論文の分類をするモデルを作ろうとしてみる〜教師データ作成編〜
こんにちは!逆瀬川 ( https://twitter.com/gyakuse ) です。
今日はGPT-3.5を使って論文を自動分類するモデルのための教師データを作ってみました。
これから文章分類とかやってみたいな〜って人の参考になれば嬉しいです。
まだまだ勉強中なので、おかしなところとかあるかもしれませんが、もしそういうところあったらぜひ指摘してください!
前段
arXivに投稿されるCS論文は多い月で8000本程度あります。これを全部チェックしようとするとものすごく時間がかかってしまいます。そのため、自動的にAbstractを要約して、Discordの各カテゴリ速報チャンネルに投稿しようと思いました。
全体構成としては、以下のような構造になっていると論文読みが捗りそうです(なお、オープンで無償のサービスであっても、論文のライセンスに気をつける必要があります)。

自動要約・自動翻訳の仕組みはすでにあるので、自動分類ができれば裏側の仕組みは完成です。
では、どう自動分類するかですが、一旦は自分のためのサービスなので、自分の興味に沿ったカテゴリ分けをしてくれると嬉しいです。今回は、以下のようなカテゴリに分けることにしました。
- 文章生成
- 音声認識
- 音声合成
- 音楽生成
- 画像生成
- 画像認識
- 物体検知
- 動画生成
- 動画分析
- 時系列解析
- NeRF
- その他
手法の検討
まずこの問題を定式化します。これは自明的に文章のクラス分類タスクといえます。そのような場合に検討するべきは、以下の3点になります。
- 分類モデルをどのようなモデルにするか
- 入力データはどのようなものか
- 教師データをどのように用意するか
なお、今回はDeep Learning手法の勉強でもあるので、既存のモデルをそのまま使うことは避けます。
分類モデルについて
文章のクラス分類を行う手法としては以下が考えられます。
- ナイーブベイズを用いるもの
- SVMを用いるもの
- 単純な全結合層を用いるもの
- 文章の長さが可変であることが考えられるので、うまく任意の次元数のベクトルに変換する工夫が必要です
- LSTMを用いるもの
- BERTを用いるもの
- BERTとTransformerについては事前学習モデルからのfine-tuningを考えます
- Transformerを用いるもの
今回は勉強も兼ねて、単純な全結合層を用いるもの、BERTのfine-tuning、T5のfine-tuningについてそれぞれ実装し、比較してみたいと思います。
モデルに入力されるデータについて
論文データはarXivから取得するのですが、PDFの中身まで確認するとコストが高くなってしまいます。論文のメタデータは、https://arxiv.org/help/api を使うと容易に取得することができ、これにはタイトル、著者、サマリ、カテゴリ(cs.AIなど)、URLなどが含まれます。
今回はそれほど多い教師データは用意できないので、著者情報は採用せず、また、シンプルなモデルとしたいので、タイトルおよびサマリを入力データとします。
教師データについて
今回は教師データを1,000件用意することを目標とします。本当であれば、数万オーダのデータを用意できればいいのですが、時間制限もあるので、一旦この程度にしてみます。
教師データの作り方としては、手動、amazon mechanical turkなどでの外部人員への依頼などがありますが、今回はGPT-3.5を用いてソフトラベルを生成し、それを学習させるという一種の蒸留(Distillation)手法を用いようと思います。GPT-3を用いたデータ拡張(data augumentation)には以下のような先行研究があります。
また、この教師データは全データ1,000件を学習用データ800件、検証用データ100件、テストデータ100件に分割します。
教師データを作る
arXivから論文データをダウンロードする
arxiv.pyを用いると、簡単に論文データをダウンロードすることができます。
# cs論文最新1,000件を取得
import arxiv
search = arxiv.Search(
query = "cat:cs.*",
max_results = 1000,
sort_by = arxiv.SortCriterion.SubmittedDate
)
取得したデータをSpreadSheetに上げる
SpreadSheetへの書き込み/読み込みはgspreadが容易です。なお、credentialsなどのダウンロードについては以下の記事を参考にしてください。
まず以下のようにauthorizeします。
import gspread
from oauth2client.service_account import ServiceAccountCredentials
scope = ['https://spreadsheets.google.com/feeds','https://www.googleapis.com/auth/drive']
credentials = ServiceAccountCredentials.from_json_keyfile_name(json_file_name, scope)
gc = gspread.authorize(credentials)
sp = gc.open_by_key(spreadsheet_id)
次に、書き込みのための情報をlistにまとめます。
items = []
for paper in search.results():
items.append([paper.title, paper.summary, paper.pdf_url])
最後に values_update 関数でバルクインサートします。
sp.values_update(
f'{sheet_name}!A1',
params={'valueInputOption': 'RAW'},
body={'values': items}
)
バルクインサートするのは、1件ずつインサートするとAPIエラーとなるためです。
バルクインサートの最大値セル数は検索してもすぐに出てこなかったため、よくわかりませんが、とりあえず動きました。
GPT-3.5で教師データを作る
ここが今回のキモです。教師データを作るために以下のようなプロンプトを用意しました。
def create_prompt(title, abstract):
return f"""
Given title and abstract of an arXiv paper, classify it into one of the following categories and output the probabilities:
Text generation
Speech recognition
Speech synthesis
Music generation
Image generation
Image recognition
Object detection
Video generation
Video analysis
Time series analysis
NeRF
Others
Title: Full-Scale Continuous Synthetic Sonar Data Generation with Markov Conditional Generative Adversarial Networks
Abstract: We propose a novel method for generating realistic and diverse images of human faces from sketches. Our method consists of two stages: sketch refinement and image synthesis. In the sketch refinement stage, we use a convolutional neural network to transform a rough sketch into a refined sketch that preserves the user’s intention and conforms to the facial anatomy. In the image synthesis stage, we use a generative adversarial network to produce photorealistic images from the refined sketches. We also introduce a new dataset of paired sketches and images of human faces, which we use to train and evaluate our method. We demonstrate that our method can generate high-quality and diverse images of faces from sketches, and outperforms existing methods in terms of both visual quality and user preference.
Category: Image generation (0.82), Image recognition (0.12), Others (0.06)
Title: {title}
Abstract: {abstract}
Category:
"""
典型的なfew-shotプロンプトとなります。{タスクの説明}-{タスク例}-{今回のタスクの入力}という系列になっています。論文3つくらい動かした所、いい感じだったのでこれを1,000件全部に当ててみます。プロンプトの入力と出力がだいたい500tokenであるため、0.02ドル/1k token(OpenAI::GPT::text-davinci-003)をかけると、およそ10ドルかかることがわかります。実際、この処理のあとにdashboardを確認したところ、11.2ドルかかっていました。
この処理は40分かかりました。
結果は以下のように、なんかうまくいってる感じです!

