自然言語処理におけるデータ拡張手法
はじめに
こんにちは。今回は、次の論文についての記事です。
https://arxiv.org/abs/2110.01852
※本記事にある画像は、当論文より引用しています。
前置き
データ
基本的にこの記事では、「データ」は何らかのテキストを指します。
データ拡張とは
データ拡張は英語で、data augmentationと言います。これはDAと略される場合があります。データ拡張は、既存のデータセットを用いてデータをさらに増やすことです。
主に、より精度の高いモデルを学習する目的で用いられ、データ拡張により多くの学習用データを蓄えます。元からあるデータが少ない場合や、特に特定のラベル(カテゴリ)のデータが少ない場合などには、重宝すると思います。
また、作成されたデータの用途にも、次のようにいろいろと考えられます。
- モデルの事前学習を行う
- 特定のタスク向けにデータを学習する
- 事前学習済みのモデルをfine-tuningする
データ拡張の応用先
前置きはここまでとして、この章以降が本題です。
まずこの章では、当論文が紹介しているデータ拡張手法を用いることで、何ができるのかを記載します。
一番は文書分類
意外と言うべきか分かりませんが、当論文を読み解くと、データ拡張の一番の応用先は文書分類です。文書分類と言えば、自然言語処理の中で最も有名で、基本的な部類のタスクですね。新規テキストに対して、あらかじめ定義されたラベル一覧の中から適切なラベルを選ぶ、昔からよくあるタスクです。
最近は多種多様なタスクが話題になっていると感じているので、かえって盲点でした。
文書分類タスクがデータ拡張の一番の応用先になっていることの背景は、このタスクのシンプルさにあります。このタスクの構造上、学習データの増加はダイレクトに、そのラベルについての意味的な理解の増強につながります。
その他のタスクへの応用
当論文では、文書分類の他に大きく2つの応用先が述べられています。
1つはテキスト生成です。その代表例は、機械翻訳です。
もう1つはstructured predictionというものです。日本語で言うと、構造推定、構造学習でしょうか。このタスクについては、SanSan社の配信記事を参考にさせていただきました。
応用先についての所感
