[論文紹介] Snowflake - NSDI '20 -
Building An Elastic Query Engine on Disaggregated Storage
突然始まった、論文紹介シリーズである。
データベースに関連する目に付いた論文をざっくりと解説していく。個人的な興味は分散DB、トランザクション、ストレージエンジン等なので、その辺りに偏ることはご容赦頂きたい。
初回は「Building An Elastic Query Engine on Disaggregated Storage」(日本語訳:分散ストレージ上での弾力性の高いクエリエンジンの構築)、Snowflakeのアーキテクチャを解説した論文を読んでいく。
※早速お詫びとなるが、Zennのタイトルで文字数制限があり、正式な論文名を当記事に冠することが出来ない。誤解を招くタイトルだったら申し訳ない。
と思ったら
こちらに論文の翻訳が発表されていた。英語は苦手だが全文読んで理解したいという方はこちらを読んだ方が良いかも知れない。
さらに企業情報や技術的内容についても、後続記事「スノーフレイク (SNOW) の技術的な企業分析」で解説されている。ご興味のある方は一読をお勧めする。
私のDB与太話も含めた、私見だらけの要約を読みたいという気まぐれな方は以降に進んで頂きたい。
この論文を読んで(個人的な感想)
理解してる方には当たり前のことかも知れないが、Snowflakeはデータベースとしてとらえるより、Hadoopのような分析基盤として捉えた方が分かりやすい。
Snowflakeのドキュメントに記載のあるKey Conceptsには、以下のようなアーキテクチャが紹介されている。
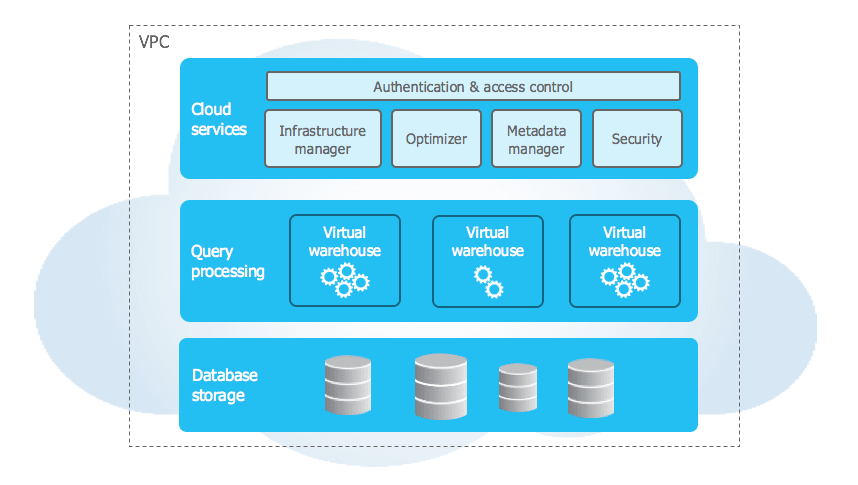
上図はManagementレイヤとしてのCloud servicesと、ComputeとしてのQuery processing、そしてStorageレイヤとしてのDatabase storageの3層に分かれている。
しかし、実体としては当論文で紹介されているように以下の4層構造で捉えることが適切と考える。
- Cloud services
- Query processing
- Distributed Ephemeral Storage
- Database storage
このうち、Distributed Ephemeral Storageを如何に扱うか、そしてSnowflake全体のElasticityを担保しながら更に上手く使う方法がないかについて当論文では詳しく語られている。
当論文で提示されたアーキテクチャを解釈し図示すると、以下のようになる。
良く言われるように、Snowflakeのデータはコスト優位でキャパシティの弾力性が高く、可用性も非常に高いオブジェクトストレージサービス(AWSではS3)に永続化される。これが図中のRemote Persistent Storageである。
ドキュメント等では仮想ウェアハウスとして説明されるクラスタがこのストレージ上に構築される。クラスタを構成するノードは、大容量のNVMe-SSDを搭載したVMと推測される。AWSで言えばi3などが該当し、これらのインスタンスローカルなEphemeral DiskとDRAMを下記2つの用途で利用する。
- 分析クエリが生成するIntermediate Data
- Remote Storageから取得したデータを置くWrite-through Cache
どのデータをどのノードが扱うかは基本的にConsistent Hashingで決定している。つまり、Remote Storage上に多数存在するファイルをHashによる分散で各ノードに割り当てているわけであり、Hadoopのようなデータ分析基盤に近いという私の感想はここから来ている。
但し、分析クエリの処理能力をオンデマンドで拡張するためにはComputeノードの追加が必要であり、拡張時にIntermediate DataとCacheの双方がノード間でリバランスされるようではSnowflakeの目標とするElasticityが達成できない。そのため、Lazy Consistent Hashingというアルゴリズムを用いて、リバランス負荷を軽減させる設計がなされている。
ここは現状実装されているリソース拡張方法が最適だとSnowflakeも考えているわけではなく、論文中にもFuture workとして目指す姿がいくつか示されている。
そのうちの最大の目標は、ServerlessなDWHという姿になる。
Related Workにあげられているように、データ分析におけるIntermediateなデータをServerlessでも効率的にやり取りしながら、拡張性・弾力性を担保するプラットフォームを目指していることが当論文では示されている。
そもそもSnowflakeとは?
