Snowflakeの論文「The Snowflake Elastic Data Warehouse」を読んでみた_Part2
目次
- はじめに
- 注意事項(再掲)
- 4.1 Pure Software-as-a-Service Experience
- 4.2 Continuous Availability
- 4.3 Semi-Structured and Schema-Less Data
- 4.4 Time Travel and Cloning
- 4.5 Security
- 感想
- おまけ
はじめに
この記事は、最近読んだSnowflakeの論文「The Snowflake Elastic Data Warehouse」の内容を備忘的に残したものです。Part1は以下を参照。
今回は、Part2ということで、「4. FEATURE HIGHLIGHTS」の内容を私なりにまとめてみます。対象を4章のみに絞っているので、4.1、4.2といった節の単位で見出しを区切っています。
ちなみに5章「RELATED WORK」では、他クラウドDWHやドキュメントDBとの(当時のアーキテクチャにおける)比較が述べられています。また、6章「LESSONS LEARNED AND OUTLOOK
」は、当時の時勢を踏まえた開発に対する思いやSnowflakeの画期性、今後の技術的課題などがシンプルに述べられています。それぞれ、論文公開からだいぶ時間が経っている現在(2024年)に記述しても、あまり意味がないと思われたため、今回のブログ記事の対象からは外しました。ご興味があれば元の論文をご参照ください。
注意事項(再掲)
- この論文は2016年に寄稿されたものです。情報が古い可能性がありますので、ご注意ください。
- 当時SnowflakeはAWSでの稼働のみをサポートしていたので、Snowflakeの稼働環境はAWSを前提とした書き方になっています。
4.1 Pure Software-as-a-Service Experience
Snowflakeは標準的なデータベースインタフェース(JDBC、ODBC、Pythonなど)をサポートし、様々なサードパーティツールと連携できるが、Web UIだけでシステムと対話できるということが、決定的な差別化要因である。
- Web UIによって、どんな場所、環境からもSnowflakeにアクセスできるようになり、ソフトウェアをダウンロードする必要もなく、様々な操作ができるようになった。
- Web UIはSQL操作だけでなく、データベースカタログへのアクセス、ユーザーやシステムの管理、モニタリング機能、使用状況に関する情報などを提供する。
- Web UIの機能は継続的に拡張していく予定。
Web UIのみならず、システムアーキテクチャのあらゆる側面に、使いやすさとサービス体験へのこだわりが及んでいる。
故障モード(failure modes)も、チューニングも、物理的な設計も、ストレージの手入れも必要ない。データとクエリだけが全て、という考え方。
4.2 Continuous Availability
かつてDWHはバックエンドシステムであり、ダウンタイムが運用に大きな影響を与えることは無かった。しかし、データ分析がビジネスにとって不可欠になるにつれ、継続的可用性はDWHにとって重要な要件となった。
Snowflakeは、障害回復力とオンラインアップグレードという技術的な特徴によって、継続的可用性を提供している。
4.2.1 Fault Resilience
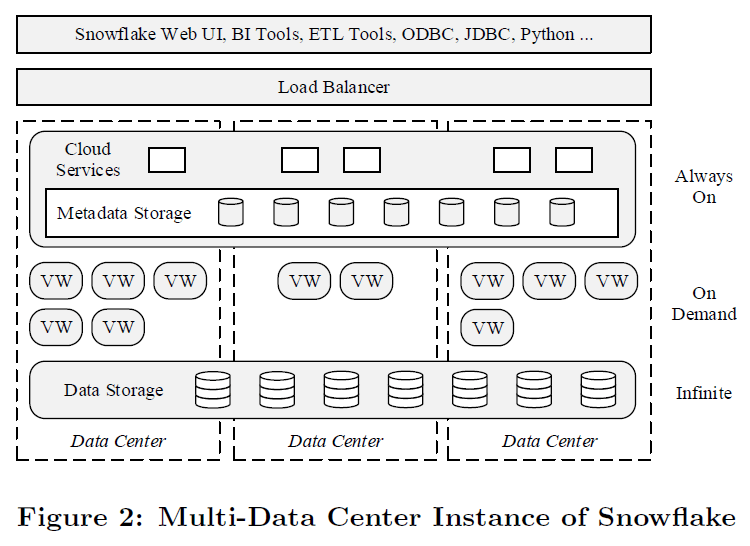
元論文「The Snowflake Elastic Data Warehouse」より引用
ストレージ層はS3が使用されている。
