【TF-IDF】Adoの「過学習」はどのあたりが過学習なのか?
過学習。機械学習やディープラーニングが世の中に広まる中、この言葉の認知度が増してきたところですが、Adoが「過学習」をリリースしたことで一気に市民権を得た感じがします。
一方で、この「過学習」の歌詞。 ざっと読んでみても、どのあたりが過学習なのか、よく分かりません。
そこで、今回は、自然言語処理の基本的技術の一つTF-IDFを使って何が過学習なのかを突き止めたいと思います。
TF-IDFとは
ざっくり言うと、その文書を特徴づける重要な単語を抽出する手法になります。
以下のように、単語の出現頻度とレア度の積で表されます。単語の出現頻度が高く、かつ、他の文章にはあまり出てこない単語が重要とみなされます。
TFとIDFを式で表すと以下のとおりです。
それではやっていきましょう!
Adoの歌詞全曲のテキストデータを取得
TF-IDFでは、ある文書に現れる単語のレア度を考慮します。レア度は他の文書、つまり、ここでは他の歌詞との比較で計算できるものですので、「過学習」も含め、歌詞全曲のテキストデータを取得する必要があります。
歌ネットをスクレイピングすることでAdoの歌詞データを取得します。
具体的な方法は以下の記事でご紹介しています。
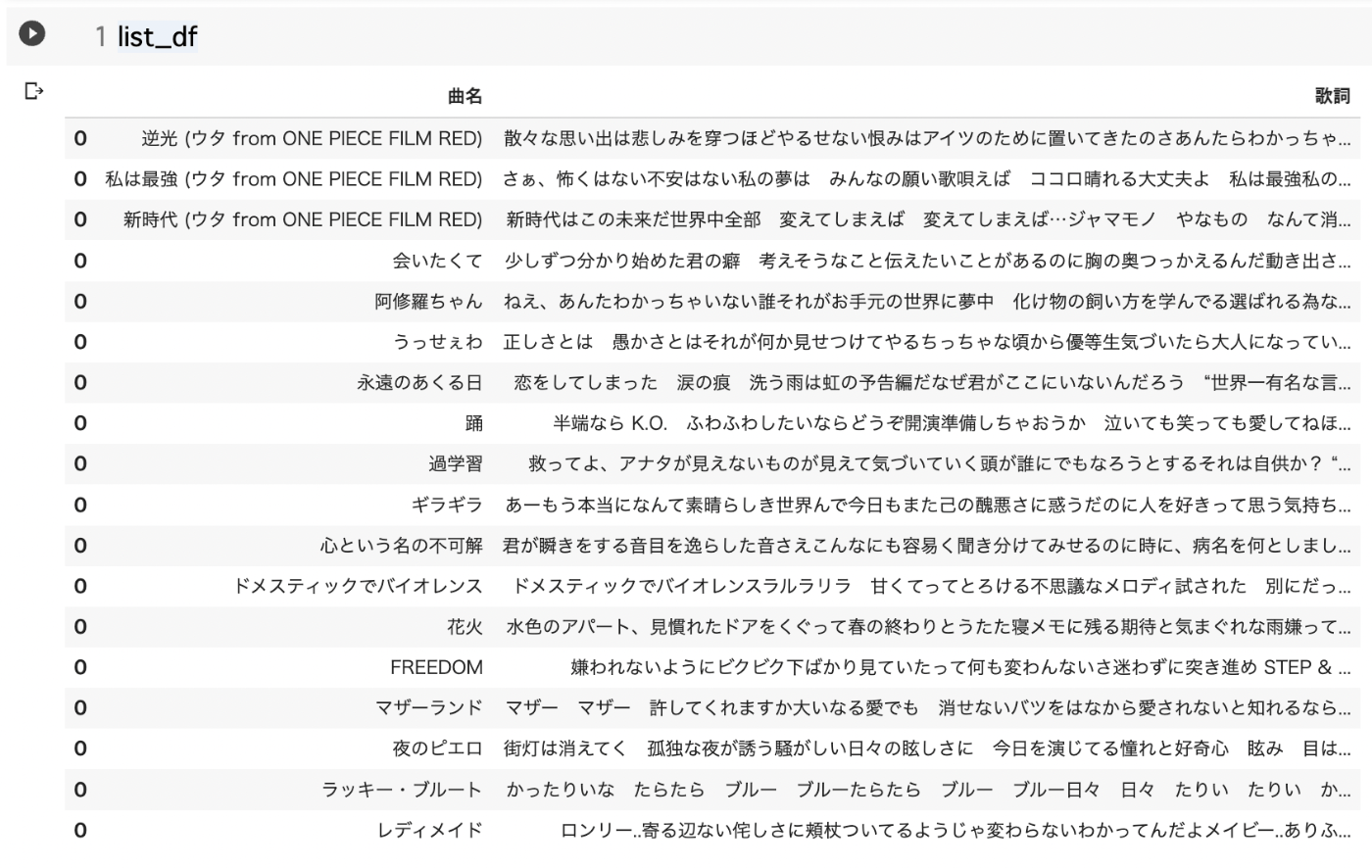
歌詞一覧のURL'https://www.uta-net.com/artist/29298/' にしてください。
曲名と歌詞をlist_dfに格納します。
形態素解析
単語の重要度を考慮するためには、まず、文書を単語にわける必要があります。この作業を形態素解析と呼びます。
MeCabのインポート
ここではMeCabというライブラリーを使って形態素解析を行います。
必要なライブラリー群をインストールし、MeCabをインポートします。
!apt install aptitude
!aptitude install mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file -y
!pip install mecab-python3==0.7
import MeCab
MeCab.Tagger()
MeCabを使用する場合、形態素解析のための辞書をMeCab.Tagger()の引数で指定します。
