【自然言語処理】BERTを使って歌詞をベクトルに変換し可視化する
自然言語処理モデルの王様と言われるBERTを使って、文章をベクトルに変換し可視化しましたので、それらのタスクについて示したいと思います。
これは 「BERTによる自然言語処理入門」 を参考にしたものですが、本では、livedoorのニュースコーパスが用いられていました。
ここでは、文章コーパスとして、女性シンガー(後述)の歌詞を使ってみたいと思います。
ライブラリーのインストール
BERTが格納されているtransformersのほか、matplotlibで日本語を可視化するためにjapanize_matplotlibもインストールしておきます
!pip install transformers==4.18.0 fugashi==1.1.0 ipadic==1.0.0
!pip install japanize_matplotlib
ライブラリーのインポート
import pandas as pd
import numpy as np
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
import japanize_matplotlib
%matplotlib inline
from transformers import BertJapaneseTokenizer, BertModel
歌詞データの準備
90年代〜最近まで自分が知っている女性シンガーの歌詞を集めました。
歌詞は歌ネットで収集します。
可視化のため、収集した歌詞には女性シンガーごとにラベルを振っておきます。
labels = {
'ZARD':0,
"大黒摩季":1,
"森高千里":2,
"椎名林檎":3,
"竹内まりや":4,
"DREAMS COME TRUE":5,
"宇多田ヒカル":6,
"ヨルシカ":7,
"あいみょん":8,
}
df = pd.read_csv("/content/woman_singer.csv",index_col=0).reset_index()
df
次のようなデータフレームを準備します。

歌ネットからの歌詞の収集方法は以下を参考にしてください。
歌詞のベクトルを計算
BERTを使って歌詞の文章ベクトルを計算します。
# BERTの日本語モデル
MODEL_NAME = 'cl-tohoku/bert-base-japanese-whole-word-masking'
#トークナイザとモデルのロード
tokenizer = BertJapaneseTokenizer.from_pretrained(MODEL_NAME)
model = BertModel.from_pretrained(MODEL_NAME)
model = model.cuda()
#各データの形式を整える
max_length = 256
sentence_vectors = []
labels = []
for i in range(len(df)):
# 記事から文章を抜き出し符号化を行う
lines = df.iloc[i,3].splitlines()
text = '\n'.join(lines)
encoding = tokenizer(
text,
max_length = max_length,
padding = 'max_length',
truncation = True,
return_tensors = 'pt'
)
encoding = {k: v.cuda() for k, v in encoding.items()}
attention_mask = encoding['attention_mask']
#文章ベクトルを計算
with torch.no_grad():
output = model(**encoding)
