プログラムがメモリをどう使うかを理解する(3)
この記事は
このシリーズの3本目です。
前回の記事は
こちらです。
文字列はどこに置かれるのか?
前回は文字列を保持する変数を3通りの方法で定義してみました。
const char* strA = "HogeHoge";
const char strB[] = "HugeHuge";
std::string strC = "FooBarFooBarFooBarFooBar";
どれもC/C++の入門書にありそうな書き方ですが、これらは全て文字列の実体を格納する場所が異なります。それぞれどこに格納されるのか、調べてみましょう。
「文字列置き場」とそこへのポインタ
まず strA から。
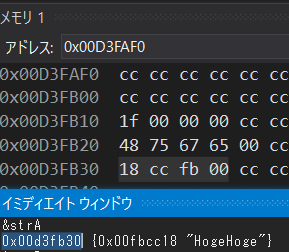
&strA が指すアドレス 0x00D3FB30 に入っているのは 0x00FBCC18 という値のようです。イミディエイトウィンドウの出力結果を見るに、これもアドレスのようなので、この近辺を覗いてみましょう。

あった!ありました! "HogeHoge" 以外にも、色々な文字列らしきバイト列が見えます。どうやらここらへん一帯は 文字列置き場 みたいですね。strA という変数は文字列そのものを持たずに、文字列が格納されているアドレスを「お探しの文字列はこちらです」と 指し示していた わけです。これはまさに ポインタ の役割に他なりません。
const char* strA = "HogeHoge";
このコードで何が行われるのかをまとめると、
- コンパイル時に "HogeHoge" という文字列リテラル(""で囲われた文字列)が現れたので、これを文字列置き場に配置して、コード上の文字列リテラルを配置したアドレスに置き換える
- 実行時に strA に 1. で置き換えたアドレスを代入する
ということになります。「strA に "HogeHoge" という文字列を代入する」と解説している書籍は多いでしょうし、プログラムの意図としてはその解釈でも間違いではないのですが、少なくともC/C++のプログラムでは、上記のようなことが行われています。
「変数置き場」に置かれた配列
では次に strB を見てみましょう。

はい、こちらは間違いなく配列そのものが、これまで見てきた 変数置き場 に置かれていますね。前回 int 型の配列を作ってみましたが、それと同じような配置と言えるでしょう。
const char strB[] = "HugeHuge";
これで行われていることは……
- strB は
const char型の配列として定義され、その長さは右辺値の文字列長(ASCIIコード8個分+ヌル終端)によって決定され[9]となる - そこに
"HugeHuge"が代入(コピー)される
です。strA よりはよっぽど「文字列の代入」と呼べる動作になっているかと思います。
ここで勘の良い方は「じゃあそのコピー元ってどうなってるの?」と思われるかもしれません。実は、更に勘の良い方は「さっき見た『文字列置き場』にあったよな」と気づかれたかもしれません。
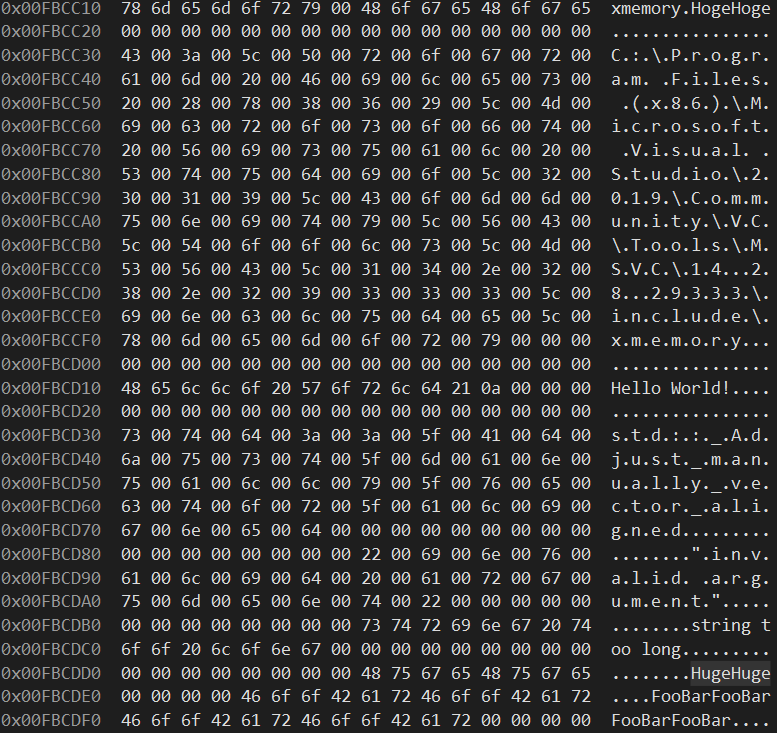
はい、右下をご覧ください。"HugeHuge" もいました。ここからコピーされています。
つまり、この代入をすると 文字列が二重持ちされる わけですね。これを良しとするか、無駄と思うかは、文字列の用途によって異なると思います。プログラム中で不変な文字列として利用したいなら strA の方がいいですし、処理中で何らかの文字列操作をして変更したいのなら、この後解説する strC の方が適切でしょう。
「第2変数置き場」に確保された配列
最後に strC を見てみましょう。C++なら文字列は std::string を使いましょう!と解説している書籍も多いですよね。

……ん~……ダメです、さっぱり分かりません。sizeof(std::string) はいくつでしょうか?