まず、著者のバックグラウンドとしてSnowflakeをトレーニング・実務等で触ったことはない。当記事はその前提であくまで論文紹介としてお読み頂きたい。
SnowflakeはHPにもあるように、「クラウドデータプラットフォーム」を標榜し、DWHとしてはもちろん、その周辺のデータ蓄積や処理を統合的に担うサービスの提供を目指している。
大きな特徴として、インストールベースのソフトウェアとしてではなく、あくまでクラウド上で提供されるサービスとしてのみ提供されている。つまり、オンプレミスのサーバに構築するシステムとしては使えない。
今回紹介する論文はまさにこの特徴に関連しており、パブリッククラウド(AWS、Azure、GCP)で提供される分散ストレージ上に如何にElasticなクエリエンジンを築くかについて、設計と実装が丁寧に解説されている。
この論文の位置付け
当論文ではSnowflakeを運用した上での知見を実際のデータに基づいて解説している。
Snowflakeの実行計画作成やその最適化・同時実行制御などについてはSIGMOD '16で発表されたこちらの論文を参照のこと。
本文の簡単な解説
当論文へのポインタはこちら。
以降では全文の詳細な解説というより、論文中からDistributed Ephemeral StorageとそのElasticityに係わる部分を抽出し、理解できるように構成している。
Snowflakeの課題意識とデザインゴール
Introductionでは、従来のシェアードナッシング・アーキテクチャで構成されたデータベース(Hadoopのようなデータ基盤も含む)の欠点として、以下が指摘されている。
- ハードウェアの分割単位とワークロードの要求がマッチしない
- Elasticityの欠如
従来アーキテクチャではCPUとメモリ・ストレージ等の個別調整は困難で、ノード(VM)単位でスケールする必要があった。しかし、それではElasticityの欠如を招くというのがSnowflakeの強い課題意識になっており、同ワードは論文中に40回も登場する。
Snowflakeではこうした欠点を解決するために、「SQLをサポートをするクラウドベースのデータウェアハウスシステム」として、下記3つのデザインゴールが設定されている。
- ComputeリソースとStorageリソースの弾力性(Elasticity)
- マルチテナンシー
- 高いパフォーマンス
1.のElasticity低下の原因となるのが、中間的・一時的なデータの扱いである。
intermediate(69回登場)やephemeral(66回登場)という記述が当論文ではたびたび見られるが、これは集計処理等で生成された中間データの事を指す。
先ほど述べたノード単位のスケールでは、中間データの移動・再編成を伴い、パフォーマンスにも様々な悪影響を及ぼす。これをSnowflakeでは、ComputeとStorageの密結合を分離することで解決する。
上記の課題意識を受けて、Snowflakeの設計と実装における、2つの重要なアイデアは以下となる。
- Computeノード間で共有可能なIntermediate Dataを管理する、カスタムストレージシステム
- 上記ストレージをWrite-through Cacheとしても用い、ネットワーク負荷を軽減する
ポイントとなるのはIntermediate Dataである。この部分に関してはクエリ実行で復元できるため高い可用性よりも、低レイテンシ・高スループットなアクセスが優先される。
こうした前提を踏まえ、Snowflakeは下記4つのコンポーネントから構成される(※論文にならい、Elasticのワードを多用する)。
- クラウドサービスを利用したコントロールレイヤ(CS)
- 仮想ウェアハウスによるElasticなComputeリソース
- Elasticなノードローカルの一時的ストレージ
- Elasticなリモートの(ネットワークアクセスが必要な)永続ストレージ
上記4階層のうち、1.はクエりのスケジューリングやその他制御を担当し、実体データを持たない。データ処理は2.のComputeリソースを用いて行われる。この2.の処理時に3.は必要なデータを一時的に格納し、4.とは異なる低レイテンシなアクセスを提供する。
また、3.はノードローカルなキャッシュとしてだけでなく、ノードを跨るEphemeral Storage Systemとして構築される。このストレージシステムは仮想ウェアハウス単位で実行され、ノード追加・削除時もリバランスが不要である。
4.はリモートの永続ストレージである。レイテンシやスループットよりも可用性・拡張性などに重点を置き、AWSをプラットフォームとする場合は S3(オブジェクトストレージ)が使われる。Snowflakeでは、S3上の巨大でImmutableなファイルを通常DBのデータブロックのように扱う。 このファイルには部分的なWriteは許されず、全てを上書きする必要がある。部分的なReadは可能。
Ephemeral Storage System