ここまでの処理をまとめたのが以下のcolabです。
生成された教師データの確認
データをパースし、実際に変な偏りができていないか確認してみます。
まず、Video generation (0.80), Video analysis (0.15), Others (0.05) のように出力された形式から以下のようなソフトラベル表現を作ります。
{'text generation': 0.0,
'speech recognition': 0.0,
'speech synthesis': 0.0,
'music generation': 0.0,
'image generation': 0.0,
'image recognition': 0.0,
'object detection': 0.0,
'video generation': 0.8,
'video analysis': 0.15,
'time series analysis': 0.0,
'nerf': 0.0,
'others': 0.05}
これを以下の関数で実施します。
def normalize_genre_probabilities(text):
temp_genres = {}
try:
for item in text.split(","):
genre, prob = item.strip().rsplit(maxsplit=1)
prob = float(prob.strip("()"))
temp_genres[genre.lower()] = prob # ジャンルの名前を小文字に変換する
except:
temp_genres['others'] = 1.0
# 以下のジャンルのリストを作る
genres_list = ["Text generation", "Speech recognition", "Speech synthesis", "Music generation", "Image generation", "Image recognition", "Object detection", "Video generation", "Video analysis", "Time series analysis", "NeRF", "Others"]
genres_list = [genre.lower() for genre in genres_list] # ジャンルのリストも小文字に変換する
genres = {}
for genre in genres_list:
if genre in temp_genres.keys():
genres[genre] = temp_genres[genre]
else:
genres[genre] = 0 # 確率が0であるジャンルも辞書に追加する
# 合計が1になるように確率を調整する
total = sum(genres.values())
for genre in genres:
genres[genre] /= total
genres[genre] = round(genres[genre], 2)
# 補正項
if sum(genres.values()) != 1:
genres["others"] += round(1 - sum(genres.values()), 2)
return genres
pandasでDataFrameに変換してmeanを求めると、以下のようになります。
おや…?

matplotlibでグラフ化します。
import matplotlib.pyplot as plt # matplotlibをインポート
mean.plot(kind='bar') # 平均割合を棒グラフとしてプロット
plt.show()
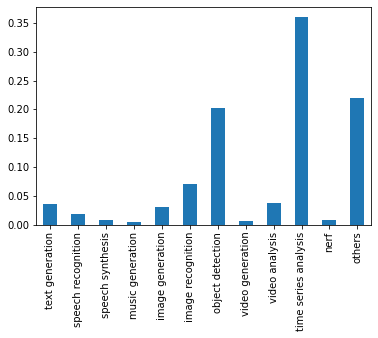
………
time series analysisがやたら多いです。
データセットを見ると、どうやら誤ったラベル付けになっているもよう。

ラベル付けに失敗した逆瀬川!いったいどうなってしまうのかーー!
後編に続く
Discussion