sizeof(std::string)
28
なるほど、28バイト(x86/MSVCの場合)ですか。 0x00D3FAF8 から始まって、さっき見た "HugeHuge" のちょっと前までが28バイトなので、この範囲が std::string の値と見て間違いなさそうですね。
何となくですが、最初の4バイト+4バイト、ここに入ってる値がアドレスっぽいですねぇ。
08 fa 17 01 60 ad 17 01
たぶん 0x0117FA08 と 0x0117AD60 のことじゃないでしょうか。見に行ってみましょう。
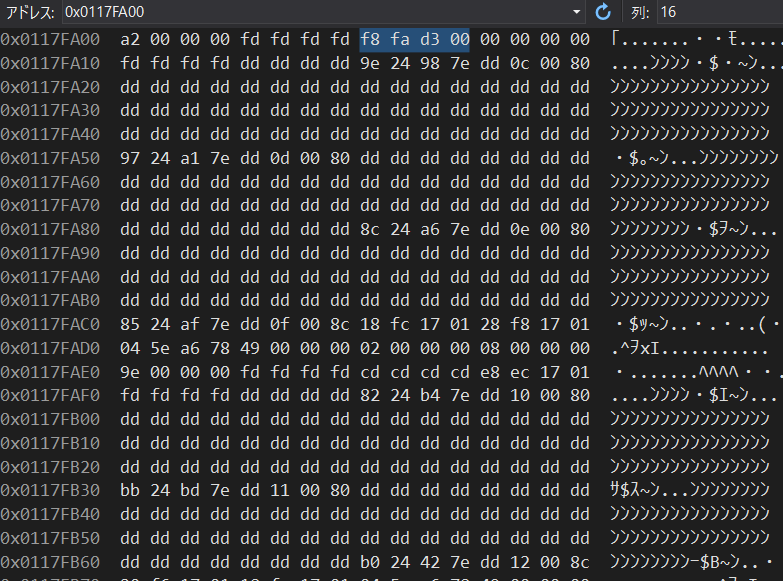
ん?これは 0x00D3FAF8 というアドレスが入ってるっぽいですね。こっちは外れか……
それにしても、ここらへんはさっきの 変数置き場 とは違って、ンンンンンンンンが多いですね。時折エ~ンとかヲ~ンとかが入ってます。景色が違う気がしますね。
ではもう1つのアドレスっぽい方を見てみます。

ビンゴ!見つかりました。やはり文字列へのポインタでした。しかしここはさっきの 文字列置き場 とは違って、周りは文字列だけではない色々なデータが転がってるようです。そもそもアドレスがかなり遠い場所(0x01から始まっている)になってますので、ここはいわば 第2変数置き場 とでも言うべき場所ではないでしょうか。
std::string strC = "FooBarFooBarFooBarFooBar";
では、std::string 型の変数に文字列を代入するのがどういうことかと言うと、
- 代入しようとしている文字列が収まるサイズの配列を 第2変数置き場 に確保する
- std::string 型の変数内でその配列への ポインタ を保持する
- ついでに文字列長と配列長も持つ
-
第2変数置き場 に確保した配列へ 文字列置き場 に配置された
"FooBarFooBarFooBarFooBar"をコピーする
てな感じになります。
3つの領域
そんなわけで、プログラムから直接扱えるメモリには、3つの領域があることがわかりました。いつまでも「~置き場」みたいな呼び方をするのもカッコ悪いですし、正式名称と結び付けて覚えましょう。
スタック
これまで 変数置き場 と呼んでいた、関数内で定義した変数が配置される領域です。
スタックでは、最初に定義された変数が領域の末尾(アドレスが大きい側)から配置されるという特性があります。
