chiselでスーパスカラを実装 その2
はじめに
現在chiselを使って仮想CPUを自作しており、スーパスカラ実行に挑戦しています。
前回IDステージまで並列化したので、今回はEXステージを並列化します。
全体の構成
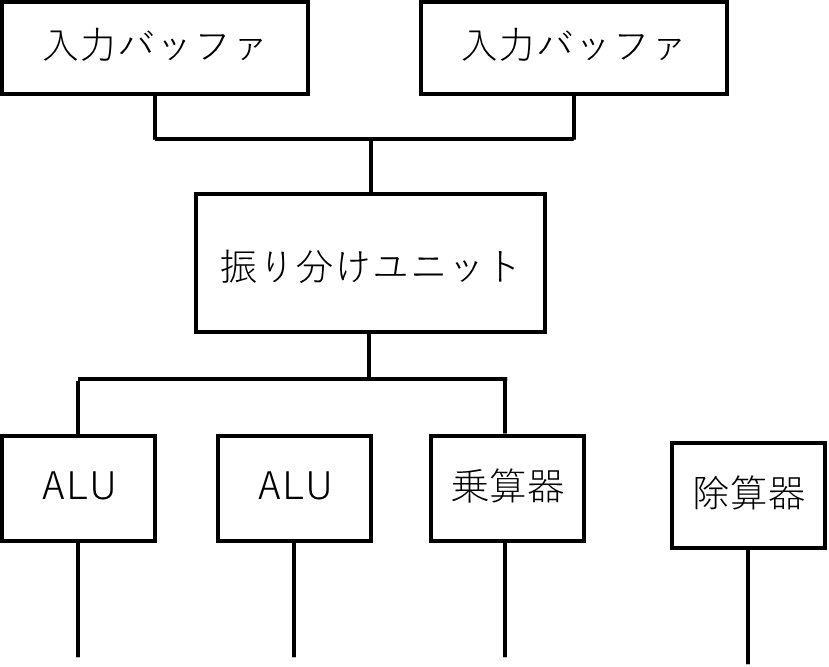
ハードウェア構成
- 入力バッファ
- 2つのバッファが存在
- Decoderステージの出力が格納される
- 指令振り分けユニット
- 入力バッファから指令(と関連データ)を取り出し
- 適切な実行ユニットを決定
- 当該ユニットの入力バッファにデータを格納
- 実行ユニット
- ALU x2、乗算器、除算器
- 各々が入力バッファを備える
- 出力
- 4つ(実行ユニット数)分のポートが存在
- 後続のMEMユニットの入力バッファに接続される
これらのユニットをひとまとめにしたEXUnitMgrを定義します。
パイプライン構成
上記を3サイクルで実行します。
サイクル1:入力バッファからデータを受け取り
サイクル2:実行ユニットを決定
サイクル3:演算

1. 入力バッファ
Decoderユニットがデコードした結果を格納します。指令振り分けユニット
がここからデータを取っていきます。
1度に同時取得するデータ数(今は2)分のバッファを用意します。
Decoder段階では2指令分が1つの変数に結合されているので、分解して各バッファに入力します。
最初の指令が到達したらバッファへの入力を有効にします。
val idexBufs = Seq.fill(FETCH_NUM)(
Module(new Queue(gen = new EXInSignals, entries = INST_BUF_DEPTH)))
// FETCH_NUM=2, INST_BUF_DEPTH=4
Seq.tabulate(FETCH_NUM){
i => decAfterHzResolvers(i).addToBuf(idexBufs(i)) // decAfterHzResolvers: Decoderの最終段
val nInst = extractNthWord(id_reg_inst, i) //指令を分離
val startEnq = Mux(nInst > 0.U, true.B, false.B)
idexBufs(i).io.enq.valid := startEnq & !stall_flag
idexBufs(i).io.deq.ready := true.B
}

2. 指令振り分けユニット
今回の構成では入力が2指令に対して、使用可能な実行ユニットが4つ(ALU2つ、乗算器と除算器が各1つ)あります。
指令の内容に応じて適切なユニットを選びます。例えば指令がaddならばALUを、mulなら乗算器を選択します。

出力
2つの指令に対し、「どの実行ユニットで実行するか」を表すタグを付与して出力します。
class CmndRouter extends Module {
val io = IO(new Bundle {
val inputs = Input(Vec(FETCH_NUM, new EXInSignals))
// EXInSignalsが実行ユニットで使用する指令およびデータ
val outUnitInfs = Input(Vec(ALU_NUM, new EXUnitInf))
val results = Output(Vec(FETCH_NUM, new EXRouterOut))
})
…
}
class EXRouterOut extends Bundle {
val signal = new EXInSignals
val unitName = UInt(WORD_LEN.W)
}
EXUnitMgrが、このタグを見て対応するユニットの入力バッファに格納します。
//指令振り分けユニット
val cmndRouter = Module(new CmndRouter())
...