- S3はAZ間のレプリケーションによって、99.99%の可用性と、99.999999999%(イレブンナイン)の耐久性を保証する。
クラウドサービス層も複数AZでの耐障害性がある。
- S3アーキテクチャに合わせて、クラウドサービス層のメタデータストアも複数のAZに分散してレプリケーションされる。
※メタデータストアにS3が使われているためと思われます。 - クラウドサービス層の他のサービス群は複数のAZにあるステートレスノードで構成され、ロードバランサーがユーザーリクエストを振り分ける。そのため、単一ノードや、AZ全体で障害が発生しても、システム全体には影響がない。(故障ノードを使ったクエリは失敗してしまう可能性があるが、その場合、次のクエリでは別のノードにリダイレクトされる。)
VWはパフォーマンス上の理由からAZに分散されない。
- 分散クエリ実行において、高いネットワークスループットを担保することは非常に重要であり、同一AZ内では(複数AZに分散している場合と比べて)ネットワークスループットが高くなる。
- クエリ実行中にワーカーノードの1つが故障した場合、クエリは失敗するが透過的に再実行される仕組みになっている。(ノードを即座に再配置するか、一時的にノード数を減らすかによって再実行を実現。)
- ノードの再配置を高速化するために、Snowflakeはスタンバイノードの小さなプールを保持している。
- AZ全体で障害が発生した場合には、そのAZ上で動くVWで実行されている全クエリが失敗することになるが、することは稀であると想定し、そのリスクについては受容するというスタンスを取っているが、将来的にはそういったリスクにも対処したいと考えている。
(補足)現在のSnowflakeにおけるクエリ実行成功率のSLAについては、以下ブログ記事が参考になります。
4.2.2 Online Upgrade
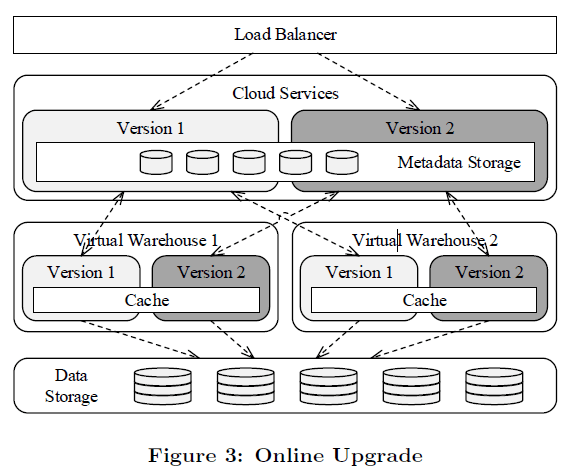
元論文「The Snowflake Elastic Data Warehouse」より引用
Snowflakeは障害発生時だけでなく、ソフトウェアのアップグレード中にも継続的可用性を提供する。
- クラウドサービス層のコンポーネントとVWの両方にて、複数のバージョンを並行してデプロイできるように設計されている。これは全サービスがステートレスであることによって可能になる。
- ソフトウェアアップグレード時には、まず新バージョンのサービスを旧バージョンと一緒にデプロイする。
- その後、ユーザーアカウントは順次新しいバージョンに切り替わっていき、その時点で新しく発行されたクエリはすべて新しいバージョンのサービスへ、旧バージョンに対して実行されていたクエリは完了するまでそのまま実行される。
- すべてのクエリとユーザーが旧バージョンの使用を終了すると、そのバージョンのすべてのサービスが終了し、廃止される。
- Figure 3にあるように、アップグレードプロセス中には2つのバージョンが並列で動いており、クラウドサービス層のサービスは一致するバージョンのVWにしか向かないようになっている。
- クラウドサービス層では両バージョンでメタデータストアを共有している。
- 異なるバージョンのVWも同じワーカーノード、およびそのワーカーノードのキャッシュを共有できる。そのため、アップグレード後にキャッシュを再投入する必要がない。
Snowflakeは本論文執筆時において、週1回アップグレードをしている。
- オンラインアップグレードが可能なことにより、開発スピードや迅速なバグの対処ができる。
- Snowflakeでは、アップグレードとダウングレードの両方が継続的にテストされている。