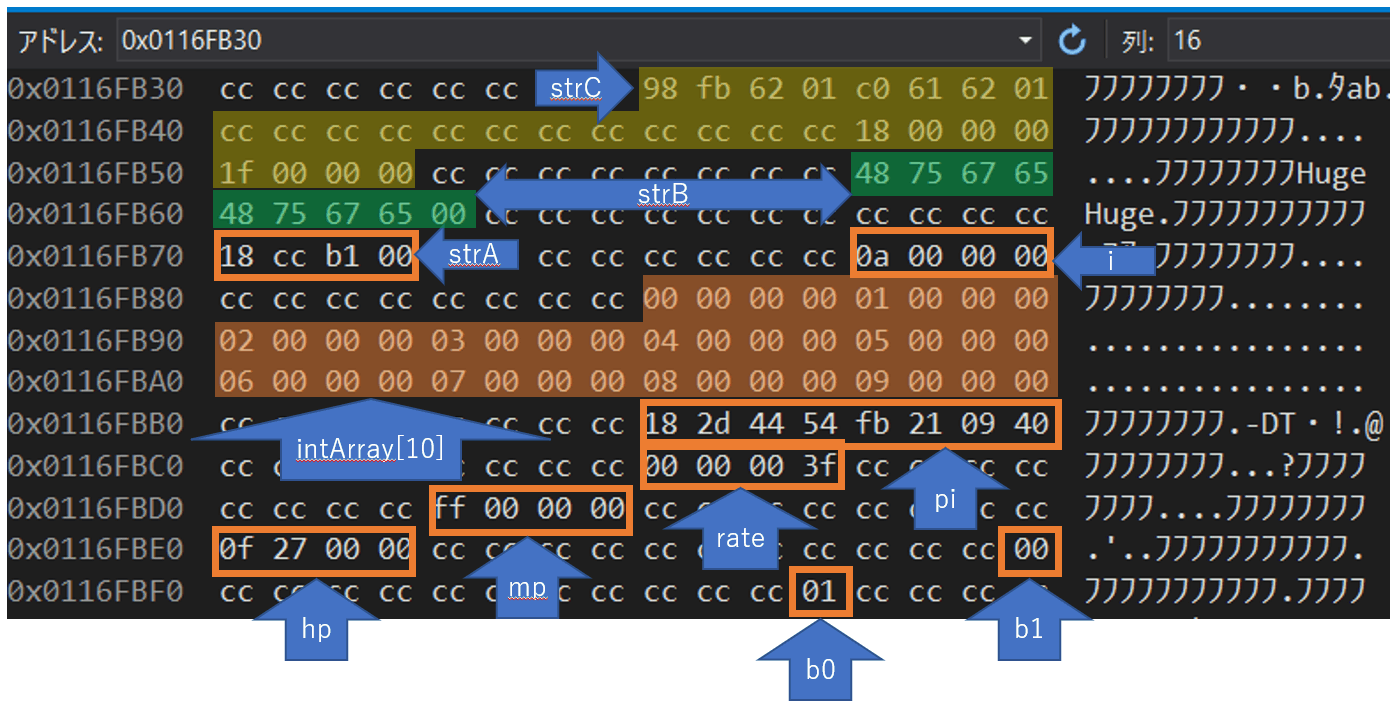
この図を見れば一目瞭然ですね。積み上げていくから スタック と呼ばれています。
スタック上での変数用領域確保は、現在のてっぺんを、確保したい型のサイズ分だけ上(アドレスが小さい方)にスライドさせるだけで済みます。スコープや関数を抜けて変数を破棄する時も、型のサイズ分だけ下(アドレスが大きい方)にスライドさせるだけです。この特性により、スタックでのメモリ管理は後述するヒープより遙かに高速に処理できます。
その反面 コンパイル時に型のサイズが確定しないものは変数として定義できない ですし、スタックに積んだ変数の大きさを後から変えることはできない という大きな制約が課せられます。もし底の方に埋もれた変数を大きくしたいなんてことをやろうとすると、大きくしたい分、上に乗っかってるものを動かす必要があります。すると、動かした変数のアドレスが変わってしまい、ポインタでそれらを参照していたら色々と破綻します。
ヒープ
スタックは、コンパイル時にサイズを確定し、一定方向に変数用のメモリ領域を積み上げることで処理の単純化を図っていました。しかし、実際には長さの変わるものを扱いたいというニーズは確実に存在します。文字列がその代表例であり、まず真っ先に思い当たるものになると思います。
こういったニーズに応えるために、第2変数置き場 としての ヒープ が存在します。
ヒープとは、必要になった時に確保して、不要になったら返却するメモリ領域のことです。空き領域さえあれば、プログラムの処理中の好きなタイミングで好きな大きさを確保することができるため、実行時にならないとサイズが確定しない大きさの配列(バッファ)が作れます。後からサイズを変更したい(文字列に付け足して長くなった、など)場合は、もっと長い大きさの配列を作ってそこに内容をコピーし、元の短い配列は解放して新しい配列のアドレスをポインタに保持する、といった操作になります。今回取り上げた std::string もそういう動作になっています。
スタックより自由がきくからこれでいいじゃん、と思われるかもしれませんし、実際ちょっと前はそういう風潮がありました。そういった設計思想はJavaや(昔の)C#に色濃く反映されています。