ということで、データ拡張を多くのタスクに有効活用するのは、思ったより難しそうだと感じました。もちろん、効果を出せないわけではないと思います。ですが、目指しているタスクに対して、「どうやってデータ拡張をすればどのくらいの効果が得られそうか」の事前調査が重要になりそうです。そうしないと、「せっかくデータ拡張をしたのにあまり意味がなかった」となってしまう可能性が高くなると思います。
今までデータ拡張についての知見は特になかったので、勉強になりました。これは1つ、戒めておいたほうが良さそうです。
データ拡張の手法
前章までで、応用先を確認しました。ここからは、データ拡張の具体的な手法について説明します。
手法の3タイプ
当論文は、データ拡張を大きく次の3タイプに分けています。
| 手法のタイプ | 概要 |
|---|---|
| paraphrasing | ある1データの意味とできるだけ同じになるように、新たなデータを作成する。 |
| noising | ある1データにノイズをかける形で、新たなデータを作成する。 |
| sampling | 複数のデータを利用し、まったく新規のデータを1から作成する。 |
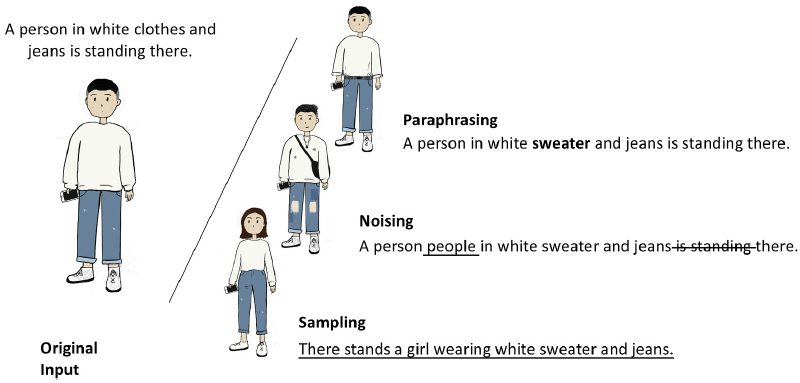
これら3タイプの例が、冒頭にも添付した画像です。
少しの例外はありますが、各タイプの手法は次のようになります。
この例だと、paraphrasing(言い換え)では、clothingをsweaterに変えただけです。ですので、意味はほとんど同じです。元のデータを少し言い換えた程度です。
noisingでは、たとえば単語の追加、置き換え、削除をします。そのため、paraphrasingに比べると、作成されるデータの意味が少なからず変化します。また、上の例のように、「a person people」のような文法的に正しくない表現も起こりえます。
samplingでは、全面的に1からデータを作成します。まさにテキスト生成に近い手法です。
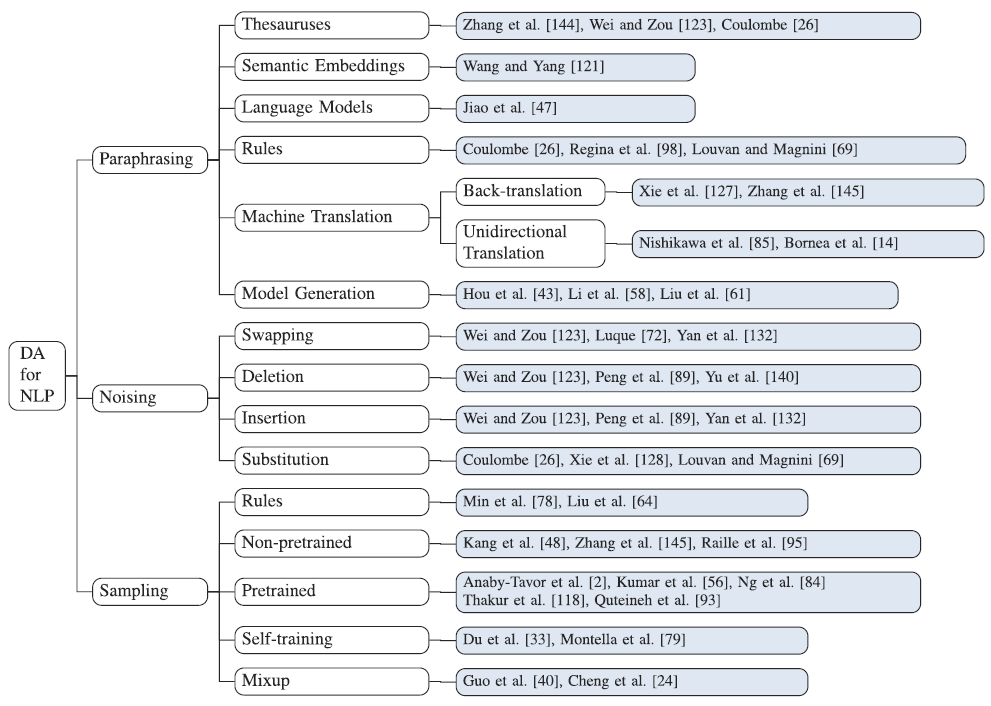
また、データ拡張をさらに細分化した図を、参考までに添付します。とにかくここでは、データ拡張手法の分類の最上位にこれら3タイプがある、ということをおさえておきます。
paraphrasingによるデータ拡張
noisingやsamplingに比べると、良くも悪くもこの手法は堅実なやり方です。当論文では、paraphrasingとして次の6種類を挙げています。
