chiselでスーパスカラを実装 その1
はじめに
現在chiselを使って仮想CPUを自作しています。
今回はCPUの機能の一つ、スーパスカラ実行を実装しました。
スーパスカラ実行とは
以下wikipediaからの引用です。
スーパースカラー(superscalar,スーパースケーラ)とは、プロセッサのマイクロアーキテクチャにおける用語で、複数の命令を同時にフェッチし、複数の同種のあるいは異種の実行ユニットを並列に動作させ[1]、プログラムの持つ命令レベルの並列性を利用して性能の向上を図るアーキテクチャである。
これまで各ユニットが1つずつあり、それらが直列に動いていましたが、ユニットの数を増やし、動作を並列化します。
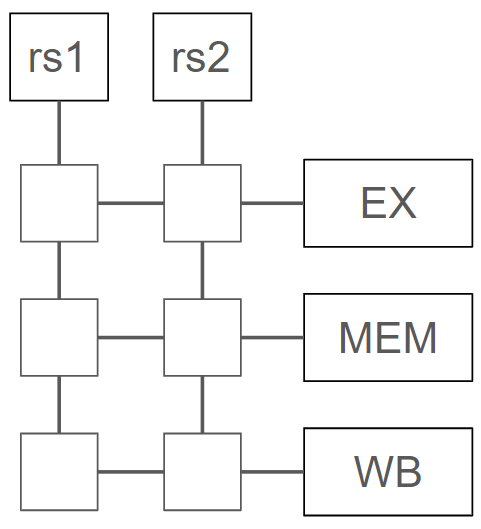
現状の構成
以下のように、coreとmemoryが接続されています。名前の通り、coreがmemoryから指令をフェッチし、各種処理を行います。
class Top extends Module{
val io = IO(
new Bundle{
val exit = Output(Bool())
val gp = Output(UInt(WORD_LEN.W))
}
)
val core = Module(new Core())
val memory = Module(new Memory())
core.io.imem <> memory.io.imem
core.io.dmem <> memory.io.dmem
}
Core内は以下のステージに分かれています。
- IF: 指令をメモリからフェッチ
- ID:フェッチした指令をデコード
- EX:指令を実行
- MEM:処理結果をメモリへ書き込み
- WB:処理結果をレジスタに書き込み
IFステージの並列化
まずはフェッチユニットを2つに増やし、2命令を同時にフェッチできるようにします。
現状の実装
フェッチ部分の実装は以下のようになっています。
class Memory extends Module{
val io = IO(
new Bundle{
val imem = new ImemPortIo()
val dmem = new DmemPortIo()
}
)
io.imem.inst := Cat(
mem(io.imem.addr + 3.U(WORD_LEN.W)), //val WORD_LEN = 32
mem(io.imem.addr + 2.U(WORD_LEN.W)),
mem(io.imem.addr + 1.U(WORD_LEN.W)),
mem(io.imem.addr),
)
...
}
class Core extends Module{
val io = IO(
new Bundle{
val imem = Flipped(new ImemPortIo())
val dmem = Flipped(new DmemPortIo())
val exit = Output(Bool())
val gp = Output(UInt(WORD_LEN.W))
}
)
...
val if_inst = io.imem.inst
memoryはimem.instにimem.adrで指定されたアドレスから32bit分の値を書き込み、coreがそれを変数if_instに取り出しています。
フェッチ数の増加
これを(32ビット×IFユニット数(=2))分フェッチできるようにします。
object Consts{
val WORD_LEN = 32
val FETCH_NUM = 2
val FETCH_DATA_LEN = FETCH_NUM * WORD_LEN
...
}
class Memory extends Module{
...
