プログラムがメモリをどう使うかを理解する(2)
この記事は このシリーズの2本目です。
値の表現
前回は 0xDEADBEEF という16進数を直接代入する瞬間を観察しましたが、それができたところであまり嬉しくはありません。なので、もう少し実用的な値がどのように表現され、メモリ上に配置されるのかを見ていこうと思います。
では、main関数の中に変数を色々追加してみましょう。
int main()
{
bool b0 = true;
bool b1 = false;
int hp = 9999;
int mp = 255;
float rate = 0.5f;
double pi = 3.14159265358979323846;
int intArray[10];
for (int i = 0; i < 10; ++i)
{
intArray[i] = i;
}
std::cout << "Hello World!\n"; // ここでブレーク
}
ブレークしたところで各変数のアドレスをイミディエイトウィンドウで調べて、メモリウィンドウで表示してみます。
bool
bool型の変数はtrueかfalseのいずれかの値を取りますが、この処理系(MSVC/x86)におけるメモリ上では1と0で表現されます。
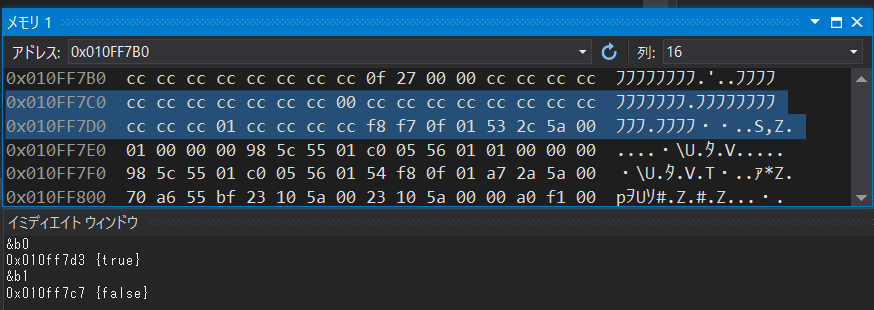
0xcc が並んでいる中に 0x01 と 0x00 が存在しています。サイズは1バイトのようですが、これもあくまでこの処理系においてそうなっているだけで、他のコンパイラやプラットフォームでは異なる表現になることがあり得る点には注意しましょう。
もう一つ気になるのは、プログラム上では2個続けて定義したのに、このメモリの中ではb1の方が若いアドレスに配置され、間隔も微妙に空いていることです。変数の配置場所は定義順によらず、コンパイラが都合の良いように配置を調整するということですね。
int
int型は、昨今のメジャーな処理系では「32ビット(4バイト)で表現する符号付き整数」を表現します。本当にそうかどうかは、イミディエイトウィンドウで sizeof(int) を実行して確認しといてください。
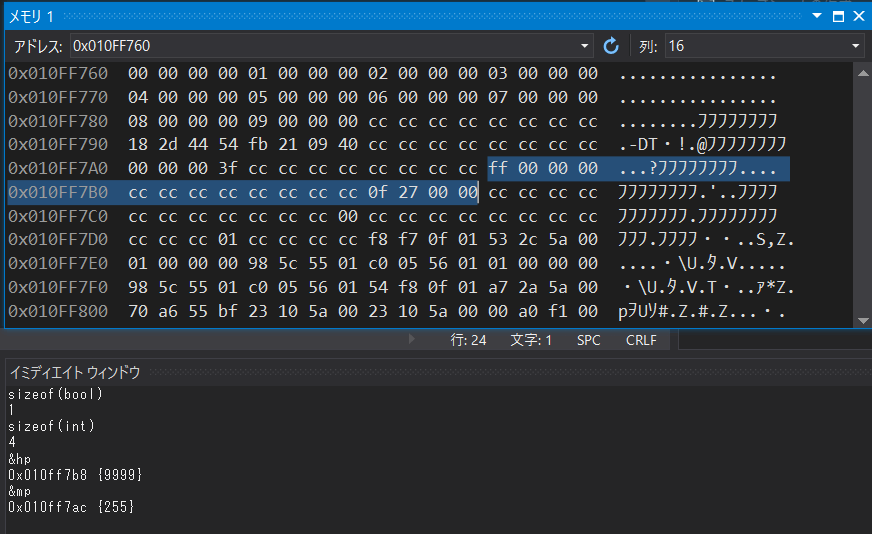
ついでにbool型のサイズも調べときました。1バイトですね。sizeofで問い合わせたサイズは、その処理系においては信用して良い値です。
ちょっと復習と雑談