1.シソーラス
シソーラスは、辞書みたいなものです。データ内の1つの単語に似ている単語を、WordNetと呼ばれるシソーラスから抽出し、その単語に置き換えます。

2.Word2Vec系
シソーラスを用いたやり方に似ていますが、シソーラスの代わりにWord2Vec系のモデルを用います。具体的には、特徴量ベクトル同士の近い単語に置き換えます。

また、この手法は単語単位だけではなく、フレーズ(複数の単語の連なり)単位での置き換えも可能です。
3.言語モデル
言語モデルと書きましたが、ここではBERTやRobertaのようなMasked Language Modelのことです。
具体的なやり方は、データ内の特定の単語をマスク(見えなくする)し、そのマスクされた単語を言語モデルにより推論します。そして推論により得られた単語で、元のデータの対象の単語を置き換えます。

4.ルールベース
ルールベースによるデータ拡張は、たとえばこのようなやり方です。

5.機械翻訳
機械翻訳を利用したデータ拡張もあります。分かりやすいのは、逆翻訳と呼ばれる次のようなものです。

また、別の言語の言語データを目的のタスク向けの言語に翻訳する手もあります。
6.seq2seqのモデル
ここでいうseq2seqのモデルは、自己符号化器(オートエンコーダ)です。入力内容に近い内容が出力されるようにして学習されたモデルです。このタイプのモデルにデータを入力し、出力結果を新データとして蓄積します。

paraphrasingの中でも、機械翻訳とseq2seqは、データ内容が比較的変化しやすいです。
noisingによるデータ拡張
ここからは、noisingによるデータ拡張です。この手法の内容は、次の図が分かりやすいです。1つ1つの説明は省略します。
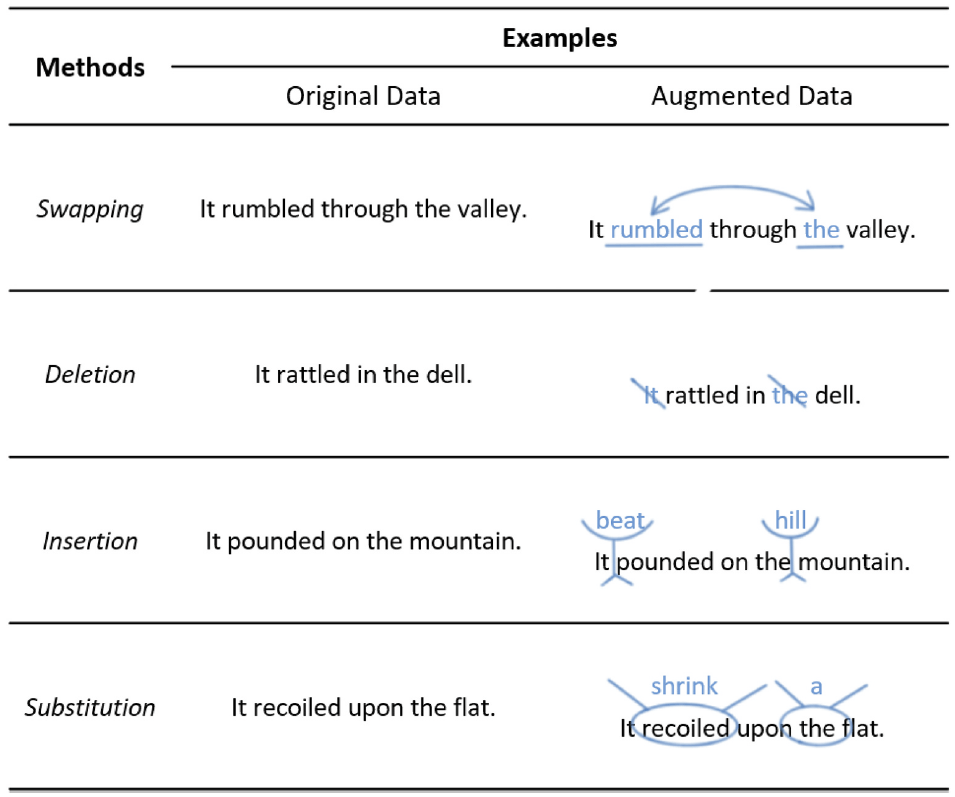
このタイプのデータ拡張では、データ自体の元々の意味をあまり損なわない程度に、データにノイズを加えます。ノイズの例は、上の図です。これにより、元のデータからいくぶん離れたデータを作れるので、データセットの中身が多様になります。
この手法の強み
paraphrasingによるデータ拡張に比べると、これは思い切った手法です。このやり方により作成されるデータは、文法的な誤りが多そうで質が低そうに見えるかもしれません。