//実行ユニット一覧とその入力バッファ一覧
val units:Seq[EXUnitBase] = Seq(Module(new ALU(2)), Module(new ALU(2)), Module(new Multiplyer(4)), Module(new Divider(4)))
val unitBufs = Seq.fill(EX_UNIT_NUM)(Module(new Queue(gen = new EXInSignals, entries = INST_BUF_DEPTH)))
//実行ユニットに指令を入力
Seq.tabulate(EX_UNIT_NUM){
i => {
io.results(i) := units(i).io.result
Seq.tabulate(FETCH_NUM){
j => {
val unitIdx = cmndRouter.io.results(j).unitName
when(unitIdx === i.U){
unitBufs(i).io.enq.bits := cmndRouter.io.results(j).signal
unitBufs(i).io.enq.valid := true.B
}
}
}
}
}
振り分けロジック
指令の振り分けは以下のようなロジックで行います。
2.a 指令が乗算(mul, mulhなど)の場合は乗算器を、除算(div, divuなど)の場合は除算器を選択
2. b 指令がALUを用いるものの場合(現状は乗算、除算以外)、i番目の指令をi番目のALUに接続(i=1, 2)(ALUの順番は任意)
※2.bについて、本当は各ALUのバッファの空き具合を見て少ない方を選択ということをしたいですが、これを1サイクルでやろうとしたら苦戦しました。とりあえず将来の宿題として今は指令の順番とALUの対応を決め打ちしてしまいます。
コードは以下のようになります。
「同一の複数ユニットに対する指令の振り分けを決めるユニット」であるUnitDeciderを定義します。入力にALU指令があればこれに入力します。
将来的にはここに※のロジックを実装したいです。今は決められた順番で指令をALUに繋ぐだけです。
Seq.tabulate(FETCH_NUM) { i =>
val exe_fun = io.inputs(i).exe_fun
switch(exe_fun){
is(ALU_MUL, ALU_MULH, ALU_MULHSU, ALU_MULHU){
io.results(i).unitName := MUL_IDX
}
is(ALU_DIV, ALU_DIVU, ALU_REM, ALU_REMU){
io.results(i).unitName := DIV_IDX
}
is(ALU_ADD, ALU_SUB, ALU_AND, ALU_OR, ALU_XOR, ALU_SLL, ALU_SRL, ALU_SRA, ALU_SLT, ALU_SLTU, ALU_JALR, ALU_COPY1){
isAlu(i) := true.B
}
}
io.results(i).signal <> io.inputs(i)
}
unitDecider.io.unitInfs := io.outUnitInfs
unitDecider.io.isValids := isAlu
unitDecider.io.start := true.B
class UnitDecider(sigNum: Int, unitNum: Int) extends Module {
val io = IO(new Bundle {
val pc = Input(Vec(sigNum, UInt(WORD_LEN.W)))
val unitInfs = Input(Vec(unitNum, new EXUnitInf))
val isValids = Input(Vec(sigNum, Bool()))
val start = Input(Bool())
val done = Output(Bool())
val results = Output(Vec(sigNum, new UnitDeciderOut))
})
for (cmdIdx <- 0 until sigNum) {
io.results(cmdIdx).pc := io.pc(cmdIdx)
io.results(cmdIdx).unitName := sigNum.U