- 本番バージョンで重大なバグが発見された場合、迅速に以前のバージョンにダウングレードするか、修正プログラムを実装して予定外のアップグレードを実行することができる。
- 継続的にアップグレードとダウングレードをテスト・演習しているので、このプロセスもそれほど怖いものではない。高度に自動化されている。
4.3 Semi-Structured and Schema-Less Data
Snowflakeでは、標準SQLのネイティブなデータ型に加えて、半構造化データ型を3つ(VARIANT、ARRAY、OBJECT)サポートしている。
特にVARIANT型があることで、Snowflakeは従来のETLではなく、ELT方式を使用することができる。(ARRAYとOBJECTは、VARIANTを制限した形に過ぎない。)
- ドキュメントスキーマを指定したり、ロード時に変換を実行する必要がない。
- JSON、Avro、XMLなどのフォーマットの入力データをVARIANT列に直接ロードすることができる。
- 変換処理(Transformation)が必要な場合には、並列SQLデータベースのフルパワーを使って実行することができる。
- 結合、ソート、集約、複雑な述語などは従来のETLツールでは欠落しているか、非効率な処理になっていた。
- Snowflakeではユーザ定義関数(UDF)も備えており、その中でJavaScript構文とVARIANT型を使うことができる。これによって、SnowflakeにプッシュできるETLタスクの数はさらに増える。
4.3.1 Post-relational Operations
半構造化データに対する最も重要な操作は、データ要素の抽出であり、Snowflakeは関数的なSQL記述と、JavaScriptライクなパス構文の両方で抽出操作を提供する。
また、Snowflakeはフラット化(入れ子になった半構造化データを複数行に分割する操作)もサポートしており、SQLのラテラルビューを使用してフラット化操作を表現する。このフラット化を再帰的に行うことができるので、半構造化データの階層構造をリレーショナルテーブル(SQL処理に適した形)に変換することができる。
フラット化の反対の操作である集約操作(ARRAY_AGGやOBJECT_AGGなど)もいくつか導入されている。
4.3.2 Columnar Storage and Processing
半構造化データをRDBに統合する場合、シリアライズ(直列化、バイナリ化)を使用するのが一般的な設計方法であるが、このような行単位の(rowwise)表現では、カラム型リレーショナルデータよりもデータの保存と処理の効率が悪くなってしまう。
Snowflakeでは、スキーマレスなシリアライズの柔軟性と、列指向RDBのパフォーマンスの両方を実現するために、型推論と列指向ストレージに新しい自動化アプローチを導入している。
- Snowflakeでは半構造化データを格納する際、システム側で単一テーブルファイル内のドキュメントのコレクションに対して、統計分析を自動的に実行する。
- この統計分析によって自動型推論を実行し、どのパスが頻繁に共通するかを判断した後、対応する列はドキュメントから削除され、他のネイティブのリレーショナルデータと同じく、圧縮されたカラム形式を使用して保存される。
- これらの列に対して、Snowflakeは通常のリレーショナルデータと同様に、プルーニングで使用するための集約処理を計算する。
- テーブルスキャンの間、各列はVARIANT型の1つの列に再構築することができるが、ほとんどのクエリは元のドキュメントの列のサブセットにしか興味がない。そのような場合、Snowflakeは射影(projection)とキャスト式をスキャン演算子に押し下げ、必要な列のみがアクセスされ、ターゲットとなるSQL型に直接キャストされるようにする。