ここからは先ほど触れたEphemeral Storage Systemの詳細を見ていく。
Snowflakeでは、ローカルメモリ->ローカルSSD->リモートオブジェクトストレージの順に、データ配置を階層化している。Ephemeral Storage Systemでは前の2つ、メモリとSSD上のデータ管理を行う。
クエリ実行により発生した中間データのうち、メモリ内に収まらないものはローカルSSDに移動され、SSDに収まらないデータは更にリモートの永続ストレージ(つまりS3)に移動される。
エフェメラルストレージシステム内の永続的なファイルの「ビュー」は、リモートの永続的なデータストア内のファイルと一貫していなければならない。エフェメラルストレージシステムが、永続的データファイルのためのWrite-through Cacheとして動作することでこれを実現する。
現状のローカルメモリ+ローカルSSD以外に、インメモリ・ストレージ・システムが検討されたこともあるとのことだが、想定される中間データのボリュームが大きいため、現在の構成となっている。
現在のEphemeral Storage Systemにも課題はあり、例えばIntermediate DataとWrite-through Cacheの配分は解を出すのが困難な問題の一つである。現状はIntermediate Dataを優先しているが、それが最適でないケースも認識している。
Elasticity実現のための今後の方向性
論文中に明確に書かれているように、SnowflakeはServerlessなDWHプラットフォームを模索している。AWS Lambda、Azure Functions、Google Cloud Functionsなどのサーバーレスインフラが提供する、自動スケーリング・Elasticity・きめ細かな課金などの特徴は大きな魅力である。
そのためSnowflakeは、独自のカスタム・サーバーレスのような計算プラットフォームを構築に向けて、効率的なリモートのエフェメラル・ストレージ・アクセスとマルチテナント・リソース共有におけるいくつかの課題を解決する必要があると考えている。
そこで紹介されているのが以降の2つの論文である。
どちらもS3を利用したデータ分析の速度に満足できず、コストの高いRedisを足回りとした分析と同じパフォーマンスを実現することを目標としている。
論文はこちらから参照可能。発表時のスライドも公開されている。
PocketはまさにSnowflakeが目標としているServerlessな分析基盤において、ジョブ間の中間データのやり取りを効率的に行う分散データストアを提案している。課題意識も共通しており、S3のような既存のクラウドストレージシステムでは、Serverless Analyticsが必要とするElasticity、パフォーマンス、コストの要求を満たさないという点が出発点となっている。
Pocketの実装は以下のようになる。
- メタデータとストレージサーバは、Apache Crail分散ストレージシステムがベース。
- Flashストレージ層にはReFlexを使用
- ストレージとメタデータサーバをKubernetesで実行
Pocketでは上記の構成でHDDやNVMe-SSD、メモリなどメイン記憶領域が異なるストレージサーバを混在させている。その上でS3を圧倒的に上回り、かつインメモリKVSのRedisと同等のパフォーマンスを実現している。無論、コスト効率はPocket>Redisとなる。
当論文の資料からキーワードを一つ抜き出すとすれば、以下となるだろう。
Pocket achieves similar performance to Redis but uses NVMe Flash
Locus
論文はこちらで参照可能。これも発表時のスライドが公開されている。
こちらはCloudのSlow Storage(S3)とFast Storage(ElastiCache)を組み合わせて、High CapacityでかつHigh IOPS、そしてコスト効率の高いストレージを実現する。
実際には、S3またはElastiCacheを分析ジョブの中間データの置き場所としてシンプルに使うのではなく、ジョブのステージごとに出力するストレージを使い分けている。
主眼はパフォーマンスの向上というより、同等のパフォーマンスを出す既存構成よりもリソース利用量を削減し、同時にコスト削減を目指すという所に置かれているように見える。
まとめ
今回はSnowflakeの設計思想を紹介し、設計上の目標や将来的な方向性を解説した。
個人的にはSnowflakeをSQLが利用可能なクラウドベースのDWHとして捉えていたが、今回の論文を読むことにより、HadoopやCassandraのようなスケーラブルな分析基盤を実現するために、Intermediate Dataを効率的に扱う方法を考え続けている製品だと感じた。
今後、Snowflakeが実際にServerlessなクラウドベースのDWHを実現できるのかは、引き続きウォッチしていきたい。
Discussion