last_hidden_state = output.last_hidden_state
averaged_hidden_state =(last_hidden_state*attention_mask.unsqueeze(-1)).sum(1)/attention_mask.sum(1,keepdim=True)
#文章ベクトルとラベルを追加
sentence_vectors.append(averaged_hidden_state[0].cpu().numpy())
label = df.iloc[i,4]
labels.append(label)
#ベクトルとラベルをnumpy.ndarrayにする
sentence_vectors = np.vstack(sentence_vectors)
labels = np.array(labels)
ベクトルを見てみましょう。
sentence_vectors
出力すると、ちゃんとベクトルが生成できています。768次元あります。
array([[-0.05504537, -0.3744683 , -0.12116772, ..., -0.10191287,
-0.15372512, 0.00349309],
[-0.10901713, -0.3256916 , -0.142499 , ..., -0.172201 ,
0.1680747 , 0.0964032 ],
[ 0.10289921, -0.46415925, -0.04539696, ..., -0.21635422,
-0.04837012, -0.10104564],
...,
[-0.08404515, -0.05391428, -0.02695145, ..., -0.03524649,
0.10951725, 0.05520493],
[-0.4034347 , -0.21451093, -0.4215728 , ..., -0.23189199,
-0.01386215, -0.07891154],
[-0.14517964, -0.36689 , -0.17635193, ..., -0.08171394,
0.11400361, 0.01895481]], dtype=float32)
t-SNEによる可視化
歌詞の文章ベクトルがどのように分布しているのか可視化します。
BERTが出力した文章ベクトルは768次元あり、人間が直感的に理解することは不可能です。そこで、高次元のベクトルを低次元の空間にマッピングすることを考えます。
そのための手法として、t-SNEを使います。
t-SNEは機械学習ライブラリーのscikit-learnで利用可能です。
t-SNEを使って、2次元に変換します。
sentence_vectors_tsne = TSNE(n_components=2).fit_transform(sentence_vectors)
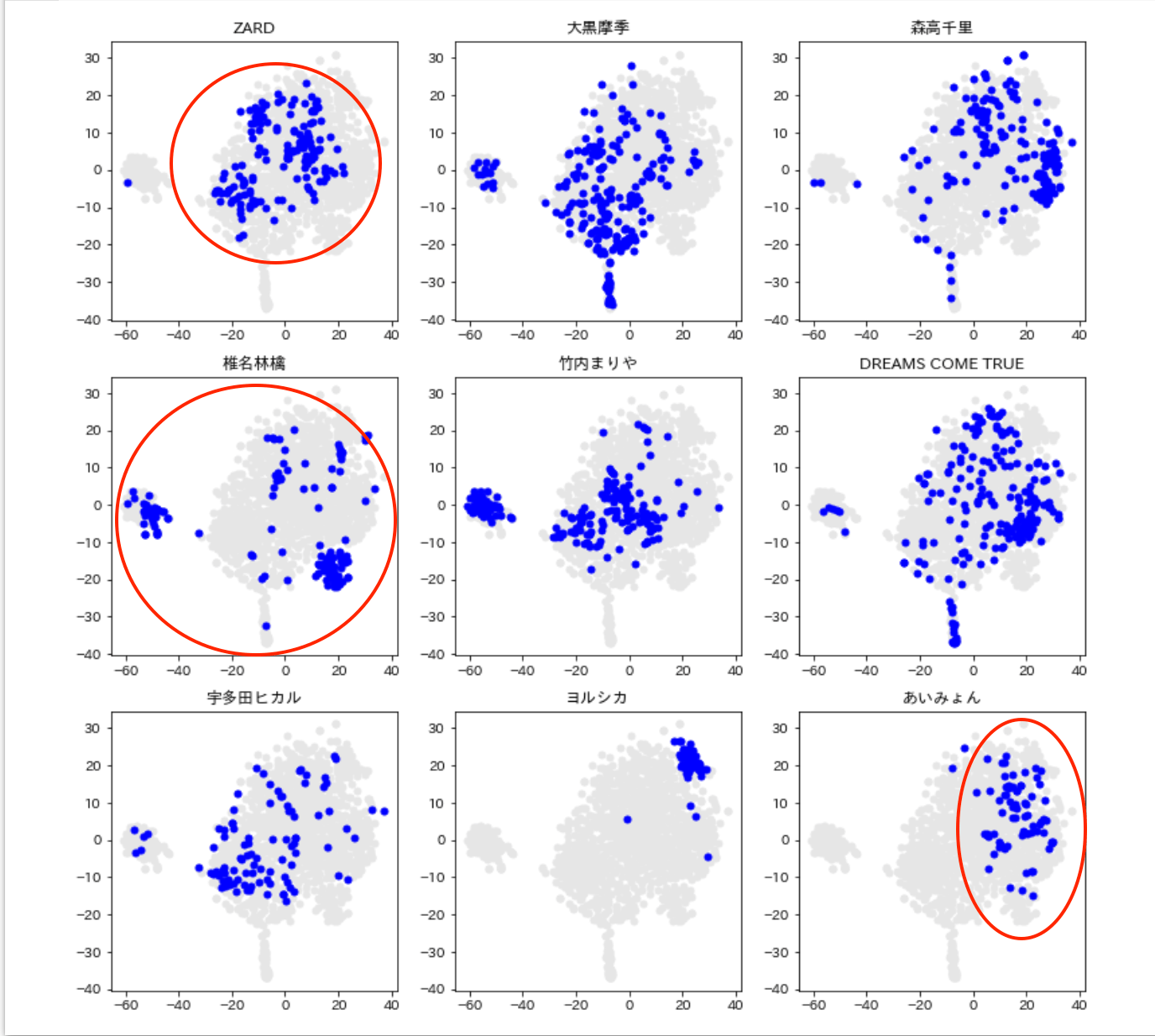
女性シンガーごとに歌詞を可視化
matoplotlibを使って、9人の女性シンガーの歌詞を可視化します。
list =[ 'ZARD',"大黒摩季","森高千里","椎名林檎","竹内まりや","DREAMS COME TRUE","宇多田ヒカル","ヨルシカ","あいみょん"]
plt.figure(figsize=(13,13))
for label in range(9):
plt.subplot(3, 3 , label +1)
index = labels ==label
plt.plot(
sentence_vectors_tsne[:, 0],
sentence_vectors_tsne[:, 1],
'o',
markersize = 5,
color = [0.9,0.9,0.9]
)
plt.plot(
sentence_vectors_tsne[index,0],