しかし実際には、ヒープの確保・返却にかかるオーバーヘッドや、メモリ領域が飛び飛びになりがちであったりする点が、速度面でのペナルティーとして無視できない場面が多く見られるようになり、スタックとの適切な使い分けや、メモリ確保戦略についてのチューニングなどが求められているのが現状です。ここらへんのトピックは今後の記事でもいくつかの切り口で掘り下げようと思います。
静的領域
スタックやヒープとは異なり、プログラムが実行されたら終了するまでずっと保持する必要のあるデータを記憶する領域のことです。今回説明した用途としては 文字列置き場 がありましたが、それ以外にも(あまり褒められた利用方法ではないですが)関数の外で定義する、いわゆるグローバル変数や、static変数などがこの領域を利用します。
プログラムをコンパイルする際に、文字列リテラル・グローバル変数・static変数などを集計して合計サイズを算出し、その分を静的領域としてプログラムのロード時に確保します。なので、大量の文字列やグローバル変数として巨大な配列を作ったりすると、確実にヒープで利用できるメモリ容量は減少します。ご利用は計画的にお願いします。
静的領域と一括りで説明していますが、文字列リテラルなどの読み取りしか起きない定数値と、中身の書き換えなどが起きるグローバル変数などは別々の領域に分けられており、読み取り専用領域のポインタを通じて書き込みを行おうとすると、OSから怒られます。
例外がスローされました:書き込みアクセス違反。
const を強引に外して何かをするのを避けた方がいいのは、こういう警告をも握りつぶしてしまうからですね。
今回のまとめ
- プログラムで扱うメモリ領域は主に3つ
- 関数内で定義する変数を配置するスタック
- 任意のタイミングで任意の大きさを確保・解放できるヒープ
- 定数値やグローバル・static変数などを配置する静的領域
- 文字列を何気なく代入するだけでも、書き方によって使われ方が全く異なる
今回はメモリダンプ画面を見て、変数の配置が見えるようになる楽しさみたいなものが伝わったなら嬉しいなぁ、という感じです。メモリ関係のデバッグをする時に思考回路をドバっと乗っけてみました。
次回以降は、
- 関数呼び出しで起こることを観察する(これでポインタや参照渡しはバッチリ)
- 構造体レイアウト(ArrayOfStructとStructOfArrayの話とか)
- CPUとメモリ・ストレージの距離感の話(ロードをうまく処理してるゲームの特徴とか)
みたいな話をしていこうかと思います。お楽しみに。
続き
Discussion