【GoogleColaboratory】歌ネット(Uta-Net)から歌詞をスクレイピングする
好きな歌手の歌詞を分析したくて、歌ネット(Uta-Net) 歌詞をスクレイピングしました。
同種のネット記事はいくつかあって、それらをコピペすれば簡単にできるかと思っていましたが、歌ネット側に仕様変更があったみたいで、うまくいきませんでした。
いろいろ調べて、GoogleColaboratoryから直接、歌詞をスクレイピングすることに成功しましたので、その方法をご紹介したいと思います。
準備1:UserAgentを取得する
GoogleColaboratoryからrequestsモジュールを使って、歌ネットのURL情報を取得しようとすると、EUの個人情報規則(GDPR) に関連したURLの情報が返ってきてしまい、指定したURL情報を取得できない場合があります。
原因はよく分かりませんが、HTTPリスクエストヘッダーのUserAgentを正しく設定することで、この問題は解決できます。
以下のサイトにアクセすることでUserAgentを取得することができます(赤囲み部分)
IPアドレスとユーザーエージェントの確認
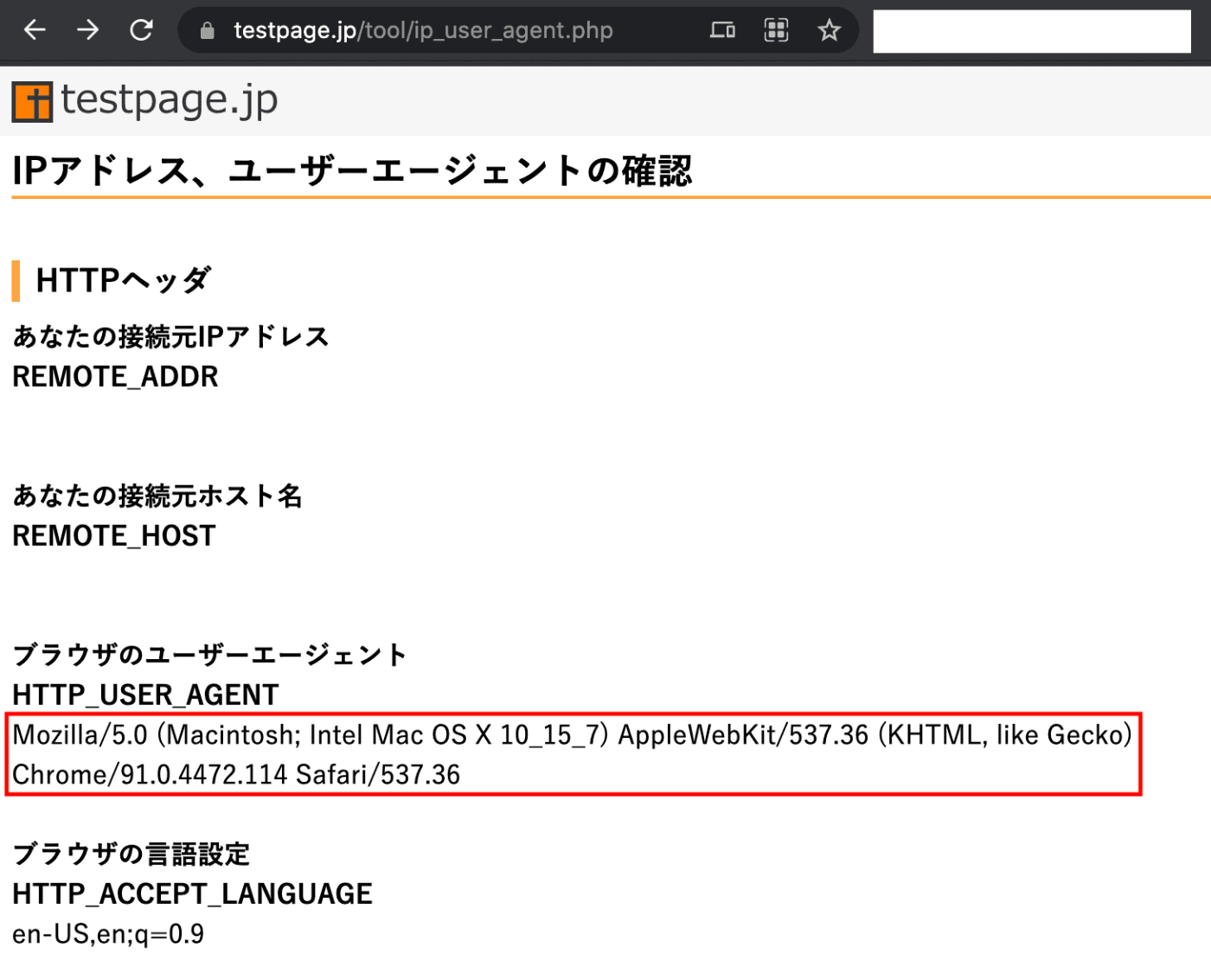
準備2:URLを取得する
次に、好きな歌手の歌詞一覧がリストになっているURLを取得します。
歌ネットの上部検索バーに歌手名を入力すると、検索結果として歌詞一覧が返ってきます。
そのURLを取得します。
例として、私の好きなぷにぷに電機のURL https://www.uta-net.com/artist/29348/ を取得します
ライブラリのインポート
まずは必要なライブラリをインポートします。
扱いやすいBeautifulSoupを使います。
import requests
from bs4 import BeautifulSoup
import pandas as pd
import time
曲名と歌詞を格納するデータフレームを用意
list_df = pd.DataFrame(columns=['曲名','歌詞'])
スクレイピングして歌詞情報を取得する
#歌ネットのurlをbase_urlに入力します
base_url = 'https://www.uta-net.com'
#urlに先ほど取得した歌詞一覧のURLを入力します
url = 'https://www.uta-net.com/artist/29348/'
#usr_agentに先ほど取得したUserAgent情報を入力します
user_agent = 'ここに、先ほど取得した赤囲みの情報を入力します'
header = {'User-Agent': user_agent}
response = requests.get(url,headers=header)
soup = Beautifu=lSoup(response.text, 'lxml')
#引数として、class_='sp-w-100'を与えます
links = soup.find_all('td', class_='sp-w-100')
#歌詞情報を取得します
for link in links:
a = base_url + (link.a.get('href'))
response = requests.get(a)
soup = BeautifulSoup(response.text, 'lxml')
song_name = soup.find('h2').text
song_kashi = soup.find('div', id="kashi_area")
song_kashi = song_kashi.text
time.sleep(1)
tmp_se = pd.DataFrame([[song_name], [song_kashi]]
index=list_df.columns).T
list_df = list_df.append(tmp_se)
データフレームを確認します
ちゃんととれていますね。

さいごに
これで歌詞の自然言語処理ができそうです。
「歌ネット スクレイピング」でググっても、ヒットする記事が少なくて苦労しました。同じことをされようとしている方の参考になればと思います。
参考にした記事
1つめの記事は、コードの内容も分かりやすく、参考になりました。
Discussion