さて、今回のコードでは何となくですが、古き良きRPGにおけるヒットポイント(HP)の最大値である9999を代入してみました。お手元に関数電卓があれば(なければOS付属の電卓アプリでもいいですが)16進数と10進数の相互変換ができると思います。9999は 0x0000270F なので、リトルエンディアンに従ってメモリ上では 0F 27 00 00 という並びになります。MPの方は255なので、FF 00 00 00 となっていますね。
もしHPの上限が9999ならば、int型を使うのは無駄です。かならず後半2バイトは 00 になるからです。short型(16ビット整数)を使う方がメモリを無駄にせずに済みます。同様に、255が上限のパラメータならば、unsigned char(8ビット整数)で十分です。このような理由から、昔のゲームにおけるパラメータの上限値は、多くの場合メモリを節約するために変数の型によって決められたものが多いです。
昨今のゲームでは、ゲームロジックを表現するのにそこまでメモリを切り詰める場面はあまり無いと思いますが、レトロゲームで出てくるパラメータの上限値が 2のべき乗-1 だったら「ああ、メモリ無くて大変だったんだな……」と苦労を偲んであげてください。
float & double
float型とdouble型の変数は、いわゆる実数を表現するためのものです。
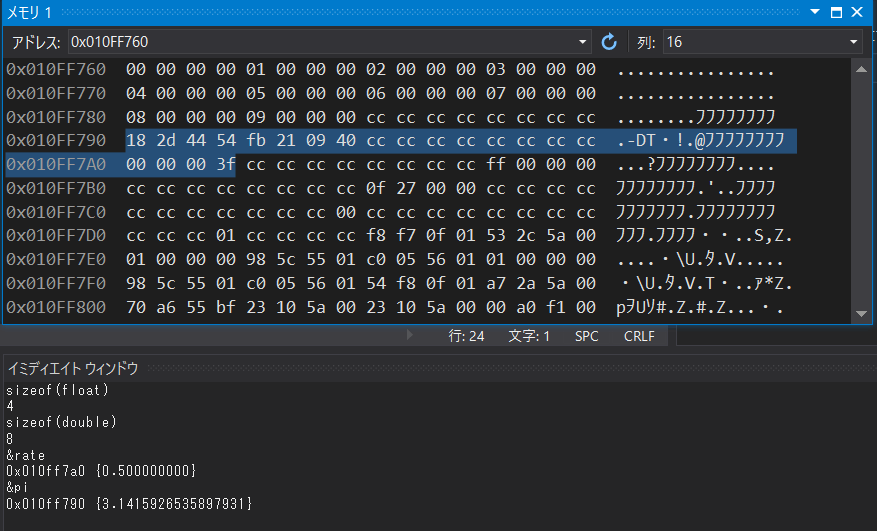
しかし、boolやintと違って、メモリ上の値を見ても(普通の人は)何がなんだか分かりません。float型やdouble型の変数として確保されたメモリ上には、浮動小数点数の標準規格によって定められた表記法に従った表現が格納されています。詳しく説明するとそれだけで超大作になるので、こちらをご覧ください。
ここで重要なのは、コンピュータにおいてはこのように 単純な整数値で扱えないような値も、あらかじめ共有された表記法で格納・解釈することで扱うことができる ということです。どこまでいっても1バイトで表現できるのは256通り(0~255)の情報でしかないですが、それらを組み合わせ、意味を持たせることで、様々な意味合いのデータを処理しているのです。
ちょっと邪悪な実験
上記の画像の通り、 &rate をイミディエイトウィンドウで評価すると、そのアドレスに格納された値が 0.5 であることを示してくれますが……
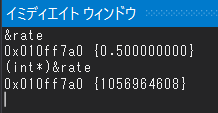
