【ローカルAI】GUIでCodeLlama-34B-Instruct-GGUFを動かしてみる【text-generation-webui】
概要
ローカルLLMで最近話題の「CodeLlama-34B-Instruct-GGUF」をtext-generation-webuiから動かし、「ローカルLLMでもファインチューニングなしでプロンプト指示できる」感覚を体験してみる。
メイン読者ターゲット
ご家庭にGPUがある人(CPUでも良いが遅い)
最適化だったり正しい理解ができてるかは別として、とりあえず動かしたい人
導入から書くので、推論スピードだけ確認したい人は下まですっ飛ばしてください。
導入
text-generation-webuiの導入
以下からclone
自分はpyenv+venv派なので
python -m venv .venv
でactivate。
あとは基本的にinstallationに従えば良い。
数少ないポイントとして、使ってるGPUやOSによってtorchが変わること、昔のGPUだとbitsandbytesで詰まる可能性があるので、きちんとinstallationをチェックしておくことの2つは抑えておくと良い。
モデルのDL
これを直接落とし、text-generation-webuiのmodelsディレクトリにggufファイルを入れる
起動
python server.py で起動できる

Modelを選択肢、左上のドロップダウンにcodellama-34b...と書いてあるので選択。
パラメータは下記記事に詳しく乗っているが、よくわからなければ「n-gpu-layersをVRAMの余裕ギリギリになるまで上げる」だけ覚えておけばなんとかなる。上げれば上げるほど速くなる。
3090だと51まで攻めれる。これは他の起動ソフトによっても変わるので注意。
low-vramはチェックすると速度を犠牲にしてVRAMを節約できるらしい。
n-g-lを3まで減らすとVRAM6GBのGPUでも動くようになる(スピードは遅いが)
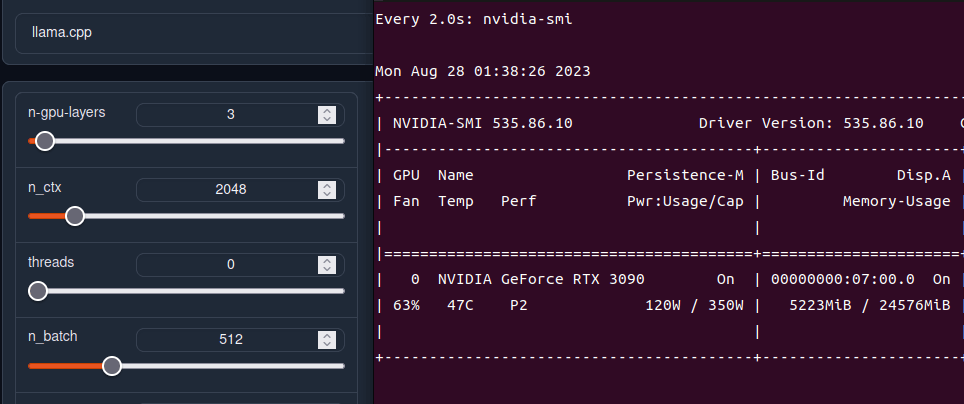
色々設定し終わったらloadボタンを押し、ロードが完了したらParameterに行く。
パラメータ調整
とりあえず最初はmax_new_tokensとtemperatureだけ覚えておけば良い。max_new_tokensは出力できる文字数、temperatureは高いほどランダム性が高まり、0だと必ず同じ出力になる(はず)
文章生成
良い感じにプロンプトを組む。プロンプトはモデルごとに最適解が違ったりするので注意すること。心配であれば、モデル配布ページを確認すると大抵書いてある。今回の場合は以下のようなプロンプトになる。
[INST] Write code to solve the following coding problem that obeys the constraints and passes the example test cases. Please wrap your code answer using ```:
{prompt}
[/INST]
コード生成でも良かったが、趣味なので今回はキャラクターを召喚することにした。右側に結果が表示される。

推論時間がterminalに書かれるので、生成スピードを計算したい場合は確認する。
今回の場合は以下。
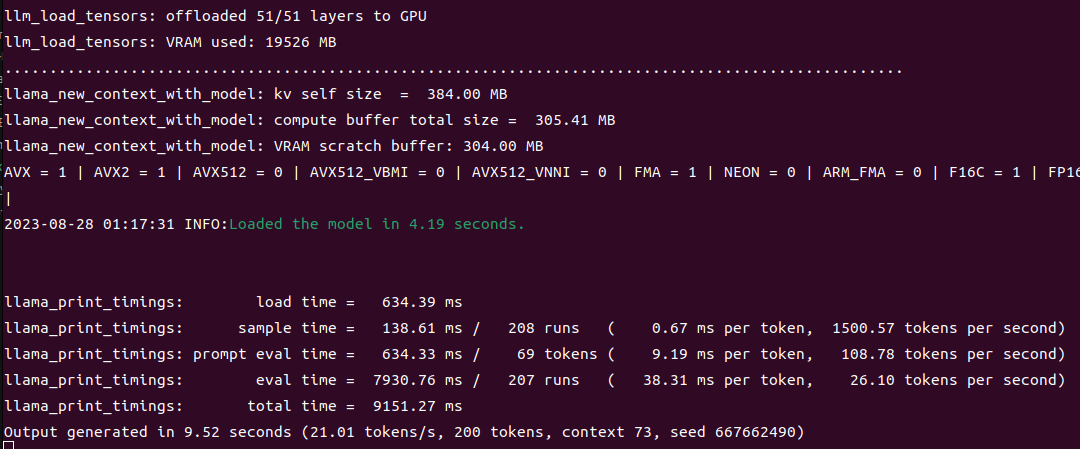
llama_print_timings: load time = 634.39 ms
llama_print_timings: sample time = 138.61 ms / 208 runs ( 0.67 ms per token, 1500.57 tokens per second)
llama_print_timings: prompt eval time = 634.33 ms / 69 tokens ( 9.19 ms per token, 108.78 tokens per second)
llama_print_timings: eval time = 7930.76 ms / 207 runs ( 38.31 ms per token, 26.10 tokens per second)
llama_print_timings: total time = 9151.27 ms
Output generated in 9.52 seconds (21.01 tokens/s, 200 tokens, context 73, seed 667662490)
eval timeというのが生成時間。26 token /sなので、ざっと秒速26単語であることがわかる。
課題点
日本語をそのまま出そうとすると、llama-cpp-pythonの仕様で漢字が抜け落ちるらしい。
GUIでなくて良いならllama.cppのサーバ機能使うのが順当そうで、どうしてもGUIでやるならGPTQ版を試してみても良いかも。
Discussion