sentence_vectors_tsne[index,1],
'o',
markersize = 5,
color ='b'
)
plt.title(list[label])
青丸が女性シンガーごとの歌詞の分布をプロットしたものになります。
ZARDは割とまとまっていますね。
椎名林檎はバラついています。
あいみょんやヨルシカは極端に寄っている感じがします。
類似の歌詞検索する
歌詞をベクトルにすることで、歌詞と歌詞の類似度を計算することができます。
コサイン類似度を使って、類似の歌詞を検索してみましょう。
#先にノルムを1にしておく
norm = np.linalg.norm(sentence_vectors,axis=1, keepdims=True)
sentence_vectors_normalized = sentence_vectors/norm
#類似度行列を計算する
#類似度行列の(i,j)要素はi番目の歌詞とj番目の歌詞の類似度を表している
sim_matrix = sentence_vectors_normalized.dot(sentence_vectors_normalized.T)
#入力と同じ行列が出力されることを避けるため、類似度行列の対角要素の値を小さくしておく
np.fill_diagonal(sim_matrix, -1)
#類似度が高い歌詞のインデックスを得る
similar_songs = sim_matrix.argmax(axis=1)
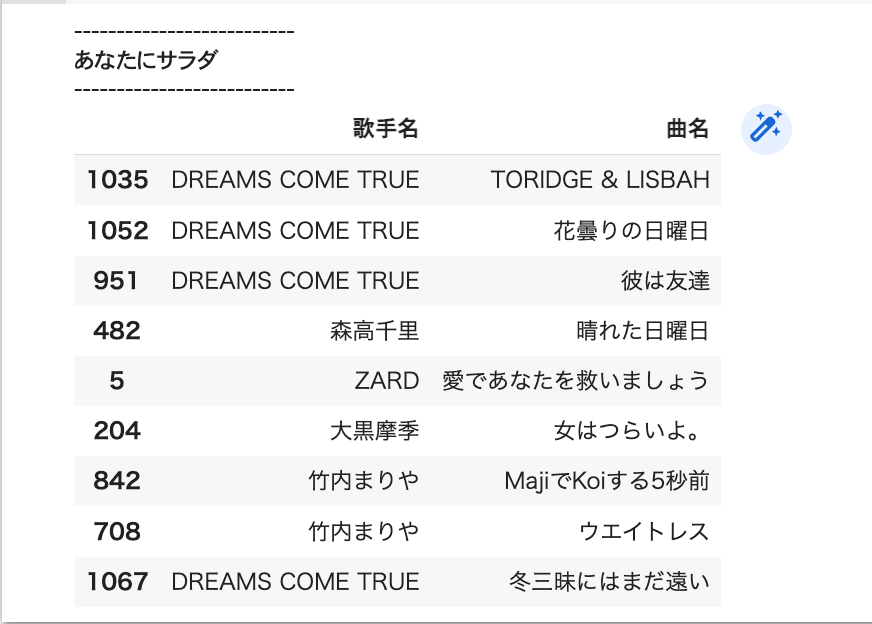
以下では、ドリカムの「あなたにサラダ」に類似している歌詞を検索しています。
どうでしょうか。
target =899
print("--------------------------")
print(df.iloc[target,2])
print("--------------------------")
top_index = np.argsort(sim_matrix[target])[::-1]
df.loc[top_index[1:10],["歌手名","曲名"]]
さいごに
いかがでしたでしょうか。文章を数値化することで、今まで感覚的にしか捉えられなかったものが、客観的に評価できるようになりますね。
文章ベクトルについては、定番のDoc2Vecがありますので、次回はそちらも試してみたいと思います。
Discussion
この部分は何をしている箇所なのでしょうか?教えていただけると幸いです。
きなこもちさん
コメントありがとうございます!
このコードの該当の行では、モデルの出力を平均化する操作が行われています。
具体的には、
last_hidden_state*attention_mask.unsqueeze(-1): ここで、last_hidden_state (各単語に対するBERTモデルの出力ベクトル) と attention_mask を要素ごとに掛け算しています。
attention_mask は入力文章の実際の単語位置を1、パディング部分を0で示すマスクで、unsqueeze(-1)操作により次元を追加しています。この操作により、パディング部分(不要な部分)のベクトルが0になります。
.sum(1): 次に、各単語のベクトルを合計します。この操作により、各入力文章に対して一つのベクトルが生成されます。
/attention_mask.sum(1,keepdim=True): 最後に、単語数(パディング部分を除く)でベクトルの合計を割ります。これにより、各単語のベクトルの平均が求められます。
つまり、このコードは各入力文章に対して、単語のベクトルの平均を求めています。
ただし、パディング部分は考慮されず、実際の単語のみが考慮されます。これにより、文章の長さに依存しない固定長のベクトル(文書ベクトル)が生成されます。