Strix HaloでローカルLLMをFine-tuningする
はじめに
Strix Haloで便利なツールを次々に開発されているDonato Capitellaさんが新しい動画を公開されていた。今回はなんと、Strix HaloでFull Fine-tuningを実現するツールを公開されており、面白そうなのでEVO-X2で動かすことにした。
というわけで、本記事ではREADME.mdを参考に導入から学習、推論までを一通り動作させる手順を備忘録的にまとめる。
環境
- EVO-X2(Ryzen AI MAx+395, 128GB)

🐔@EVO-X2:~$ amd-smi
+------------------------------------------------------------------------------+
| AMD-SMI 26.0.2+39589fda amdgpu version: 6.12.12 ROCm version: 7.0.2 |
| Platform: Linux Baremetal |
|-------------------------------------+----------------------------------------|
| BDF GPU-Name | Mem-Uti Temp UEC Power-Usage |
| GPU HIP-ID OAM-ID Partition-Mode | GFX-Uti Fan Mem-Usage |
|=====================================+========================================|
| 0000:c6:00.0 AMD Radeon Graphics | N/A N/A 0 N/A/0 W |
| 0 0 N/A N/A | N/A N/A 433/512 MB |
+-------------------------------------+----------------------------------------+
+------------------------------------------------------------------------------+
| Processes: |
| GPU PID Process Name GTT_MEM VRAM_MEM MEM_USAGE CU % |
|==============================================================================|
| No running processes found |
+------------------------------------------------------------------------------+
導入
$ git clone https://github.com/kyuz0/amd-strix-halo-llm-finetuning.git
Cloning into 'amd-strix-halo-llm-finetuning'...
remote: Enumerating objects: 13, done.
remote: Counting objects: 100% (13/13), done.
remote: Compressing objects: 100% (13/13), done.
remote: Total 13 (delta 0), reused 13 (delta 0), pack-reused 0 (from 0)
Receiving objects: 100% (13/13), 18.01 KiB | 3.60 MiB/s, done.
$ toolbox create strix-halo-llm-finetuning \
--image docker.io/kyuz0/amd-strix-halo-llm-finetuning:latest \
-- --device /dev/dri --device /dev/kfd \
--group-add video --group-add render --security-opt seccomp=unconfined
Image required to create toolbox container.
Download docker.io/kyuz0/amd-strix-halo-llm-finetuning:latest (500MB)? [y/N]: y
Created container: strix-halo-llm-finetuning
Enter with: toolbox enter strix-halo-llm-finetuning
$ toolbox enter strix-halo-llm-finetuning # ツールボックスに入る
███████╗████████╗██████╗ ██╗██╗ ██╗ ██╗ ██╗ █████╗ ██╗ ██████╗
██╔════╝╚══██╔══╝██╔══██╗██║╚██╗██╔╝ ██║ ██║██╔══██╗██║ ██╔═══██╗
███████╗ ██║ ██████╔╝██║ ╚███╔╝ ███████║███████║██║ ██║ ██║
╚════██║ ██║ ██╔══██╗██║ ██╔██╗ ██╔══██║██╔══██║██║ ██║ ██║
███████║ ██║ ██║ ██║██║██╔╝ ██╗ ██║ ██║██║ ██║███████╗╚██████╔╝
╚══════╝ ╚═╝ ╚═╝ ╚═╝╚═╝╚═╝ ╚═╝ ╚═╝ ╚═╝╚═╝ ╚═╝╚══════╝ ╚═════╝
L L M F I N E - T U N I N G
AMD STRIX HALO — LLM Finetuning (gfx1151, ROCm via TheRock)
ROCm nightly: 7.10.0a20251015
Machine: GMKtec NucBox_EVO-X2
GPU : AMD RYZEN AI MAX+ 395 w/ Radeon 8060S
Repo : https://github.com/kyuz0/amd-strix-halo-llm-finetuning
Image : docker.io/kyuz0/amd-strix-halo-llm-finetuning:latest
Quickstart:
- 1. Copy notebooks to home directory → mkdir -p ~/finetuning-workspace; cp -r /opt/workspace/* ~/finetuning-workspace/