io.imem.inst := readData(io.imem.addr, FETCH_DATA_LEN)
def readData(addr:UInt, len:Int) = Cat(
Seq.tabulate(len / BYTE_LEN)(n => mem(addr + n.U(WORD_LEN.W))).reverse
)
}
フェッチデータ数を定数化し、memoryの読み出し部分も読み出しビット数を可変にしました。
Core側は、in_instのデータ幅を変えるだけです。
val if_inst = Wire(UInt(FETCH_DATA_LEN.W))
if_inst := io.imem.inst
フェッチするアドレスの変更
1度にフェッチする指令数を増やしたので、それに合わせてpc(次に指令を取得するアドレス)の増加分も増やします。
変更前
val if_pc_plu4 = if_reg_pc + 4.U(WORD_LEN.W)
変更後
val if_pc_plu4 = if_reg_pc + (ADR_INC * FETCH_NUM).U(WORD_LEN.W)
定数は以下のように定義しています。
val BYTE_LEN = 8
val WORD_LEN = 32
val ADR_INC = WORD_LEN / BYTE_LEN
val FETCH_NUM = 2
IDステージの並列化
複数指令を同時にフェッチできるようになったので、今度はそれらのデコードも並列化できるようにします。
現状IDステージでは以下の処理を行っています。
- バイナリ指令のデコード
- 1のレジスタでハザードを起こしていないかチェック ある場合は解決
- 計算に使うデータを最終決定
IDステージを並列化するにあたり、これらは異なるステージ(間にレジスタを挟んで別周期で実行されるよう)にします。
バイナリ指令のデコード
ここはデコード処理するユニットを2つに増やし、フェッチしてきた2指令をそれぞれ入力するだけです。
class Decoder extends Module{
val io = IO(
new Bundle{
...
}
...
val rs1_addr = io.dec_in.inst(19, 15)
val rs2_addr = io.dec_in.inst(24, 20)
...
def input(inst:UInt, inst_cpy:UInt, pc:UInt) = {
...
}
//Core.scala
val decoders = Seq.fill(FETCH_NUM)(Module(new Decoder))
Seq.tabulate(FETCH_NUM){
i => decoders(i).input(...)
}
ハザードの解決
1で計算に使用するレジスタが分かりますが、それらが前の指令の計算に使われている場合があります(ハザード)。
このステージではハザードが起こっているかをチェックし、起こっている場合は解決します。
モジュール名はHazardResolverとします。
- 今回使用するレジスタのアドレス
- EX、MEM、WBの各ステージで使用しているレジスタのアドレス
を入力し、各レジスタにつきハザード状況を出力します。
(ここの詳細なロジックは割愛します)
まずはステージを分離するにあたり、ハザードを確認する処理をモジュール化します。
現状は
- 各レジスタごと(1指令で最大2つのレジスタを使う)に
- 各ユニット(EX、MEM、WB)との間にハザードがないか
をチェックしています。
これらの処理はほとんど共通なのでモジュール化します。
つまり、1指令につき6個(2レジスタ×3ユニット)のユニットが必要となります。
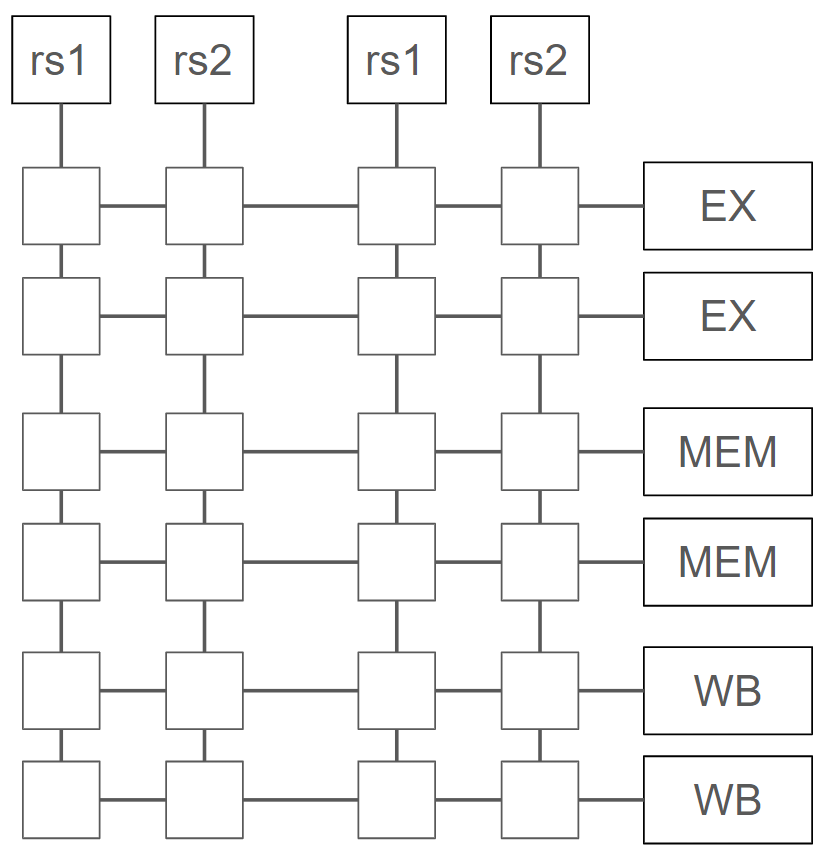
計算に使うデータを最終決定
1,2の結果を元に計算に使うデータを決定します。(第2デコーダとします)
1と同時にできないのは、ハザードが起こると指令されたデータとは異なるデータを使うことになるからです(MEMステージから持ってくる、など)
ここの並列化もただユニット数を増やすだけで問題ないです。
1のデコード結果、2のハザード情報と紐づけが間違わないように(指令1と2の結果を混ぜないように)だけ注意します。
全体像
IDステージの全体像は以下のようになります。
(細かいロジックとかはだいぶ端折りました、、、)
val decoders = Seq.fill(FETCH_NUM)(Module(new Decoder)) //デコーダ (1)
Seq.tabulate(FETCH_NUM){
i => decoders(i).input(...)