こうした最適化処理がテーブルファイルごとに独立して実行されるため、スキーマが進化しても効率的な格納と抽出が可能になっている。
しかし、クエリの最適化、特にプルーニングに関しては課題がある。クエリがパス表現に対する述語を持ち、プルーニングを使用してスキャンするファイルセットを制限したい場合を考える。この場合、ほとんどのファイルではそのパスに対応するカラムが存在するかもしれないが、それはいくつかのファイルでメタデータを保証するのに十分な頻度でしかない。
- こうした問題に対する保守的な解決策は、適切なメタデータが存在しないすべてのファイルを単純にスキャンすることである。
- 一方で、Snowflakeは半構造化データに含まれるすべてのパス(値ではない!)に対して、ブルームフィルターを計算することで解決する。
- ブルームフィルターは他のファイルメタデータと一緒に保存され、プルーニング中にクエリオプティマイザによって調査される。
- これにより、与えられたクエリが必要とするパスを含まないテーブルファイルは、安全にスキップすることができる。
(補足)ブルームフィルタについてはインターネットに色々と情報が載っているのと、私も理解しきれているわけではないので詳細は省きますが、あるデータが該当の集合に属するかどうかを判定するのに用いられる確率的データ構造の一種のようです。
ブルームフィルタは、偽陰性(あるのにないという判定ミス)がなく、偽陽性(ないのにあるという判定ミス)は起こりうるようです。偽陰性がなければクエリ対象データを取りこぼすことは無くなるので、偽陽性(クエリ対象じゃないのにスキャンしちゃうケース)のリスクは受容して効率的なデータ判定を優先した、もしくは何らか別の方法で偽陽性を取り除く仕組みを採用したのだと考えられます。
4.3.3 Optimistic Conversion
JSONやXMLなどのフォーマットでは、日付/時刻のデータなどが文字列として表現されているため、これらの値はロード時やクエリ時に、文字列から実際のデータ型に変換してあげる必要がある。
- 型付きのスキーマなどがない場合、これらの文字列変換はクエリ時に実行される必要があるが、クエリがメインのワークロードだと効率が悪くなってしまう。
- 型付けされていないデータのもう1つの問題は、プルーニングのための適切なメタデータがないことである。分析のワークロードでは、日付カラムがクエリの範囲述語として使われることが多いので特に日付データの場合には重要である。
- しかし、ロード時に自動型変換を行うのでは、元の情報を失ってしまう可能性もある。
- 例えば、数字で表現されている製品IDが実際には数値型ではなく、先頭にゼロを含む文字列型のデータかもしれない。
- 日付のように見えるものが実際にはテキストメッセージである可能性もある。
Snowflakeでは上記のような問題に対して楽観的なデータ変換(Optimistic Conversion)を行うことで解決している。
- 変換結果と変換元文字列の両方を別々の列に保存する。
- 後になって元の文字列を必要とするクエリが発生した場合には、簡単にクエリ、または再構築することができる。
- 未使用の列はロードされずアクセスもされないため、二重にデータが保存されることによるクエリパフォーマンスへの影響は最小限で済む。
4.3.4 Performance
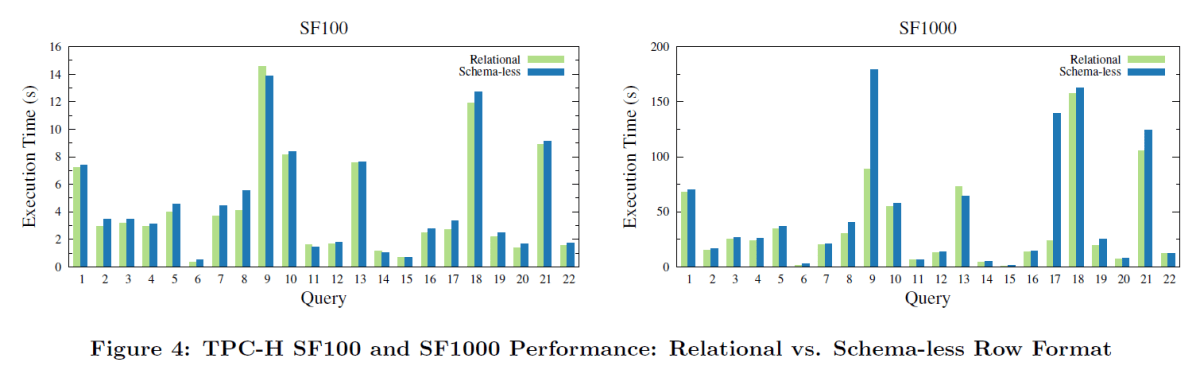
元論文「The Snowflake Elastic Data Warehouse」より引用
これまで述べてきた半構造化データに対するカラム型ストレージ、楽観的変換、プルーニングの組み合わせがクエリ性能に及ぼす影響を評価するために、TPC-Hに類似したデータを用いて実験を行ったところ、(SF1000のQ9とQ17を除き)オーバーヘッドは10%程度にとどまった。