今回はChasen互換を使います。
parse("")はUnicodeDecodeErrorを避けるためのおまじないです
tokenizer = MeCab.Tagger("-Ochasen")
tokenizer.parse("")
テキストの中から名詞を抽出する関数の作成
テキストデータの形態素解析を行なって名詞だけを抽出する関数を作ります。
def extract(text):
words = []
# 単語の特徴リストを生成
node = tokenizer.parseToNode(text)
while node:
# 品詞情報(node.feature)が名詞ならば
if node.feature.split(",")[0] == u"名詞":
# 単語(node.surface)をwordsに追加
words.append(node.surface)
node = node.next
# 半角スペース区切りで文字列を結合
text_result = ' '.join(words)
return text_result
形態素解析の実行
list_dfに入っている歌詞をfor文でひとつずつ取り出し、extract関数で形態素解析を行なって、docsリストに格納していきます。
docs = []
for i in range(len(list_df)):
text = list_df.iloc[i,1]
text = extract(text)
docs.append(text)
docs
TF-IDF
モデルのインポート
scikit-learnからTF-IDFを行うモデルTfidfVectorizerをインポートします
from sklearn.feature_extraction.text import TfidfVectorizer
モデルのインスタンス化と実行
モデルをインスタンス化し、歌詞全曲を格納したdocsを入れて実行します。
その後、分かりやすいようにPandasのデータフレームにおとします。
#モデルのインスタンス化と実行
vectorizer = TfidfVectorizer(smooth_idf=False)
X = vectorizer.fit_transform(docs)
# Pandasのデータフレームにする
values = X.toarray()