- 2. Start Jupyter Lab → jupyter lab --notebook-dir ~/finetuning-workspace/
SSH tip: ssh -L 8888:localhost:8888 user@host
起動
$ mkdir -p ~/finetuning-workspace/
$ cp -r /opt/workspace ~/finetuning-workspace/
$ jupyter lab --notebook-dir ~/finetuning-workspace/
[I 2025-10-20 23:45:36.172 ServerApp] jupyter_lsp | extension was successfully linked.
[I 2025-10-20 23:45:36.174 ServerApp] jupyter_server_terminals | extension was successfully linked.
[I 2025-10-20 23:45:36.177 ServerApp] jupyterlab | extension was successfully linked.
[I 2025-10-20 23:45:36.179 ServerApp] Writing Jupyter server cookie secret to /home/gosrum/.local/share/jupyter/runtime/jupyter_cookie_secret
[I 2025-10-20 23:45:36.307 ServerApp] notebook_shim | extension was successfully linked.
[I 2025-10-20 23:45:36.318 ServerApp] notebook_shim | extension was successfully loaded.
[I 2025-10-20 23:45:36.319 ServerApp] jupyter_lsp | extension was successfully loaded.
[I 2025-10-20 23:45:36.320 ServerApp] jupyter_server_terminals | extension was successfully loaded.
[I 2025-10-20 23:45:36.321 LabApp] JupyterLab extension loaded from /usr/lib/python3.13/site-packages/jupyterlab
[I 2025-10-20 23:45:36.321 LabApp] JupyterLab application directory is /usr/share/jupyter/lab
[I 2025-10-20 23:45:36.322 LabApp] Extension Manager is 'pypi'.
[I 2025-10-20 23:45:36.331 ServerApp] jupyterlab | extension was successfully loaded.
[I 2025-10-20 23:45:36.331 ServerApp] Serving notebooks from local directory: /home/gosrum/finetuning-workspace
[I 2025-10-20 23:45:36.331 ServerApp] Jupyter Server 2.15.0 is running at:
[I 2025-10-20 23:45:36.331 ServerApp] http://localhost:8888/lab?token=3dfd4fb4cb01518e046a74bf1f7c7da62b1edcb533f7ceb7
[I 2025-10-20 23:45:36.331 ServerApp] http://127.0.0.1:8888/lab?token=3dfd4fb4cb01518e046a74bf1f7c7da62b1edcb533f7ceb7
[I 2025-10-20 23:45:36.331 ServerApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[C 2025-10-20 23:45:36.337 ServerApp]
To access the server, open this file in a browser:
file:///home/gosrum/.local/share/jupyter/runtime/jpserver-58308-open.html
Or copy and paste one of these URLs:
http://localhost:8888/lab?token=3dfd4fb4cb01518e046a74bf1f7c7da62b1edcb533f7ceb7
http://127.0.0.1:8888/lab?token=3dfd4fb4cb01518e046a74bf1f7c7da62b1edcb533f7ceb7
gio: file:///home/gosrum/.local/share/jupyter/runtime/jpserver-58308-open.html: Failed to find default application for content type ‘text/plain’
[I 2025-10-20 23:45:36.439 ServerApp] Skipped non-installed server(s): bash-language-server, dockerfile-language-server-nodejs, javascript-typescript-langserver, jedi-language-server, julia-language-server, pyright, python-language-server, python-lsp-server, r-languageserver, sql-language-server, texlab, typescript-language-server, unified-language-server, vscode-css-languageserver-bin, vscode-html-languageserver-bin, vscode-json-languageserver-bin, yaml-language-server
ここまで来たら、Webブラウザ上でhttp://localhost:8888/lab?token=*****にアクセスすることでJupyter Notebookを起動できる。