4.4 Time Travel and Cloning
Snowflakeは多版型同時実行制御(MVCC)によって、スナップショット分離(SI)を実装している。SI実装のために、テーブルに対する書き込み操作(INSERT、UPDATE、DELETE、MERGE)は、ファイル全体を追加したり削除したりすることで、テーブルの新しいバージョン(版)を生成する仕組みになっている。
- 新しいバージョンでファイルが削除されると、設定可能な期間(最大90日間)保持され、これによりユーザーはタイムトラベル機能を使用して、以前のバージョンのテーブルを読み込むことができるようになっている。
- 便利な
ATやBEFORE構文を使ったSQLによって、ユーザーはタイムトラベルを使用できる。 - 同じメタデータに基づいて、誤ってドロップされたオブジェクトについても、UNDROPキーワードによって迅速に復元できる。
また、Snowflakeは新しいCLONEキーワードを使用した機能も実装している。
- テーブルファイルの物理的なコピーを作成することなく、同じ定義と内容を持つ新しいテーブルを素早く作成できる。
- クローン操作は単にソーステーブルのメタデータをコピーするだけである。
- クローニング直後は、両方のテーブルが同じファイルセットを参照するが、その後はどちらのテーブルもそれぞれが個別に変更されていく。
- クローン機能はスキーマやデータベース単位でもサポートされるので、非常に効率的なスナップショットが可能である。
-
CLONEキーワードはATやBEFOREと組み合わせることもでき、スナップショットを事後的に作成することも可能。
4.5 Security
Snowflakeはクラウドプラットフォームを含むアーキテクチャの全レベルにおいて、ユーザーデータを攻撃から保護するために設計されている。この目的のために以下のような機能が実装されている。
- 二要素認証
- (クライアント側での)暗号化されたデータのインポート・エクスポート
- セキュアなデータ転送
- セキュアなストレージ
- データベースオブジェクトの役割ベースのアクセス制御(RBAC)
また、Snowflakeは完全なエンドツーエンドのデータ暗号化とセキュリティを提供しており、データはネットワーク経由で送信される前、およびローカルディスクまたは共有ストレージ(S3)に書き込まれる前に常に暗号化される。
4.5.1 Key Hierarchy
SnowflakeはAWS CloudHSMに基づいた階層的なキーモデルによって、強力なAES 256ビット暗号を使用している。
暗号化キーは自動的にローテーションされ、再暗号化されるので、暗号化キーはNIST 800-57の暗号鍵管理ライフサイクルを完全に満たすものである。
さらに、暗号化と鍵の管理はユーザーにとって完全に透過的であり、設定や管理の必要はない。
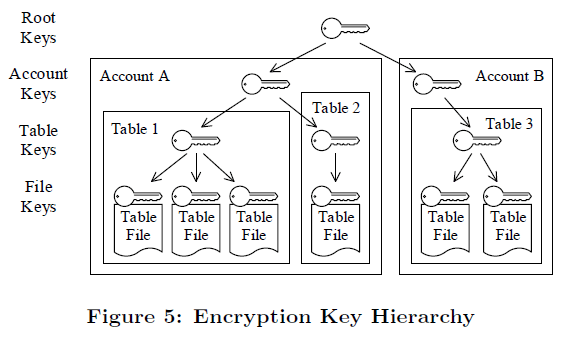
元論文「The Snowflake Elastic Data Warehouse」より引用
上図(Figure 5)のように、Snowflakeのキー階層は、上からルートキー、アカウントキー、テーブルキー、ファイルキーの4階層になっている。
- 親キーはその下の子キーを暗号化する。
- アカウントキーは1つのユーザーアカウントに対応し、各テーブルキーは1つのデータベーステーブルに対応し、各ファイルキーは1つのテーブルファイルに対応する。
- 階層化されたキーモデルによって、各キーが保護する対象のデータ量を制限する。これはセキュリティ上有効である。