}
val hazardResolver = Module(new MultiHazardResolver()) //ハザード解決ユニット(2)
val rs_addrs:Vec[UInt] = Decoder.createRSdatas(decoders) //rs1、rs2として指令されたデータ
hazardResolver.input(rs_addrs, ...) //2番目以降の引数はEX、MEM、WBなどのレジスタ情報など
val id_rs_datas:Vec[UInt] = VecInit(Seq.fill(RS_DATA_NUM)(0.U(WORD_LEN.W)))
Seq.tabulate(RS_DATA_NUM){i =>
val hazRes = hazardResolver.io.out.hazardRes(i) //ハザード情報
id_rs_datas(i) := MuxCase(regfile(hazRes.act_addr), Seq(
... //ハザード情報を元にレジスタデータを決定
)
)
}
val decAfterHzResolvers = Seq.fill(FETCH_NUM)(Module(new SecondDecoder)) //ハザード解決後の処理(3)
Seq.tabulate(FETCH_NUM){
i => decAfterHzResolvers(i).input(id_rs_datas(2 * i), id_rs_datas(2 * i + 1), ...)
}
実行結果
以下のプログラムをメモリに読み込ませ、実行しました。
(ひとまずハザードは起きないようにaddの前にnopを入れています)
00000000 <main>:
0: 00300513 li a0,3
4: 00200593 li a1,2
8: 00000013 nop
c: 00a58633 add a2,a1,a0
10: c0001073 unimp
14: 00000513 li a0,0
18: 00008067 ret
結果は以下のようになりました。


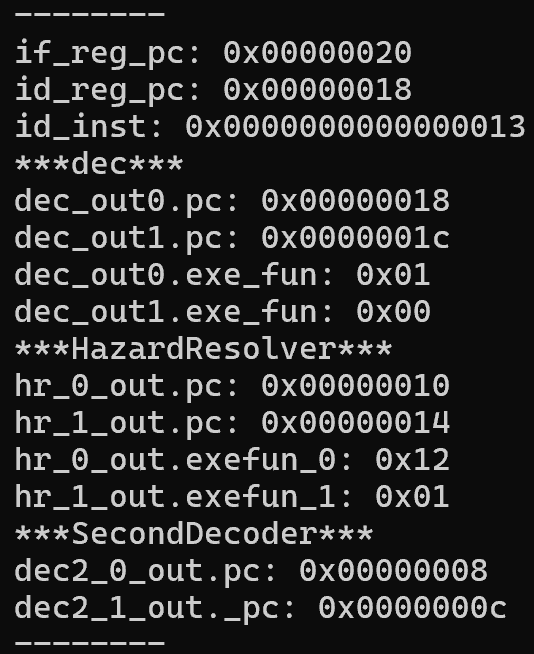
if_reg_pc: IFステージが処理しているpc
id_reg_pc: IDステージが処理しているpc
id_inst: IDステージが処理している指令
dec_out0(1): 1(2)つ目のデコーダ
.inst: 処理している指令
.exe_fun: 処理の種類(内部で定義されてる定数)
hr_0(1)_out: 1(2)つ目HazardResolver
dec2_0(1)_out: 1(2)つ目の第2デコーダ
これより
- pcが8ずつ増える
- 指令を64bitずつ取得できている
- 取得した64bitを32bitずつに分けられている
- 1サイクルごとに処理するpcが次のステージへ引き継がれていく
ことが分かります。
今後の展望
まずは後続のEXステージ以降の並列化を進めます。
また、全体が出来上がったらハザード解決の部分もちゃんと考えたいです。
なお、コードは以下に置いてあります。
Discussion