早速Full Fine-tuningを試す
workspace/gemma-finetuning.ipynbを開く。

そのまま何も考えずに、上から順に実行していくとエラーが出る。これを防ぐためには、右上のSwitch kernelをクリックし、Python (venv)に切り替えるとうまくいくようになる。


引き続き順番にセルを実行していくと、下記のセルでエラーが出る。
model = AutoModelForCausalLM.from_pretrained(
MODEL, dtype="auto", device_map="auto", attn_implementation="eager",
)
tokenizer = AutoTokenizer.from_pretrained(MODEL)
torch_dtype = model.dtype
print(f"Weights footprint: {model.get_memory_footprint()/1e9:.2f} GB")
エラーメッセージを確認すると、GemmaモデルにアクセスするにはGoogleの利用ライセンス弐同意する必要があるとのこと。すでに同意済なのでhuggingfaceのアクセストークン(hf_your_token)を下記のように追加することで、解決できる。

モデルのダウンロード完了後、その下のセルを実行することで学習が開始される。

参考までに、学習中のamdgpu_topの様子はこちら。
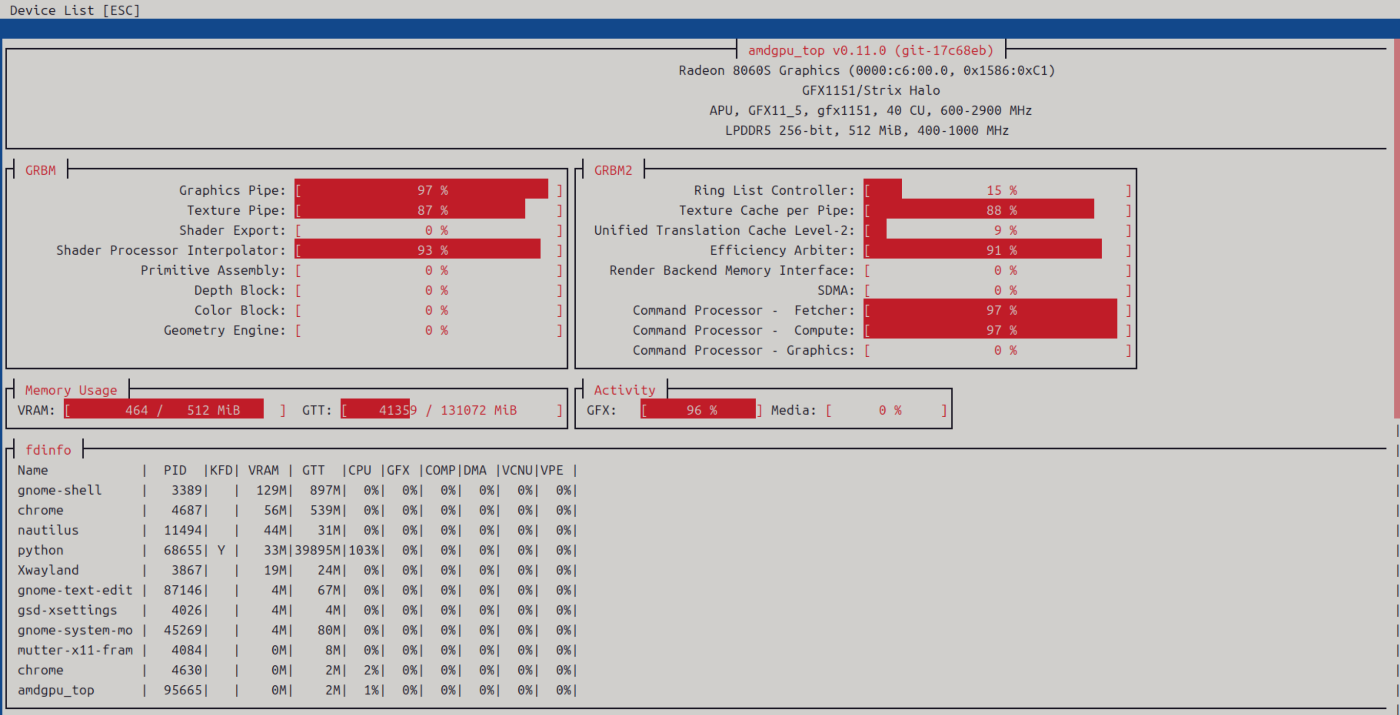
Gemma-3 1B-ITはだいたい3分ぐらいでfull fine-tuningが完了した。
ピークメモリはおよそ19GB。

Inference
notebookの一番下に、得られたモデルの推論を行うためのセルがある。

その他補足
-
動画で紹介されていたが、今のところ unsloth のフレームワークで学習することはできないらしい。
-
本記事ではFull Fine-tuningの方法だけを示したが、LoRAやQLoRAの作成にも対応しているらしい。
- 下記に示すとおり、gpt-oss-20BはLoRAなら作れるようだ。
Performance on Strix Halo
Strix Haloでの事後学習に必要なVRAMと時間の目安を下記に示す。
128GBの場合、フルファインチューニングは12Bが限界のようだ。
| Model | Full FT | LoRA | 8-bit + LoRA | QLoRA |
|---|---|---|---|---|
| Gemma-3 1B-IT | 19 GB / 2m52s | 15 GB / 2m | 13 GB / 8m | 13 GB / 9m |
| Gemma-3 4B-IT | 46 GB / 9m | 30 GB / 5m | 21 GB / 41m | 13 GB / 9m |
| Gemma-3 12B-IT | 115 GB / 25m | 67 GB / 13m | 43 GB / 2h38m | 26 GB / 23m |
| Gemma-3 27B-IT | OOM | OOM | 32 GB unstable | 19 GB runs |
| GPT-OSS-20B (MXFP4) | - | 32-38 GB / ~1h | - | - |
- ソース
まとめ
本記事では、Donato Capitellaさんが整備されたamd-strix-halo-llm-finetuningおよび動画を参考に、Strix HaloでローカルLLMをfull fine-tuningする方法についてまとめ、EVO-X2で動作することを確認した。
実を言うと事後学習自体ほぼはじめての経験で、今回の紹介動画等を参考にしつつ事後学習の数学的な意味について今後理解していきたい。また、トレーニングデータを変えたり、12BモデルでもFTしたモデルを作成してみたい。
Discussion