Snowflakeの階層型キーモデルは、マルチテナントアーキテクチャにおいて、ユーザーデータの分離を保証している。
4.5.2 Key Life Cycle
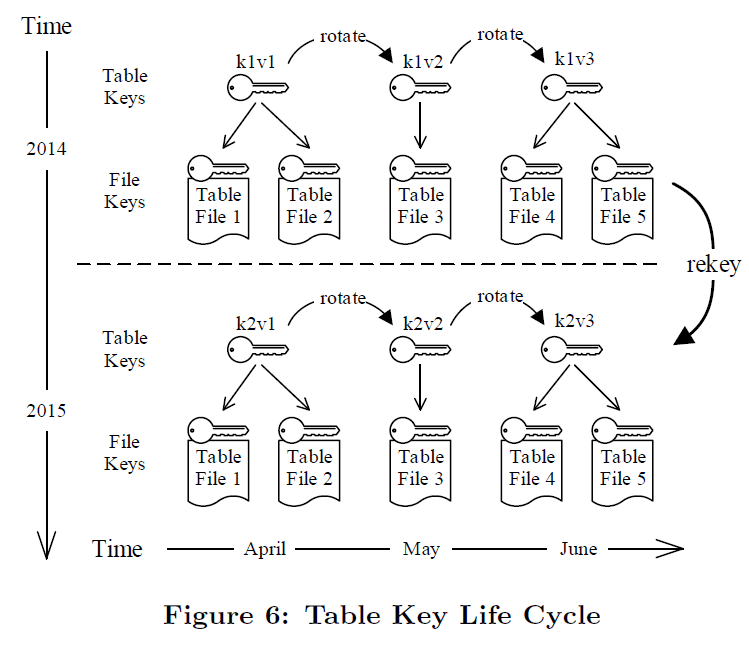
元論文「The Snowflake Elastic Data Warehouse」より引用
Snowflakeは暗号化キーの有効期間も制限しており、暗号化キーは以下の4つの段階を経る。
- (1) 運用前の作成フェーズ
- (2) キーが暗号化と復号化に使用される運用フェーズ
- (3) キーが使用されなくなる運用後のフェーズ
- (4) キーが破壊されるフェーズ
フェーズ(2)について:
- キーの発信側と受信側でそれぞれ使用できる期間を制限する必要がある。
- キーがすべてのデータを暗号化しなくなった場合にのみ、フェーズ(3)、(4)に移行することができる。
- Snowflakeは、キーのローテーションによって起点となるキーの使用期間を制限し、リキー(再暗号化)によって受信側の使用期間を制限する。
キーのローテーションについて:
- 一定間隔(例えば1か月)で新しいバージョンの暗号化キーを生成する。
- この一定期間が経過するごとに、新しいバージョンのキーが生成され、前のバージョンのキーは「引退(retire)」する(完全廃棄ではない)。
- 引退したキーはまだ使用可能であるが、データの復号のみに使用される。
- キー階層の中で新しい子キーをラップするときや、テーブルに書き込むとき、データを暗号化するために使用されるのは有効な最新バージョンのキーだけである。
リキー(再暗号化)について:
- リキーとは、古いデータを新しいキーで再暗号化するプロセスのこと。
- キーのローテーションは、キーがアクティブな状態(発信側の使用)から引退した状態(受信側の使用)へと移行することを保証するのに対して、リキーはキーが引退した状態から破棄された状態へと移行することを保証する。
Figure 6のイメージは、1つのテーブルキーのライフサイクルについて、キーが月に1回ローテーションされ、データは年に1回リキーされると仮定した例。以下、キーのローテーションとリキーの流れについて詳細説明。
- 2014年4月に、キー1のバージョン1(k1v1)を使用して、テーブルファイル1と2が作成される。
- 2014年5月、キー1はバージョン2(k1v2)にローテーションされ、k1v2を使用してテーブルファイル3が作成される。
- 2014年6月、キー1がバージョン3(k1v3)にローテーションされ、さらに2つのテーブルファイルが作成される。
- 2014年6月以降、テーブルへの挿入や更新は行われないとする。
- 2015年4月、k1v1は1年経過したことになり、破棄する必要がある。新しいキーであるキー2バージョン1(k2v1)が作成され、k1v1に関連するすべてのテーブルファイルがk2v1を使用してリキーされる。
- 2015年5月、k1v2も同様に1年経過したことになり、テーブルファイル3はk2v2を使用してリキーされる。
- 2015年6月には、テーブルファイル4と5がk2v3を使用してリキーされる。
(補足)Figure 6において、2015年の「rotate」は消した良いかもしれません。以下公式ドキュメントの図の方が分かりやすいです。
アカウントキーとテーブルキーの間、およびルートキーとアカウントキーの間にも同様の仕組みが実装されている。
- リキーが必要なのは、直下の階層のキーだけである(アカウントキーとルートキーは、ファイルのリキーは必要ない)。
- しかし、テーブルキーとファイルキーの関係は異なり、ファイルキーはテーブルキーにラップされていない。