しかし当論文によると、このような手法により作成されるデータも含めて学習したモデルは、頑健性(robustness)が高いそうです。頑健性という用語の意味は多様ですが、「テスト用データにノイズを加えても、そのデータの推論結果は変化しにくい」という意味でよく用いられます。
samplingによるデータ拡張
残るは、samplingによるデータ拡張です。所感として、これまでに述べた手法に比べるとさらに特殊です。
samplingによるデータ拡張はその手法自体、paraphrasingによるデータ拡張と少し似ている面があります。どちらのタイプにおいても、ルールベースの手法や学習済みモデルを利用した手法があります。
それでは、paraphrasingによるデータ拡張とは何が違うのか。傾向として、samplingによるデータ拡張の手法には、特定のタスクを志向したものが多いです。また、これまでに述べた手法では、特にラベル情報を気にする必要はありませんでした。samplingによるデータ拡張では、(例外もありますが)ラベル情報が加味されます。
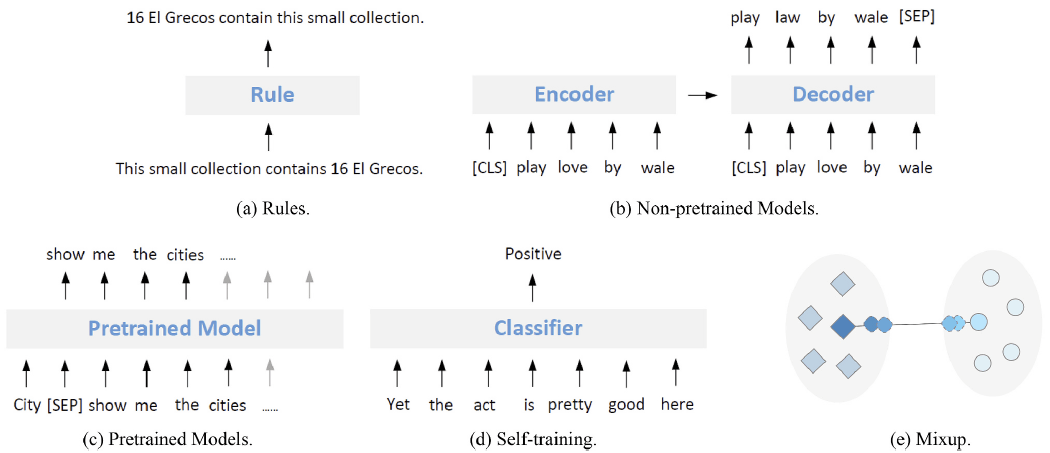
1.ルールベース
例えば、主語(あるいは主部)と述語(あるいは述部)の入れ替えです。

ここで要点になるのは、入れ替えによって得たデータのラベルは何になるのかを、あらかじめルールとして決めておけることです。これが、paraphrasingによるデータ拡張のルールベースの手法との、大きな違いです。paraphrasingやnoisingによるデータ拡張では、元のデータも新しいデータも同じでした。
上の例なら、「能動態の文」というラベルのデータから「受動態の文」というラベルのデータを得る、といった使い方ができそうです。
2.モデルによる生成
一見するとこの手法は、paraphrasingによるデータ拡張の、seq2seqのモデルを用いた手法に似ています。ですが、seq2seqモデルとは異なり、得られるデータは元のデータから意味が離れやすいです。
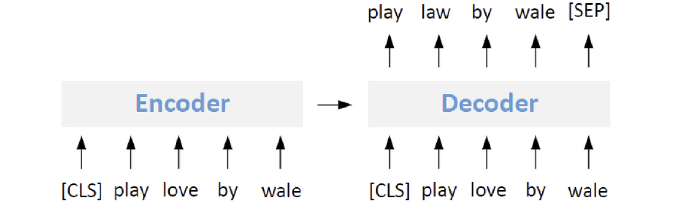
3.事前学習済みのモデル
一例としては、事前学習済みのモデルGPT-2に対し、既存の学習用データを用いてfine-tuningします。そしてそのfine-tuningしたモデルを用いて、新たなデータを生成します。

