id]]
)
output = self.tokenizer.decode(output_ids.tolist()[0])
return output
ここからは、きちんと出力されるようにファインチューニングを行う必要がある
まずはきちんと与えられた発言に対して発言を返すことを目標とする
API叩く方式にすればよかったかな?
金があればOpenAIのAPI叩いて出力した方が開発効率を考えると良いかも
ファインチューニングはこれでできる
本番は他のデータセットを用いるとして、とりあえずこのサイトのまま作ってみよう
pip install sklearnがうまく行かない事象が発生してる
pip install scikit-learnで通った
これを使ったら普通にファインチューニングを行うことができた
outputの文体も問題ない
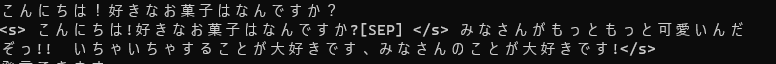
pythonのinputでプロセスがすぐ死ぬ
コピペでなんとかなった!
取り敢えずきちんと出力すること自体はできたので、一旦できたとして他部分の制作をやろうかな
モデル部分はmockにして、他部分を全部うまくできるように
mockを作った
以下の記事を参考に、APIからwavを引っ張ってくることに成功
def post_request_MQ(url):
query = 'audio_query'
response = requests.post(url+query,params=item_data)
return response.json()
def post_requestMA(url,data,speaker_id,core_version):
query = 'synthesis'
a_params = {
'speaker' :speaker_id,
'core_version':core_version,
'enable_interrogative_upspeak' : 'true'
}
return requests.post(url+query,params = a_params,data= json.dumps(data))
url = 'http://localhost:50031/'
speaker_id = 0
core_version ="0.0.0"
item_data={
'text':'これはテストです',
'speaker':speaker_id,
'core_version':core_version
}
MQ_data = post_request_MQ(url)
MA_data = post_requestMA(url,MQ_data,speaker_id,core_version)
問題はこのwavの再生で、bufferになっているのでbufferのまま再生させるということが可能なのか?という部分なんだよな
いや、違うわ
API通すのでbytes型になってる
だから仮決めだけどbytes->bufferとかにしないと扱いづらい可能性が高い
できたかも
from scipy.io.wavfile import read
import io
rate, data = read(io.BytesIO(MA_data.content))
sd.play(data,44100)
sd.wait() # sd.playが完了するのを待つ
参照はこれ
SciPy.io.wavfileのread関数の引数にbytesを使え、戻り値がnumpy arrayだからだ
LLMが返答する「talker」、返答内容を人口音声ファイルに変える「voicevoxAdapter(名前はいつか帰る)」、音声ファイルを任意のデバイスに投げる「PlaySound」の三つのモジュールからなる、入力内容に対してAIが人工音声で返答してくれるシステムの構築が完成した
TODO(優先度順)
ファインチューニングを行う
YouTubeコメントを取得する
回答をOBSで表示させる
ファインチューニングに関してはつくよみちゃんのやつを使って質問・応答のチューニングを行う予定
つくよみちゃんのやつは自分用discordサーバーにリンクがある(備忘録)
つくよみちゃんで学習してみたものの、あまりって感じだな
学習方法が悪いのか、それとも学習データが少ないことが問題なのかの切り分けができない
取り敢えずきちんとすぐファインチューニングできるように、今回はCUDA環境で学習を回せることを目標とする
雑にこれでいけるか試すかpip install --upgrade --no-deps --force-reinstall torch>=1.3 --extra-index-url https://download.pytorch.org/whl/cu117
これでいけるようになったけど、block_sizeが適切かわからない
py run_clm.py --model_name_or_path=rinna/japanese-gpt2-medium --train_file=train.txt --validation_file=train.txt --do_train --do_eval --num_train_epochs=3 --save_steps=5000 --save_total_limit=3 --per_device_train_batch_size=1 --per_device_eval_batch_size=2 --output_dir=output2/ --block_size 512
ベースのモデルも色々ある
rinnaはgpt-2だね
これ気になる
Tokenizerは、使用する学習済みモデルごとに作成されたものが存在するため、モデル学習時に使用されたTokenizerと同じものを使う必要があります。
AutoTokenizerクラスのfrom_pretrainedメソッドを使用することで、指定したモデルのTokenizerを使うことができます。
興味があっちこっち行ってpipelineも試してたのだが、日本語のpipelineが少なすぎるので厳しそう
まあできなくはない(翻訳噛ませて返答も翻訳させるとか)けど今ではないかな
一応備忘録
nlp = pipeline("conversational")
while(True):
print("入力できます")
input_str = input()
input_conv = Conversation(input_str)
response_text = nlp(input_conv)
print(response_text)
あとはモデルによって読み込ませ方とかが違うのかなぁ
あんまりタスクの種類をどうやってやるべきなのかわからない
プロンプトとしてきちんと前例を読み込ませるという基本のキができてなかった
<s>こんにちは、君は誰?[SEP]私は花子!女子高校生で甘いものが好きなんだ~</s>
次はYouTubeAPI連携
GCPでプロジェクト立ち上げてYouTube Data APIを有効化、APIKeyを発行して.envファイルに書き込む
これを見ながら実装
ライブラリ合った
これで繋げることができた
comments = json.loads(self.chat.get().json())
if(comments ==[]):
print("コメントがありません")
return None
latest_comment = comments[-1].get("message")
return latest_comment
メモとして、これで一覧で引っ張ってくれば順番に引っ張ってくるとかできるんだよな
世界観を決めておこう
自分はLive2Dじゃなくてpuppet使おうかな
TODO
diffusionでpng作成
animation gif作成
puppet連携
スタデ、前見た時とまた情勢が変わってきてる
これ使う
i2iで口を開けてるのを作ってアニメーションgifにする?
まともな対話になってないので、ちょっとまずいかな