- その代わり、ファイルキーはテーブルキーと(一意な)ファイル名の組み合わせから導き出されるようになっている。
- これによってテーブルキーが変更されるたびに関連するファイルキーもすべて変更されることになる。
- このキー導出方式は、個々のファイルキーを作成、管理、受け渡しする必要がなくなることが大きな利点である。
- Snowflakeでは何十億ものファイルを扱うので、この導出方式を採用した。(そうしないと、何ギガバイトものファイルキーを扱わなければいけなくなる。)
リキー処理はバックグラウンドで動作し、クエリ実行とは異なるワーカーノードを使用するので、ユーザーのワークロードには影響を与えない。
ファイルがリキーされた後、Snowflakeはデータベーステーブルのメタデータを更新し、新しく暗号化されたファイルを指すように動作し、古いファイルは進行中のクエリが全て終了した時点で削除される。
4.5.3 End-to-End Security
Snowflakeはルートキーを生成、保存、使用するために、AWS CloudHSMを使用している。
- AWS CloudHSMは、AWS内の仮想プライベートクラスタに接続された、一連のハードウェアセキュリティモジュール(HSM)である。
- ルートキーを使用するすべての暗号処理はHSMで実行されるため、HSMデバイスへのアクセス権限がない限り、下位レベルのキーを解除することはできない。
- HSMはキーのローテーションやリキーの際など、アカウントレベルやテーブルレベルでのキー生成にも使用されている。
- サービス停止の可能性を最小化するため、AWS CloudHSMをHA構成で構築している。
また、データの暗号化に加え、Snowflakeは次の方法でユーザーデータを保護する。
- S3のアクセスポリシーによるストレージの分離。
- データベースオブジェクトへのきめ細かなアクセス制御のための、ユーザーアカウント内のRBAC。
- 暗号化されたデータのインポートおよびエクスポートについては、クラウドプロバイダー(AWS)にデータを見られることはない。
- 安全なアクセス制御のための、二要素認証とフェデレーション認証。
感想
Snowflakeが高可用性を実現している仕組みは、なるほどなー!と思いました。VWをあえて単一AZ上で構築しているのも納得のいく理由ですし、現在のSLAから見ても、VWの可用性に対するサービス目標を放棄しているわけではないという姿勢がうかがえます。
そして、オンラインアップグレードが可能な仕組みも面白かったです。この仕組みがあるからこそ、Snowflakeのアップデートサイクルの高速化も実現できているのですね。(当時から週次アップデートしていたというのが驚きでした!)
さて、Snowflakeの論文「The Snowflake Elastic Data Warehouse」の内容を、2つのパートに分けて紹介してきました。Snowflakeは公式ドキュメントも充実しているので、ドキュメントを読めば分かる内容も多いのですが、改めて論文を読んでみると、「処理を高速化するためにそんな工夫が!」「マイクロパーティションって裏側ではそんな仕組みだったんだ!」など、新たな発見がたくさんありました。備忘メモのような形にしたので少々読みにくかったかもしれませんが、Snowflakeの内部アーキテクチャの理解深耕や、皆さんの知的好奇心を満たすことに少しでも貢献できましたら幸いです。
今回は少しお堅い内容でしたが、今後はSnowflake検証記事などもあげていこうと思います!
おまけ
実は、Snowflakeの論文はもう1本あります。
こちらの論文については、すでに日本語訳のソースがあったり、Zennにも紹介記事が投稿されていたりするので、もしご興味があれば読んでみてください。
Discussion