4.self-training
既存の学習用データを学習させたモデルを用いて、ラベルのないデータを推論し、ラベリングします。
5.mixup
ラベルの異なる2データの間の点を取って、新たなデータとする手法です。
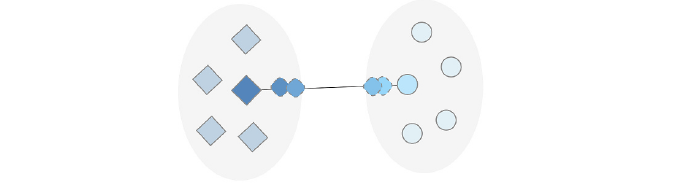
この手法の場合、得られるデータはテキストではなく特徴量ベクトルになります。また、ラベルは両者のラベルに基づくソフトラベルとなります。
この手法の応用先としては、定番のテキスト分類のほか、固有表現抽出などがあります。
データ拡張についての戦略
ここまでで、個々のデータ拡張手法についてひと通り述べました。ただ、ふつうはデータ拡張自体が目的なわけではないです。目的はたいてい、何か特定のタスクを解くことでしょう。
当論文には、データ拡張についての戦略についても書かれています。それについて、少しだけ紹介します。
データ拡張手法のバリエーション
単一のデータ拡張手法よりも、複数のデータ拡張手法を利用するやり方がよく採られています。
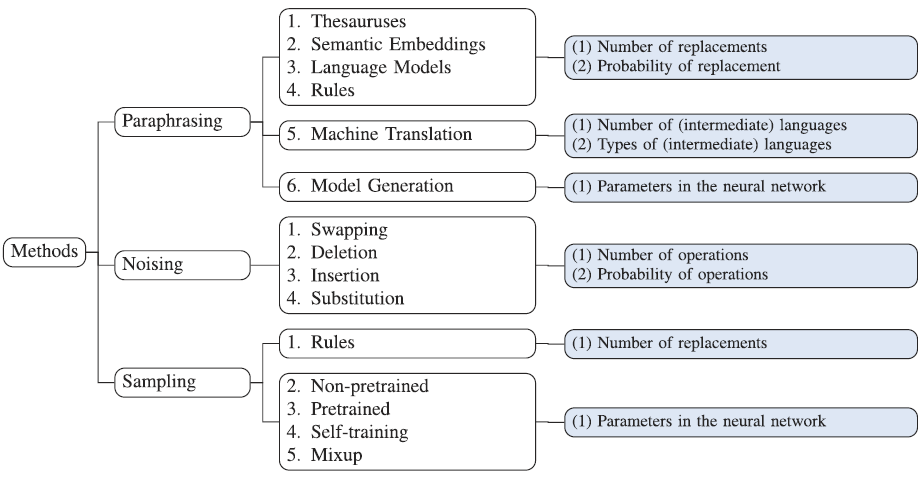
他のやり方は、各ハイパーパラメータにおいて様々なバリエーションの値を用いることです。下の図を見ると、意外に多くの種類のハイパーパラメータがあります。ハイパーパラメータの様々な値を用いることで、より多様なデータを得ることができます。
終わりに
当論文を読んで、データ拡張についての理解がだいぶ深まりました。
単に、データ拡張の手法自体を知ればいいわけではないようです。ここでもやはり、「目的に応じた手段を選ぶ」ことが重要になります。
とは言え、これはかなり難解な気がします。データ拡張の全般的な知見を超えて、自然言語処理全般についての理解が深まっていないと、適切な手段を選ぶのは難しいと思いました。例えばの話、今の時代は事前学習済みモデルが当たり前のように活用されているので、そのあたりの理解は普通に必要になりそうです。
ですのでここは甘く考えずに、入念に調査や考察をすることが重要になりそうです。
自然言語処理におけるデータ拡張についてより詳しく知りたい方は、ぜひ当論文をご確認ください。分量も多く、読みごたえがあります。
最後まで読んでいただき、ありがとうございました。
Discussion