feature_names = vectorizer.get_feature_names()
index = list_df['曲名']
tfidf_df = pd.DataFrame(values, columns = feature_names,
index=index)
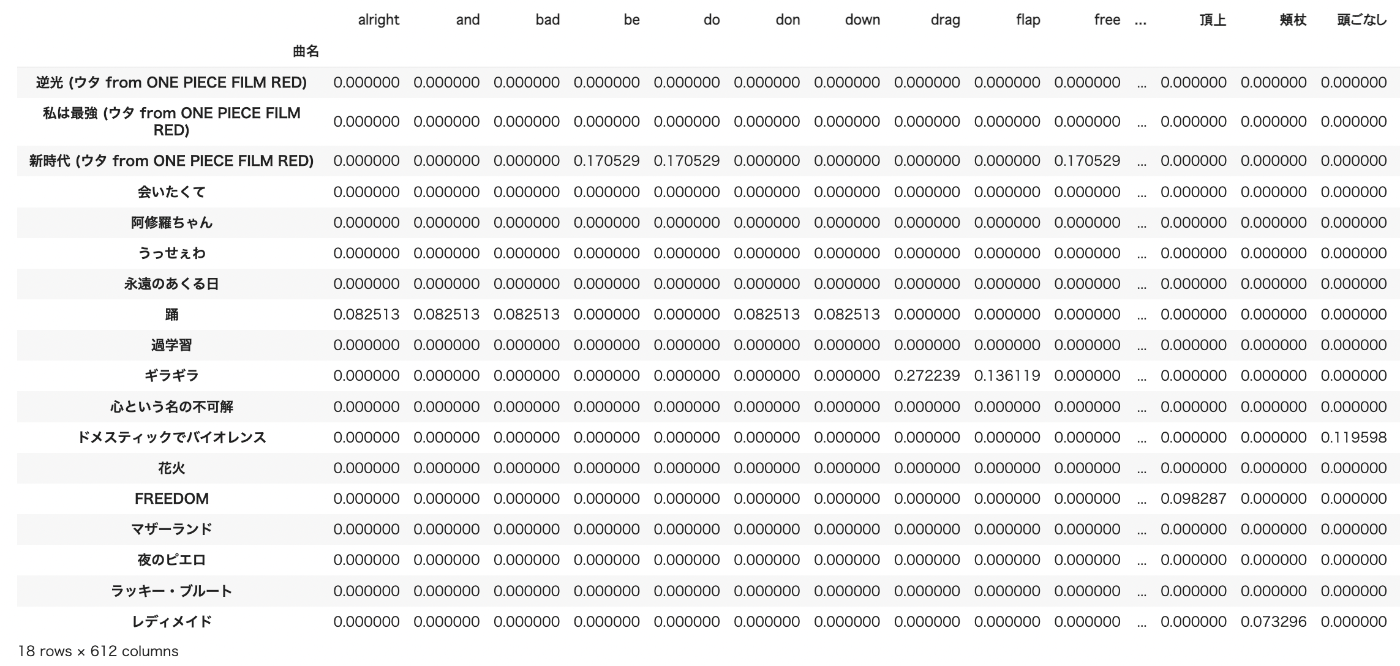
tfidf_df
インデックスに曲名、カラムにwordが並ぶデータフレームが作成できました。18曲で612のwordを抽出しています。その曲にそのwordがない場合は0が表示されます。
全曲の重要語
曲ごとに重要なword上位10個を抽出し、比較しやすいように転置します。
df_n = pd.DataFrame()
for i in range(len(list_df)):
df_i = tfidf_df[i:i+1].T.sort_values(index.values[i],ascending=False).head(10)
df_i = df_i.rename_axis('word').reset_index()
df_n = pd.concat([df_n,df_i],axis=1)
df_n
横に曲ごとの重要語(word)と点数が並んでいきます。
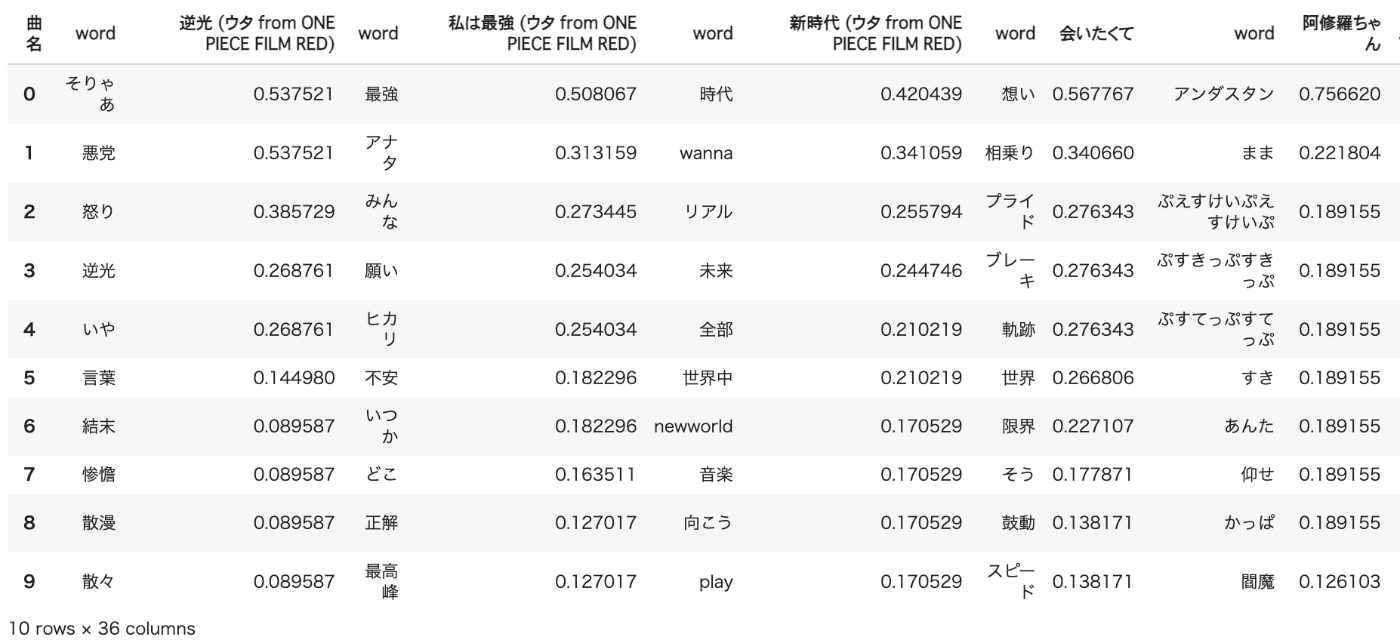
過学習の重要語
df_n = pd.DataFrame()
i =8
df_i = tfidf_df[i:i+1].T.sort_values(index.values[i],ascending=False).head(10)
df_i = df_i.rename_axis('word').reset_index()
df_n = pd.concat([df_n,df_i],axis=1)
df_n
「アナタ」を過学習していたということですね。。。(強引)

さいごに
Adoの過学習が何を過学習していたのかは正直、謎のままですが、TF-IDFについては、少しはイメージがお分かりいただけたかと思います。
TF-IDFはどんな教科書にも書いてある基本的技術です。理論的な根拠があるというより、人間が経験的に重要と感じていることを式に表したものです。必ずしも正しい重要度を表してるわけではありませんが、ある程度、人間の直観に沿っていると言えるでしょう。
Discussion