when(io.isValids(cmdIdx)) {
io.results(cmdIdx).unitName := cmdIdx.U
}
}
io.done := true.B
}
3. 実行ユニット
各実行ユニットは以下の構成です。
- 入力バッファ
- 実行部
実行部での実行が完了すると、入力バッファから新しい指令を取り出します。
このあたりのロジック、実装は以前詳しく書いたのでそちらをご参照ください。
テスト
EXUnitMgrをテストしてみます。
"result" should "be correct for 2 ALU" in {
test(new EXUnitMgr){ mgr =>
mgr.io.inputs(0).pc.poke(0)
mgr.io.inputs(0).exe_fun.poke(ALU_ADD)
mgr.io.inputs(0).op1_data.poke(1.U)
mgr.io.inputs(0).op2_data.poke(2.U)
mgr.io.inputs(1).pc.poke(8)
mgr.io.inputs(1).exe_fun.poke(ALU_ADD)
mgr.io.inputs(1).op1_data.poke(2.U)
mgr.io.inputs(1).op2_data.poke(3.U)
mgr.clock.step(1)
//EXUnitMgrの内部に指令がいく
mgr.clock.step(1)
//実行ユニットのバッファからdeqされる
mgr.clock.step(1)
//実行ユニットで演算が終わる
mgr.io.results(ALU1_IDX).execState.execComplete.expect(true.B)
mgr.io.results(ALU1_IDX).pc.expect(0)
mgr.io.results(ALU1_IDX).alu_out.expect(3)
mgr.io.results(ALU2_IDX).execState.execComplete.expect(true.B)
mgr.io.results(ALU2_IDX).pc.expect(8)
mgr.io.results(ALU2_IDX).alu_out.expect(5)
}
}
"result" should "be correct for ALU and MUL" in {
test(new EXUnitMgr){ mgr =>
mgr.io.inputs(0).pc.poke(0)
mgr.io.inputs(0).exe_fun.poke(ALU_ADD)
mgr.io.inputs(0).op1_data.poke(1.U)
mgr.io.inputs(0).op2_data.poke(2.U)
mgr.io.inputs(1).pc.poke(8)
mgr.io.inputs(1).exe_fun.poke(ALU_MUL)
mgr.io.inputs(1).op1_data.poke(2.U)
mgr.io.inputs(1).op2_data.poke(3.U)
mgr.clock.step(1)
//EXUnitMgrの内部に指令がいく
mgr.clock.step(1)
//実行ユニットのバッファからdeqされる
mgr.clock.step(1)
//ALUで演算が終わる
mgr.io.results(ALU1_IDX).pc.expect(0)
mgr.io.results(ALU1_IDX).alu_out.expect(3)
mgr.clock.step(1)
mgr.clock.step(1)
//MULで演算が終わる
mgr.io.results(MUL_IDX).pc.expect(8)
mgr.io.results(MUL_IDX).mul_out.expect(6)
}
}
}
1つ目のテストは両方がALU演算(1+2、2+3)の場合、2つ目はALU演算(2*3)の場合です。
それぞれ実行結果が正しいこと、適切なサイクル数で実行される(ALUは2サイクル、乗算器は4サイクルかかる設定にしています)ことが確認できます。
今後の展望
まずは後続のMEM、WBステージを並列化して一通りスーパスカラ実行を動作させたいです。
また、途中にも書いたように実行ユニットを振り分ける部分はかなり簡略化しているので、ここも効率化していきたいです。
コードは以下に置いてあります。
Discussion