BART日本語Pretrainedモデルを用いる予定
以下を参照
JUMAN
KNP
問題はJUMAN++じゃないことなんだよな
面倒だがdocker化してLinuxで動かすか?
pyknpに手を入れるのはあまりやりたくないので、docker作るか
dockerで環境はできた

pythonの欲しいライブラリが入らない
早稲田BERTを使う前に、他のBERTを用いたチャットボット実装を試しにやってみる
できた。

BERT、質問に対する回答はずばっとしてて良いんだけど、多分回答に必要なデータセットにないものは残念ながら何も生成できないんだよな
GPT系のやつにした
多分使い方が悪かっただけっぽい
問題はスペシャルトークンなどの扱いかな
parse方法をきちんと修正してあげたら無事会話できるようになった。
TODOはファインチューニングを行うことくらいかな
ファインチューニング用の対話一問一答データはChatGPTで生成する予定
10代女子のゲーマーをキャラクターとした対話AIを作っています。ファインチューニングを行うため、質問とそれに対する回答を10組作ってほしいです。テーマは雑談で、お互いタメ口で会話をしている設定です。一問一答形式でお願いします。
Q: お元気?
A: お元気です!あなたはお元気ですか?
Q: 今日の天気は?
A: 今日の天気は晴れです!素敵な一日になりますね。
Q: 好きなゲームは?
A: 私はFPSゲームが好きです!あなたは何が好きですか?
Q: 最近買ったゲームは?
A: 最近買ったゲームは「Cyberpunk 2077」です!面白いですか?
Q: 好きな音楽ジャンルは?
A: 私はロックやヒップホップが好きです!あなたは何が好きですか?
Q: 今週の予定は?
A: 今週の予定はゲームと友達との会話です!あなたは何をする予定ですか?
Q: 好きな映画は?
A: 私はアクションやSF映画が好きです!あなたは何が好きですか?
Q: 好きな食べ物は?
A: 私は寿司やパスタが好きです!あなたは何が好きですか?
Q: 好きなスポーツは?
A: 私はバスケットボールが好きです!あなたは何が好きですか?
Q: 今日のお気に入りのゲームは?
A: 今日のお気に入りのゲームは「Overwatch」です!あなたは何が今日のお気に入りですか?
Github Copilotを導入。
TestpilotはまだPythonには使えないが、Copilotによる型宣言の追加等を現行コードに全て適用した
TODO:
OBSに文字を表示させること
OBSの画面構築
ランダムな話題について話せるようになること
OBSはwebsocket使う
pipでsimpleobswsを入れた
これを参考に作る
取り敢えず該当するオブジェクトのテキストを変えるのをやろうお
async functionで返ってくるコルーチンをrun_until_completeでwrapしてあげるとかいう暴力的な解決方法を用いてるが問題ないのか?
def get_scene_item_list(self):
loop = asyncio.get_event_loop()
req = simpleobsws.Request("GetSceneItemList",{ "sceneName": sceneName })
res = loop.run_until_complete(self.ws.call(req))
return res
OBS websocketv5系はここに載ってる
websocket v5系の記述がないのでv4にすべきか悩むな
loop = asyncio.get_event_loop()
req = simpleobsws.Request("SetInputSettings",{ "inputName": "test_text","inputSettings":{"text":"MY NEW TEXT" }})
res = loop.run_until_complete(self.ws.call(req))
これでいけた、SetInputSettingsにあったのね
負荷テストを行った感じでは、雑談枠は多分問題なくできる
ただゲーム実況は今のところ難しそうだよね
このテスト配信を持ってこのスクラップはクローズします。
このスクラップでできるようになったことは以下
- コメントから質問文を抽出し回答、回答内容をOBSに反映し合成音声に変換しOBSに出力