int型の変数のアドレスとして強引に解釈すると、指しているアドレスは同じなのに、解釈される値は 0.5 とはほど遠い巨大な数値になります。格納時と解釈時用いる表記法がマッチングしないと、このような事故が起きます。
メモリは単なるバイト列でしかないので、それをどう解釈するかは実行コード側の裁量に委ねられています。C/C++では強引なキャストによって簡単に「解釈違い」が起こせてしまいます。それが必要だったり、意図してやっているなら良いのですが、そうでない場合に変なキャストをするのは避けましょう。
配列
int型の配列を作り、0~9までの値を順番に入れたものを見てみましょう。
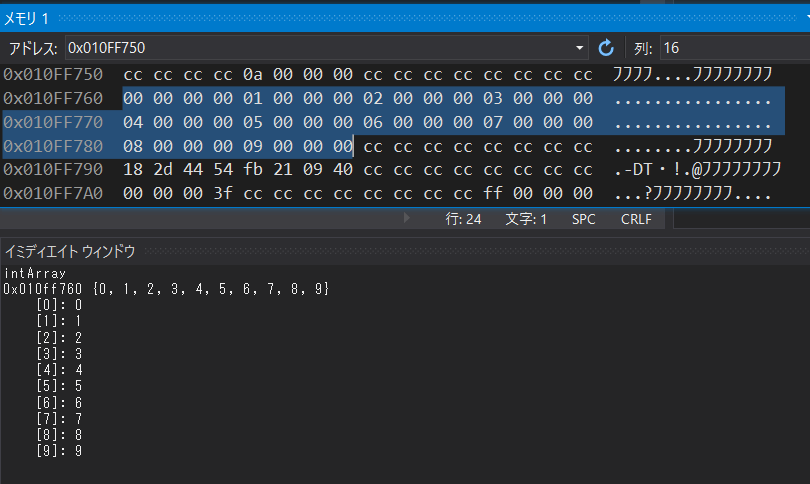
これまでの変数群とは異なり、隙間無く10個分ぴっちり並んでいますね。これがC/C++における配列のとても重要な性質です。必ずメモリ上で連続することが保証されているのです。この性質は様々な場面において大きなメリットをもたらすので、覚えておいてください。
文字列の表現(と次回への引き)
さて、次は文字列の表現に移りたいところですが、とりあえずこんなコードを追加してみます。
const char* strA = "HogeHoge";
const char strB[] = "HugeHuge";
std::string strC = "FooBarFooBarFooBarFooBar";
これらの変数近辺のメモリを覗くと……
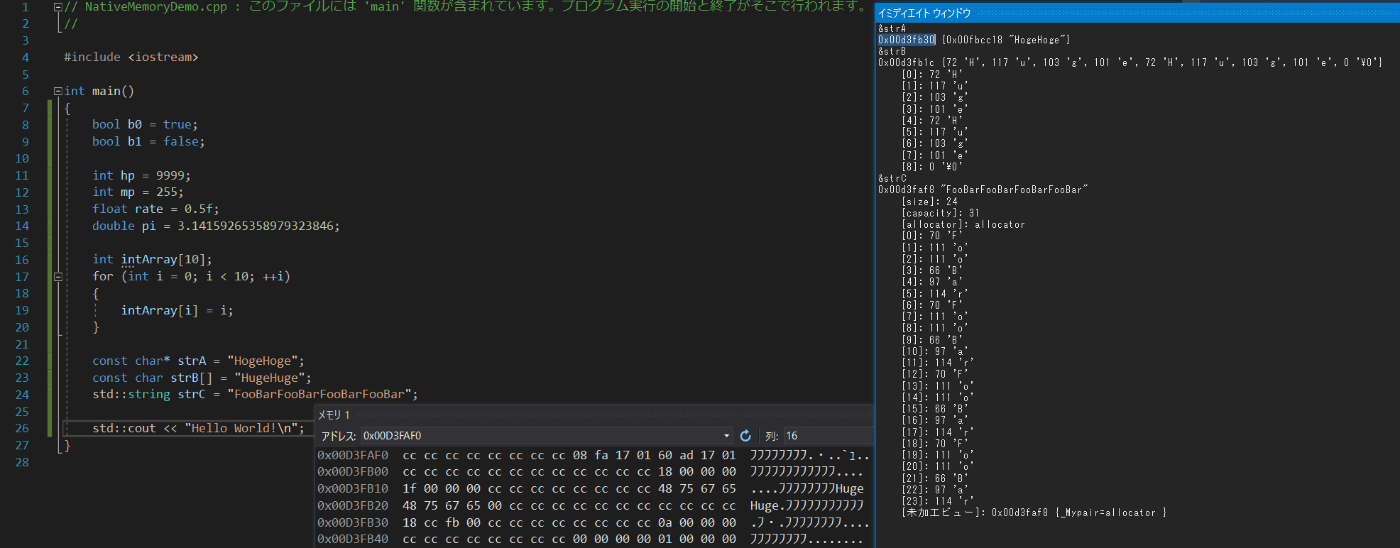
strB の "HugeHuge" は見当たりますが、strA と strC に代入した文字列が見当たりません。ですが、イミディエイトウィンドウで見た限りは、ちゃんと保持されているようではあります。これはいったい……?
今回のまとめ
- 変数が使うスペースはコンパイラが良きように決めてくれる
- 変数の型によってメモリ上で占めるサイズが決まる
- 1バイトで表現できるのはあくまで0~255の整数値でしかない
- それらの組み合わせたり、意味するところを定めることで、色々なものを表現できる
- 配列はメモリ上でも先頭から末尾まで隙間無く順番に並ぶ
- 文字列も保持できるけど、記法によって何か扱い方が違うっぽい……?
というところで今回はここまで。次回は間接参照とか、静的領域とか、そこらへんをやっていきます。ご期待ください。
続き
Discussion